目录
💃概述
⛹定义
编辑⛹消息队列
🤸♂️消息队列应用场景
编辑🤸♂️两种模式:点对点、发布订阅
编辑⛹基本概念
💃Kafka安装
⛹ zookeeper安装
⛹集群规划
编辑⛹流程
⛹原神启动
🤸♂️批量脚本
⛹topics常规操作
⛹生产者命令行操作
⛹消费者命令行操作
💃生产者
⛹生产者消息发送
⛹异步发送api
🤸♂️普通异步发送
🤸♂️回调异步发送
⛹同步发送
⛹分区
🤸♂️分区策略
🤸♂️自定义分区
⛹提高吞吐量
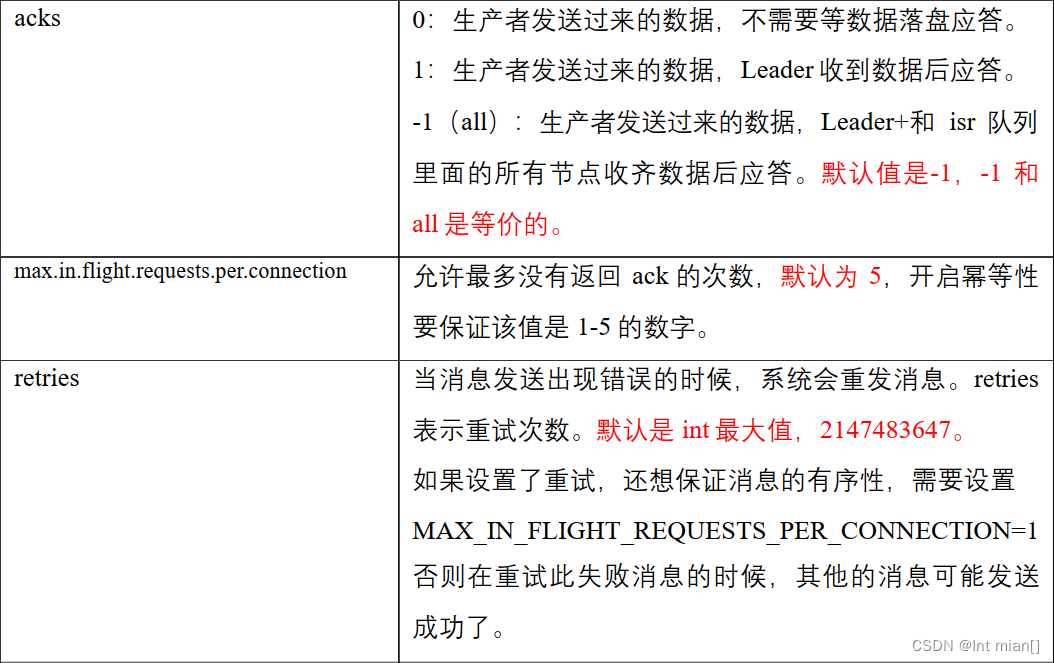
⛹数据可靠性Ack
🤸♂️0 1 -1三个应答毛病
🤸♂️去重
🤸♂️事务
⛹有序
💃Broker
👩🚀Broker 工作流程
🤸♂️Zookeeper 存储的 Kafka 信息
🤸♂️总体工作流程
👩🚀Kafka 副本
副本基本信息
Leader 选举流程
🧠整理思路:
follower挂了
leader寄了
分区副本分配
Leader Partition 负载平衡
👩🚀文件存储
🤸♂️存储机制
Topic 数据的存储机制
文件清理策略
👩🚀高效读写数据
💃Kafka 消费者
👩🚀消费方式 pull
👩🚀Kafka 消费者工作流程
消费者组原理
消费流程
👩🚀消费案例
消费一个主题
消费一个分区
消费者组
👩🚀分区的分配策略、再平衡
👩🚀offset 位移
👩🚀消费者事务
👩🚀数据积压(消费者如何提高吞吐量)
💃Kafka-Eagle 监控
安装 改配置
💃Kafka-Kraft 模式
优点
安装配置
💃概述
⛹定义
Kafka传统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。(发布/订阅:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息。)
Kafka 最新定义:Kafka 是一个开源的分布式事件流平台(Event Streaming Platform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。
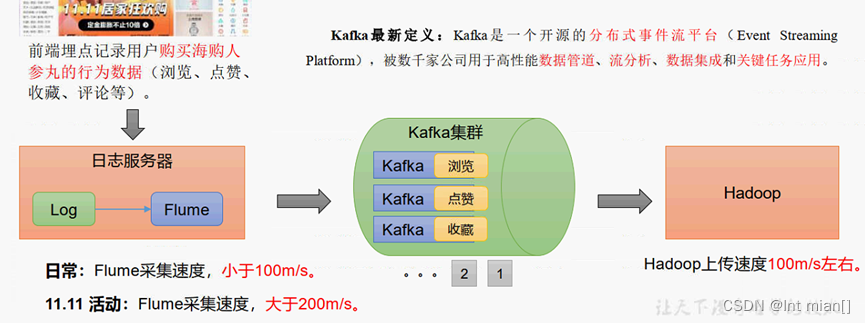 ⛹消息队列
⛹消息队列
🤸♂️消息队列应用场景
缓存/消峰
 解耦:允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
解耦:允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
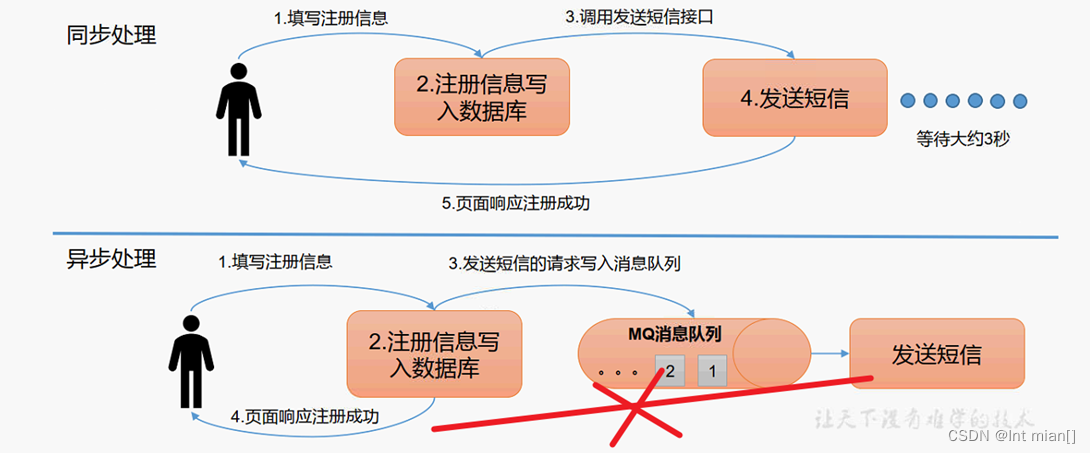
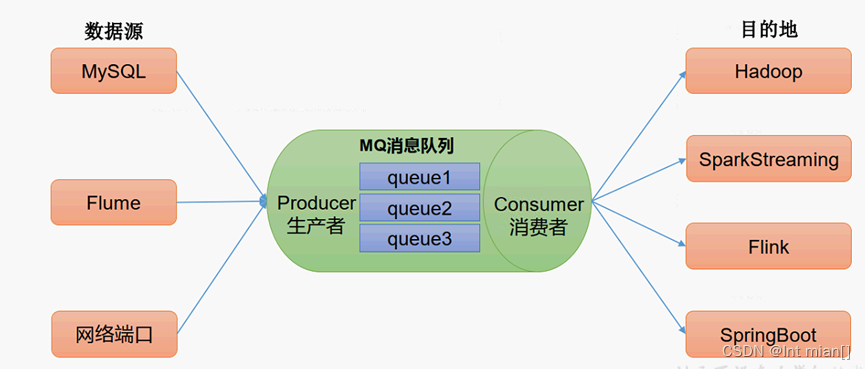 异步通信:允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。
异步通信:允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。
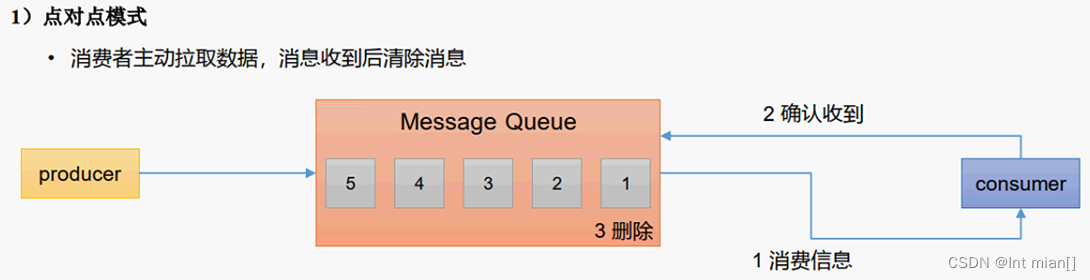
 🤸♂️两种模式:点对点、发布订阅
🤸♂️两种模式:点对点、发布订阅

1.为方便扩展,并提高吞吐量,一个topic分为多个partition
2.配合分区的设计,提出消费者组的概念,组内每个消费者并行消费
3.为提高可用性,为每个partition增加若干副本,类似NameNode HA
4. ZK中记录谁是leader,Kafka2.8.0以后也可以配置不采用ZK
 ⛹基本概念
⛹基本概念
(1)Producer:消息生产者,就是向 Kafka broker 发消息的客户端。
(2)Consumer:消息消费者,向Kafka broker 取消息的客户端。
(3)Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
(4)Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个topic。
(5)Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。
(6)Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个topic 可以分为多个 partition,每个partition 是一个有序的队列。
(7)Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower。
(8)Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
(9)Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步。Leader 发生故障时,某个Follower 会成为新的Leader。
💃Kafka安装
⛹ zookeeper安装
zookeeper(目前只有安装)-CSDN博客
⛹集群规划
不是每个都要zk
 ⛹流程
⛹流程
下载
官网安装地址:Apache Kafka
本文使用kafka_2.12-3.0.0:https://archive.apache.org/dist/kafka/3.0.0/kafka_2.12-3.0.0.tgz
解压
tar -zxvf kafka_2.12-3.0.0.tgz -C /export/server/改配置
cd config
vim server.properties
# The id of the broker. This must be set to a unique integer for each broker.
# 这里三个节点都要有自己的id,不能重复,hadoop1是0,hadoop2是1,hadoop3是2
broker.id=1
# A comma separated list of directories under which to store log files
# 日志数据,不能放到tmp临时目录,自己指定一个
log.dirs=/export/server/kafka/log
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181/kafka
:wqfenfa
fenfa到另外两个集群,修改id为2和3!!!
