文章目录
- 一、Transformer的架构
- 一、编码
- 1.1 词向量编码(Input Embedding)
- 1.2 位置编码(Positional Encoding)
- 二、Mask
- 2.1 PAD Mask
- 2.2 上三角Mask
- 二、注意力计算
- 2.1 Q、K、V 向量的生成
- 2.2 自注意力计算流程
- 2.2 单头注意力和多头注意力
- 三、计算流
参考自 https://www.bilibili.com/video/BV19Y411b7qx?p=2&vd_source=e768911f41969985adfce85914bfde8f
一、Transformer的架构
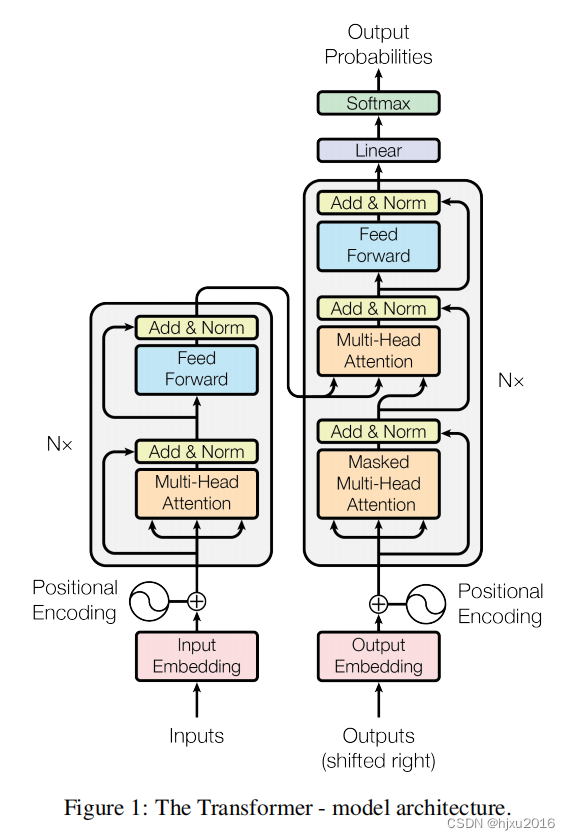
一、编码
词向量编码 + 位置编码 = 最终的输入编码
