Python
python语言的学习技巧:多写多敲
要求能够掌握基础知识,能够使用python实现自动化脚本的开发即可!!!
一、python语言的特点
- python是一种胶水语言:python需求和其他的行业结合在一起才能发挥更大的作用
- 现在主流的自动化测试python/java栈
- java/vb(qtp、uft)/JavaScript(selenium)
- python是一种高级语言:语法越来越简单了、更好理解了、支持面向对象了
- python是一门弱类型语言:给变量传什么数据,该变量就是什么类型的
- python是跨平台的语言:一处编码、处处可用(不同的OS)
- python是一门解释型语言:逐行解释执行
- python是一门面向对象语言:一切皆是对象
- python是一门简单易学的自动化脚本开发语言
二、python开发环境(熟练掌握)
要求熟练掌握环境搭建
-
python软件包的安装
python分为python2版本和python3版本。
- 在D盘创建一个文件夹:python、python38,注意不要有空格,不要有中文字符
- python安装时候选择自定义安装(以免后面找不到安装目录)、勾选添加python到环境变量path(在任何cmd路径下都可以执行python命令)
- 注意:安装的软件,不允许对路径中目录名称进行修改、删除、移动
- 直接点下一步直到完成。
环境变量配置:
- 我的电脑—属性—高级属性设置—环境变量
- 系统环境变量—path—点击编辑,将python安装目录粘贴到path中即可
-
安装集成开发环境(IDE)工具—pycharm
-
使用pycharm创建一个工程目录。。
-
python代码三种执行方式
- 命令行交互式执行
- 通过命令行直接运行py文件
- 通过IDE工具开发并运行代码
-
pip的使用
pip工具是python语言中的一个包管理(第三方软件管理)工具,负责第三方软件的安装、卸载、更新等。
和Linux系统下yum命令、nodejs的npm命令功能相似
安装python是自带pip工具
-
pip帮助信息
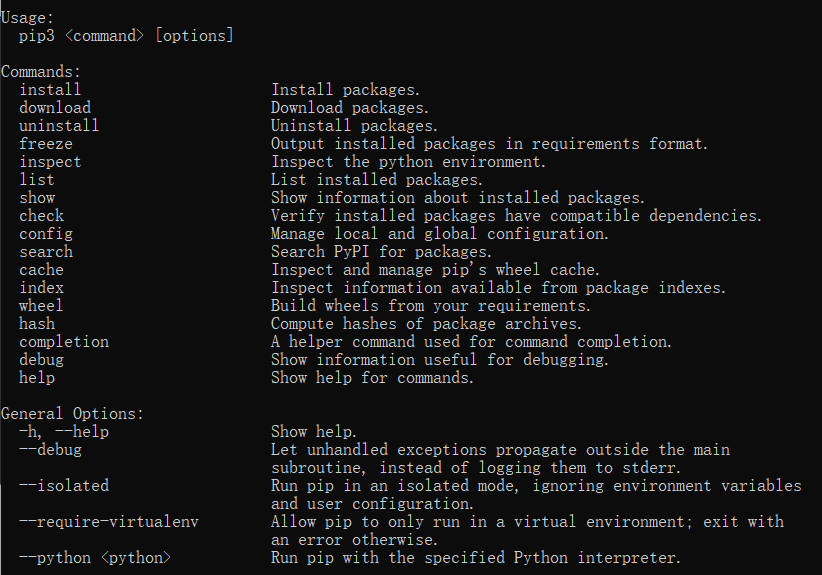
-
pip安装第三方包
selenium:是做web的自动化测试的工具
pymysql:是在python中处理数据库的包,连接数据库、对数据库进行增删改查等操作
基本命令1:默认安装最新版本:pip install 包名
pip install selenium
pip install pymysql
基本命令2:指定版本进行安装:pip install 包名==x.y.z
pip install pymysql==1.0.2
基本命令3:临时指定指定镜像服务器下载:pip install 包名-i http://mirrors.aliyun.com/pypi/simple/
国内常用的镜像源服务器有:
-
清华:https://pypi.tuna.tsinghua.edu.cn/simple
-
阿里云:http://mirrors.aliyun.com/pypi/simple/
-
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
-
华中理工大学:http://pypi.hustunique.com/
-
山东理工大学:http://pypi.sdutlinux.org/
-
豆瓣:http://pypi.douban.com/simple/
基本命令4:永久配置镜像源服务器下载
在C:\Users\用户名目录下创建pip的文件夹。
在pip文件夹下创建一个txt文本文件,重命名为pip.ini文件
编辑文件内容:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host=pypi.tuna.tsinghua.edu.cn基本命令5:批量安装包
提前准备一个reqirement.txt的文件。格式要求如下
pymysql==1.1.0 selenium==4.12.0pip install -r reqirement.txt
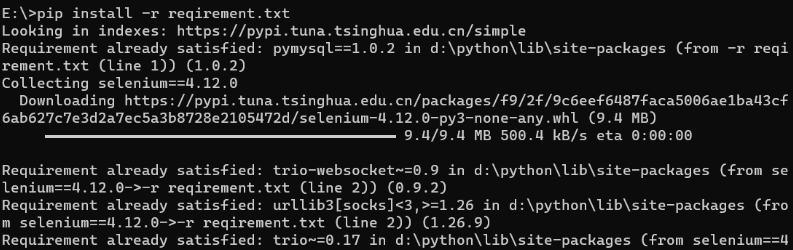
-
-
pip查看安装的包
基本命令:pip list
-
卸载包
基本命令:pip uninstall 包名
pip uninstall pymysql
-
三、Python运行原理
-
编译型语言
-
需要对高级语言的源代码(.java.c等)进行一次完整的编译,如果编译通过就生成计算机可识别字节码,可以运行字节码;如果失败就不能运行。
常见的编译型语言有:java,C,C++语言。
-
-
解释型语言
由解释器对源代码(.py)进行逐行解释、并运行的过程。
常见的解释型语言:python\php\ruby语言等。
-
运行原理
- 先创建一个xx.py结尾的python源码文件
- cmd—》python xx.py:由python解释器解释源码为字节码
- 执行字节码输出结果
-
Python字符集
Python源文件是utf-8字符集格式。
utf-8是一种可变长度的unicode编码。
Python基础语法
一、关键字
在python语言中,给特定的单词赋予了特定的功能、含义,这些单词就称为关键字。
在高级IDE编译器中,关键字会以不同的颜色标注。

- 数值类型的关键字:False、True、None
- 逻辑控制类:if、elif、else、for、while、break、continue、return
- 类、方法创建:class、def
- 异常处理:try、except、finally
- 导包:import、from、as
二、标识符
标识符是给python中的变量、方法、类等取的名字。
标识符定义的要求:
- 见名知意:age、name、gender等
- 通过下划线连接多个单词:student_name、studentAge
- 必须是由数字、字母、下划线组成,不能以数字开头
- 标识符不能是关键字
- 标识符大小写敏感的:age、Age
三、python中的注释
注释是python中的不可执行代码,有三种注释类型
-
单行注释:对变量或每一行代码做注释,方便理解,使用#号进行单行注释
-
多行注释:使用的是’‘’xxxx‘’‘或者”“”dddd“”“
-
文档注释:在方法中的第一行位置使用‘’‘xxxxx’‘’,“”“xxxxx”“”作为文档注释
文档注释,也叫文档字符串,是python特有的一种用法。
可以通过方法名**.__ doc __**来获取文档注释的内容。
四、行和缩进
-
缩进
缩进是python中特有的一种确定代码块、作用域范围的用法。
相同缩进的代码属于同一代码块,具有相同的作用域范围。
缩进一般采用4个、8个空格,也可以是一个tab键
-
行
一行内建议写一条语句,python中的语句是不需要分号结尾的。
一条语句是可以写在多行的,多行语句写法,通过反斜杠\实现多行。
对于python中带了{}、[]、()数据类型,直接多行显示不用反斜杠也可以
五、输入输出方法
-
输入方法
从键盘输入数据到代码中,使用input()方法,返回的是字符串格式的数据。
-
输出方法
使用print()将数据输出到控制台
-
导包
import 包名/模块
from 包名/模块 import方法名
六、数据类型
python是一种弱类型语言,指的是定义变量的时候不需要指定数据类型。
-
变量
代码运行过程中,其值会发生改变的量,称之为变量。
在python中使用“”,‘’定义字符串数据类型。
name=“red” name=“blue”-
name是变量,是标识符。
-
“red”和“blue”是字符串常量(不会变),一般存储在常量池中,每个常量都有自己独立的首地址。
-
name=“blue”:变量name指向常量blue的首地址;给变量name赋值blue
-
变量的定义格式:变量名=初始化值
- 变量不需要声明(不需要指定数据类型),给什么数据就是什么类型(其类型是变量指向的初始化值的类型)
- 创建变量必须进行初始化。初始化才能创建
- =是一个运算符号,赋值、指向
- 一般一行内创建一个变量,也允许一行创建多个变量
aa=bb=cc=12
a,b=12,23
print(a)
print(b)
a,b=b,a
print(a)
print(b)
# 输出
12
23
23
12
python中有几大数据类型:
- 数值类型
- 整数
- 小数
- 复数
- 布尔类型:True、False
- 序列类型
- 字符串类型
- 元组
- 集合
- 字典类型
1、数值类型
- 整数类型
python整数没有长度限制,想存多大就多大,而且数据都是准确的。