环境变量/etc/profile,也分发
# kafka
export KAFKA_HOME=/export/server/kafka
export PATH=$PATH:$KAFKA_HOME/bin⛹原神启动
启动kafka之前要先启动zk
zk start
bin/kafka-server-start.sh -daemon config/server.properties关闭的时候要先关kafka,先关zoo的话会关不掉kafka!!!!
注意:停止 Kafka 集群时,一定要等 Kafka 所有节点进程全部停止后再停止 Zookeeper集群。因为 Zookeeper 集群当中记录着 Kafka 集群相关信息,Zookeeper 集群一旦先停止,Kafka 集群就没有办法再获取停止进程的信息,只能手动杀死Kafka 进程了
🤸♂️批量脚本
case $1 in
start)
for i in hadoop1 hadoop2 hadoop3
do
echo ================ Kafka-3.0.0 $i start ================
ssh $i "/export/server/kafka/bin/kafka-server-start.sh -daemon /export/server/kafka/config/server.properties"
done
;;
stop)
for i in hadoop1 hadoop2 hadoop3
do
echo ================ Kafka-3.0.0 $i stop ================
ssh $i "/export/server/kafka/bin/kafka-server-stop.sh"
done
;;
*)
echo "Usage: $0 {start|stop}"
;;
esac
⛹topics常规操作
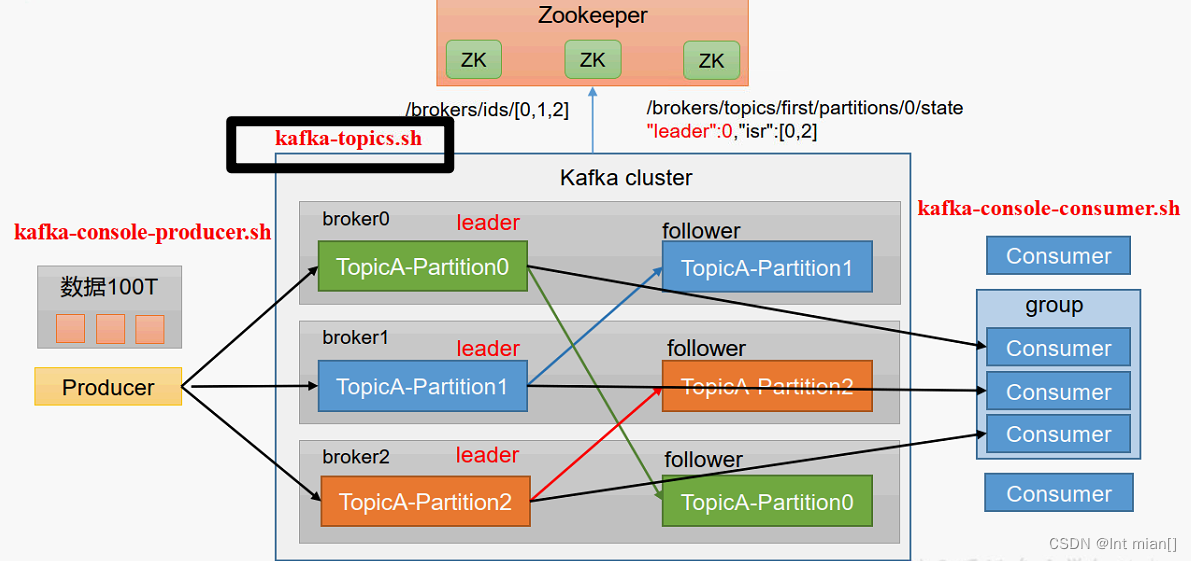
查看操作主题命令参数
bin/kafka-topics.sh

查看当前服务器中的所有 topic
bin/kafka-topics.sh --bootstrap-server hadoop1:9092 --list
创建first topic
bin/kafka-topics.sh --bootstrap-server hadoop1:9092 --create --partitions 1 --replication-factor 3 --topic first
查看first 主题的详情
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first
修改分区数(注意:分区数只能增加,不能减少)
bin/kafka-topics.sh --bootstrap-server hadoop1:9092 --alter --topic first --partitions 3
再次查看first 主题的详情
bin/kafka-topics.sh --bootstrap-server hadoop1:9092 --describe --topic first
删除topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --delete --topic first
⛹生产者命令行操作
查看操作生产者命令参数
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh

bin/kafka-console-producer.sh --bootstrap-server hadoop1:9092 --topic first
>hello world
>atguigu atguigu
⛹消费者命令行操作
1)查看操作消费者命令参数
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh
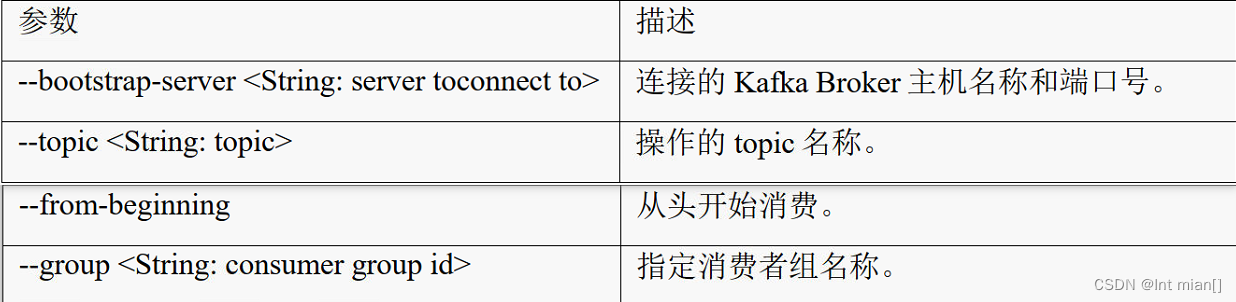
费消息
(1)消费first 主题中的数据。
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop1:9092 --topic first
(2)把主题中所有的数据都读取出来(包括历史数据)。
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first
💃生产者
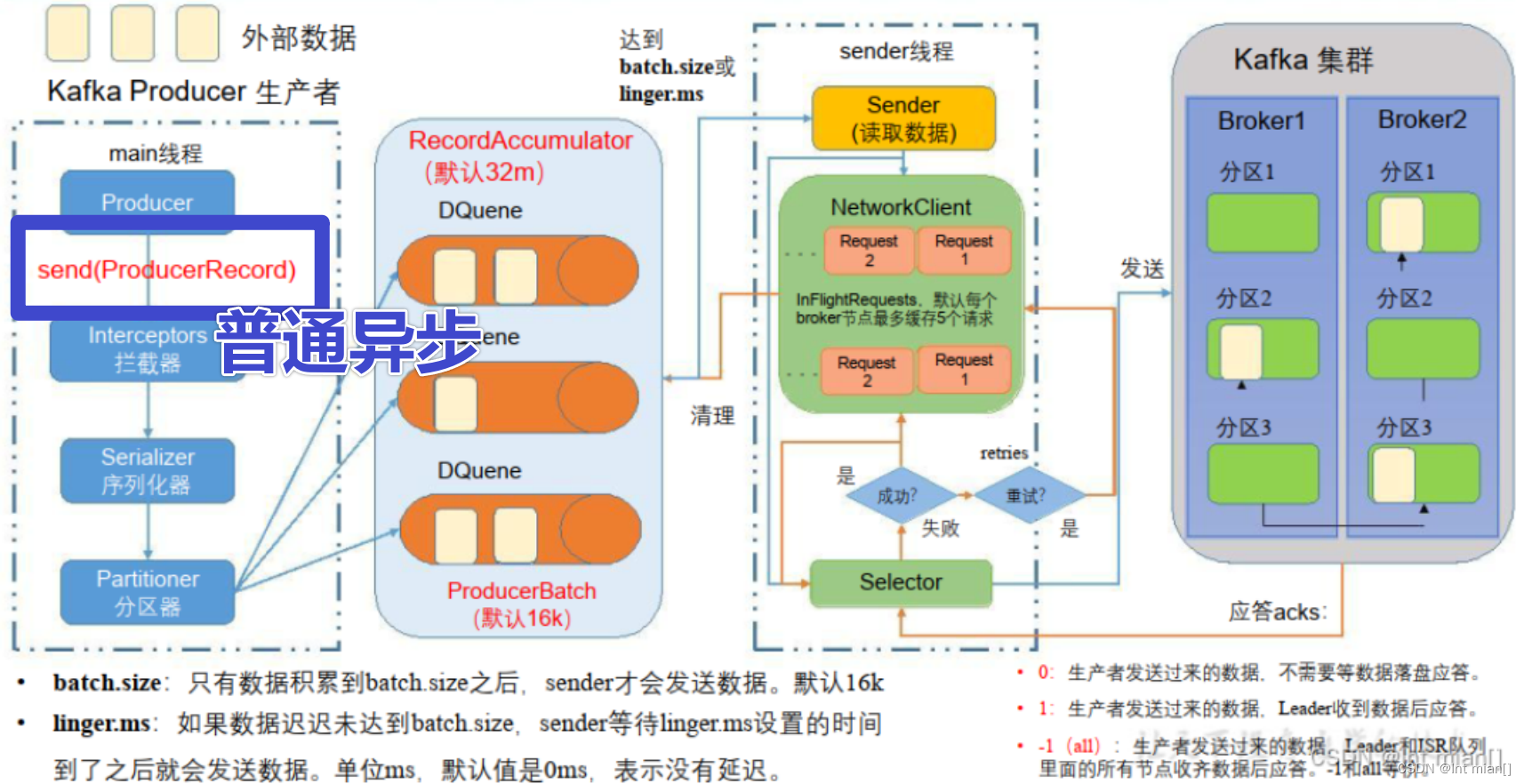
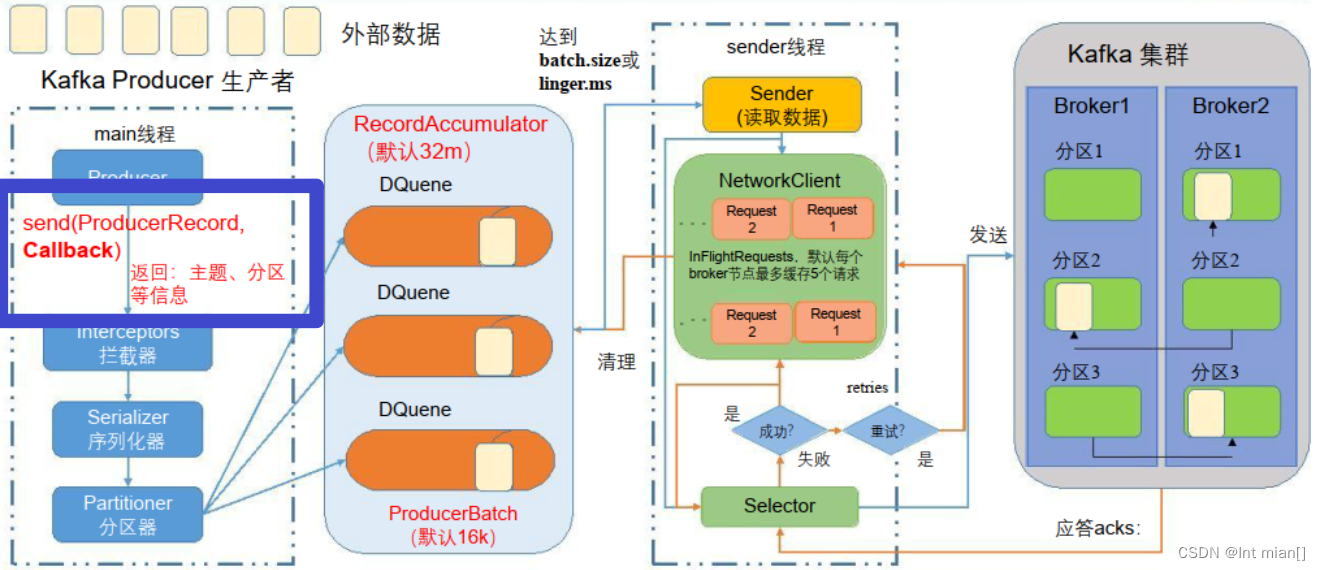
⛹生产者消息发送
在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程。在 main 线程中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker
参数:

⛹异步发送api
🤸♂️普通异步发送
1)需求:创建 Kafka 生产者,采用异步的方式发送到 Kafka Broker
(一边汇报完成了,一边在队列执行)
public static void main(String[] args) {
// TODO 创建生产者对象
Properties conf = new Properties();
// 指定集群
// public static final String BOOTSTRAP_SERVERS_CONFIG = "bootstrap.servers";
conf.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop1:9092,hadoop2:9092");
// 指定序列化器
conf.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// conf.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
conf.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(conf);
// TODO 发送数据
for (int i = 0; i < 5; i++) {
producer.send(new ProducerRecord<>("first", "yuange"+i));
}
// TODO 关闭资源
producer.close();
}在 hadoop1 上开启 Kafka 消费者。