1.1 词向量编码(Input Embedding)
可以是简单的词向量编码
1.2 位置编码(Positional Encoding)
Teanformer 不同于Rnn, 在处理数据时,不考虑数据的位置信息,所以需要在数据中加入位置信息,以让处于不同位置的相同数据有所不同,相互区分。
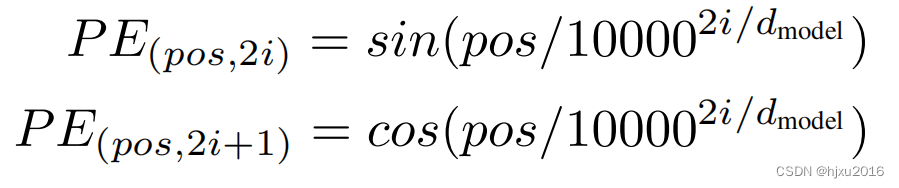
p
o
s
pos
pos: 词位置,[0,1,2,3…] 第一个词、第二个词
i
i
i: 编码位置,[0, 1, 2, 3, …],
i
i
i 是词向量编码后,第0个向量,第1个向量
如果词向量编码是32个维度,那么
i
i
i 是 0-31
p
o
s
pos
pos 是PE矩阵的行数,
i
i
i 是矩阵的列数
d
m
o
d
e
l
d_{model}
dmodel: 编码维度, 32
