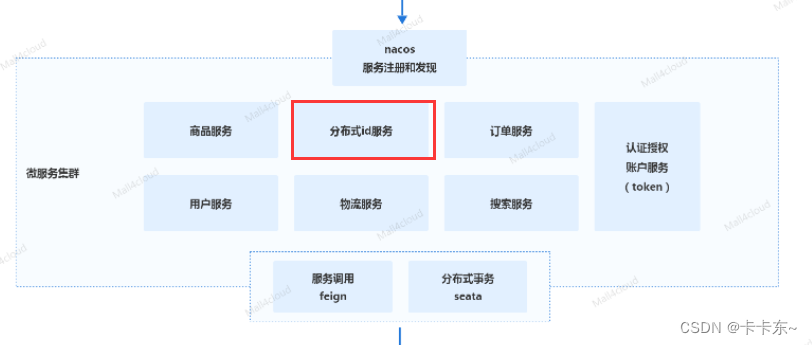
mall4cloud-leaf 基于美团leaf的生成id服务
- 分布式id介绍
- 具体代码及使用
- 项目中的生成id模式
- 具体代码
- 分布式id生成使用
分布式id介绍
分布式ID(Distributed ID)是在分布式计算环境中生成的唯一标识符或标识号。在分布式系统中,通常需要唯一标识不同的实体或数据,以确保数据的一致性、唯一性和跟踪性。分布式ID的生成可以避免多个节点或服务生成相同的标识符,从而避免数据冲突和不一致性。
分布式ID的好处包括:
唯一性:分布式ID是全局唯一的,无论在系统中的哪个节点生成,都不会与其他节点的ID冲突。
数据一致性:分布式ID可用于唯一标识数据库中的记录,确保不同节点的数据操作不会导致冲突或数据不一致性。
分布式系统中的跟踪:通过在分布式系统中的操作和事件中使用唯一ID,可以轻松跟踪和审计系统中发生的事情,有助于故障排除和性能分析。
降低数据库压力:分布式ID生成可以减少对数据库的写入压力,因为不需要立即查询数据库以获取唯一ID。这有助于提高性能。
去中心化:使用分布式ID生成服务,而不是依赖于中心化的ID生成器,有助于降低单点故障的风险。
提高性能:分布式ID生成服务通常经过优化,可以提供高性能的ID生成,适用于高吞吐量的应用程序。通过使用Leaf服务生成唯一ID,可以减少对数据库的写入请求,因为不再需要插入数据后立即查询以获取生成的ID。
美团Leaf的实现方式可以基于Twitter Snowflake算法,它的主要组成部分包括:
时间戳:Leaf服务使用时间戳来确保生成的ID在一定时间内是唯一的。时间戳通常占据了ID的高位,以确保生成的ID是递增的。
数据中心ID:数据中心ID是一个数字,用于标识不同的数据中心。在大型分布式系统中,可能存在多个数据中心,每个数据中心中的节点需要具有唯一的数据中心ID。这有助于确保生成的ID不会与其他数据中心中的ID冲突。通常,数据中心ID是分配给数据中心的唯一标识符,如数字1、2、3等。
机器节点ID:机器节点ID用于在同一数据中心内标识不同的节点或服务器。每个节点都应具有唯一的机器节点ID,以防止在同一数据中心内的不同节点生成ID时出现冲突。通常,机器节点ID是分配给机器或节点的唯一标识符
序列号:序列号部分用于解决同一毫秒内的ID冲突。当在同一毫秒内多次请求ID时,序列号递增以确保ID的唯一性。
也可以基于数据库方式生成,项目中使用的是该方式:
具体代码及使用
项目中的生成id模式
在本项目中,使用的是Leaf-segment号段模式,该模式是对直接用数据库自增ID充当分布式ID的一种优化,减少对数据库的频率操作。相当于从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,业务服务将号段在本地生成1~1000的自增ID并加载到内存。