bin/kafka-console-consumer.sh --bootstrap-server hadoop1:9092 --topic first

🤸♂️回调异步发送
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是元数据信息(RecordMetadata)和异常信息(Exception),如果 Exception 为 null,说明消息发送成功,如果 Exception 不为 null,说明消息发送失败。

// TODO 发送数据
for (int i = 0; i < 5; i++) {
producer.send(new ProducerRecord<>("first", "yuange" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null){
System.out.println("topic:"+metadata.topic()+" part:"+metadata.partition());
}
}
});
}
⛹同步发送
只需在异步发送的基础上,再调用一下 get()方法即可。
// TODO 发送数据
for (int i = 0; i < 5; i++) {
producer.send(new ProducerRecord<>("first", "yuange" + i)).get();
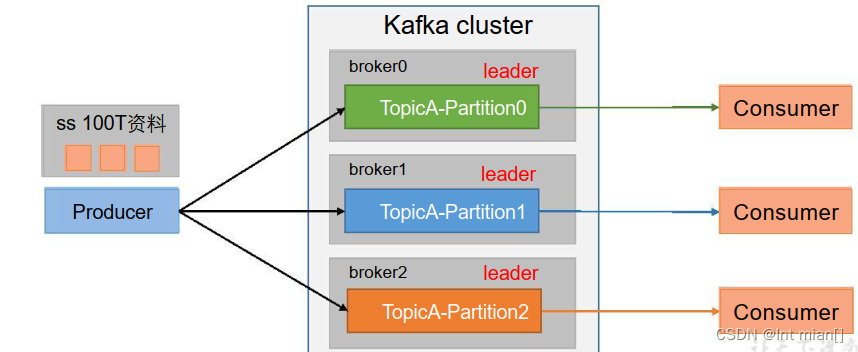
}⛹分区
(1)便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
(2)提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
🤸♂️分区策略



// TODO 发送数据
for (int i = 0; i < 20; i++) {
producer.send(new ProducerRecord<>("first", "yuange" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
System.out.println("topic:"+metadata.topic()+" part:"+metadata.partition());
}
});
Thread.sleep(2);
}指定2毫秒 超时重新选择分区了????

🤸♂️自定义分区
🤸♂️实现类
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String s = value.toString();
int part = 0;
if(s.contains("yuange")){
part = 0;
}else{
part = 1;
}
return part;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}实现
public static void main(String[] args) throws InterruptedException {
// TODO 创建生产者对象
Properties conf = new Properties();
// 指定集群
// public static final String BOOTSTRAP_SERVERS_CONFIG = "bootstrap.servers";
conf.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop1:9092,hadoop2:9092");
// 指定序列化器
conf.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// conf.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
conf.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
conf.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "org.example.kafka.implement.MyPartitioner");
KafkaProducer<String, String> producer = new KafkaProducer<>(conf);
// TODO 发送数据
for (int i = 0; i < 20; i++) {
if (i%2 == 0){
String value = "yuange" + i;
producer.send(new ProducerRecord<>("first", value), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
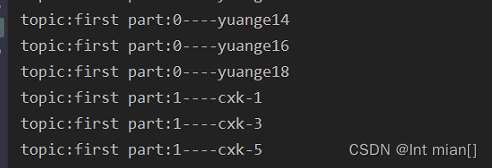
System.out.println("topic:"+metadata.topic()+" part:"+metadata.partition()+value);
}
});
}else {
String value = "cxk-" + i;
producer.send(new ProducerRecord<>("first", value), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
System.out.println("topic:"+metadata.topic()+" part:"+metadata.partition()+value);
}
});
}
}
// TODO 关闭资源
producer.close();
}
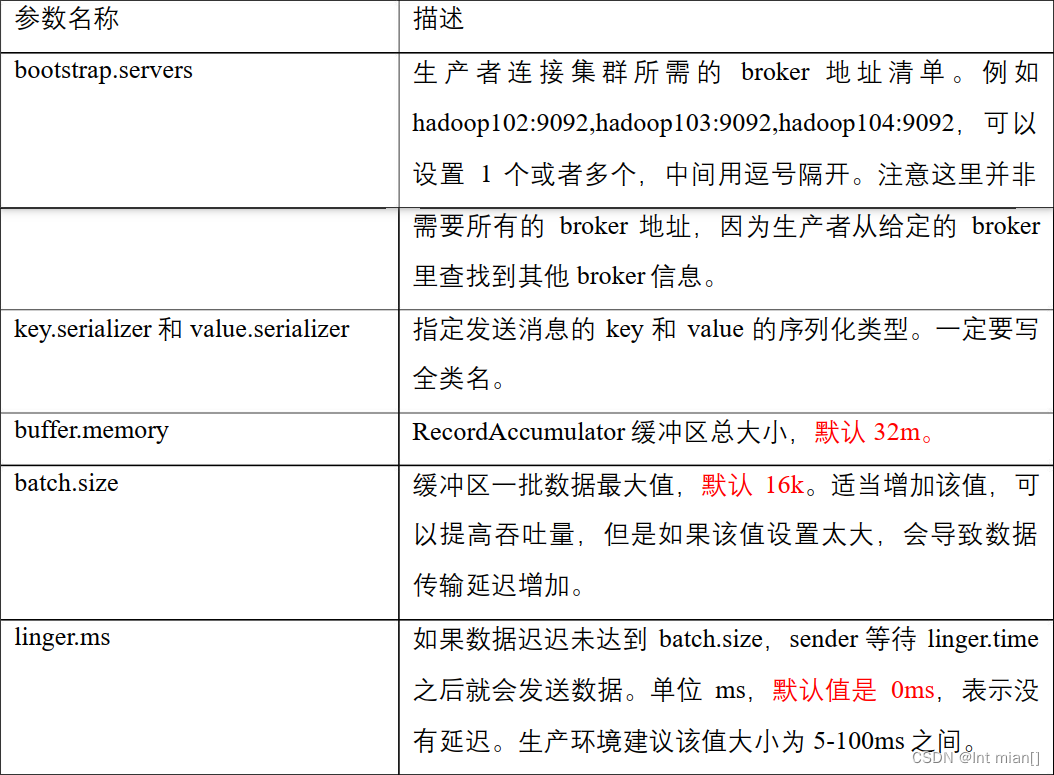
⛹提高吞吐量
batch.size:批次大小,默认16k
linger.ms:等待时间,修改为5-100ms (这两个同时生效,满足一个)compression.type:压缩snappy (弹幕说解压影响性能)
RecordAccumulator:缓冲区大小,修改为64m
// 缓冲区大小
conf.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 32*1024*1024);
// 批次大小
conf.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
// linger.ms
conf.put(ProducerConfig.LINGER_MS_CONFIG, 1);
// 压缩?