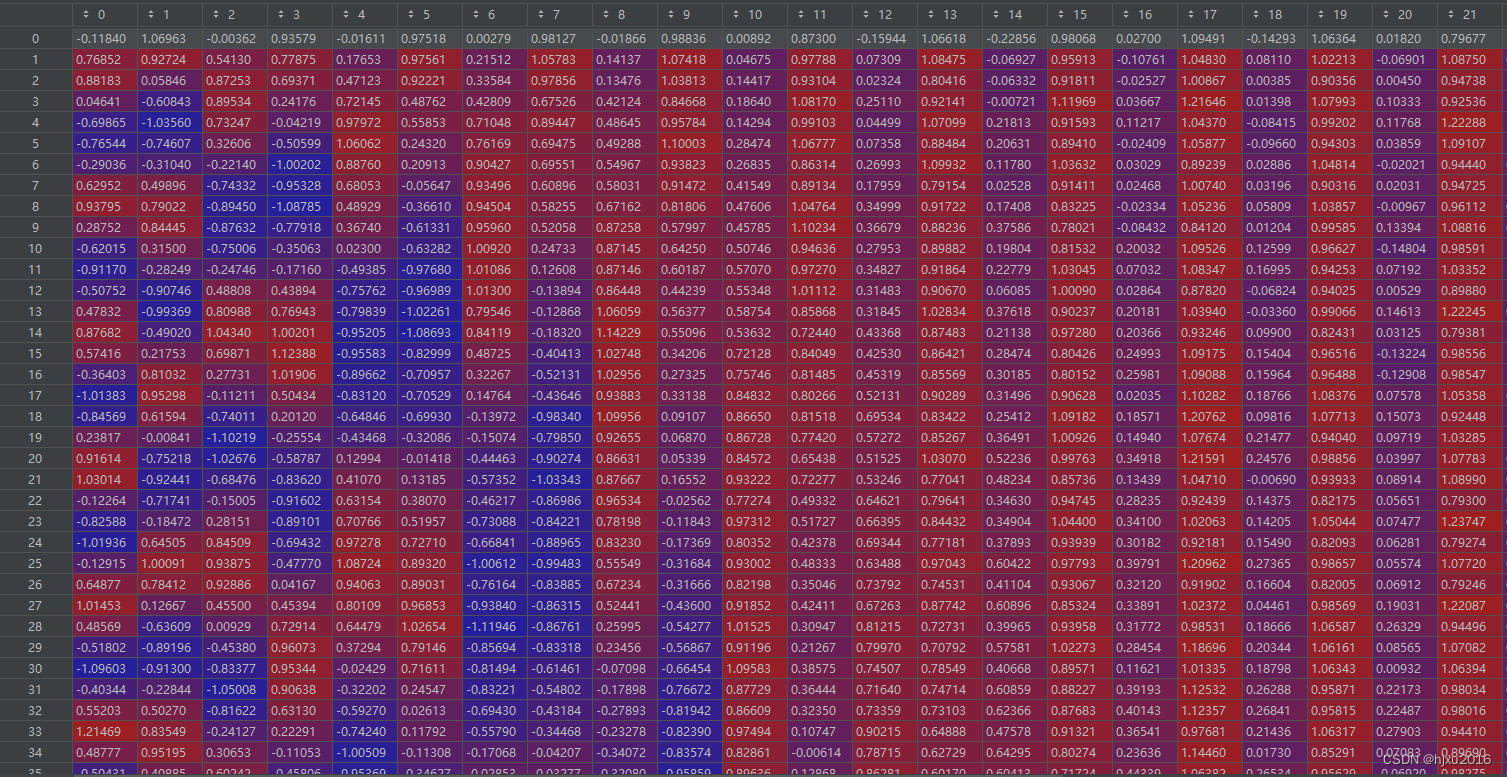
来看一个位置编码的矩阵截图
可以看到,第一列数值波动的频率比较高,越往右波动越小
二、Mask
最终Mask 是Pad mask 与上三角mask取并集
2.1 PAD Mask
让一句话保持同样的长度,当出现短的句子的时候,需要补Pad,
每个词对Pad的注意力标注为Mask, 但Pad 对每个词的注意力正常计算