由于号段模式依赖于数据库表,我们先看一下相关的数据库表:
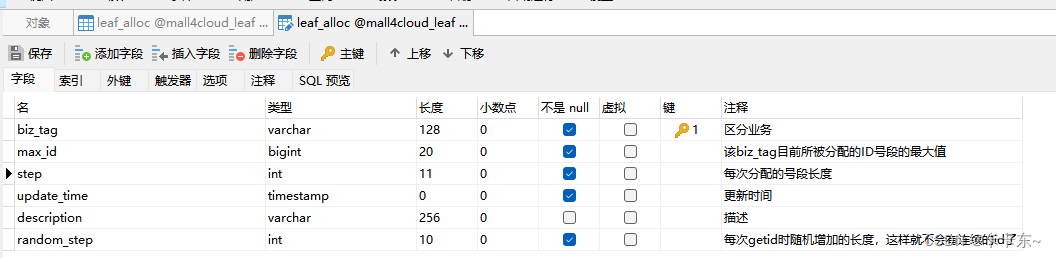
biz_tag:针对不同业务需求,用biz_tag字段来隔离,如果以后需要扩容时,只需对biz_tag分库分表即可
max_id:当前业务号段的最大值,用于计算下一个号段
step:步长,也就是每次获取ID的数量
random_step: 每次getid时随机增加的长度
之后在nacos的配置,只需连接数据库即可。
具体代码
在代码中,leaf作为一个独立的服务,获取id时都是通过fegin调用的。所以主要代码如下:
@FeignClient(value = "mall4cloud-leaf",contextId ="segment")
public interface SegmentFeignClient {
/**
* 获取id
* @param key
* @return
*/
@GetMapping(value = FeignInsideAuthConfig.FEIGN_INSIDE_URL_PREFIX + "/insider/segment")
ServerResponseEntity<Long> getSegmentId(@RequestParam("key") String key);
}
@RestController
public class SegmentFeignController implements SegmentFeignClient {
private static final Logger logger = LoggerFactory.getLogger(SegmentFeignController.class);
@Autowired
private SegmentService segmentService;
@Override
public ServerResponseEntity<Long> getSegmentId(String key) {
//通过不同服务的key获取分布式id
return ServerResponseEntity.success(get(key, segmentService.getId(key)));
}
private Long get(String key, Result id) {
Result result;
if (key == null || key.isEmpty()) {
throw new NoKeyException();
}
result = id;
if (Objects.equals(result.getStatus(), Status.EXCEPTION)) {
throw new LeafServerException(result.toString());
}
return result.getId();