conf.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(conf);⛹数据可靠性Ack
🤸♂️0 1 -1三个应答毛病

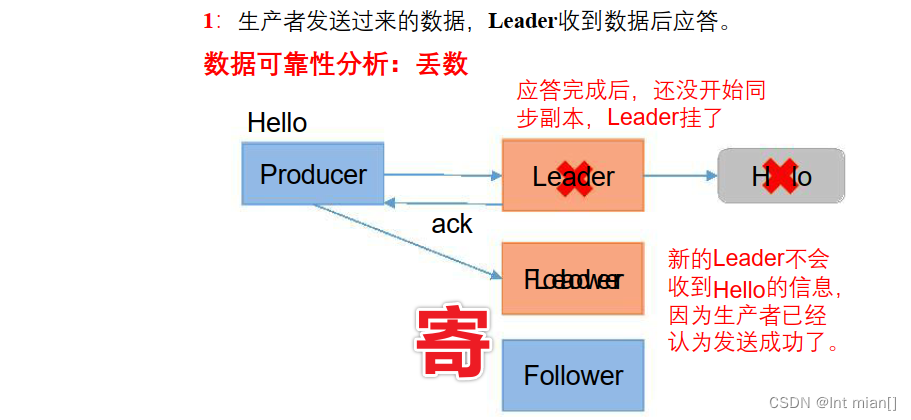
思考:Leader收到数据,所有Follower都开始同步数据,但有一 个Follower,因为某种故障,迟迟不能与Leader进行同步,那这个问 题怎么解决呢?
Leader维护了一个动态的in-sync replica set(ISR),意为和Leader保持同步的Follower+Leader集合(leader:0,isr:0,1,2)。 如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值由replica.lag.time.max.ms参数设定,默认30s。例如2超时,(leader:0, isr:0,1)
数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
- acks=0,生产者发送过来数据就不管了,可靠性差,效率高;
- acks=1,生产者发送过来数据Leader应答,可靠性中等,效率中等;
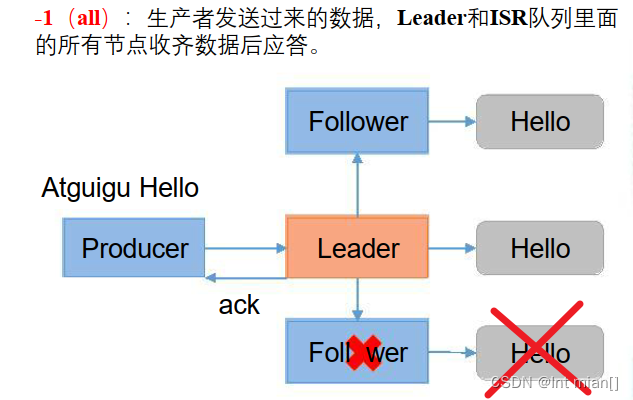
- acks=-1,生产者发送过来数据Leader和ISR队列里面所有Follwer应答,可靠性高,效率低;
acks=0很少使用;
acks=1,一般用于传输普通日志,允许丢个别数据;
acks=-1,一般用于传输和钱相关的数据, 对可靠性要求比较高的场景。
https://kafka.apache.org/documentation/#producerconfigs
conf.put(ProducerConfig.ACKS_CONFIG, "1"); conf.put(ProducerConfig.RETRIES_CONFIG, 3);
数据会重复,之后解决
🤸♂️去重
• 至少一次(At Least Once)= ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2 可以保证数据不丢失,但是不能保证数据不重复
• 最多一次(At Most Once)= ACK级别设置为0 可以保证数据不重复,但是不能保证数据不丢失。
• 精确一次(Exactly Once):对于一些非常重要的信息,比如和钱相关的数据,要求数据既不能重复也不丢失。
Kafka 0.11版本以后,引入了一项重大特性:幂等性和事务。
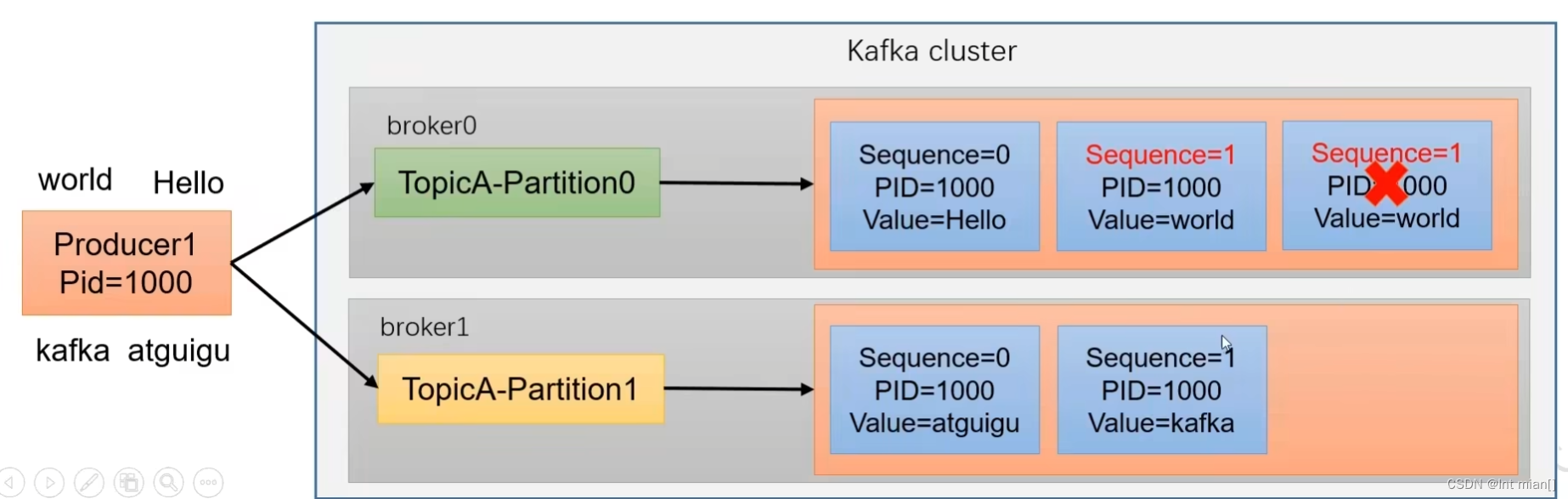
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
重复数据的判断标准:具有<PID, Partition, SeqNumber>相同主键的消息提交时,Broker只会持久化一条。其中PID是Kafka每次重启都会分配一个新的;Partition 表示分区号;Sequence Number是单调自增的。 所以幂等性只能保证的是在单分区单会话内不重复。
开启参数 enable.idempotence 默认为 true,false 关闭
🤸♂️事务
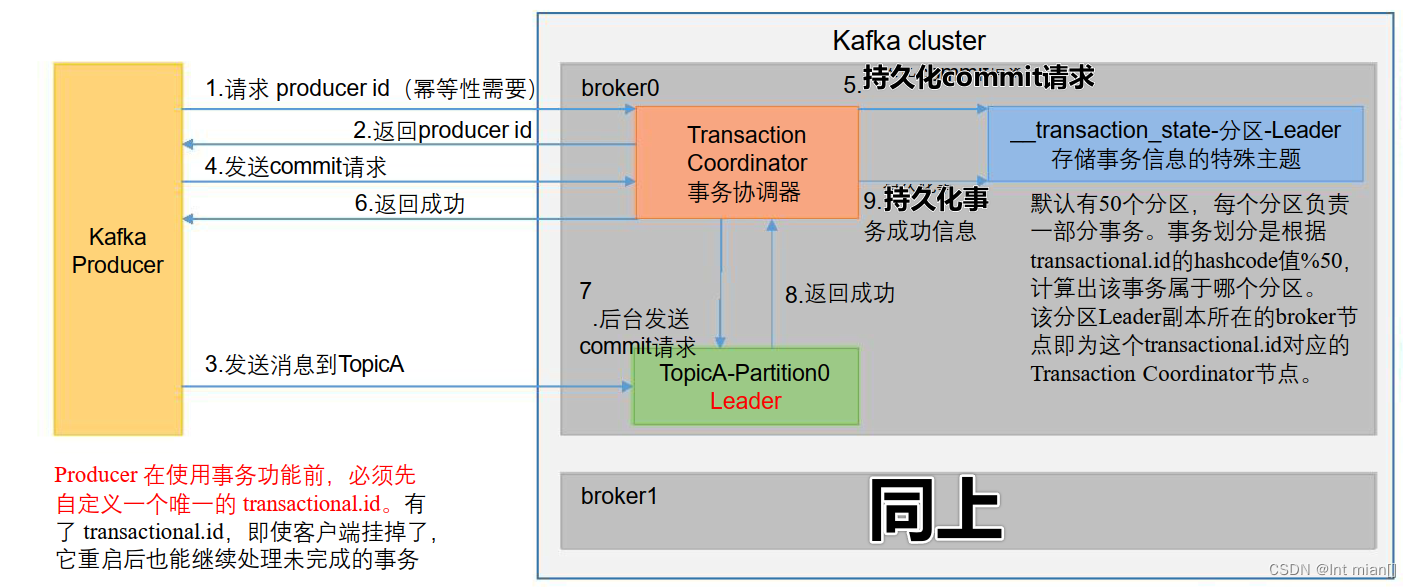
conf.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "shiwuid-01");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(conf);
