图像语义分割 pytorch复现DeepLab v1图像分割网络详解以及pytorch复现(骨干网络基于VGG16、ResNet50、ResNet101)
- 背景介绍
- 2、 网络结构详解
- 2.1 LarFOV效果分析
- 2.2 DeepLab v1-LargeFOV 模型架构
- 2.3 MSc(Multi-Scale,多尺度(预测))
- 2.3 以VGG16为特征提取骨干网络代码
背景介绍
论文名称:Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
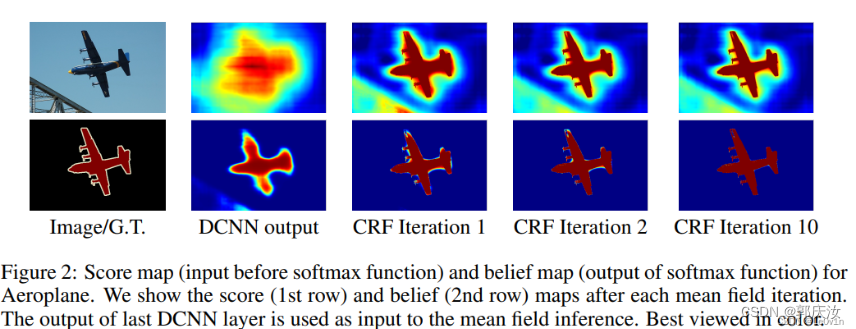
- 2014 年发表于 CVPR
- DeepLab v1 是一种用于语义分割的卷积神经网络模型,其核心思想是结合了全局上下文信息,以更好地理解图像中的语义内容。
论文中指出了当前图像语义分割的存在问题:
- 下采样会导致图像的分辨率降低
在 DCNN 中,通常通过池化层来进行信号下采样,这是为了减少特征图的尺寸和参数数量。然而,池化操作会导致特征图的空间分辨率降低,从而损失了一部分细节信息。在图像标注任务中,像素级的细节信息对于准确的标注非常重要,因此信号下采样可能会影响标注的质量。

- 空间不敏感
DCNNs 在高级视觉任务中表现出色的一个原因是它们具有一定程度的平移、旋转、缩放等空间不变性。然而,对于像素级标注任务(如语义分割或像素级分类),我们希望网络能够对每个像素点进行精细的标注,这就需要网络具有较高的空间敏感性。然而,DCNNs 的不变性特性可能导致在特征提取过程中丢失一些空间信息,使得网络对于像素级标注任务不够敏感。
论文中解决以上两个问题的方案:

- 1、采用空洞卷积
- 2、采用fully-connected CRF(Condition Random Fie)(全连接条件随机场)
CRF在语义分割领域是常用的方法,但是在DeepLab V3之后便不再使用
网络优势:
- 速度更快,论文中说因为采用了膨胀卷积的原因,但fully-connect CRF很耗时
- 准确率更高,相比之前最好的网络,提升了7.2个点
- 结构简单,主要采用DCNN和CRFs级联构成
DeepLab:本文提出的语义分割模型
MSc:Multi-Scale,多尺度
CRF:全连接条件随机场,用于对图像进行后处理以改善分割或标注的结果。它通常用于在图像分割任务中对神经网络的输出进行精炼和优化
LargeFOV:空洞卷积
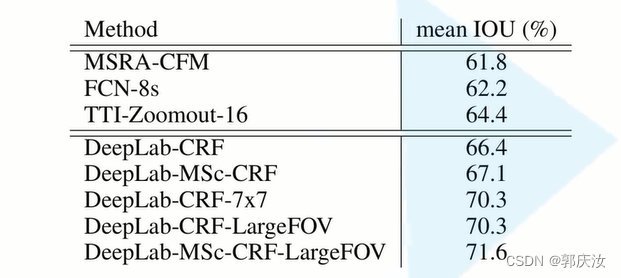
2、 网络结构详解
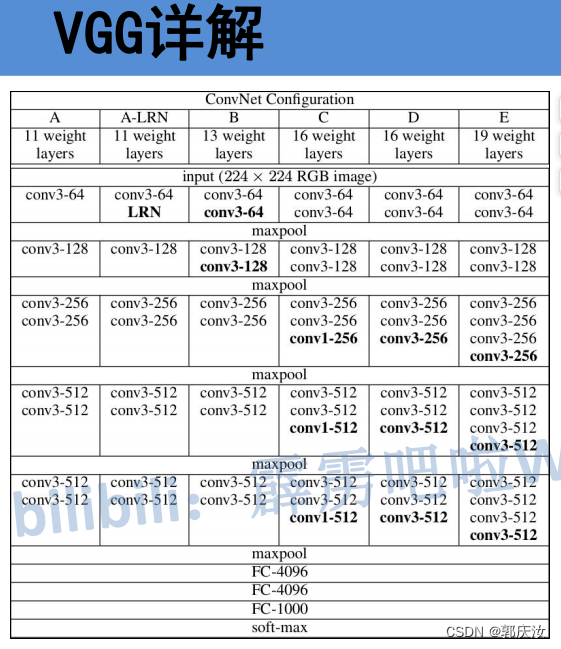
DeepLab v1 的 Backbone 使用的是 VGG16作为主要的卷积神经网络架构(2014年最牛逼的分类网络为VGG)。在 DeepLab v1 中,VGG16 的部分或全部全连接层被去除,而只保留卷积层,并通过空洞卷积(Atrous Convolution)来增大感受野,从而实现对图像的全局上下文信息的捕获
VGG16 的结构包含 16 层卷积层和全连接层,其中包括 13 个卷积层和 3 个全连接层。该模型在 ImageNet 数据集上进行了训练,并在图像分类任务上取得了很好的性能。
2.1 LarFOV效果分析

将卷积核减小,比如从原来的 kernel_size = (7, 7) 变为 kernel_size = (4, 4) 或 kernel_size = (3, 3)

注意❗️
- 这里替换全连接层的卷积层并非普通卷积层,而是一个膨胀卷积,它有一个膨胀系数 r,可以扩大感受野。
- 图中的 input stride 其实是膨胀系数 r。