- 浮点型数据
浮点型数据是保留17位的精度,17位以后数据不再准确
# 定义一个浮点型数据
salary = 12000.12
print(salary)
输出:12000.12
# 浮点型数据是保留17位的精度,17位以后数据不再准确
salary2 = 1.12345678901234567890
print(salary2)
输出:1.1234567890123457
# 使用科学计数法来写:2*e^2
salary3 = 2e2
print(salary3)
输出:200.0
-
布尔值
只有True和False
# 定义布尔类型数据
flag=False
print(flag)
- type()方法的使用
# 使用type()方法可以识别变量的数据类型
# python一切皆是对象,数据类型也是对象
print(type(age))
# <class 'int'>
print(type(salary))
# <class 'float'>
print(type(flag))
# <class 'bool'>
score = int(input("请输入你的成绩:"))
# <class 'str'>
# 数字类型的字符串是可以强转为整数的
print(type(score))
# <class 'int'>
-
进制和进制转换(了解)
进制:进位的方式,逢几进一就是几进制数据。
常见的进制有:
- 二进制:是由0、1组成,逢2进1,是由0b开头
- 八进制:由0、1、2、3、4、5、6、7组成,逢8进1,是0o开头
- 十进制:由0、1、2、3、4、5、6、7、8、9组成,逢10进1
- 十六进制:由0、1、2、3、4、5、6、7、8、9、a、b、c、d、e、f组成,逢16进1,由0x开头
其他进制转10进制的算法:8421码转化
二进制转十进制::01010101=1+0+4+0+16+0+64+0=85
八进制转十进制: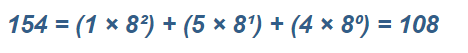
十进制转其他进制:十进制数据除以2,整除取余数,直到除尽,余数反转就是二进制
25对应的2进制数据为:11001
-
python中提供了由10进制转为其他进制的方法:
bin():转二进制(B)
oct():转八进制(O/Q)
hex():转十六进制(X)
int():转十进制
-
常见数值数据处理的方法
主要讲了math模块和random中的方法使用
# math模块实现算术运算
import math
# 查math模块的用法,有哪些方法可以用
print(abs(-12)) # 绝对值
print(math.floor(12.3)) # 向下取整数
print(math.ceil(12.3)) # 向上取整数
print(math.pi) # 圆周率
print(math.sqrt(4)) # 开根号
print(math.sin(math.pi / 6)) #求sin30°的值
import random
# 用于处理随机数的
randzhengshu=random.randint(1,9999)
print(randzhengshu)
2、字符串
-
字符串的定义
''' 1、python3中的字符串都是unicode编码的 2、字符串是以""或者''来定义的 3、字符串是不可变的一种数据类型 4、python的字符串中可以通过\实现转义 5、在字符串前面添加r或R起到取消转义的功能(也称之为自然字符串) ''' name = "测试王同学" teacher_name = 'alle\n' teacher_name = 'alle\tn' teacher_name = 'alle\\tn' print(teacher_name) teacher_name4 = r'alle\n' teacher_name5 = R'alle\n' print(teacher_name4) print(teacher_name5) -
编码、解码和乱码的概念
编码:采用指定字符集将字符转为字节码的过程,使用的方法是encode()
解码:采用指定的字符集将字节码转为字符的过程,使用的decode()
乱码:同一个字符,采用不同的编码和解码字符集进行操作,就会出现乱码的情况,建议编码和解码使用相同字符集
# 将好这个中文使用gb2312编码为字节码:b'\xba\xc3' print("好".encode("gb2312")) # 将好这个中文使用utf-8编码为字节码:b'\xe5\xa5\xbd' print("好".encode("utf-8")) a = b'\xba\xc3' # 将a变量对应的整数,解码成汉字 print(a.decode('gb2312')) b = b'\xe5\xa5\xbd' # 将a变量对应的整数,解码成汉字 print(b.decode('utf-8')) # 使用gb2312编码“小”这个汉字 print("小".encode("gb2312")) c = b'\xd0\xa1' print(c.decode("gb2312")) print(c.decode("utf-8")) # С -
字符串的格式化输出
%s:字符串占位符
%d:整数占位符
%f:浮点数占位符
%m.nf:限制宽度和精度的浮点数占位符
# 字符串的格式化输出
print("软件测试")
# %s:表示字符串的占位符
name = input("输入课程姓名:")
age = int(input("请输入课程号:"))
price = float(input("请输入价格:"))
print("我的课程是:%s,课程号是:%d,价格是:%10.2f元" % (name, age, price))
print("我的老师的名字:{}".format(age))
- 常见的字符串处理方法
# 字符串处理的常见方法(函数)
# 可以通过索引号取每个字符,有正向索引(0~总长度-1)和反向索引(-1到-总长度)的使用
# 取值的格式:字符串变量名[索引号]
# 索引号不能越界
teacher_name=" 测试blue老师 "
name="bluE"
print(teacher_name[-2])
# 获取a字符所在字符串中的索引号
print(teacher_name.index("a"))
#去除字符串中空格的用法
print(teacher_name.rstrip())
print(teacher_name.lstrip())
# 将name的值首字母大写
print(name.title())
print(name.upper())
print(name.lower())
#按照固定的格式拆分字符串
phone="186-1234-4567"
print(phone.split("-"))
数值和字符串是属于最基础的两种类型,是属于最终的数据展示格式。
3、序列
序列是多个相同特点数据类型的统称,包括字符串类型、列表和元组类型
序列类型特点:
- 有序,按照存入的顺序取出数据
- 可索引,通过下标获取指定索引对应的元素
- 可切片,从大的字符串切出多个子串的用法
- 可重复,元素是可以重复的
序列通用的运算符:
- in/not in:成员运算符,格式:xxx in序列。
- not in
- +:拼接序列
- *:复制序列
- [索引号]:通过索引获取数据
- [start:end:step]:切片
# 定义一个字符串序列
name = "blue"
# 有序
print(name)
# 可索引
print(name[0])
# in/not in:成员运算符号
print("a" in name)
print("aa" in name)
print("ll" in name)
# + : 作为序列拼接功能使用
role = "老师"
shenfen = name + role
print(shenfen)
# * : 复制序列
print("blue" * 2)
print(name * 2)
# 都可以切片,格式:序列名[start:end:step],step默认是1,start和end指的是索引号
# []中至少出现一个:才叫切片
# start和end是左闭右开[1,10),可以取到start对应的值,但是取不到end对应的值
print(shenfen[0:3])
print(shenfen[0:7])
print(shenfen[0:8])
print(shenfen[:]) # 切所有
print(shenfen[::1])
print(shenfen[::2])
print(shenfen[::-1])
print(shenfen[-7:-1])
print(shenfen[-7:])
序列通用的方法:
序列类型也叫容器类型,其中有多个元素!!