producer.initTransactions();
producer.beginTransaction();
try {
// TODO 发送数据
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<>("first", "value"+i));
Thread.sleep(300);
}
producer.send(new ProducerRecord<>("first", "----------"));
producer.commitTransaction(); // 提交事务
}catch (Exception e){
producer.abortTransaction(); // 终止事务
}⛹有序
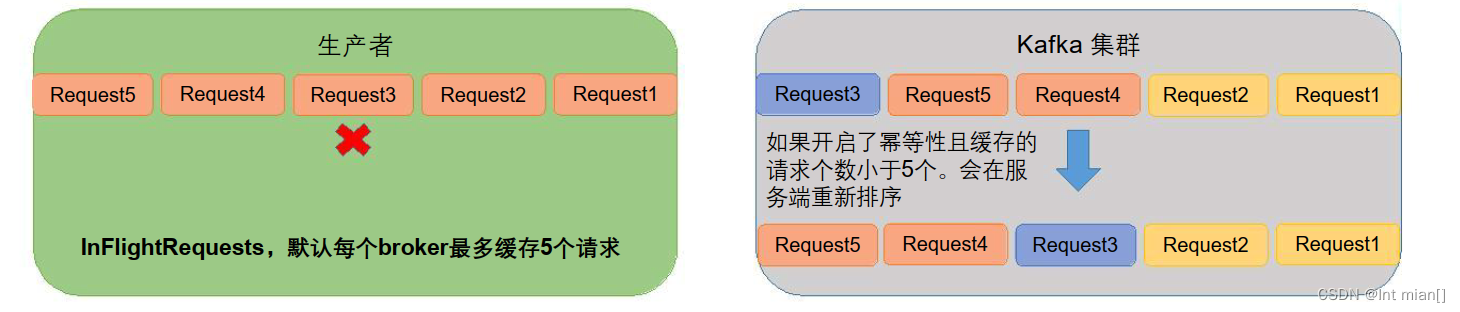
1 )kafka在1.x版本之前保证数据单分区有序,条件如下:
max.in.flight.requests.per.connection=1(不需要考虑是否开启幂等性)
2 )kafka在1.x及以后版本保证数据单分区有序,条件如下:
1)未开启幂等性
max.in.flight.requests.per.connection需要设置为1。
2)开启幂等性
max.in.flight.requests.per.connection需要设置 ≤ 5。
原因说明:因为在kafka1.x以后,启用幂等后,kafka服务端会缓存producer发来的最近5个request的元数据, 故无论如何,都可以保证最近5个request的数据都是有序的。(seqence)
💃Broker
👩🚀Broker 工作流程
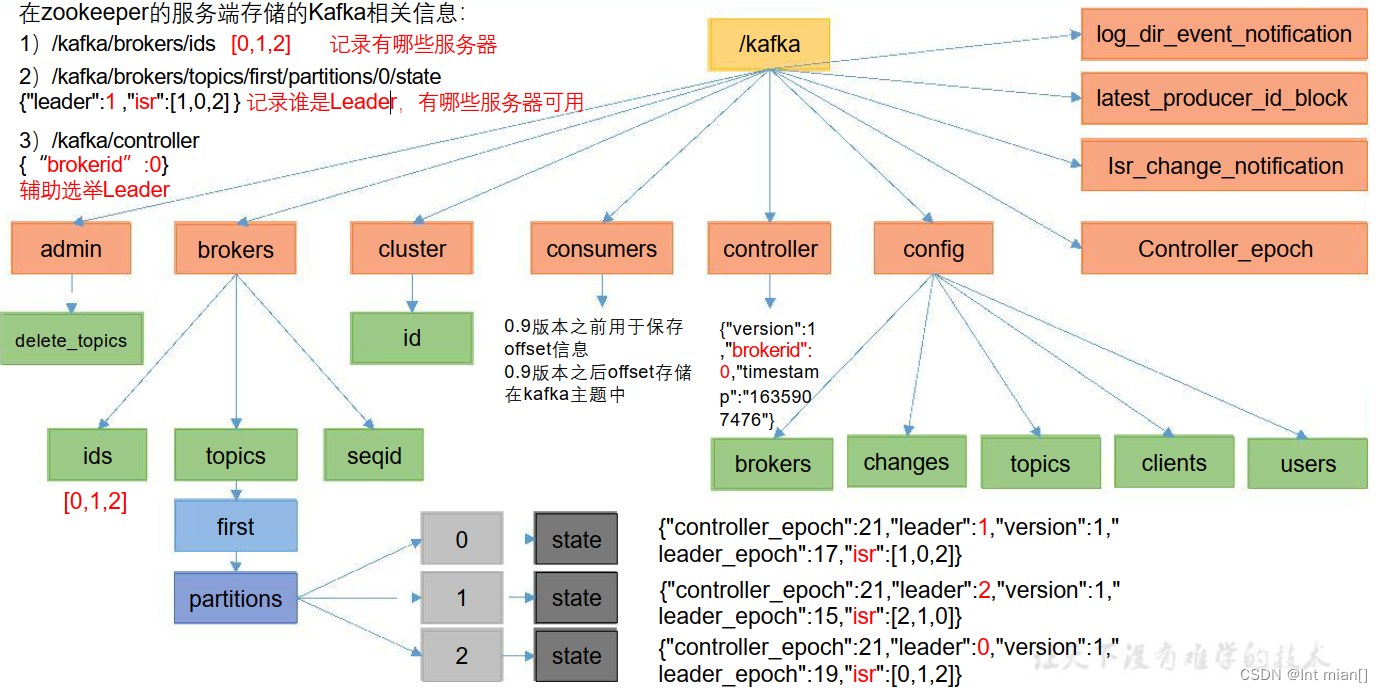
🤸♂️Zookeeper 存储的 Kafka 信息
bin/zkCli.sh
通过 ls 命令可以查看 kafka 相关信息。
🤸♂️总体工作流程

👩🚀Kafka 副本
副本基本信息
1)Kafka 副本作用:提高数据可靠性。
2)Kafka 默认副本 1 个,生产环境一般配置为 2 个,保证数据可靠性;太多副本会增加磁盘存储空间,增加网络上数据传输,降低效率。
3)Kafka 中副本分为:Leader 和 Follower。Kafka 生产者只会把数据发往 Leader,然后 Follower 找 Leader 进行同步数据。4)Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)。
- AR = ISR + OSR
- ISR,表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms 参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。
- OSR,表示 Follower 与 Leader 副本同步时,延迟过多的副本
Leader 选举流程
Kafka 集群中有一个 broker 的 Controller 会被选举为 Controller Leader,负责管理集群broker 的上下线,所有 topic 的分区副本分配和 Leader 选举等工作。
Controller 的信息同步工作是依赖于 Zookeeper 的。
1. kafka每启动一个集群,就会在zk里面注册,每个broker都有一个controller
2. 谁先注册好谁就是controller
3. leader监听所有的broker
4. 选举出来的controller选举leader
