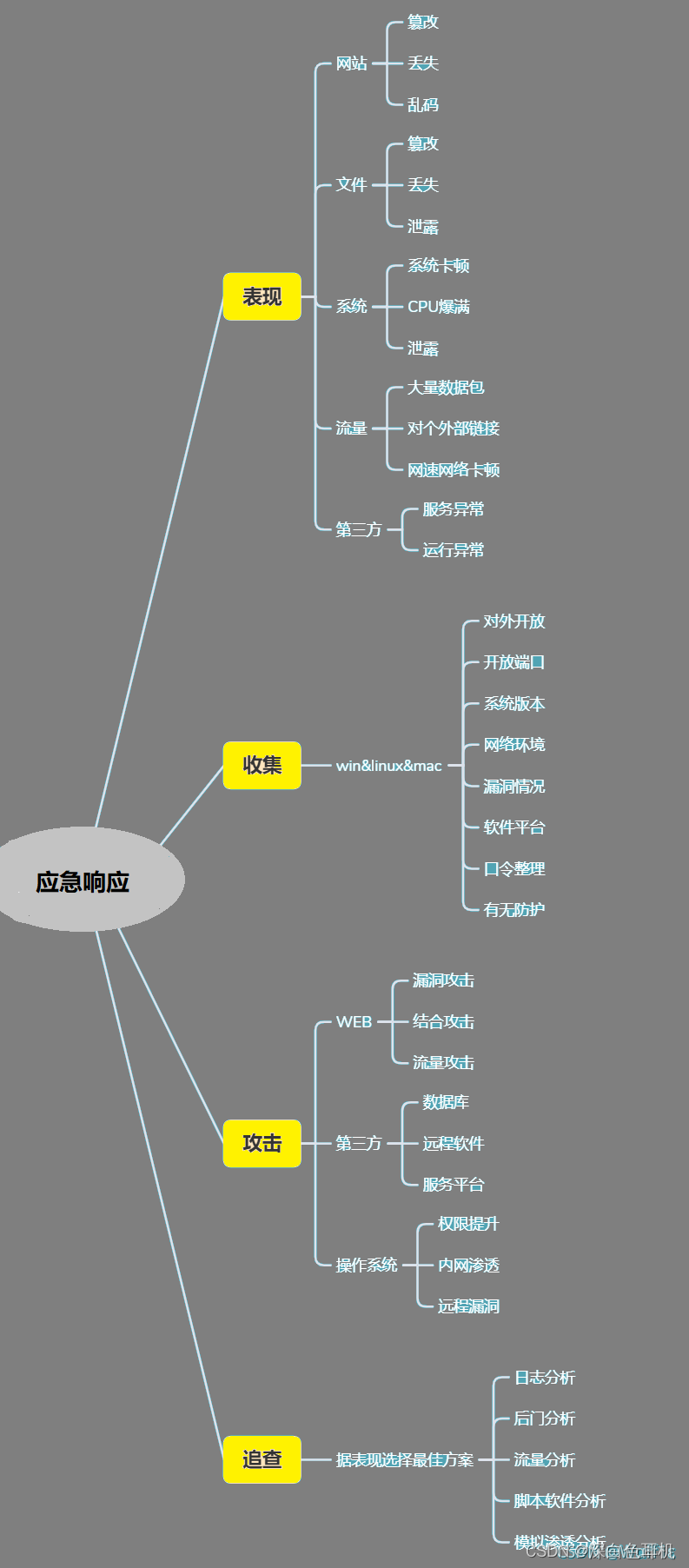
Mean-shift算法是一种非参数密度估计算法,主要用于图像分割、目标跟踪和聚类等领域。其基本原理是以某个点为中心,计算该点周围所有点的密度,并将中心点移动到密度最大的位置,不断迭代,直到中心点不再移动或满足停止条件为止。
目录
🌷🌷思路理解
🍋🍋算法步骤
🍓🍓python代码
有意思的知识又增加了,祝大家1024快乐
相比kmeans聚类,Meanshift 最大的优势是不需要人为指定分成几类。该算法会根据分布密度自动将数据归到适合的类中。
🌷🌷思路理解
Meanshift 聚类算法的大致思想就是 “哪里人多哪里跑” .(借鉴大佬的思路理解,一下就明白)
- 首先,将所有数据点设置为未标记状态。
- 从未被标记的数据中随机选取一个点作为初始大佬(质心);
- 由于事先并不知道会聚成几类,所以只能一类一类的聚,最后聚成几类就几类了。
- 以当前大佬为圆心,半径为R(超参1) 画个圆,圆内的点记做集合 M ,里面为该位大佬的小弟;为了方便日后相认,大佬决定给小弟们一张带来自己标识的保命卡进行标记。
- 由于是随机选择的大佬,难以服众。这位大佬的小弟们提出要召开选举大会,选出新的大佬(即通过算法选出新的质心);
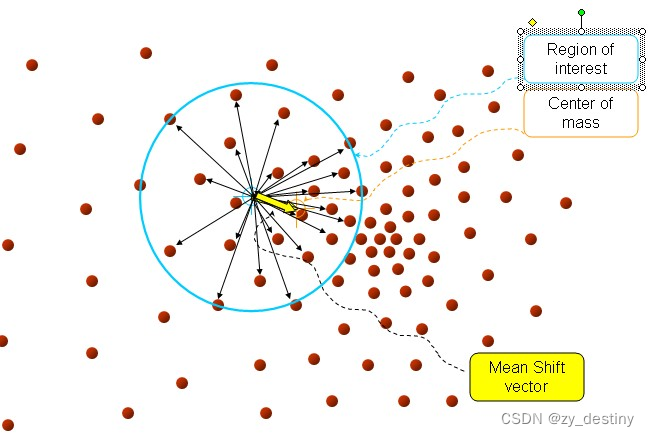
- 投票依据:这一届的小弟都很喜欢热闹,哪里人多就往哪边投。依次计算各位小弟到该大佬的向量距离(黑色向量)的平均值shift(绿色向量),如下图所示。
- 更新方式:旧大佬(蓝色圆圈)沿着投票方向即shift向量的方向移动,移动距离是||shift||,即为新大佬的位置(橙色圆圈)。也就是说这个大佬是“虚拟的”。
- 迭代2~3步骤,直到新大佬和旧大佬之间的偏移量小于某一个设置的阈值 E(超参2),即表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛。从而得到一个候选大佬(还不是正式的哈,晋级之路漫漫其修远兮)。
- 比较这位候选大佬跟正式大佬的距离,若距离小于指定的阈值 ω (超参3),则合并这两个大佬。否则,将该候选大佬提升为正式大佬,类别数加1;
- 迭代上述2-9步骤,直到所有数据点都被标记;
- 正式大佬全部确定下来后,小弟们就要选择投靠哪位大佬了。根据大佬在晋级路上发给小弟们的保命卡数量(即每个正式大佬对每个小弟的访问频数),小弟们选择投靠给自己保命卡最多的大佬(即对自己访问频数最大的那个大佬)。看样子小弟们还是很念旧情的哈。