- len(序列名):计算一个序列的长度、元素的个数
- 序列名.index(x)
- max(序列名)
- min(序列名)
- 序列名.count(x)
# shenfen变量元素个数是多少?
print("shenfen变量的元素个数(长度):%d个"%len(shenfen))
# 序列中的最大值和最小值
print(max(shenfen))
aa = "aAbB"
print(max(aa))
print(min(aa))
# 将字符转为整数
print(ord("a"))
# 将整数转为字符串
print(chr(65))
print(ord("老"))
print(ord("师"))
bb = "123456"
print(max(bb))
print(min(bb))
# index(x)获取指定子串x在大串中的索引号,找不倒指定的子串就会报错
shenfen = "blue老师"
print(shenfen.index("b"))
print(shenfen.index("老"))
print(shenfen.index("老师"))
# index(x,start,end) : 在指定的范围内查找指定子字符串x的索引号
print(shenfen.index("老",4,7))
# count(): 统计序列中指定元素的个数
print(shenfen.count("a"))
print(shenfen.count("l"))
print(shenfen.count("ll"))
4、序列—字符串
- 字符串是序列,有序、可索引、可切片、可重复、不可被改变。
- 在查询字符索引的find()方法–对比index()方法。
- 在查不到指定的元素的时候返回-1,查到就返回索引,其他的用法和index()相同。
# find()的使用--只能使用于字符串类型(序列和元组不能用)
print(shenfen.find("a"))
print(shenfen.find("l"))
print(shenfen.find("ll"))
print(shenfen.find("老师"))
print("~~~~~~~~~~~~~~~~~~~~~~~~~~")
print(shenfen.find("abc"))
print(shenfen.find("老",4,7))
5、序列–列表
-
列表是一个容器类型,通过[]和,来定义,其元素可以是任意类型(数字、列表、字符串、字典、元组等)。
-
列表的特点:有序、可索引、可切片、可重复、可改变
-
列表的index和remove方法在找不到元素时,运行时会报错,而不是像其他语言一样返回-1,或者什么也不做。因此,使用index和remove方法,更好的方式是像下面这样。
a = [10, 20, 30] index = a.index(66) if 66 in a else -1 # 输出:-1 print(index) if 20 in a: a.remove(20) # 输出:[10, 30] print(a)
-
定义列表
list=[1,2,3,4,5,6]
list2=[“blue”,’王同学’,’rourou’]
info=[[“blue”,28],[“王同学”,25],[‘rourou’,23]]
list1 = [1,2,3,3,4,5,6]
list2 = ["blue",'王同学',"rourou"]
info = [["blue",28],["王同学",25],["rourou",23]]
# 列表是有序的
print(list1)
# 列表可索引(正向和反向索引)
print(list1[0])
print(list1[-1])
print(info[2][0])
# 可切片
print(info[:])
print(info[1:])
print(info[::-1])
# 可改变:改变变量中元素
# print(id(list1))
# list1[0] = 12
# print(list1)
# print(id(list1))
# str1 = "abc"
# print(id(str1))
# str1 = "cba"
# print(id(str1))
# + *
print(list1+list2)
print(list1*2)
print("-----------------------------------")
print("-"*30)
-
列表的常见方法
-
给列表追加元素,追加在列表的最后位置-append()
list2 = ["blue",'王同学',"rourou"] list2.append("张同学") print(list2) -
给列表插入元素,按照指定的位置插入一个元素-insert()
list2.insert(2,"张同学") print(list2) list2.insert(0,"张同学") # print(list2) list2.insert(2,["张同学",20]) # ['blue', '王同学', ['张同学', 20], 'rourou'] print(list2) -
将一个列表中的所有元素加到另外一个列表中-extend()
#['blue', '王同学', 'rourou', '张同学', 20] list2.extend(["张同学",20]) print(list2) -
给列表删除元素
-
删除最后一个元素-pop(),给参数,给哪个索引号,就删除哪一个值
print(list2.pop(4)) # 不带参数的话默认删除最后一个元素 print(list2.pop()) print(list2) -
根据指定的值删除元素-remove(x)
print(list2.remove(20)) print(list2) print(list2.remove("blue")) print(list2) -
使用del 删除指定索引号的元素
del list2[4] print(list2) -
使用切片删除元素
list2[3:]=[] print(list2)
-
-
修改列表元素
list2[0] = "blue老师" print(list2) -
查列表元素\元素索引
print(list2[1]) print(list2.index("王同学")) -
其他方法:
index() count() reverse():逆序 info.reverse() print(info) print(info[::-1]) print(info)
-
6、序列–元组
元组是一种序列类型,有序、可索引、可切片、可重复、不可被改变(和字符串类似)
-
元组定义:(),但是括号中至少要有一个逗号
# 定义元组 tuple1 = (12,) # 定义一个空的元组 tuple2=tuple() print(type(tuple2)) print(tuple2) -
元组的特点
# 元组的特点 tuple3 = (12,23,4,5,5,6,7,8,[66,88]) # 有序、可重复 print(tuple3) # 索引和切片 print(tuple3[0]) print(tuple3[-1]) print(tuple3[:]) print(tuple3[0:5]) # 不可变 tuple3[0]=1 # ‘tuple' object does not support item assignment # tuple3[-1][0]=12 print(tuple3) -
元组的运算符和方法
print(tuple3+tuple1) print(tuple3*2) print(len(tuple3)) print(tuple3.index(23)) # 求数据的索引 -
注意事项
列表可用于需要进行数据动态维护的场景;元组用于敏感型数据的存储(不能随便改)
字符串是最常用的数据载体,是数据的最终载体,用于数据的磁盘存储、网络传输等
列表和元组是容器存储的能力,
不管是列表、元组还是字符串,都可以通过索引偏移获取元素、切片。
7、set集合
-
set集合特点:无序、不可重复
-
set集合的创建
# 定义set集合 # 使用{}来定义 set1 = {12, 23, 34, 5, 6, 6} set2 = {"a", "aaa", "sds"} print(set1) print(set2) # 定义一个空的set集合 set3 = {} set4=set() print(type(set3)) print(type(set1)) print(type(set4)) -
集合运算
set5={1,2,3,4,5} set6={4,5,6,7} # 差集运算 print(set5-set6) # 并集 print(set5 | set6) # 交集 print(set5 & set6)
8、字典
字典是python中以键值对作为元素的一种数据类型。
其中的键是无序的,不能重复,值可以是任意其他的数据类型
使用{}定义,键:值组成其元素,多个键值对之间用逗号分隔。
-
字典的定义