5. leader自己的信息在zk也有一个空间
6. 其他follower从这个空间拉取leader信息
7. 1号leader寄
8. 重新选举leader,下一个就是0
🧠整理思路:
一个分区分好几个块,leader、follower都是拿分区说事
leader是负责在生产者和消费者中间交互的

follower挂了
两个概念:
LEO(Log End Offset):每个副本的最后一个offset,LEO其实就是最新的offset + 1。
HW(High Watermark):所有副本中最小的LEO
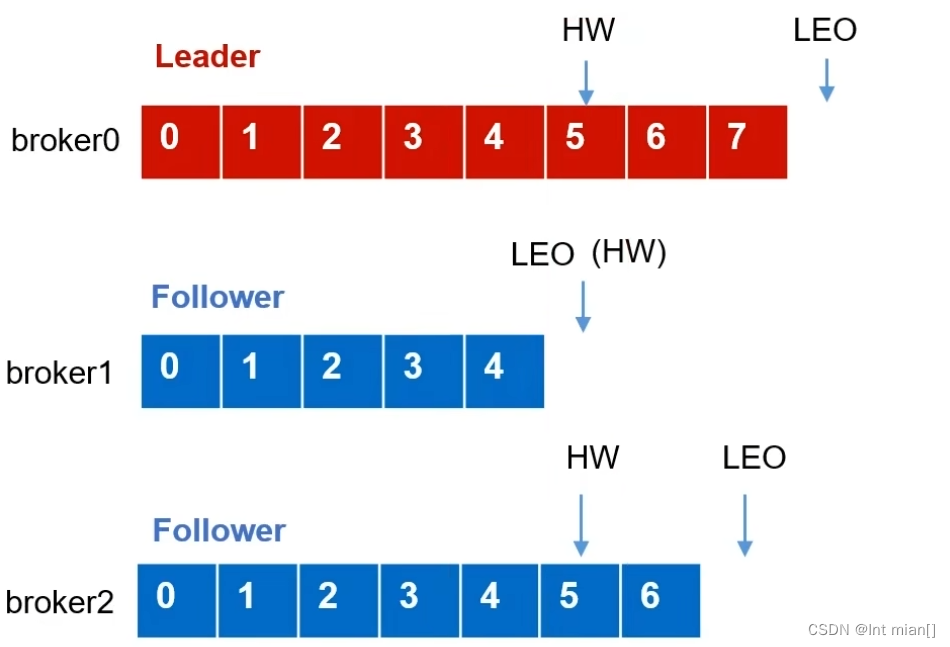

讲到这了突然特么来了一句:消费者只能拉取到HW
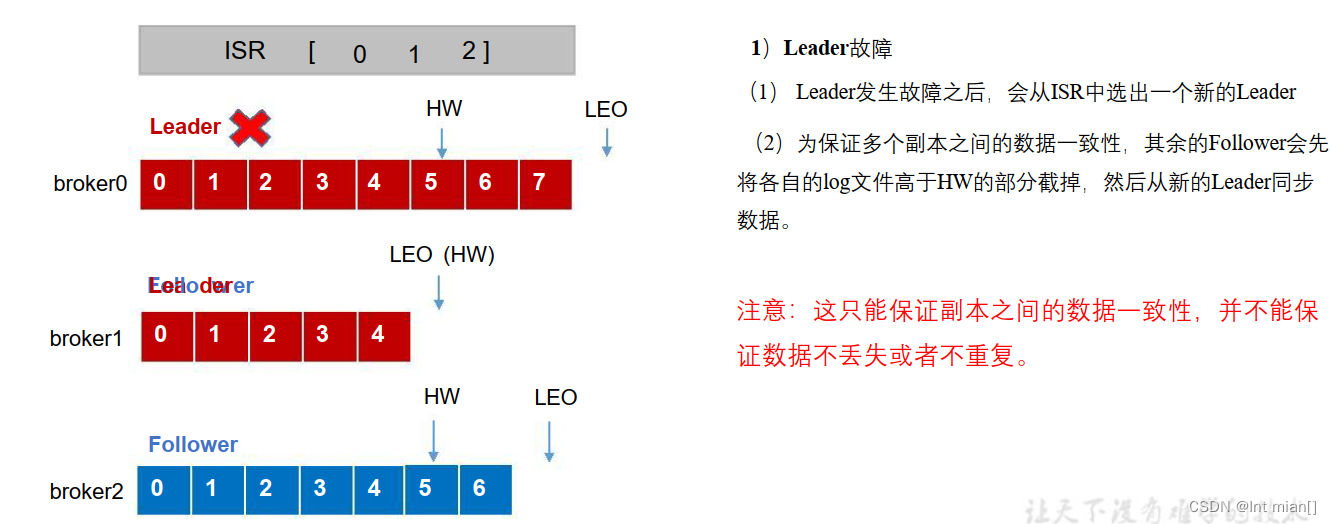
leader寄了
人话:
leader寄了之后,选出来一个follower作为新leader,以这个新的leader目前有的数据量为基准,多了给扔掉,不能比新王多!但是数据丢掉了
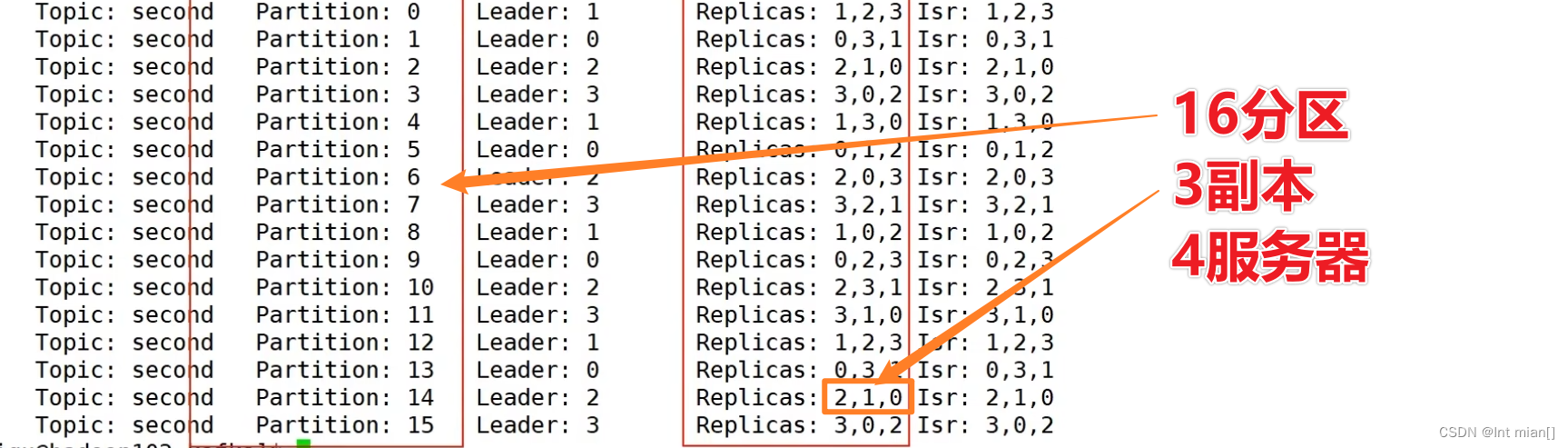
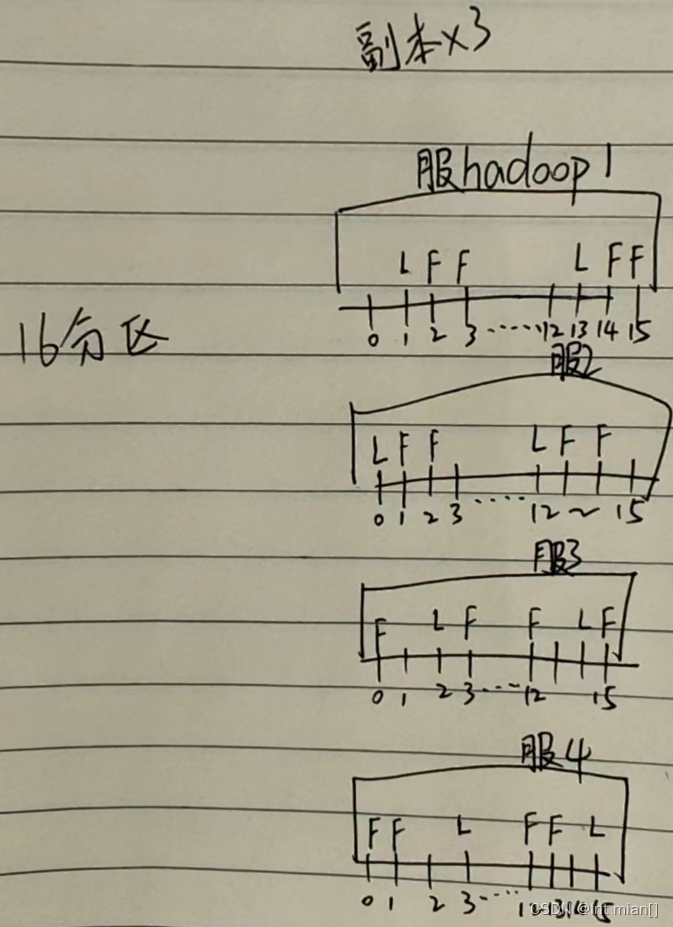
分区副本分配
就是一种负载均衡
Leader Partition 负载平衡
有平衡的机制
👩🚀文件存储
🤸♂️存储机制
Topic 数据的存储机制
Topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是Producer生产的数据。Producer生产的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment。每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名+分区序号,例如:first-0。
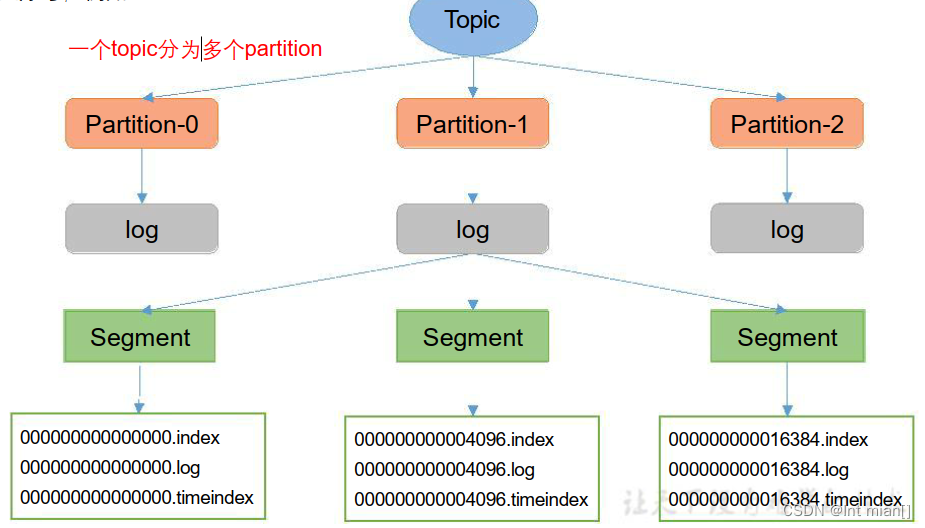
存在KAFKA_HOME/datas下
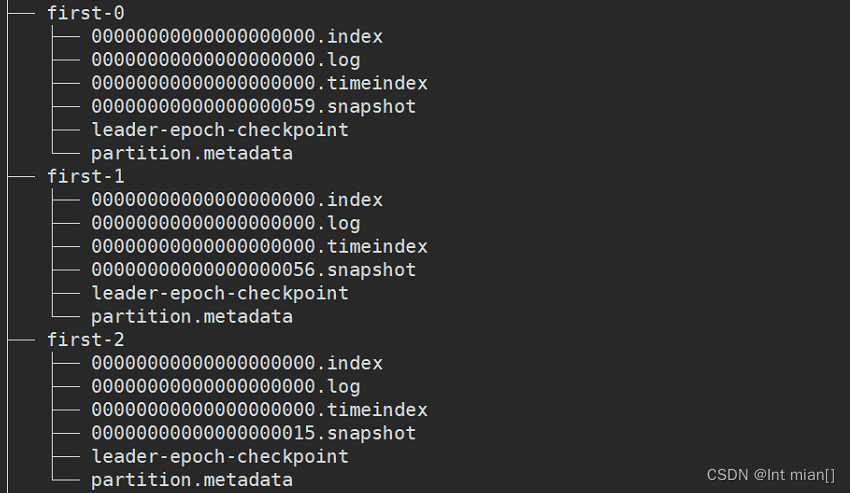
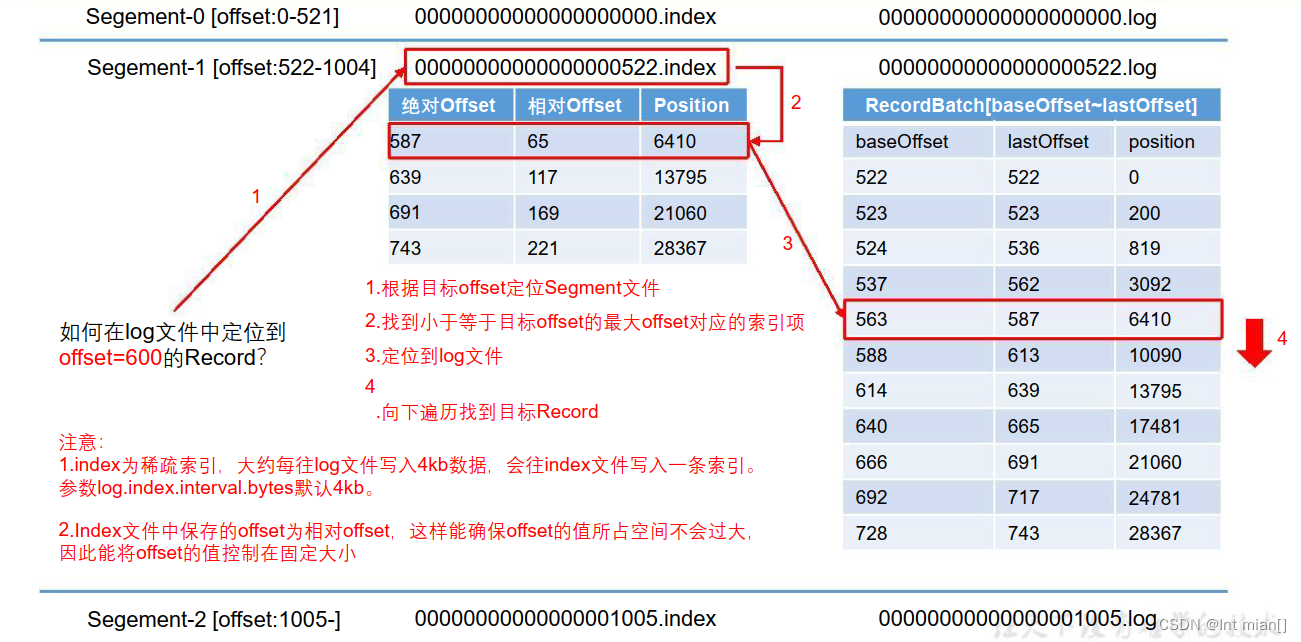
1.index为稀疏索引,大约每往log文件写入4kb数据,会往index文件写入一条索引。
参数log.index.interval.bytes默认4kb
2.Index文件中保存的offset为相对offset,这样能确保offset的值所占空间不会过大
因此能将offset的值控制在固定大小
文件清理策略
Kafka 中默认的日志保存时间为 7 天,可以通过调整如下参数修改保存时间。
log.retention.hours,最低优先级小时,默认 7 天。
log.retention.minutes,分钟。
log.retention.ms,最高优先级毫秒。
log.retention.check.interval.ms,负责设置检查周期,默认 5 分钟。log.retention.bytes,默认等于-1,表示无穷大。
清理策略有 delete 和 compact 两种。
1)delete 日志删除:将过期数据删除
⚫ log.cleanup.policy = delete 所有数据启用删除策略
1)基于时间:默认打开。以 segment 中所有记录中的最大时间戳作为该文件时间戳。
2)基于大小:默认关闭。超过设置的所有日志总大小,删除最早的 segment。
2)compact 日志压缩
compact日志压缩:对于相同key的不同value值,只保留最后一个版本。
⚫ log.cleanup.policy = compact 所有数据启用压缩策略