2.2 DeepLab v1-LargeFOV 模型架构
VGG系列网络结构:
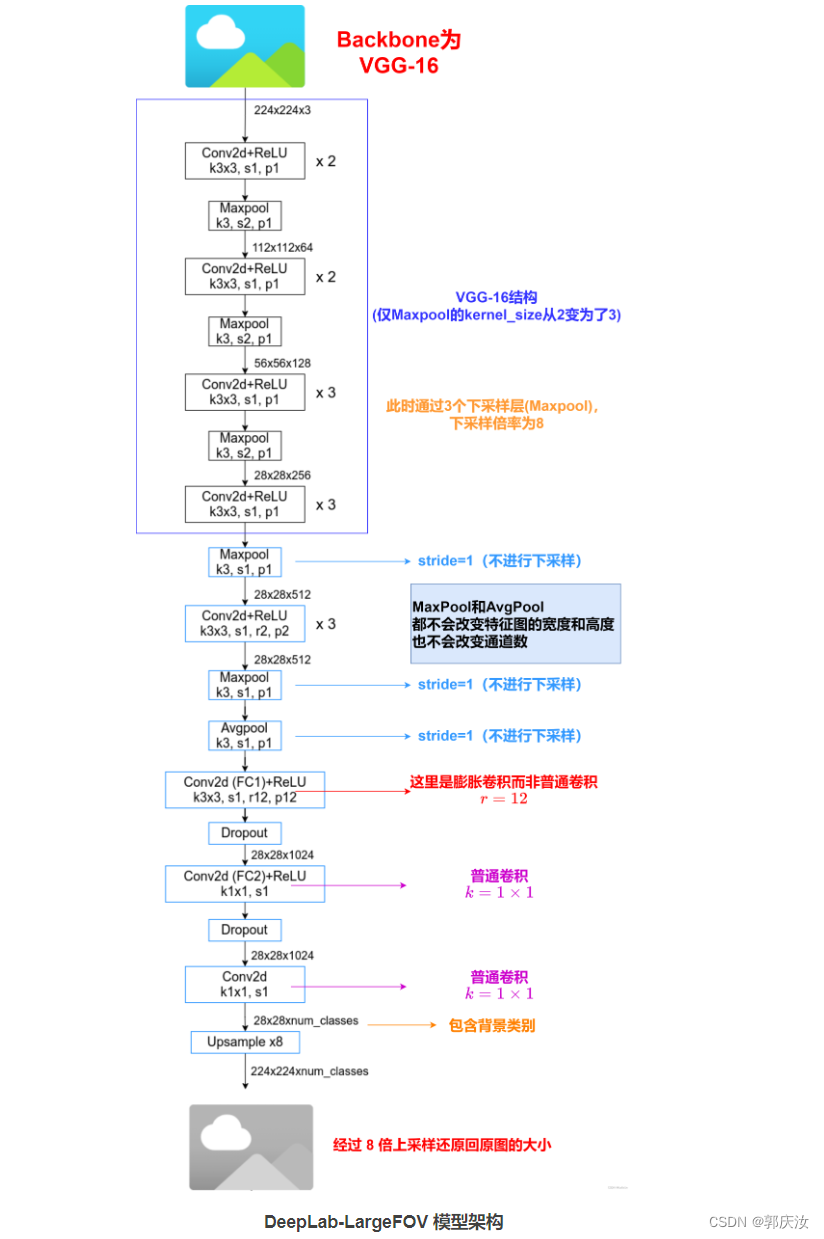
DeepLab-LargeFOV 模型架构:
经过上采样得到 224 × 224 × num class的特征图并非模型最终输出结果,还要经过一个 Softmax 层后才是模型最终的输出结果。
Softmax 层的作用是将每个像素的类别预测转换为对应类别的概率。它会对每个像素的 num_classes 个类别预测进行归一化,使得每个预测值都落在 0 到 1 之间,并且所有类别的预测概率之和为 1。这样,对于每个像素点,我们可以得到每个类别的概率,从而确定该像素属于哪个类别的概率最大。最终的输出结果通常是经过 Softmax 处理后的特征图,其中每个像素点都包含了 num_classes 个类别的概率信息。
LargeFOV 本质上就是使用了膨胀卷积。
- 通过分析发现虽然 Backbone 是 VGG-16 但使用 Maxpool 略有不同,VGG 论文中是 kernel=2,stride=2,但在 DeepLab v1 中是 kernel=3,stride=2,padding=1。接着就是最后两个 Maxpool 层的 stride 全部设置成了 1(这样下采样的倍率就从原来的 32 变成了 8)。最后三个 3 × 3 的卷积层采用了膨胀卷积,膨胀系数 r = 2。
- 然后关于将全连接层卷积化过程中,对于第一个全连接层(FC1)在 FCN 网络中是直接转换成卷积核大小为 7 × 7,卷积核个数为 4096 的卷积层(普通卷积),但在 DeepLab v1 中作者说是对参数进行了下采样最终得到的是卷积核大小 3 × 3 ,卷积核个数为 1024 的卷积层(膨胀卷积)(这样不仅可以减少参数还可以减少计算量,详情可以看下论文中的 Table2),对于第二个全连接层(FC2)卷积核个数也由 4096 4096 采样成 1024(普通卷积)。
- 将 FC1 卷积化后,还设置了膨胀系数(膨胀卷积),论文 3.1 中说的是 r = 4 但在 Experimental Evaluation 中 Large of View 章节里设置的是 r = 12 对应 LargeFOV。对于 FC2 卷积化后就是卷积核 1 × 1 ,卷积核个数为 1024 的普通卷积层。接着再通过一个卷积核 1 × 1 ,卷积核个数为 num_classes(包含背景)的普通卷积层。最后通过 8 倍上采样还原回原图大小。
注意❗️采用的是双线性插值(Bilinear Interpolation)的策略来实现上采样,双线性插值会考虑其周围 4 个最近的像素点,根据距离权重进行插值计算。这样可以有效地将特征图还原到原始输入图像的大小,使得网络的输出和输入在空间尺寸上保持一致
2.3 MSc(Multi-Scale,多尺度(预测))
即融合多个特征层的输出
DeepLab-LargeFOV-MSc 模型架构