#字典的定义 dict1={} # 键是不可变的数据类型,可以是字符串、整数、元组等 dict2={"王同学":"张同学","文章":"马伊琍","邓超":"孙俪","张杰":"谢娜","文章":"姚笛"} print(dict2) # dict3={["aa","bb"]:12} dict3={(12,23):12} dict3={12:23} print(dict3) # unhashable type: 'list' -
字典的常见用法
-
查看字典中某个键的值
print(dict2["文章"]) print(dict2.get("文章")) print(dict2.get("鹿晗")) # 查看字典中的所有的键\值\键值对 print(dict2.keys()) print(dict2.values()) print(dict2.items()) -
修改和更新功能
# 更新、增加键值对到字典中 dict2["黄晓明"]="小海绵" print(dict2) # dict2["鹿晗"]="关晓彤" # print(dict2) dict2.update({"鹿晗":"关晓彤"}) print(dict2) -
删除字典的键值对
# 删除字典中的键值对-pop() dict2.pop("邓超") print(dict2) -
补充两个字典的创建方法(了解)
# 补充两个创建字典fromKeys() dict6={}.fromkeys([1,2,3,4]) print(dict6) #通过dict() a=[1,2,3,4] b=[5,6,7,8] dict7=dict(zip(a,b)) print(dict7)
-
9、Python中的数据类型转换
# 定义两个字符串
x='12'
xx='12.23'
# 将x转为整数
a=int(x)
aa=float(xx)
print(type(a))
print(type(aa))
s=str(a)
ss=str(aa)
print(type(s))
print(type(ss))
# 字符串、列表、元组之间的转换
str1='abcdef'
# 字符串转列表
list1=list(str1)
print(list1)
print(type(list1))
#字符串转元组
tuple1=tuple(str1)
print(tuple1)
print(type(tuple1))
# 列表转元组
list2=[12,23,4,5,6,7,7,'aa',[12,4]]
tuple2=tuple(list2)
print(tuple2)
print(type(tuple2))
#eval()的用法
str3='1+1'
print(eval(str3))
七、运算符
- a=1+2
- a=1+2:一条赋值语句
- 1+2:加法表达式
- 1、2:运算数
- +、=:运算符
- a:变量
-
算术运算符
+:加法、正号、序列拼接
# + print(4+6) print(+4) print('a'+'b')-:减法、减号
*:乘法、序列复制
/:除法、精确除法
//:取整除法
# * print(2*4) print("aaan"*2) # / print(4/2) print(3/2) # // : 取整 print(4//2) print(3//2)%:取余、取模运算
**:幂运算
# % print(4%2) print(3%2) # ** print(3**2) -
比较运算符
结果一定是True和False
==:判断是否等于
>
<
>=
<=
!=
a = 12 b = 23 c = 34 print(a==b) print(a!=b) print(a>b) print(a<b) print(a>=b) print(a<=b) # python中的特殊用法 print(a<b<c) -
赋值运算符
=
+=:a+=2相当于a=a+2
-=
*=
/=
**=
//=
%=
d = 12 d += 2 print(d) -
逻辑运算符
参与运算的运算数可以是布尔值,结果是布尔值
and:x and y
x是True,y是True,结果是True
x是False,y是True,结果是False
x是True,y是False,结果是False
x是False,y是False,结果是False
or:x or y
x是True,y是True,结果是True
x是False,y是True,结果是True
x是True,y是False,结果是True
x是False,y是False,结果是False
not: not x
x是True,结果是False
x是False,结果是True
print(True or False) print(False and False) print(not False) print(a>b and b<c) print(a<b and b<c) -
位运算
python的位运算(二进制位),整数都要转为二进制补码进行运算。
二进制的最高位是符号位:0表正数、1表示负数
- 原码:直接将整数转为二进制
- 反码:正数反码和原码相同;负数原码转反码:除了符号位不变,其他位上0变1、1变0
- 补码:正数的补码和原码也相同;负数反码转补码:除了符号位不变,反码最后一位加1,补码就可以参与运算了
- 反码:正数的补码和原码相同;负数补码转反码:除了符号位不变,补码最后一位减1
- 原码:正数的补码和原码相同;负数反码转原码:除了符号位不变,其他位上0变1、1变0,原码就可以在控制台显示了
&:位于运算,x&y,60&13
同为1,结果为1,否则结果为0
60&13 60的原码:00000000 00111100 60的反码:00000000 00111100 60的补码:00000000 00111100 13的原码:00000000 00001101 13的反码:00000000 00001101 13的补码:00000000 00001101 60的补码&13的补码: 00000000 00111100& 00000000 00001101 60&13的补码:00000000 00001100 60&13的反码:00000000 00001100 60&13的原码:00000000 00001100--->12|:位或运算
同为0,结果为0,否则结果为1
60|13 60的原码:00000000 00111100 60的反码:00000000 00111100 60的补码:00000000 00111100 13的原码:00000000 00001101 13的反码:00000000 00001101 13的补码:00000000 00001101 60的补码|13的补码: 00000000 00111100| 00000000 00001101 60|13的补码:00000000 00111101 60|13的反码:00000000 00111101 60|13的原码:00000000 00111101--->61^:异或运算
相同为0,不同为1
60^13 60的原码:00000000 00111100 60的反码:00000000 00111100 60的补码:00000000 00111100 13的原码:00000000 00001101 13的反码:00000000 00001101 13的补码:00000000 00001101 60的补码^13的补码: 00000000 00111100^ 00000000 00001101 60^13的补码:00000000 00110001 60^13的反码:00000000 00110001 60^13的原码:00000000 00110001--->49~:取反
把补码数据按位取反,0变1,1变0
60~13 60的原码:00000000 00111100 60的反码:00000000 00111100 60的补码:00000000 00111100 13的原码:00000000 00001101 13的反码:00000000 00001101 13的补码:00000000 00001101 ~60的补码:11111111 11000011 ~60的反码:11111111 11000010 ~60的原码:10000000 00111101--->-61右移运算:>>
把二进制数据整体向右侧移动指定的位数,右侧的数据直接删除,左侧补0
往右侧移动一位,相当于除以2
8/2=4
8>>1
左移运算:<<
2<<3是2*8的最高效算法
往左侧移动一位相当于乘以2,移动2位相当于乘以4
-
成员运算符
一般用于序列数据中,检查元素是否是序列的成员
in,not in
-
身份运算符
判断两个变量的地址是否相同。
is,is not
相当于判断两个变量的**id()**值是否相同
baobao = "blue" wang = "blue1" blue = wang print(baobao is wang) print(baobao is not wang) print(id(baobao)) print(id(wang)) print(id(allen))
八、控制语句
1、if语句
if是一种分支、选择语句,需要对指定的条件表达式的值确定具体选择哪一个分支。
python的分支语句中没有switch–case语句。
方法1:只有一个选择
if(条件表达式):
if语句代码块
..
