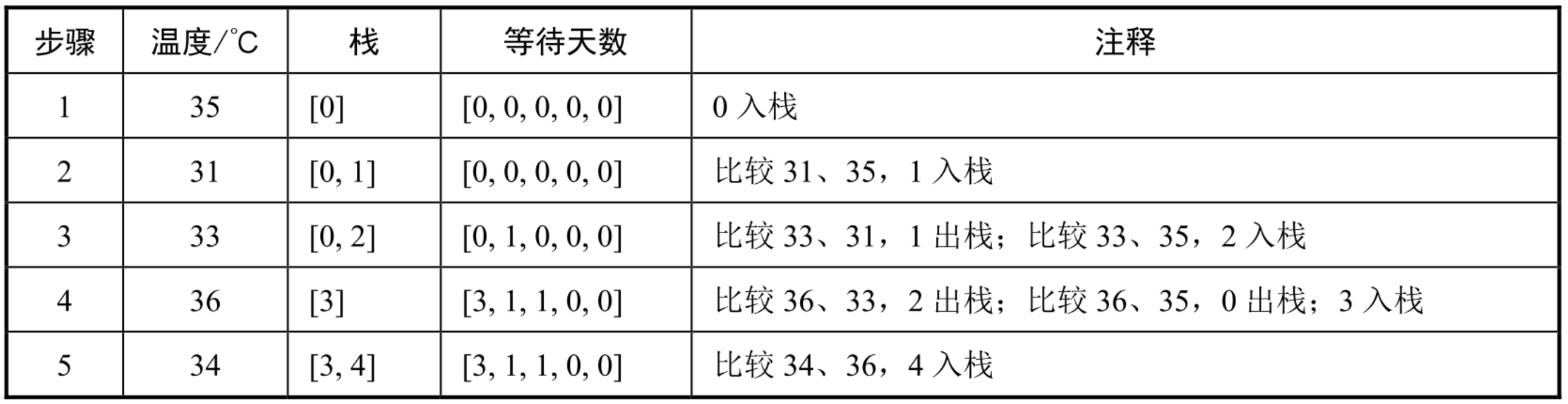
一、样本不均衡问题
样本(类别)不平衡指的是分类任务中不同类别的训练样例数目差别很大的情况,一般地,样本类别比例(多数类VS少数类)明显大于1:1(例如4:1)就可以归为样本不均衡的问题。现实中,样本不平衡是一种常见的现象,如:金融欺诈交易检测,欺诈交易的订单通常是占总交易数量的极少部分,而且对于有些任务而言少数样本更为重要。

1.1不均衡问题的影响
具体举个例子,在一个欺诈识别的案例中,好坏样本的占比是1000:1,而如果我们直接拿这个比例去学习模型的话,因为扔进去模型学习的样本大部分都是好的,就很容易学出一个把所有样本都预测为好的模型,而且这样预测的概率准确率还是非常高的。而模型最终学习的并不是如何分辨好坏,而是学习到了”好 远比 坏的多“这样的先验信息,凭着这个信息把所有样本都判定为“好”就可以了。这样就背离了模型学习去分辨好坏的初衷了。
所以,样本不均衡带来的根本影响是:模型会学习到训练集中样本比例的这种先验性信息,以致于实际预测时就会对多数类别有侧重(可能导致多数类精度更好,而少数类比较差)。如下图(示例代码请见:github.com/aialgorithm),类别不均衡情况下的分类边界会偏向“侵占”少数类的区域。更重要的一点,这会影响模型学习更本质的特征,影响模型的鲁棒性。
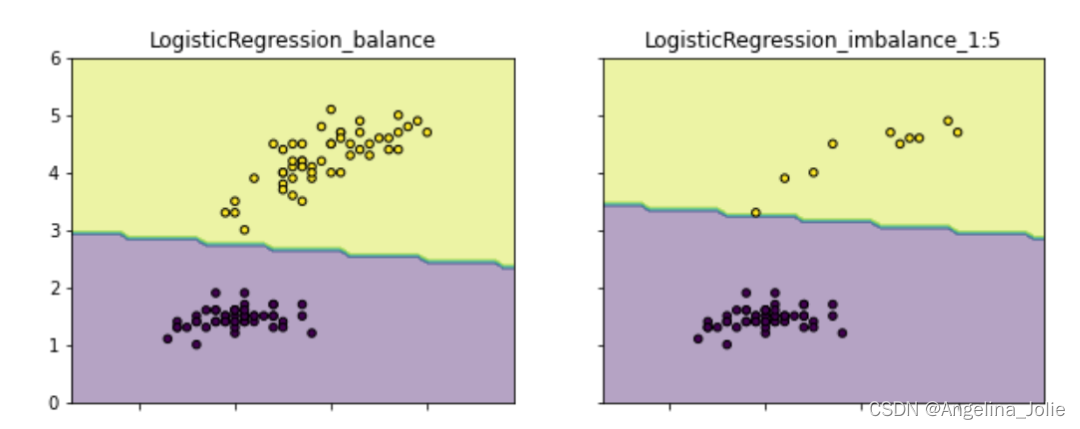
总而言之,我们通过解决样本不均衡,可以减少模型学习样本比例的先验信息,以获得能学习到辨别好坏本质特征的模型。
1.2 判断解决不均衡的必要性
从分类效果出发,通过上面的例子可知,不均衡对于分类结果的影响不一定是不好的,那什么时候需要解决样本不均衡?
-
判断任务是否复杂:复杂度学习任务的复杂度与样本不平衡的敏感度是成正比的(参见《Survey on deep learning with class imbalance》),对于简单线性可分任务,样本是否均衡影响不大。需要注意的是,学习任务的复杂度是相对意义上的,得从特征强弱、数据噪音情况以及模型容量等方面综合评估。
-
判断训练样本的分布与真实样本分布是否一致且稳定,如果分布是一致的,带着这种正确点的先验对预测结果影响不大。但是,还需要考虑到,如果后面真实样本分布变了,这个样本比例的先验就有副作用了。
-