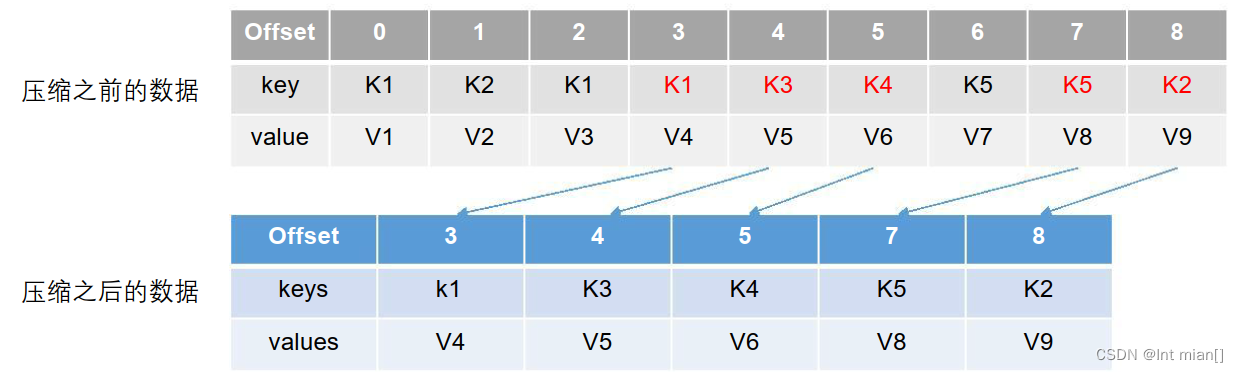
压缩后的offset可能是不连续的,比如上图中没有6,当从这些offset消费消息时,将会拿到比这个offset大 的offset对应的消息,实际上会拿到offset为7的消息,并从这个位置开始消费。
这种策略只适合特殊场景,比如消息的key是用户ID,value是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。
👩🚀高效读写数据
- Kafka 本身是分布式集群,可以采用分区技术,并行度高
- 读数据采用稀疏索引,可以快速定位要消费的数据
- 顺序写磁盘(同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。 )
- 页缓存 + 零拷贝技术 (零拷贝:Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。Kafka Broker应用层不关心存储的数据,所以就不用走应用层,传输效率高。
PageCache页缓存:Kafka重度依赖底层操作系统提供的PageCache功能。当上层有写操作时,操作系统只是将数据写入PageCache。当读操作发生时,先从PageCache中查找,如果找不到,再去磁盘中读取。实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用。 )
💃Kafka 消费者
👩🚀消费方式 pull
pull(拉)模式:
consumer采用从broker中主动拉取数据。
Kafka采用这种方式。不足之处是,如果Kafka没有数据,消费者可能会陷入循环中,一直回空数据。
push(推)模式:
Kafka没有采用这种方式,因为由broker 决定消息发送速率,很难适应所有消费者的消费速率。例如推送的速度是50m/s, Consumer1、Consumer2就来不及处理消息。
👩🚀Kafka 消费者工作流程
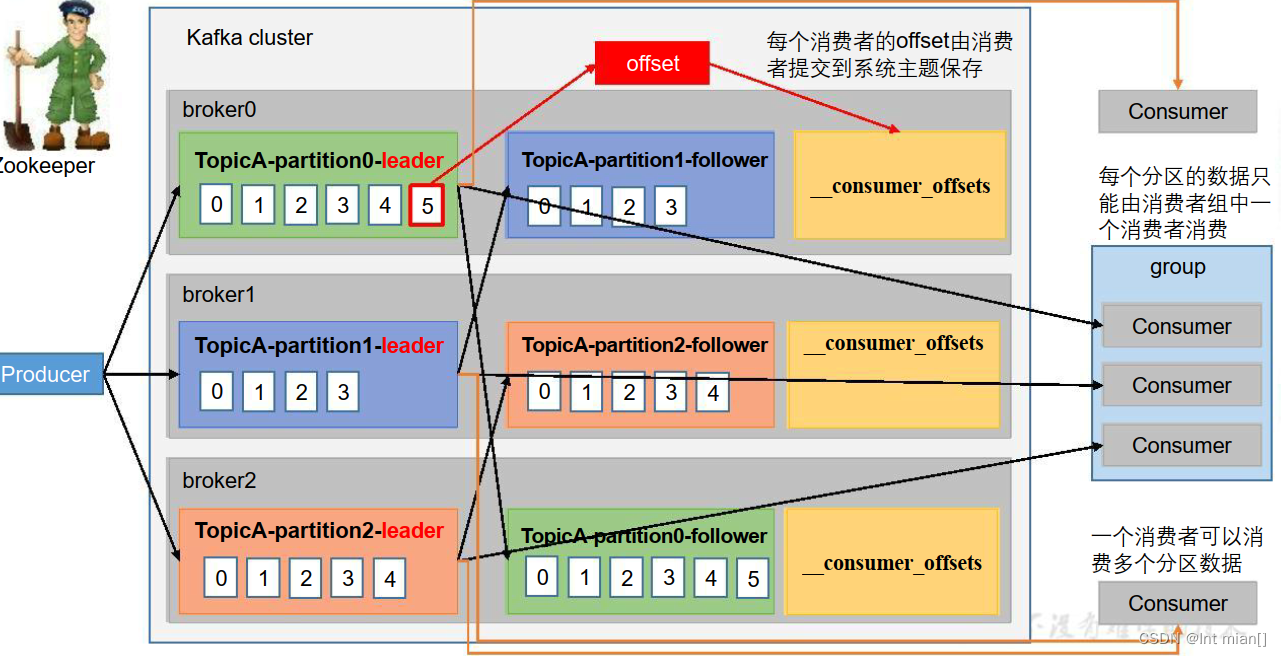
消费者组原理
Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
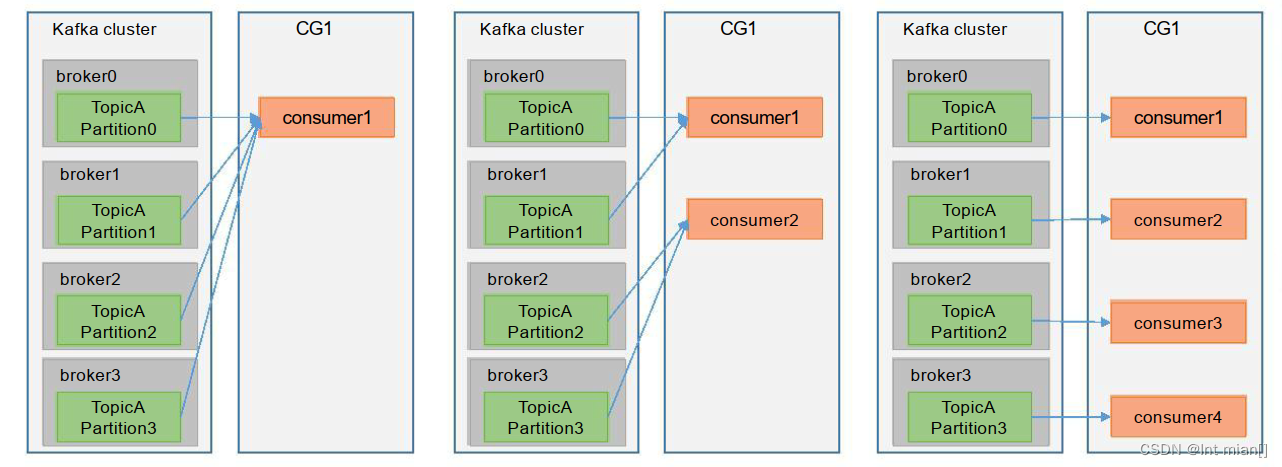
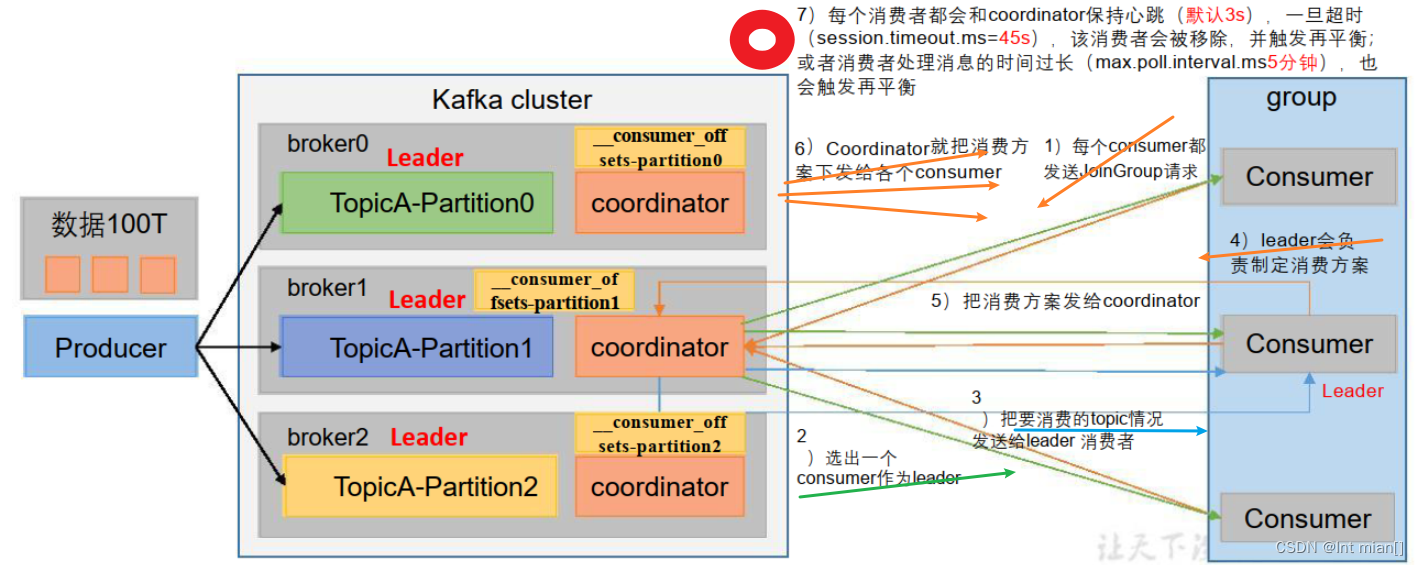
1、coordinator:辅助实现消费者组的初始化和分区的分配。
coordinator节点选择 = groupid的hashcode值 % 50( __consumer_offsets的分区数量)
例如: groupid的hashcode值 = 1,1% 50 = 1,那么__consumer_offsets 主题的1号分区,在哪个broker上,就选择这个节点的coordinator作为这个消费者组的老大。消费者组下的所有的消费者提交offset的时候就往这个分区去提交offset。
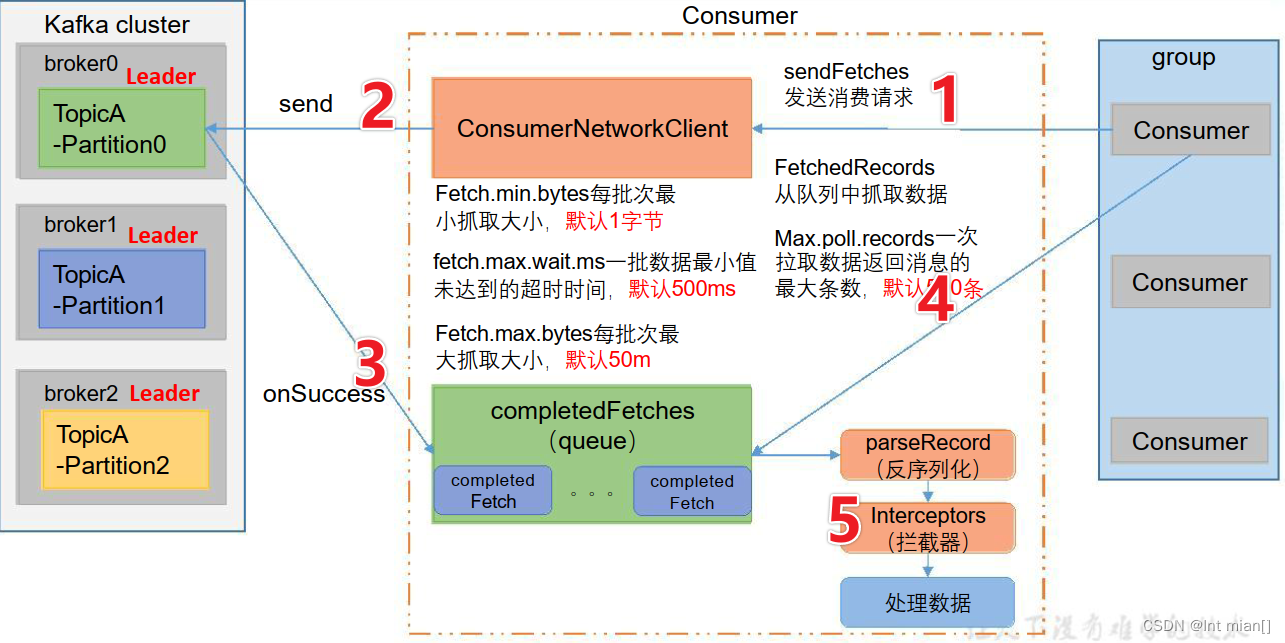
消费流程
👩🚀消费案例
消费一个主题
public static void main(String[] args) throws InterruptedException {
Properties conf = new Properties();
conf.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop1:9092");