...
#if语句
choice=input("我选择了学科:")
if(choice=='软件测试'):
print('学好软件测试,登上人生巅峰!')
print('if语句结束!')
方法2:有一个条件,但是有不同的选择
if(条件表达式):
if语句代码块
...
...
else:
else语句的代码块
....
方法3:多条件选择
if(条件表达式1):
if语句代码块1
elif(条件表达式2):
if语句代码块2
elif(条件表达式3):
if语句代码块3
else:
else语句代码块
方法4:if语句嵌套(了解)
if(条件表达式1):
if代码块1
if(条件表达式2):
if代码块
else:
else代码块
else:
else代码块
if(条件表达式3):
if代码块
else:
else代码块
2、for循环语句
循环语句代码块是可以循环运行的,专门的条件来限制循环的次数。
可以使用序列作为循环次数控制的结构
for循环中可以跟序列或者字典、range()方法
for循环的语法结构:
for 变量 in 序列类型数据:
循环代码块
for循环语句的作用:
- 从字符串、列表、元组、字典中遍历取出元素
- 利用序列的元素个数,来控制循环次数
- range(start,end,step):效率比序列和字典要高
3、while循环
基本语法格式:
条件表达式为True,则执行代码块语句
条件表达式为False,则退出while循环语句
while(条件表达式):
代码块(要有调整条件表达式值的雨具)
...
else:
else代码块
# 当条件表达式为False的时候才能执行这一句
print("结束while循环到此处了")
4、其他控制语句
break:跳出(结束)for、while循环,遇到break则直接结束后续所有循环
continue:继续,结束当次循环,继续进入下一次循环
九、函数与方法
一、函数的定义
- 函数的作用:封装具有特定功能的代码块,提高代码的复用性
- 使用关键字def来定义函数,后面跟函数名标识符()
- Python中的返回值一般是通过return关键字带回的,如果不写返回None,可以返回一个值,也可以同时返回多个值,结束方法(后续的代码不在执行)
- 函数是设计出来的,在拿到需求之后,动手写函数之前,要分析两个内容
- 要不要参数?要几个参数?
- 要不要返回值?返回什么?
不带参数:def 函数名():
函数代码块
return 返回值
带参数:def 函数名(变量1,变量2….):
函数代码块
return 返回值
二、方法的调用
方法不调用不执行,只有调用了才能执行其中的功能。
-
有返回值方法的调用
三种调用方法的格式:方法名(参数列表)
- 直接调用:直接写方法名(),没太大作用
- 赋值调用:比较灵活,方法的返回值可以参与后续的运算
- 输出调用:一般是返回值可能只会用到一次的情况
def sum(num1, num2): c = num1 + num2 return c print(sum(1, 2)) # 赋值调用,把方法的返回值赋值到一个变量中,可以参与后续的运算了 s = sum(12, 21) print(s + 1) -
无返回值方法的调用
建议直接调用方法即可:方法名(参数列表)
# 控制台上打印99乘法表功能,设计成一个方法 def ninenine(): # 实现99乘法表的输出功能 for row in range(1, 10): for col in range(1, row + 1): print(f'{row}*{col}={row * col}', end=" ") print() # 不建议使用输出调用\赋值调用 # print(ninenine()) # 直接调用即可 ninenine()
作业1:定义一个方法,实现百钱买百鸡的案例
作业2:定义一个方法,输出n*n乘法表
# 作业1
def money():
for x in range(0,101):
for y in range(0,101):
for z in range(0,101):
if(x+y+z==100 and 5*x+3*y+z/3==100):
print(f'公鸡{x}只,母鸡{y}只,小鸡{z}只')
money()
# 作业1
def kun():
count = 0
for x in range(21):
for y in range(34):
z=100-x-y
if(x*5+y*3+z/3==100):
count+=1
# print(f'公鸡{x}只,母鸡{y}只,小鸡{z}只')
# print(f'共有{count}种购买方案')
return count
print(kun())
# 作业2
n=int(input('输入一个数字:'))
def ninenine(n):
for row in range(1, n+1):
for col in range(1, row+1):
print(f'{row}*{col}={row * col}', end=" ")
print()
return '-'*30
print(ninenine(n))
三、函数的参数类型
常见的参数类型:
- 位置参数:按照在括号中顺序传参
- 关键字参数:按照参数名=值的方式传参
- 默认值传参:参数是有默认值的,可以不用给实参,自带值
- 不定长参数:可以接受多个参数
-
位置参数
位置参数使用的特点:
- 必须按照函数定义时候的参数个数和参数顺序传参。
- 多了、少了都会报错。
- 顺序反了,虽然不报错,但是可能结果是不对的
-
关键字参数
把形参名作为一个关键字在使用,实现指定名字传参
- 关键字参数后面不允许出现位置参数(直接语法就是错误的)
- 位置传参后面可以跟关键字参数,但是要注意别冲突
- 建议按照每个关键字分别传参。解决了传参的顺序问题
- getinfo(name=‘blue’,age=28)
- getinfo(age=28,name=‘blue’)
-
默认值参数
在定义函数的时候可以直接给形式参数赋值(guoji=‘中国’),在后续调用的时候:
如果指定guoji参数,就以指定的实参为准
如果不指定guoji参数,就以默认值为准
# 定义一个方法,输出学生信息 def printInfo(name,age,gender,guoji='中国'): print('学生的姓名为%s,年龄为%s,性别为%s,国籍为%s!!!'%(name,age,gender,guoji)) printInfo('blue','28','男','china') printInfo('blue','28','男') # 这个是前面见过的典型的默认值参数的使用 print('',end='\n') -
不定长参数
在定义函数的时候,不确定调用函数的时候会传几个实际参数进来,这种场景下可以使用不定长参数。
-
*args
args是将传入的多个实参先保存在一个元组中,如果想使用再从元组中遍历出来。
# *args是将传入的多个实参先保存在一个元组中,如果想使用再从元组中遍历出来。 # 定义一个方法,args是一个元组类型 # 先存数据到元组中 # 再取出来使用 def sum(*args): # print(type(args)) # <class 'tuple'> # print(args) aa=0 for i in args: aa+=i return aa # 传一个值 print(sum(12, 12, 2342, 3423, 9))-
**kwargs
kwargs是将传入的aa=bb格式的实参,保存在kwargs字典中,如果要使用就需要从字典中把数据遍历出来。
# **kwargs:是以键值对的形式接收实参,然后存储在一个字典中 def ssum(**kwargs): # print(type(kwargs)) # <class 'dict'> # print(kwargs) bb=0 for ii in kwargs.values(): bb+=ii return bb print(ssum(a=12, b=12)) -
十、面向对象
1、几个概念
- 面向对象和面向过程
- 面向过程:一般是通过方法来封装固定功能代码块,C语言是一个面向过程的语言,不断写方法,方法之间相互调用实现某个复杂的功能
- 面向对象:是对面向过程的再一次封装,包括方法和属性。不断地写类,通过类创建不同的对象,通过对象调用不同的方法。
- 面向对象的开发中把对象作为最基本的单位,面向过程的最基本单位是方法
- 面向对象中需要包含数据(属性)和处理数据的方法(行为)
- 类和对象
- 类:是抽象的概念,是从大量的具体事务中抽象出来的,应该包括方法和变量
- 对象:是具体的概念,是由类实例化出来的,都有自己特定的属性和行为。
- 实例化:通过类创建对象的过程(抽象到具体的过程)
- 方法和变量
- 方法和变量其实是对具体的对象的行为和属性的抽象
- 实例方法:其实就是类中的方法
- 实例变量:类中方法中定义的变量、而且以self.开头的变量就是实例变量,是每个对象独有的属性值
- 类变量:类中方法外的变量,属于类的,类的所有实例(对象)都有这个属性
- 局部变量:类中方法中定义的变量,作用域只能是在该方法中,出来方法代码块就被注销
2、类的创建
-
类的格式
-
class:是创建类的关键字
-
class 类名():
类体
-
类名:是一个标识符,便于调用、引用
-
类体:
- 方法:和前面讲过的方法差别不大,第一个参数必须有,而且必须是self
- 变量(实例变量、类变量、局部变量)
-
-
创建一个类
- 创建类从具体的事务、对象到抽象的类的过程。
- 对班级内十位同学进行分析,共同的属性和行为:
- 属性:年龄、姓名、国籍、性别、学号、身高、体重……
- 行为:吃饭、睡觉、学习、玩游戏、看视频、唱歌…….