判断是否出现某一类别样本数目非常稀少的情况,这时模型很有可能学习不好,类别不均衡是需要解决的,如选择一些数据增强的方法,或者尝试如异常检测的单分类模型。
二、样本不均衡的解决方法
基本上,在学习任务有些难度的前提下,不均衡解决方法可以归结为:通过某种方法使得不同类别的样本对于模型学习中的Loss(或梯度)贡献是比较均衡的。以消除模型对不同类别的偏向性,学习到更为本质的特征。本文从数据样本、模型算法、目标(损失)函数、评估指标等方面,对个中的解决方法进行探讨。
2.1 样本层面
2.1.1 欠采样、过采样
最直接的处理方式就是样本数量的调整了,常用的可以:
-
欠采样:减少多数类的数量(如随机欠采样、NearMiss、ENN)。
-
过采样:尽量多地增加少数类的的样本数量(如随机过采样、以及2.1.2数据增强方法),以达到类别间数目均衡。
-
还可结合两者做混合采样(如Smote+ENN)。
具体还可以参见【scikit-learn的imbalanced-learn.org/stable/user_guide.html以及github的awesome-imbalanced-learning】
2.1.2 数据增强
数据增强(Data Augmentation)是在不实质性的增加数据的情况下,从原始数据加工出更多数据的表示,提高原数据的数量及质量,以接近于更多数据量产生的价值,从而提高模型的学习效果如下列举常用的方法:
-
基于样本变换的数据增强
样本变换数据增强即采用预设的数据变换规则进行已有数据的扩增,包含单样本数据增强和多样本数据增强。
单样本增强(主要用于图像):主要有几何操作、颜色变换、随机擦除、添加噪声等方法产生新的样本,可参见imgaug开源库。

多样本增强:是通过组合及转换多个样本,主要有Smote类(可见imbalanced-learn.org/stable/references/over_sampling.html)、SamplePairing、Mixup等方法在特征空间内构造已知样本的邻域值样本。
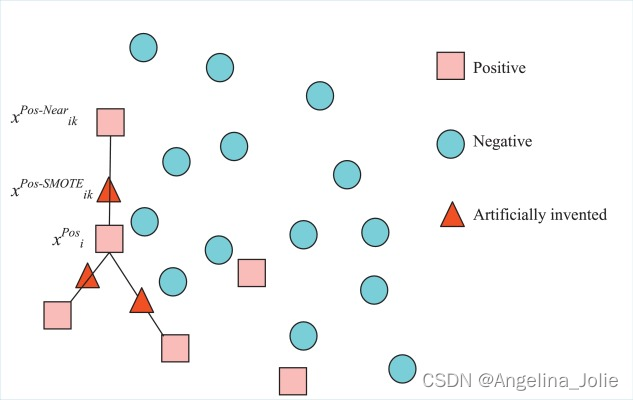
基于深度学习的数据增强:生成模型如变分自编码网络(Variational Auto-Encoding network, VAE)和生成对抗网络(Generative Adversarial Network, GAN),其生成样本的方法也可以用于数据增强。这种基于网络合成的方法相比于传统的数据增强技术虽然过程更加复杂, 但是生成的样本更加多样。