ps:上面涉及的三个超参是需要用户人为指定的哈。
🍋🍋算法步骤
Mean-shift算法的步骤如下:
1. 初始化起始点。
2. 构建核函数,计算当前点周围所有点的权值。
3. 计算当前点的质心(即密度最大的位置),并将该点移动到质心位置。
4. 判断移动距离是否小于阈值,若小于则停止迭代,否则返回步骤2。
5. 将所有点分配到最终的簇中。
通过不断移动中心点,Mean-shift算法最终将所有数据点聚类到它们最密集的区域。由于Mean-shift算法不需要预先指定簇的个数,因此它被广泛应用于图像分割和目标跟踪等领域。
ps: 高斯核函数: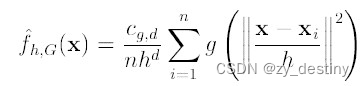
高斯核函数只是用来计算映射到高维空间之后的内积的一种简便方法,目的为让低维的不可分数据变成高维可分。利用核函数,可以忽略映射关系,直接在低维空间中完成计算。
🍓🍓python代码
import cv2
import numpy as np
# 读取图像
img = cv2.imread('image.jpg')
# 对图像进行分割
# 使用均值漂移算法构建初始聚类中心
# 然后使用KMeans算法进一步优化聚类效果
Z = img.reshape((-1,3)).astype('float32')
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
ret, label, center = cv2.kmeans(Z, 8, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS)
# 将每个像素的标签转换为其对应的中心颜色
center = np.uint8(center)
res = center[label.flatten()]
res2 = res.reshape((img.shape))
# 显示结果
cv2.imshow('Original image', img)
cv2.imshow('Segmented image', res2)
cv2.waitKey(0)
cv2.destroyAllWindows()
有意思的知识又增加了,祝大家1024快乐
整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