- 将属性和行为定义为类中的变量和方法:
- 实例变量:年龄、姓名、性别、学号、身高、体重……
- 类变量:国籍
- 局部变量:学习时间长度,是学习这个行为中的一个属性
- 实例方法:吃饭、睡觉、学习、玩游戏、看视频、唱歌…….
-
对象的创建
- 格式1:对象名=类名()
- 格式1:对象名=类名(参数1,参数2……)
-
调用方法和变量
- 调类变量
- 类名.类变量名=‘值’—>当前对象及使用该类定义类,其他对象的该值都发生了改变
- 对象名.类变量名—>其实是该对象创建了一个自己的和类变量同名的实例变量,只改变的是自己的值,不影响其他对象的类变量值
- 调成员变量
- 对象名.实例变量名
- 方法的调用
- 对象名.方法名()
- 对象名.方法名(参数1,参数2….)
- 调类变量
-
构造方法
Python中构造方法名_ _init _ _(self),是类中内置的一个方法,在创建对象的时候自动调用。可以无参,也可以有参数,通过参数实现对成员变量的初始化。
self:哪一个对象调用实例变量、方法,那self指的就是那个对象
- print(xiaowang.name)
- print(xiaozhang.name)
3、面向对象三大特性
三大特性:封装、继承、多态
-
封装
什么时候会用到封装?在类中某些变量、方法不希望通过对象直接访问到。
怎么实现封装?
-
把不想别人看的东西隐藏起来:只需要在变量名或者方法名的前面加上_ _
定义私有的属性age:self._ _age=20
私有属性只能在类中的方法间调用,不能通过对象调用
-
并且要提供公共访问的方法实现对变量的修改和查看
封装的两个类型:
- 私有化变量:self._ _age=20
- 私有化方法:def _ _play()
-
-
继承
父类:也叫基类、超类,把大量的类的共同/相同的属性和行为,提取出来,封装在另一个类中。这个类就是父类。
子类:也叫派生类,上面所提的大量的类
这种子类和父类之间就存在着一种继承的关系。
重写:子类重新改写父类的同名方法,子类对象调用方法使用的是重写后的子类的。
格式:
class 子类名(父类名):
子类的特有的属性和行为
-
Python中继承的特点
- 支持单继承
- 支持多继承
- 支持多层继承
# 单继承 class yeye(): piqi='脾气大' def play(self): print('下棋') class mu(): yanzhi='温柔漂亮' def hobby(self): print('爱好逛街') class fu(yeye): zhangxiang='英俊潇洒' def play(self): print('父亲喜欢打篮球') class zi(fu,mu): pass z = zi() print(z.zhangxiang) z.play() print(z.piqi) z.hobby() print(z.yanzhi)
-
-
多态
Python中的多态是鸭子多态。
Python中的多态不要求有继承关系。
多态是指一个对象在不同的时候展现不同的形态:
一只小花猫对象是只猫
一只小花猫对象是只动物
十一、模块
1、模块的概念
Python中以.py结尾的文件称之为模块。
- 便于管理代码
- 把相同、类似功能逻辑的代码封装在一个模块中,便于使用
- 模块中可以封装方法、类、变量及可执行代码
- 创建模块
# 定义一个方法
def printInfo():
print('热爱生活')
class phone():
def call(self,phoneNo):
print(f'打电话给{phoneNo}')
# 调试代码放在这
mate60 = phone()
mate60.call('15712345678')
# 整体作用:起到调试作用,只限制在本模块中执行
# __name__:是模块中内置的一个变量,在本模块中运行的值是__main__
if __name__=='__main__':
# 调试代码都要放在这个位置
print(__name__)
printInfo()
print('在当前模块中运行代码!!')
else:
print(__name__)
print('在其他模块中运行代码!!')