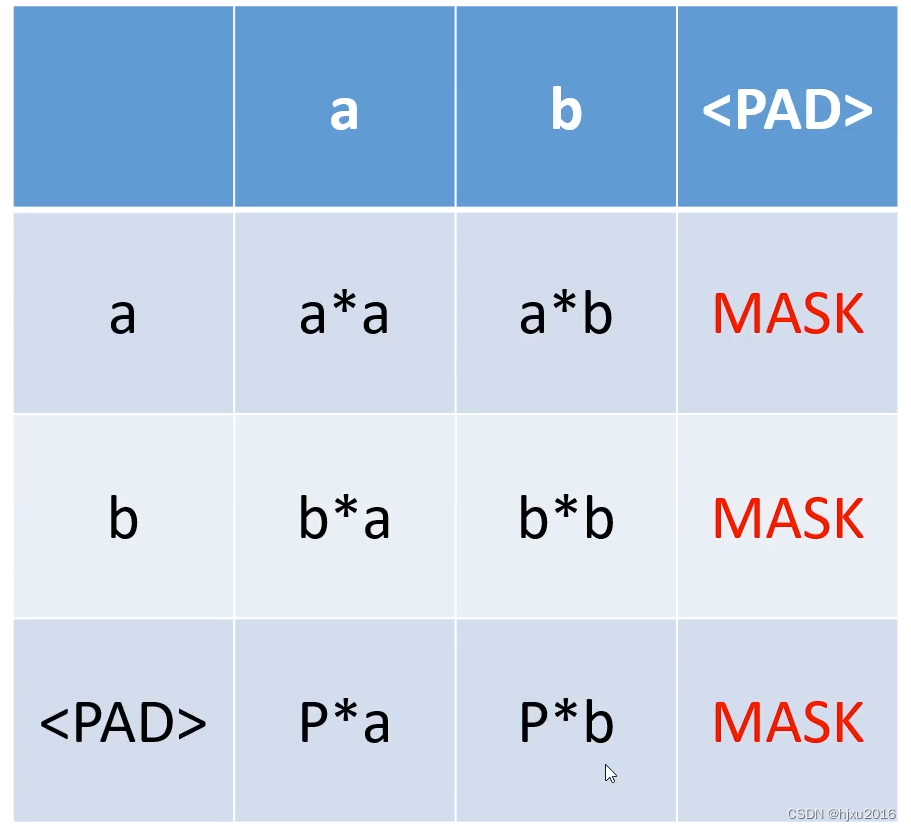
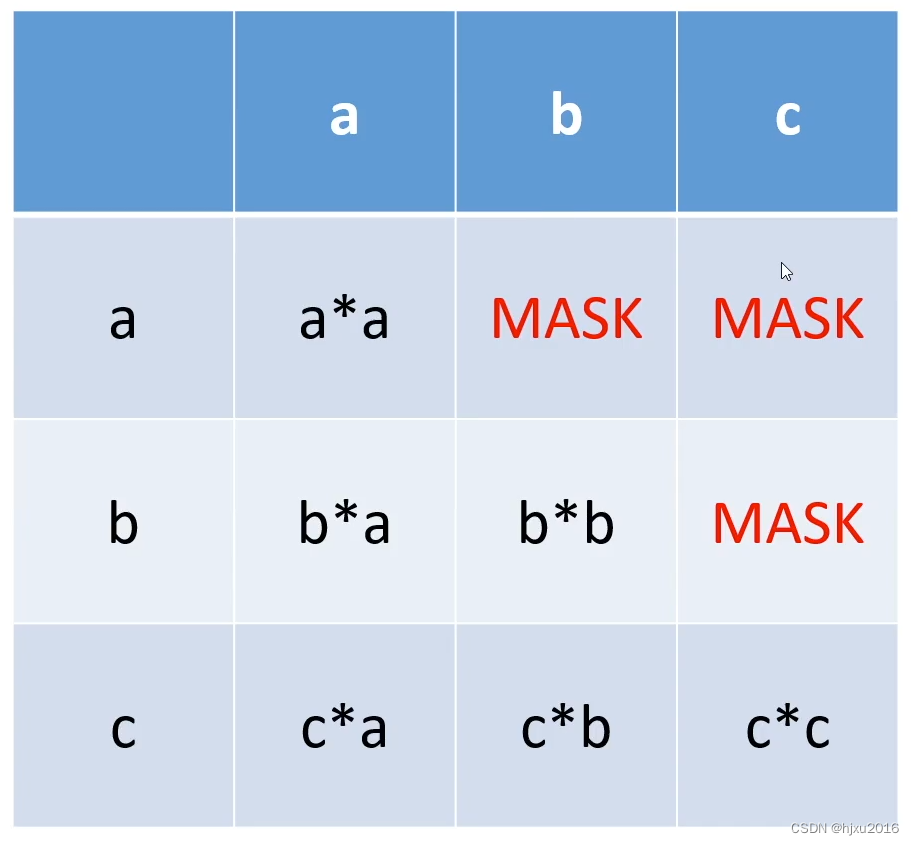
2.2 上三角Mask
b和c是需要预测到的词,因此a不能注意到b
二、注意力计算
2.1 Q、K、V 向量的生成
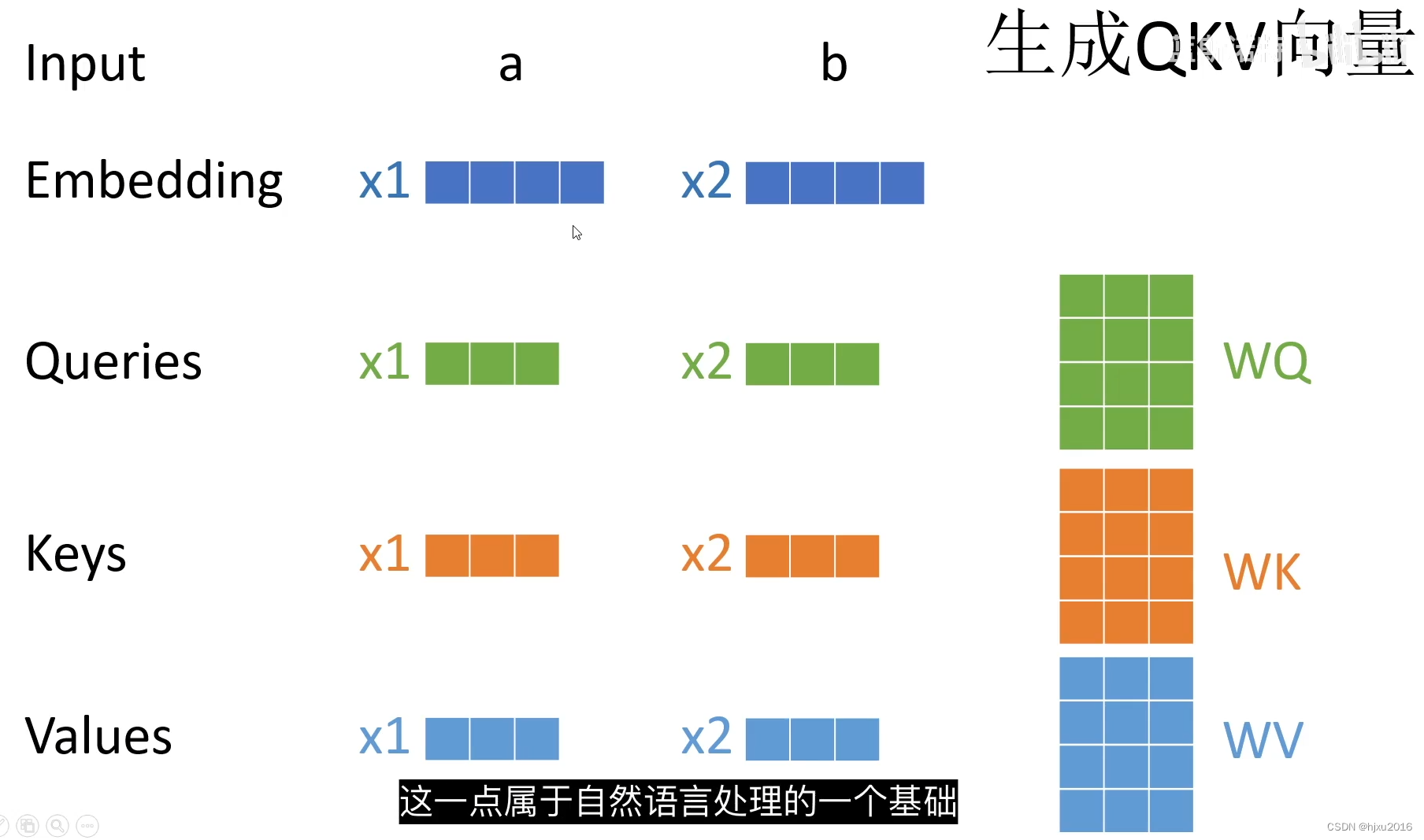
2.2 自注意力计算流程