数据样本层面解决不均衡的方法,需要关注的是:
-
随机欠采样可能会导致丢弃含有重要信息的样本。在计算性能足够下,可以考虑数据的分布信息(通常是基于距离的邻域关系)的采样方法,如ENN、NearMiss等。
-
随机过采样或数据增强样本也有可能是强调(或引入)片面噪声,导致过拟合。也可能是引入信息量不大的样本。此时需要考虑的是调整采样方法,或者通过半监督算法(可借鉴Pu-Learning思路)选择增强数据的较优子集,以提高模型的泛化能力。
2.2 损失函数的层面
损失函数层面主流的方法也就是常用的代价敏感学习(cost-sensitive),为不同的分类错误给予不同惩罚力度(权重),在调节类别平衡的同时,也不会增加计算复杂度。如下常用方法:
2.2.1 class weight
这最常用也就是scikit模型的’class weight‘方法,If ‘balanced’, class weights will be given by n_samples / (n_classes * np.bincount(y)). If a dictionary is given, keys are classes and values are corresponding class weights. If None is given, the class weights will be uniform.,class weight可以为不同类别的样本提供不同的权重(少数类有更高的权重),从而模型可以平衡各类别的学习。如下图通过为少数类做更高的权重,以避免决策偏重多数类的现象(类别权重除了设定为balanced,还可以作为一个超参搜索。示例代码请见github.com/aialgorithm):
clf2 = LogisticRegression(class_weight={0:1,1:10}) # 代价敏感学习 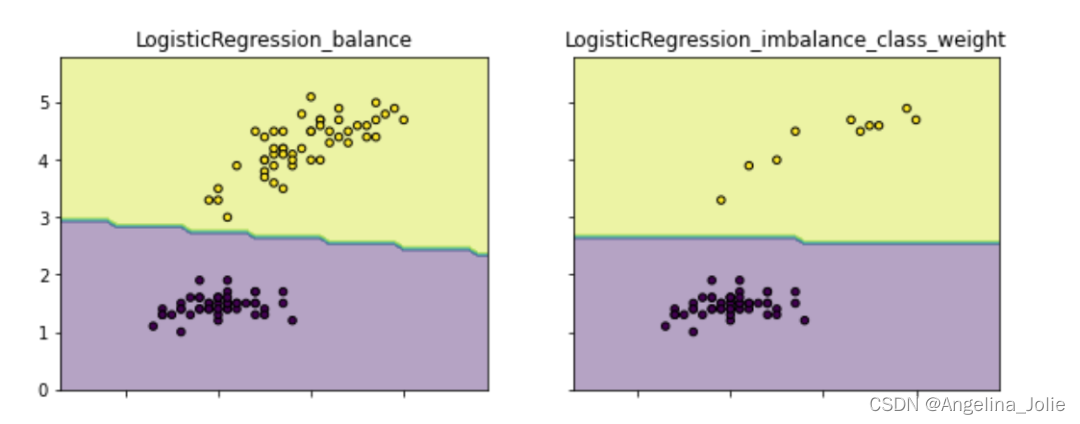
2.2.2 OHEM 和 Focal Loss
上文的大意是,类别的不平衡可以归结为难易样本的不平衡,而难易样本的不平衡可以归结为梯度的不平衡。按照这个思路,OHEM和Focal loss都做了两件事:难样本挖掘以及类别的平衡。(另外的有 GHM、 PISA等方法,可以自行了解)
-