-
使用模块
写了模块一般不是在本模块中使用的,也不是所有的功能都定义在一个模块中的,只有通过模块之间的相互调用才能形成一个复杂的程序
使用两个关键字from、import
通过导入模块,就可以使用模块中定义的功能了(方法和类了)
包:是包括了_ _init _ _.py模块的一个文件夹,使用它带包导入模块:包名.模块名
-
import xx模块
-
from xx模块 import xx方法,xx类
-
-
理解if_ _name _ _==“ _ _main _ _”语法
就是一个普通的if语句,重点是理解 _ _name _ _变量的值的变化。
-
_ _name _ _:在当前模块下运行等于 _ _main _ _
-
_ _name _ _:在导入到其他模块下运行等于模块名,判断条件就是False
-
-
导模块的原理
Python在遇到import、from import的时候会做几件事:
- 检查sys.path返回的列表有哪些目录,找到要导入的模块
- 如果sys.path的列表中有一个目录,则该目录可以直接导入
- 如果sys.path的列表中没有指定目录,则该目录下文件不能直接导入
- 把指定的目录追加到sys.path中,就可以导了
- 将模块解释成字节码文件(pyc)
- 直接运行字节码文件了
- 注意:后续再导入相同模块的时候就不需要前两步骤了,直接从内存加载字节码文件
- 检查sys.path返回的列表有哪些目录,找到要导入的模块
2、常见的导入案例
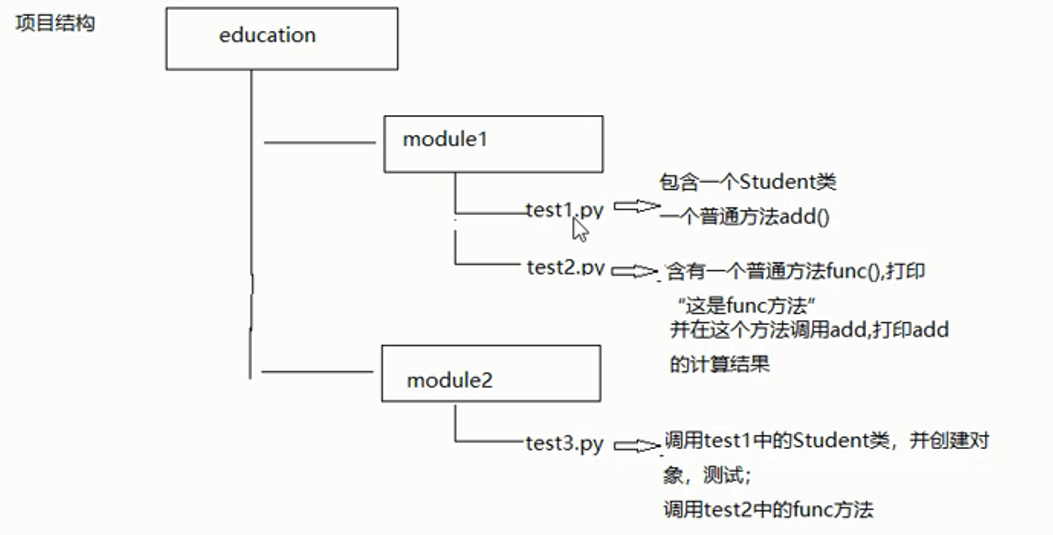
-
同一目录下的导入
直接导模块即可?sys.path中有该目录
test1中的代码
class student(): def add(self,a,b): return a+b if __name__=='__main__': s=student() print(s.add(12,23))test2中的代码
from education.module1.test1 import student def func(): print('我是func方法') s = student() print(s.add(12, 234)) if __name__=='__main__': func() -
同级别目录之间相互导入模块
test3中的代码
# 将module目录加载到sys.path列表,就可以直接导入其他的模块了 # 不能给绝对值的路径 # os模块,提供了大量的对文件夹目录处理的方法 import os import sys # os.path.dirname():获取某个目录或者文件所在的目录,也是相对的值 # os.path.abspath():将相对路径转为绝对值的表示法 # __file__:当前文件的名字 # D:\PycharmProjects\PythonDemo01\education\module2 path1=os.path.abspath(os.path.dirname(__file__)) path2=os.path.abspath(os.path.dirname(path1))+r'\module1' print(path1) print(path2) sys.path.append(path2) from test1 import student from test2 import func s=student() print(s.add(12,4)) print('-'*30) func()
3、异常和异常处理
异常:在程序运行过程中,出现错误、异常会导致程序的终止,在控制台上显示异常信息
异常是Python语言中针对某些特定的错误,设计的一个专门的类,出现了某个错误,控制台就会抛出哪一个类信息。
三个常见异常处理的关键字
-
try
-
except
-
finally
# a=1/0 # try检查代码块中的代码是否会抛出异常 try: ac=1/0 a=[1,2,3,4] print(a[3]) print('ssssssss') # 抓异常,如果抓到一个异常,则执行对应的代码块 # 体现多态的特点 # except IndexError as e: except Exception as e: # 异常处理 print(e) finally: print('不管抛不抛异常,最终都要执行finally语句')
十二、IO处理
一、Python中的IO
Python中数据的输入和输出操作(i:input;o:output)
-
input()输入方法
input():监听键盘的输入,遇到回车键,则将数据返回到代码中来,返回的是字符串。
结合一些工厂类方法进行数据类型的转换:int(input())、float(input()).
-
print()输出方法
print():输出数据到控制台,可以格式化输出
-
priint(“你好,%s”%name)
-
%s
-
%d
-
%f
-
%.4f
-
-
print(“你好,{}”.format(name))
-
print(“你好,{1},{2}”.format(name,age))
-
print(f“你好,{name}”)
-
-
pprint()
美化输出的方法。
import pprint a = {"a":1,"b":2,"c":3,"d":4} b=['1','sss',1,2,3,4,5,6] print(a) pprint.pprint(b,indent=2)
二、文件IO的用法
对文件(文本文件、csv文件、json文件、excel文件、yaml文件等读写操作)
-
基本操作流程
- 通过open()打开文件并创建文件对象
- 将文件对象加载到内存(缓存区)
- 对缓存区数据的操作
- 读
- 写
- 读写
- 对二进制文件进行读写
- 将缓存区数据重新写回到磁盘
-
文本文件的读写
创建文件对象的格式:f=open(文件的全路径,操作模式,文件的编码集合)
- 文件的全路径:建议字符串的前面加一个R/r(取消转义)
- 读写模式
- r:只读模式
- w:只写模式,覆盖写入
- a:追加模式,在文件末尾处追加数据
- r+\w+\a+都是读写模式,既能写也能读
- b:二进制的读写模式(binary)
-
数据的读取操作
- read(size):按照指定的字节读取数据
- readline():读取行
- readlines():读取多行
import time # 打开并且创建对象 f=open(r'd:\blue.txt','r',encoding='utf-8') # 读取数据 # print(f.read(15)) # print(f.read(70)) # 按照行进行读取:不加参数就是读取一行、加上参数后按照字节长度读取 # print(f.readline(5)) # 一次性读取多行,返回是多行数据为元素的列表,包括每行结尾处的换行符 # ['hello world1!\n', 'hello world2!\n', 'hello world3!\n', 'hello world4!'] # print(f.readlines()) # 获取文件数据的所有行数据的列表 # for data in f.readlines(): # print(data) # # 每隔开1s读取一行数据 # time.sleep(1) for i in range(10): print(f.readline()) # 每隔开1s读取一行数据 time.sleep(2) # 关闭文件对象 f.close() -
写入数据到文件-w
如果文件不存在,创建文件并写入
-
write():写入一个指定的字符串
-
writelines():写入多行数据,参数格式是列表
# 写入数据 f=open(r'd:\blue.txt','w',encoding='utf-8') # 写入一行 # f.write('你好,中国111') data=['hello world1!\n', 'hello world2!\n', 'hello world3!\n', 'hello world4!'] f.writelines(data) # 关闭文件对象 f.close() -
-
推荐写法(必须掌握)
with open()语法,这种语法不用去担心文件是否关闭的问题
# f参数就是打开的文件对象 with open(r'd:\blue.txt','r',encoding='utf-8')as f: print(f.read()) with open(r'd:\red.txt','a',encoding='utf-8')as f: f.writelines(['你好\n','大家好!\n'])
三、csv文件的读写
csv文件是一种非常常见的用于数据存储的文件,按照‘,’分隔的多列数据
-
创建csv文件
- excel设计数据,另存为csv文件
- 直接创建文本文件,后缀名可以改为.csv,用超级记事本工具notepad++直接写
-
读取文件内容
需要用到csv的模块,是python自带的,直接导入就可以使用了
-
写入到数据文件(掌握)
# 先导包 import csv # 打开文件 with open(r'd:\aa.csv', 'r', encoding='utf-8') as f: # reader返回csv中的数据集合 data = csv.reader(f) #<_csv.reader object at 0x000001C286C27BE0> # print(data) # 遍历读取文件后的数据对象 for d in data: print(d[2]) with open(r'd:\aa.csv', 'a', encoding='utf-8',newline='') as f: # 追加写入数据 # 创建一个写入对象 duixiangWrite = csv.writer(f,dialect='excel') # writerow():要求的参数是列表格式['xiaohei',23,'男','学生'] # writerows() # duixiangWrite.writerow(['xiaohei',23,'男','学生']) name = [['xiaohei',23,'男','学生'],['xiaohei2',23,'男','学生'],['xiaohei3',23,'男','学生']] duixiangWrite.writerows(name)
四、json类型文件的读写(掌握)