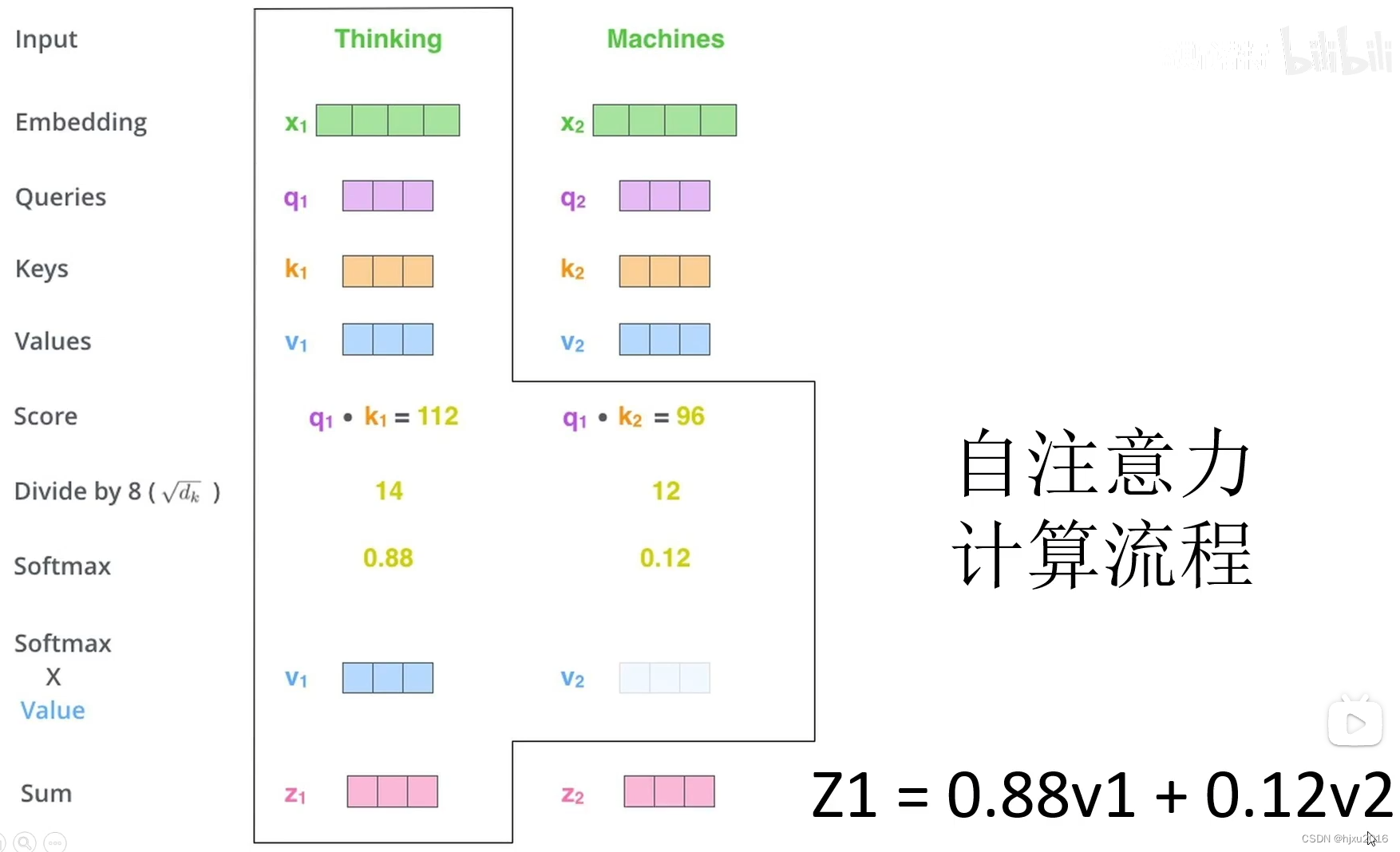
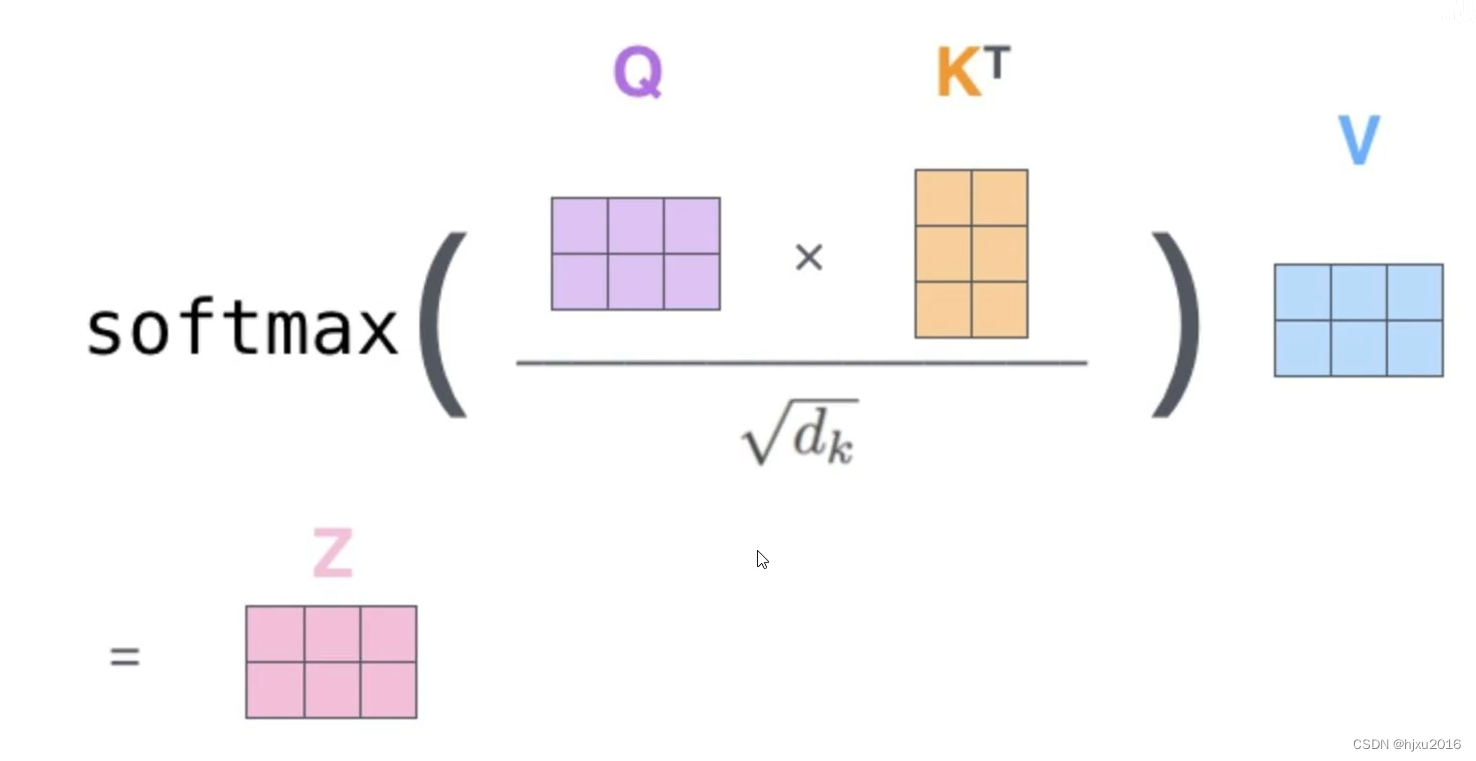
2.2 单头注意力和多头注意力
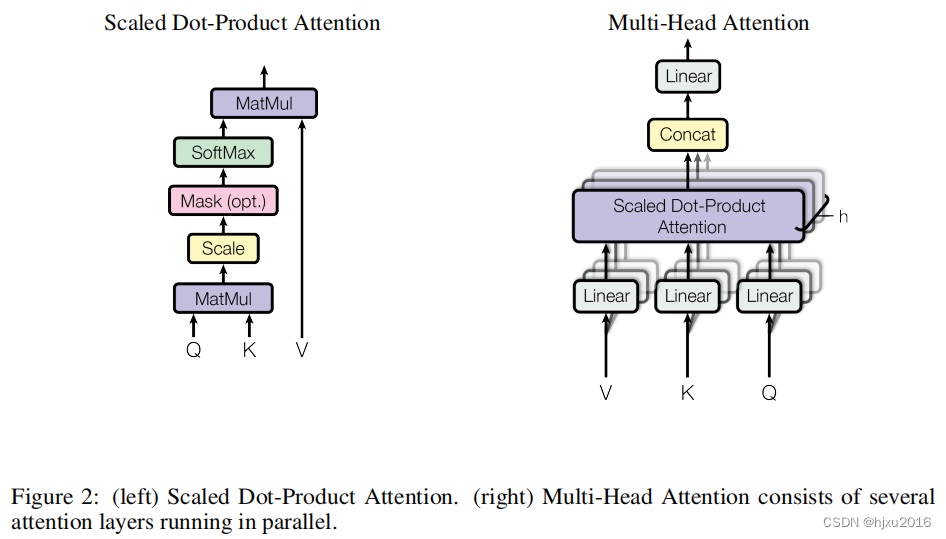
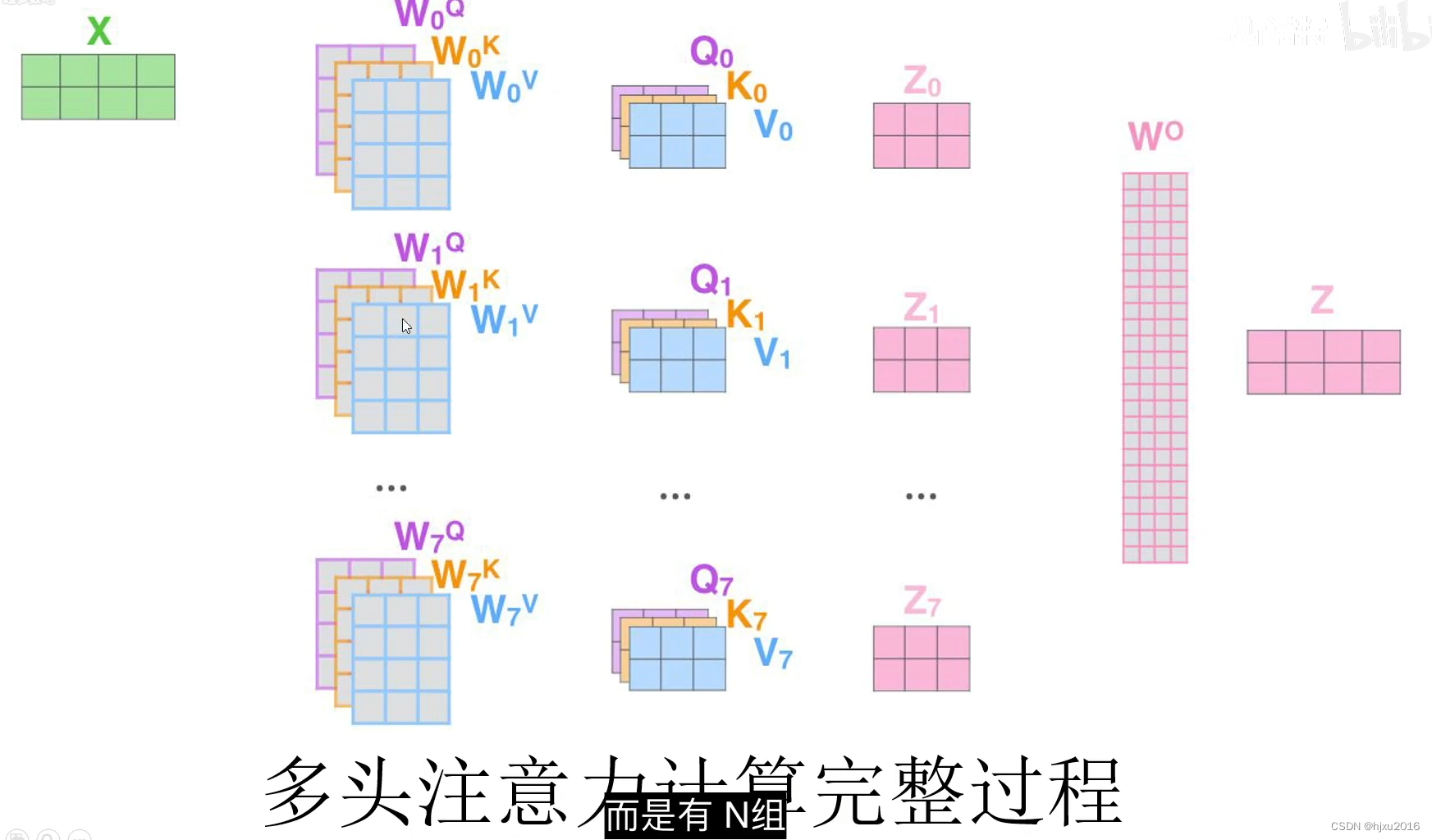