OHEM(Online Hard Example Mining)算法的核心是选择一些hard examples(多样性和高损失的样本)作为训练的样本,针对性地改善模型学习效果。对于数据的类别不平衡问题,OHEM的针对性更强。
-
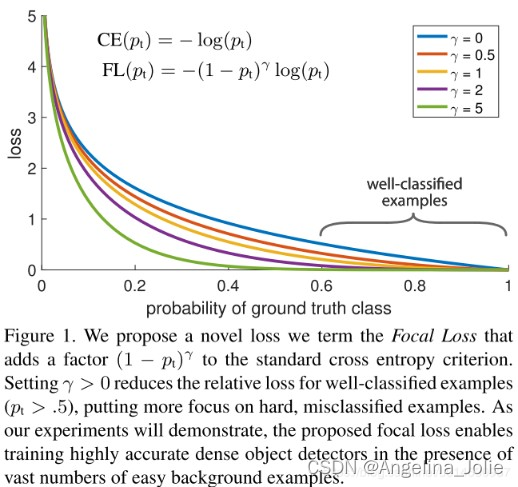
Focal loss的核心思想是在交叉熵损失函数(CE)的基础上增加了类别的不同权重以及困难(高损失)样本的权重(如下公式),以改善模型学习效果。
2.3 模型层面
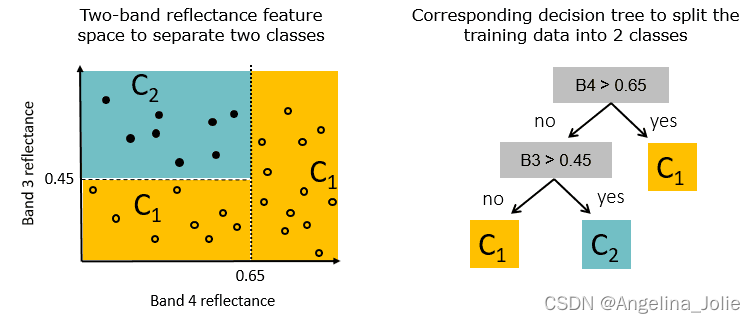
模型方面主要是选择一些对不均衡比较不敏感的模型,比如,对比逻辑回归模型(lr学习的是全量训练样本的最小损失,自然会比较偏向去减少多数类样本造成的损失),决策树在不平衡数据上面表现相对好一些,树模型是按照增益递归地划分数据(如下图),划分过程考虑的是局部的增益,全局样本是不均衡,局部空间就不一定,所以比较不敏感一些(但还是会有偏向性)。相关实验可见arxiv.org/abs/2104.02240。
解决不均衡问题,更为优秀的是基于采样+集成树模型等方法,可以在类别不均衡数据上表现良好。
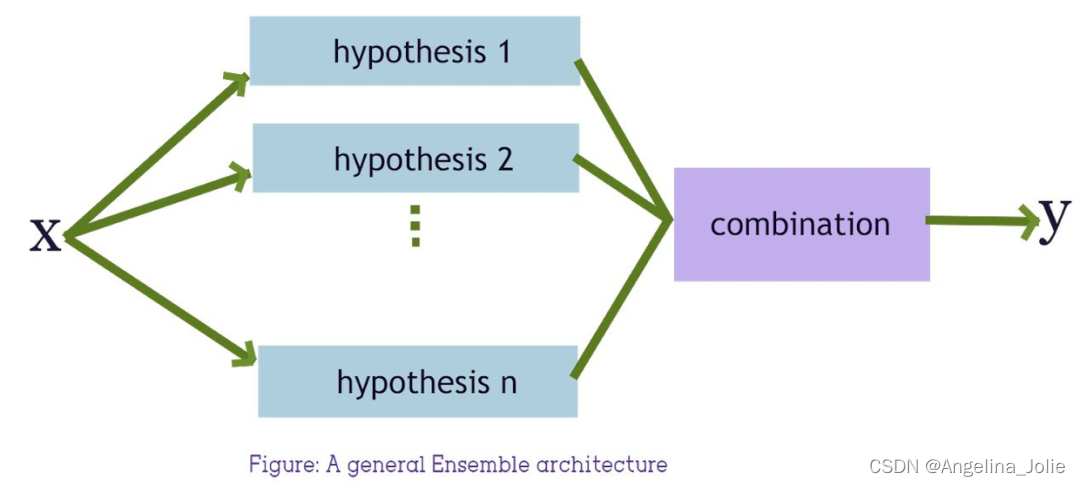
2.3.1 采集+集成学习
这类方法简单来说,通过重复组合少数类样本与抽样的同样数量的多数类样本,训练若干的分类器进行集成学习。
-
BalanceCascade BalanceCascade基于Adaboost作为基分类器,核心思路是在每一轮训练时都使用多数类与少数类数量上相等的训练集,然后使用该分类器对全体多数类进行预测,通过控制分类阈值来控制FP(False Positive)率,将所有判断正确的类删除,然后进入下一轮迭代继续降低多数类数量。
-
EasyEnsemble EasyEnsemble也是基于Adaboost作为基分类器,就是将多数类样本集随机分成 N 个子集,且每一个子集样本与少数类样本相同,然后分别将各个多数类样本子集与少数类样本进行组合,使用AdaBoost基分类模型进行训练,最后bagging集成各基分类器,得到最终模型。示例代码可见:www.kaggle.com/orange90/ensemble-test-credit-score-model-example