json文件是一种可读性非常好的数据结构,具体数据都是以键值对的形式给出的。
json文件是一种不依赖于任何语言的一种数据结构,但是又能被任意语言处理。可以用于不同系统/语言之间的数据传递。
json文件的数据组成:[]、{}、“”、:
使用json文件来存储一个班级的所有学员的基本信息:
[
{
"name":"张三",
"age":28,
"gender":"男"
},
{
"name":"李四",
"age":20,
"gender":"男"
},
{
"name":"王五",
"age":38,
"gender":"女"
}
]
//另外一种写法
{
"teacher":"blue老师"
"data":[
{
"name":"张三",
"age":28,
"gender":"男"
},
{
"name":"李四",
"age":20,
"gender":"男"
},
{
"name":"王五",
"age":38,
"gender":"女"
}
]
}
-
创建json文件
注意保存为UTF-8编码格式
-
在Python中进行读取
使用json中的load()方法实现数据的读取
# json是Python自带的模块,不需要安装 import json import pprint # 打开文件 with open(r'd:\blue.json','r',encoding='utf-8') as f: # 读取json数据有两个方法:load()\loads() data=json.load(f) print(data) print(type(data)) for d in data: pprint.pprint(d) -
写数据到json文件中
使用json中的dump()方法。
# 创建json文件并打开 with open(r'd:\blue2.json', 'w', encoding='utf-8', newline='\r\n') as f: # 定义要写入的数据 a = [ { "name": "张三", "age": 28, "gender": "男" }, { "name": "李四", "age": 20, "gender": "男" }, { "name": "王五", "age": 38, "gender": "女" } ] # 将上面的列表写入到json文件中 # indent:缩进,相当于tab(4个空格) json.dump(a,f,indent=1,ensure_ascii=False)
五、excel文件的读操作(了解)
使用xlrd模块对excel文件进行读操作,如果excel文件格式是xlsx文件的话,xlrd建议使用1.2.0版本。
安装时:pip install xlrd==1.2.0
-
创建xlsx文件
-
读取数据
import xlrd # 打开文件 f = xlrd.open_workbook(r'd:\aa.xlsx') #<xlrd.book.Book object at 0x00000102AFC10BD0> # print(f) # 获取excel工作簿中的指定sheet页对象 # sheet=f.sheet_by_name('Sheet1') # sheet=f.sheet_by_index(0) # 获取第一个sheet列表 sheet=f.sheets()[0] # <xlrd.sheet.Sheet object at 0x00000102B03131D0> # print(sheet) # 获取数据的行数 row = sheet.nrows col=sheet.ncols print(col) print(row) # 获取一行数据 # print(sheet.row_values(0)) # 获取所有行数据 # for i in range(row): # for j in range(col): # print(sheet.row_values(i)[j]) for i in range(row): # for j in range(col): print(sheet.cell_value(i,0))
十三、单元测试框架
一、单元测试案例
#作为单元测试的测试对象
class mathdemo():
#实现加法运算
def add(self,a,b):
return a+b
#实现减法运算
def minus(self,a,b):
return a-b
#实现乘法运算
def multi(self,a,b):
return a*b
#实现除法运算
def devide(self,a,b):
return a/b
单元测试:针对代码中最小单位进行的测试,验证其功能是否正确,覆盖率的测试类型,属于白盒测试范畴
在Python中最小的单元是类,我们要验证类中的方法的正确性
进行单元测试参考的依据是什么?详细设计文档,代码是测试对象
- 做单元测试一定要引入单元测试的框架:(好处)
- 提供了更好的、方便管理大量单元用例的方式
- 有直接用于判断用例对错的方法
- 还可以提供输出可视化的报告
- Python中的单元测试框架:
- unittest
- pytest
二、unittest框架
-
框架的组成(从下往上)
- TestCase:测试用例层,耗时最长最多的一层
- TestSuite:测试集合层,可以将不同类型的用例放到同一个集合中统一运行
- TestLoader:测试加载层,提供了大量的方法,将测试用例加载到测试集合中
- TestRunner:测试运行器层,运行测试集合的
- TestResult:测试结果层
-
TestCase层
测试用例层,一条测试用例包括三个方法组成:
- setUp(self):只能有一个该方法,在每一个测试用例方法运行前执行,起到初始化的作用
- test_xxx(self):测试用例方法,放的是用例步骤,可以有多个
- tearDown(self):只能有一个该方法,在每一个测试用例方法运行后执行,起到资源释放的作用
# 单元测试用例的模块:不需要安装,直接导入即可 import unittest from danyuan.calcDemo import mathdemo # 创建一个单元测试类(一个普通类,继承unittest的测试类TestCase) class testCalc(unittest.TestCase): # 重写TestCase中的两个方法 def setUp(self): print('我是setUp方法') self.md = mathdemo() def tearDown(self): print('我是tearDown方法') self.md = None # 单元测试用例方法1 def test_add_01(self): '''加法的一条测试用例''' print('我是add_01方法') sj = self.md.add(1, 2) yq = 3 # 断言:就是判断预期结果和实际结果是否一致 # unittest框架中提供了很多断言的方法 # 判断是否相等的方法 # assert:断言 self.assertEqual(yq, sj, '预期结果和实际结果不一致!!!') # 单元测试用例方法2 def test_add_02(self): '''负数参与加法的一个测试用例''' print('我是add_02方法') sj = self.md.add(-1, 2) yq = 1 self.assertEqual(yq, sj, '预期结果和实际结果不一致!!!') # 单元测试用例方法3 def test_jian_03(self): '''乘法运算''' print('我是add_03方法') sj = self.md.minus(5, 4) yq = 1 self.assertEqual(yq, sj, '预期结果和实际结果不一致!!!') if __name__ == '__main__': unittest.main()常见的断言方法
- self.assertEqual()
- self.assertIn(元素,序列)
常见的装饰器:
- @unittest.skip()
- @unittest.expectedFailure
-
TestSuite测试集合层
discover()返回的就是一个测试集合对象。
# 测试集合对象:TestSuite # discover:就是将指定目录下的py模块中的单元测试用例加载并返回到测试集合对象 suite = unittest.defaultTestLoader.discover(r'./',pattern='test*.py') # print(suite) -
运行器层
采用BeautifulReport模块来运行测试集合。
pip install BeautifulReport
# 运行集合,生成可视化的报告 # 安装第三方的模块:BeautifulReport # 创建运行器,和测试集合关联在一起 runner = BeautifulReport(suite) runner.report("单元测试报告",'result',r'./')





![[ThinkPHP]The namespace “work“ is ambiguous (worker, workflow)](https://img-blog.csdnimg.cn/5518bfb71edc403083b4ceede56a736e.png)