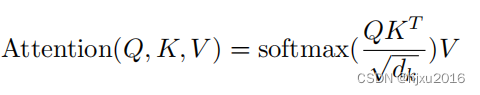
三、计算流
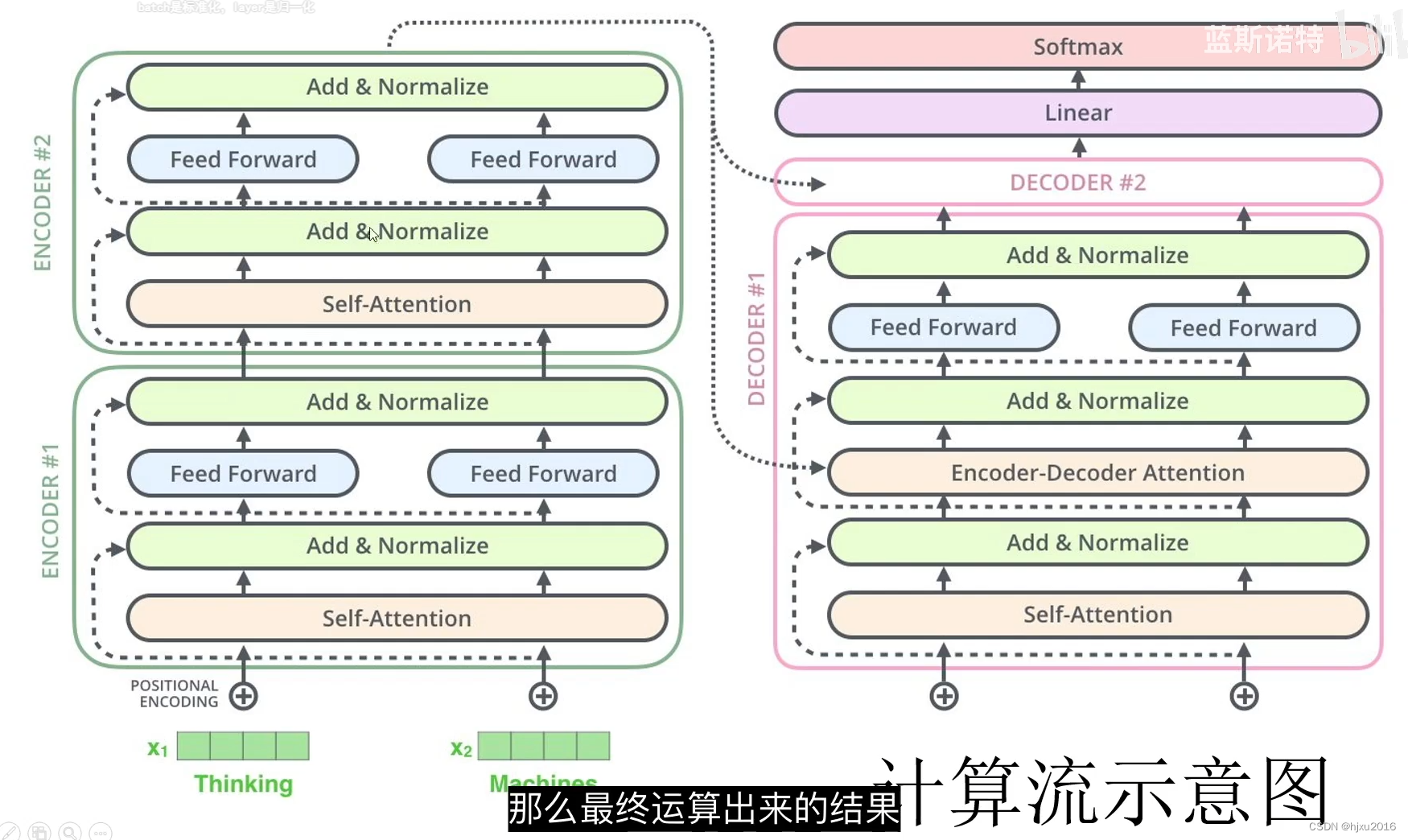






![2023年中国电动升降诊疗台产业链及市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/ac8fdf4787f5463b115fa4f70a621e9a.png)