2.3 以VGG16为特征提取骨干网络代码
DeepLab-LargeFOV
#!/usr/bin/python
# -*- encoding: utf-8 -*-
import torchvision
import torch
import torch.nn as nn
import torch.nn.functional as F
斜体样式
class DeepLabLargeFOV(nn.Module):
def __init__(self, in_dim, out_dim, *args, **kwargs):
super(DeepLabLargeFOV, self).__init__(*args, **kwargs)
# vgg16 = torchvision.models.vgg16()
layers = []
layers.append(nn.Conv2d(in_dim, 64, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(64, 64, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.MaxPool2d(3, stride = 2, padding = 1))
layers.append(nn.Conv2d(64, 128, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(128, 128, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.MaxPool2d(3, stride = 2, padding = 1))
layers.append(nn.Conv2d(128, 256, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(256, 256, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(256, 256, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.MaxPool2d(3, stride = 2, padding = 1))
layers.append(nn.Conv2d(256, 512, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(512, 512, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(512, 512, kernel_size = 3, stride = 1, padding = 1))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.MaxPool2d(3, stride = 1, padding = 1))
# 以下采用膨胀卷积
layers.append(nn.Conv2d(512,
512,
kernel_size = 3,
stride = 1,
padding = 2,
dilation = 2))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(512,
512,
kernel_size = 3,
stride = 1,
padding = 2,
dilation = 2))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.Conv2d(512,
512,
kernel_size = 3,
stride = 1,
padding = 2,
dilation = 2))
layers.append(nn.ReLU(inplace = True))
layers.append(nn.MaxPool2d(3, stride = 1, padding = 1))
self.features = nn.Sequential(*layers)
classifier = []
classifier.append(nn.AvgPool2d(3, stride = 1, padding = 1))
classifier.append(nn.Conv2d(512,
1024,
kernel_size = 3,
stride = 1,
padding = 12,
dilation = 12))
classifier.append(nn.ReLU(inplace=True))
classifier.append(nn.Conv2d(1024, 1024, kernel_size=1, stride=1, padding=0))
classifier.append(nn.ReLU(inplace=True))
classifier.append(nn.Dropout(p=0.5))
classifier.append(nn.Conv2d(1024, out_dim, kernel_size=1))
self.classifier = nn.Sequential(*classifier)
self.init_weights()
def forward(self, x):
N, C, H, W = x.size()
x = self.features(x)
x = self.classifier(x)
x = F.interpolate(x, (H, W), mode='bilinear', align_corners=True)
return x
def init_weights(self):
vgg = torchvision.models.vgg16(pretrained=True)
state_vgg = vgg.features.state_dict()
self.features.load_state_dict(state_vgg)
for ly in self.classifier.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
nn.init.constant_(ly.bias, 0)
if __name__ == "__main__":
net = DeepLabLargeFOV(3, 10)
in_ten = torch.randn(1, 3, 224, 224)
out = net(in_ten)
print(out.size())
in_ten = torch.randn(1, 3, 64, 64)
mod = nn.Conv2d(3,
512,
kernel_size = 3,
stride = 1,
padding = 2,
dilation = 2)
out = mod(in_ten)
print(out.shape)
import os
import torch
from torchsummary import summary
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net=DeepLabLargeFOV(3,21).to(device)
print(summary(net,(3,224,224)))
print(torch.cuda.current_device())



![[资源推荐]看到一篇关于agent的好文章](https://img-blog.csdnimg.cn/de6aaa3e8194476dbff5a02647131af2.png)