一、动机
- 大模型在各种类型的NLP任务上均展现出惊艳的表现。基于CoT propmt能够更好地激发大模型解决复杂推理问题的能力,例如解决数学解题,可以让模型生成reasoning path。现有的经典的CoT方法有few-shot cot、zero-shot cot等。
- 然后现有的cot面临两个核心挑战:
- 需要提供相关的exemplars作为指导;
- 需要尽可能减少人工标注的成本;
- Zero-shot CoT避免了人工标注来引导推理,但是对于一些复杂的任务难以完成推理,例如code generation;而few-shot CoT则可以通过引入task相关的exemplar来让大模型生成相应的推理,但是此时则需要人工标注或挑选exemplar
- 因此引发一个研究问题:如何能够同时兼顾两者的优势?
- 本文提出一种“归纳学习”的提示方法。首先设计instruction让大模型生成出与当前问题比较相关的exemplars,并补全exemplars,最后让模型recall relevant problem and aolutions来解决当前的问题。
二、方法
本文关注problem-solving task。
给定一个问题
x
x
x,首先通过一个prompt method将问题映射到文本输入
ϕ
(
x
)
\phi(x)
ϕ(x),任务目标是调用LLM解决这个问题并生成目标答案
y
y
y,生成的目标答案可以包含reasoning path
r
r
r和答案
a
a
a。

本文则是关注在设计
ϕ
\phi
ϕ。

Self-Generated Exemplars
**归纳提示学习(analogical prompting)**旨在模型在解决一个新的问题时,能够自发性地寻找相似的已有的知识。因此提出Self-Generated Exemplars方法,即让模型从在训练阶段掌握的problem-solving knowledge中生成出相关的问题和解决方法。
设计指令来达到这个目的:

基于这个instruction的一个实例如下所示:

大模型能够根据给定的instruciton,在对于一个新的问题
x
x
x时候,能够先生成出3个相关的且互不相同的problem并给出相应的解决方案,然后再对目标问题进行解决。
self-generated instruction的三个核心部分:
- 需要明确地让模型生成relevant切diverse exemplars。因为打磨学会偏向于重复地生成一些经典的问题,误导模型生成。
generate problems that are distinct from each other.
- single-pass & independent exemplar generation。实验发现single-pass效果最好:
- single-pass:本文提出的方法,一个instruction让模型生成3个exemplar;
- independent exemplar generation:让模型分别生成若干exemplar,然后采样3个exemplar之后再重新设计prompt让大模型进行生成。
- exemplar number K K K:发现3~5最佳。
Self-generated Knowledge + Exemplars
对于像code-generation等复杂的任务,low-level exemplar generation不一定能过让模型很好地解决此类问题,因此本文提出一种high-level generation方法。通过设计如下指令来实现:
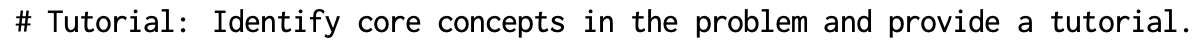
对应的具体的例子如下所示:

本质来说,就是在self-generated exemplar prompt的基础上,添加新的任务,即让模型生成核心知识。例如代码生成中,需要让模型先思考选择什么algorithm,以及algorithm对应的tutorial。
Knowledge的优势主要体现在两个方面:
- knowledge act as high-level takeaways that complement low-level exemplars, which prevents LLMs from overly relying on specific exemplars and helps to generalize to new problems;
- LLMs identify the core concepts of the problem and produce exemplars that align more closely in fundamental problem-solving approaches
三、实验
实验数据任务:
- mathematical problem solving:GSM8K、MATH等;
- code generation:动态规划、图算法等复杂的编程题,例如codeforces;
- Big-Bench
模型:
- GPT3.5-turbo、GPT-4、PaLM2-L
实验结果:
发现本文提出的方达到了SOTA。
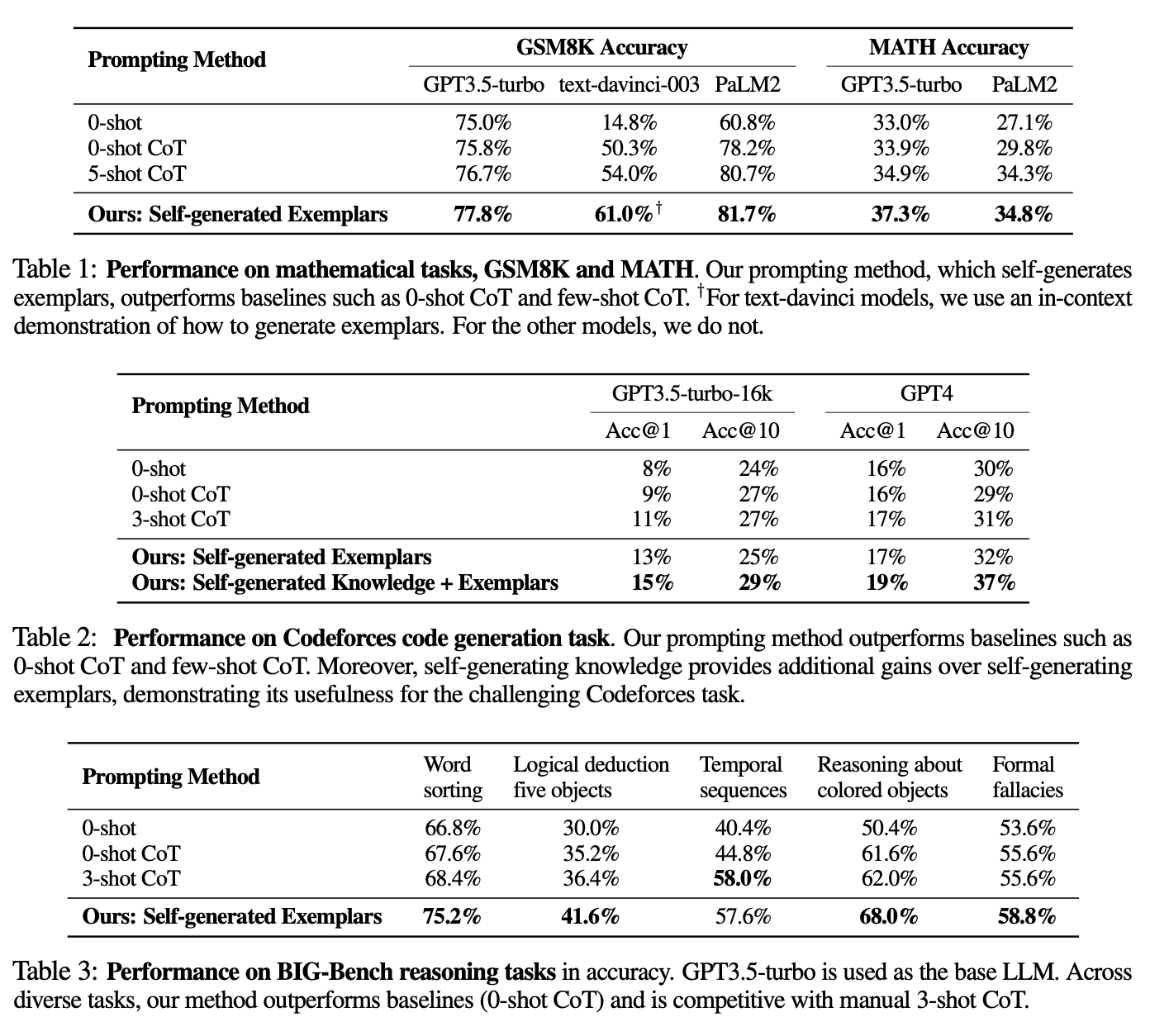
探索:Self-generation exemplar与retrieve relevant exemplar的对比
- retrieve方法的优势在于准确可靠,即采样得到的exemplar一定是准确的,但是缺点在于需要额外的标注成本,且搜索空间往往有限
- self-generation方法的优势在于简单且自适应,能够根据具体的task量身定制对应的exemplar,且搜索空间可以是整个模型训练的语料。 v
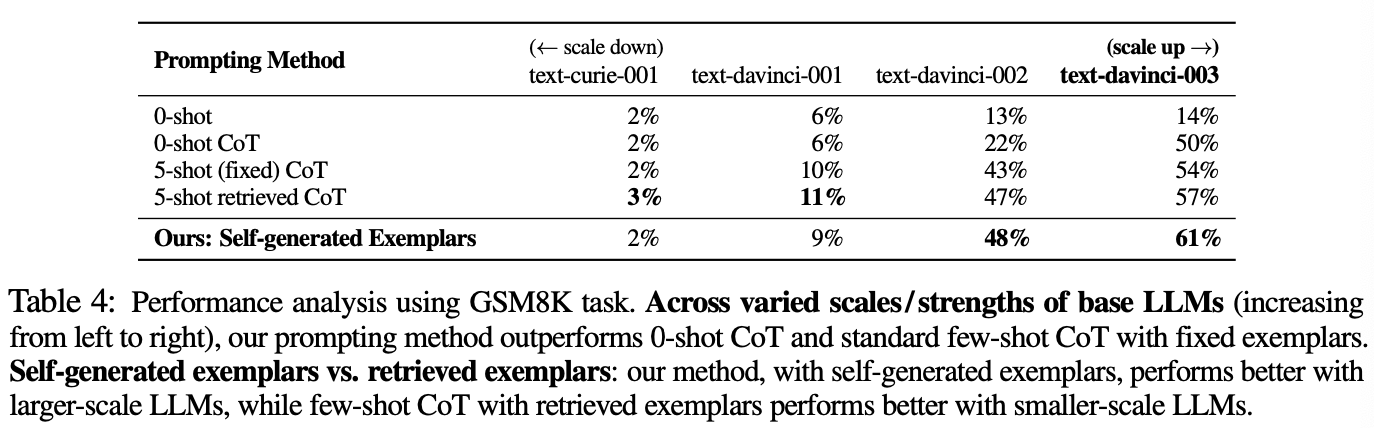
探索:Scale of LLM
上图中展示出,当模型规模越大时,解题的准确性也越高,同时我们提出的self-generation方法与baseline的提升幅度也越大。
- 当使用小模型时候,LLM本身的知识有限,因此更需要retrieve exemplar;
- 当使用大模型的时候,此时LLM本身的知识很丰富,选择self-generation更容易得到与目标问题相近的exemplar。
探索:exemplar数量分析
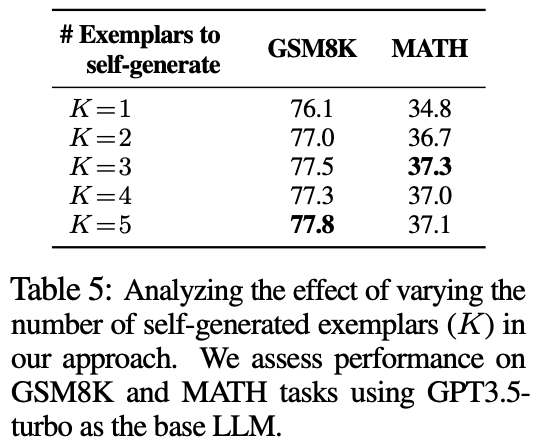
发现当
K
∈
{
3
,
4
,
5
}
K\in\{3, 4, 5\}
K∈{3,4,5}时候更合适。