通常,在数据集噪声较小的情况下,可以用BalanceCascade,可以用较少的基分类器数量得到较好的表现(基于串行的集成学习方法,对噪声敏感容易过拟合)。噪声大的情况下,可以用EasyEnsemble,基于串行+并行的集成学习方法,bagging多个Adaboost过程可以抵消一些噪声影响。此外还有RUSB、SmoteBoost、balanced RF等其他集成方法可以自行了解。
2.3.2 异常检测
类别不平衡很极端的情况下(比如少数类只有几十个样本),将分类问题考虑成异常检测(anomaly detection)问题可能会更好。
异常检测是通过数据挖掘方法发现与数据集分布不一致的异常数据,也被称为离群点、异常值检测等等。无监督异常检测按其算法思想大致可分为几类:基于聚类的方法、基于统计的方法、基于深度的方法(孤立森林)、基于分类模型(one-class SVM)以及基于神经网络的方法(自编码器AE)等等。

2.4 决策及评估指标
当我们采用不平衡数据训练模型,如何更好决策以及客观地评估不平衡数据下的模型表现。对于分类常用的precision、recall、F1、混淆矩阵,样本不均衡的不同程度,都会明显改变这些指标的表现。
对于类别不均衡下模型的预测,我们可以做分类阈值移动,以调整模型对于不同类别偏好的情况(如模型偏好预测负样本,偏向0,对应的我们的分类阈值也往下调整),达到决策时类别平衡的目的。这里,通常可以通过P-R曲线,选择到较优表现的阈值。

对于类别不均衡下的模型评估,可以采用AUC、AUPRC(更优)评估模型表现。AUC的含义是ROC曲线的面积,其数值的物理意义是:随机给定一正一负两个样本,将正样本预测分值大于负样本的概率大小。AUC对样本的正负样本比例情况是不敏感,即使正例与负例的比例发生了很大变化,ROC曲线面积也不会产生大的变化。

总结
我们通过解决样本不均衡,可以减少模型学习样本比例的先验信息,以获得能学习到辨别好坏本质特征的模型。可以将不均衡解决方法归结为:通过某种方法使得不同类别的样本对于模型学习中的Loss(或梯度)贡献是比较均衡的。具体可以从数据样本、模型算法、目标函数、评估指标等方面进行优化,其中数据增强、代价敏感学习及采样+集成学习是比较常用的,效果也是比较明显的。其实,不均衡问题解决也是结合实际再做方法选择、组合及调整,在验证中调优的过程。
注:本文主要探讨分类任务的类别不均衡,回归任务的样本不均衡详见《Delving into Deep Imbalanced Regression》