}
}
封装的fegin方法中,主要就是通过key去获取id,这个key就是表中的biz_tag。下面看一下leaf的具体代码。
@Override
public Result get(final String key) {
// 检查初始化是否成功
if (!initOk) {
// 如果初始化失败,返回异常结果
return new Result(EXCEPTION_ID_IDCACHE_INIT_FALSE, Status.EXCEPTION);
}
// 从缓存中获取名为 'key' 的SegmentBuffer对象
SegmentBuffer buffer = cache.get(key);
if (buffer != null) {
// 如果找到了缓存中的SegmentBuffer
if (buffer.isInitOk()) {
// 检查SegmentBuffer是否已成功初始化
synchronized (buffer) {
// 同步块,确保线程安全
if (buffer.isInitOk()) {
// 再次检查SegmentBuffer是否已成功初始化
try {
// 尝试从数据库中更新SegmentBuffer
updateSegmentFromDb(key, buffer.getCurrent());
logger.info("Init buffer. Update leafkey {} {} from db", key, buffer.getCurrent());
// 更新成功后,将SegmentBuffer的初始化标志设置为true
buffer.setInitOk(true);
}
catch (Exception e) {
// 如果更新出现异常,记录警告日志
logger.warn("Init buffer {} exception", buffer.getCurrent(), e);
}
}
}
}
// 从SegmentBuffer中获取ID并返回
return getIdFromSegmentBuffer(cache.get(key));
}
// 如果未找到名为 'key' 的SegmentBuffer,返回异常结果
return new Result(EXCEPTION_ID_KEY_NOT_EXISTS, Status.EXCEPTION);
}
这段代码来自类SegmentIDGenImpl,后面我们加一篇对于leaf的源码分析文章。
分布式id生成使用
我们请求一个注册用户的接口,之后通过fegin调用leaf接口产生用户id。

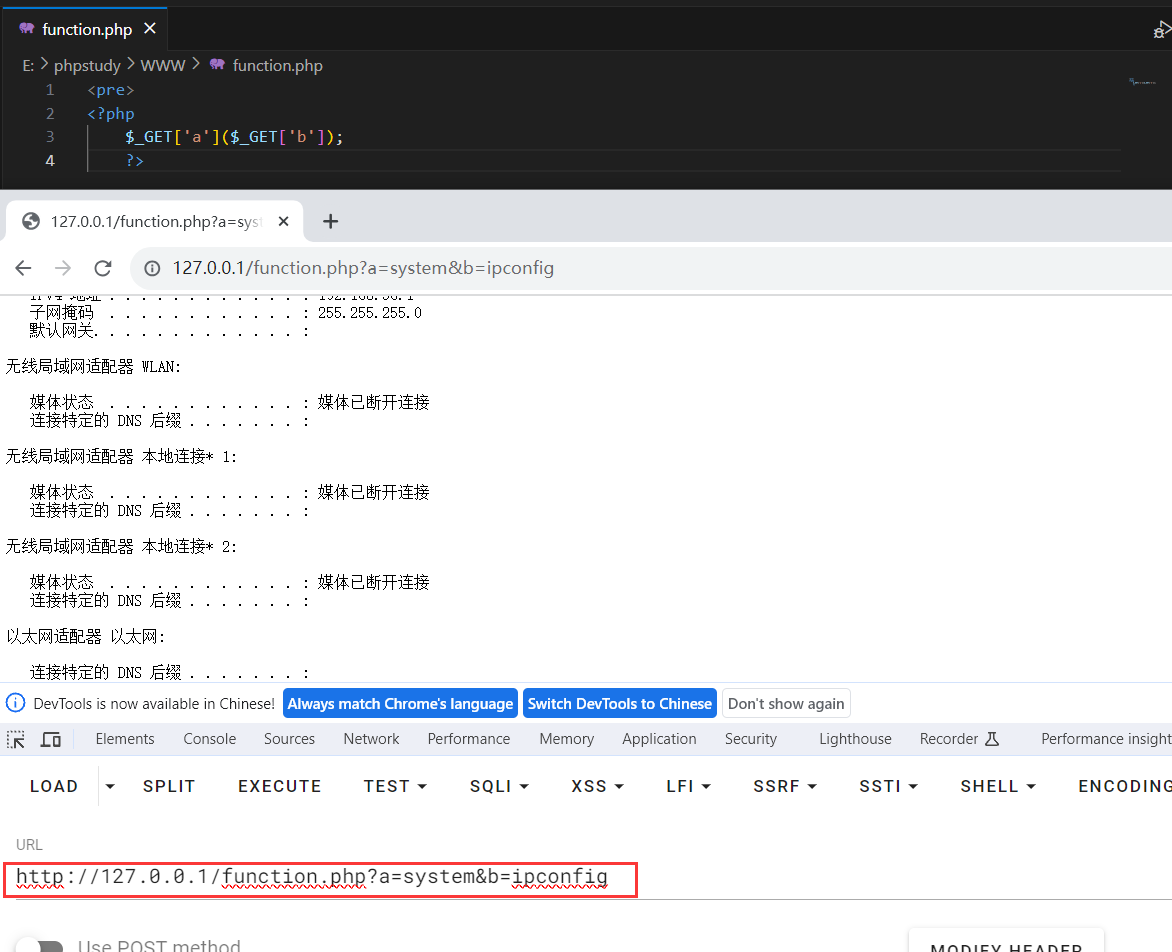
可以看到,产生的id是106806。
之后向下请求,它产生的id是上一个id增加(1~10)之间的随机数产生的数字,和数据表中的random_step字段对应。