conf.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
conf.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
conf.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(conf);
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
consumer.subscribe(topics); // 这意味着消费者将开始从指定的主题接收消息并进行处理
while (true){
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> rec : consumerRecords){
System.out.println(rec);
}
}
}
消费一个分区
上面分配分区改为:

消费者组
nb,就是把上面那个指定分配分区的复制三份,只要groupid相同,就是一个逻辑组
👩🚀分区的分配策略、再平衡
Q:一个consumer group中有多个consumer组成,一个 topic有多个partition组成,现在的问题是,到底由哪个consumer来消费哪个 partition的数据?
A:Kafka有四种主流的分区分配策略: Range、RoundRobin、Sticky、CooperativeSticky。
可以通过配置参数partition.assignment.strategy,修改分区的分配策略。
默认策略是Range + CooperativeSticky。
Kafka可以同时使用多个分区分配策略。
Range 以及再平衡
Range 是对每个 topic 而言的。 首先对同一个 topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。
假如现在有 7 个分区,3 个消费者,排序后的分区将会是0,1,2,3,4,5,6;消费者排序完之后将会是C0,C1,C2。
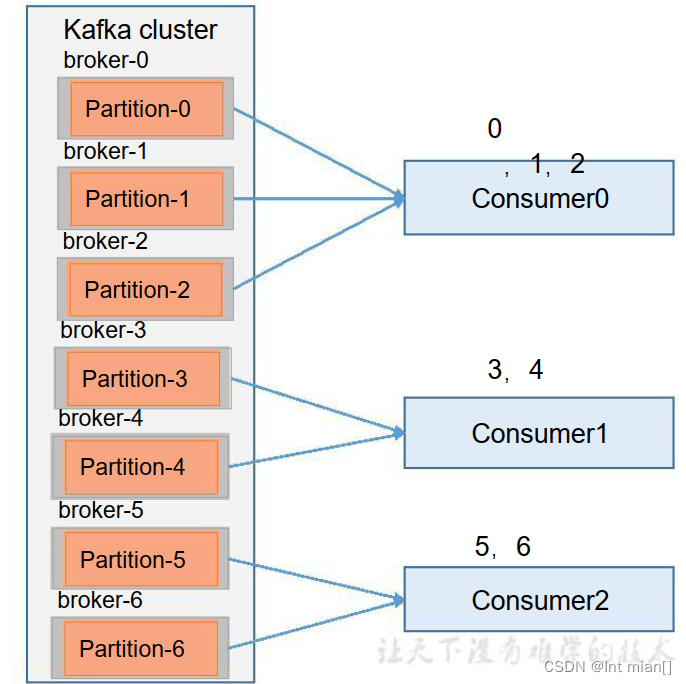
但是如果有 N 多个 topic,那么针对每个 topic,消费者 C0都将多消费 1 个分区,topic越多,C0消费的分区会比其他消费者明显多消费 N 个分区 !!!
再分配:消费者 0 已经被踢出消费者组,所以重新按照 range 方式分配。
RoundRobin 以及再平衡
RoundRobin 针对集群中所有Topic而言。
RoundRobin 轮询分区策略,是把所有的 partition 和所有的consumer 都列出来,然后按照hashcode 进行排序,最后通过轮询算法来分配 partition 给到各个消费者。
Sticky 以及再平衡
粘性分区定义:在执行一次新的分配之前, 考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。
首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化。
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1号消费者:消费到 2、5、3 号分区数据。
2号消费者:消费到 4、6 号分区数据。
0号消费者的任务会按照粘性规则,尽可能均衡的随机分成 0 和 1 号分区数据,分别由 1 号消费者或者 2 号消费者消费。to
1号消费者:消费到 2、3、5 号分区数据。
2号消费者:消费到 0、1、4、6 号分区数据。
👩🚀offset 位移
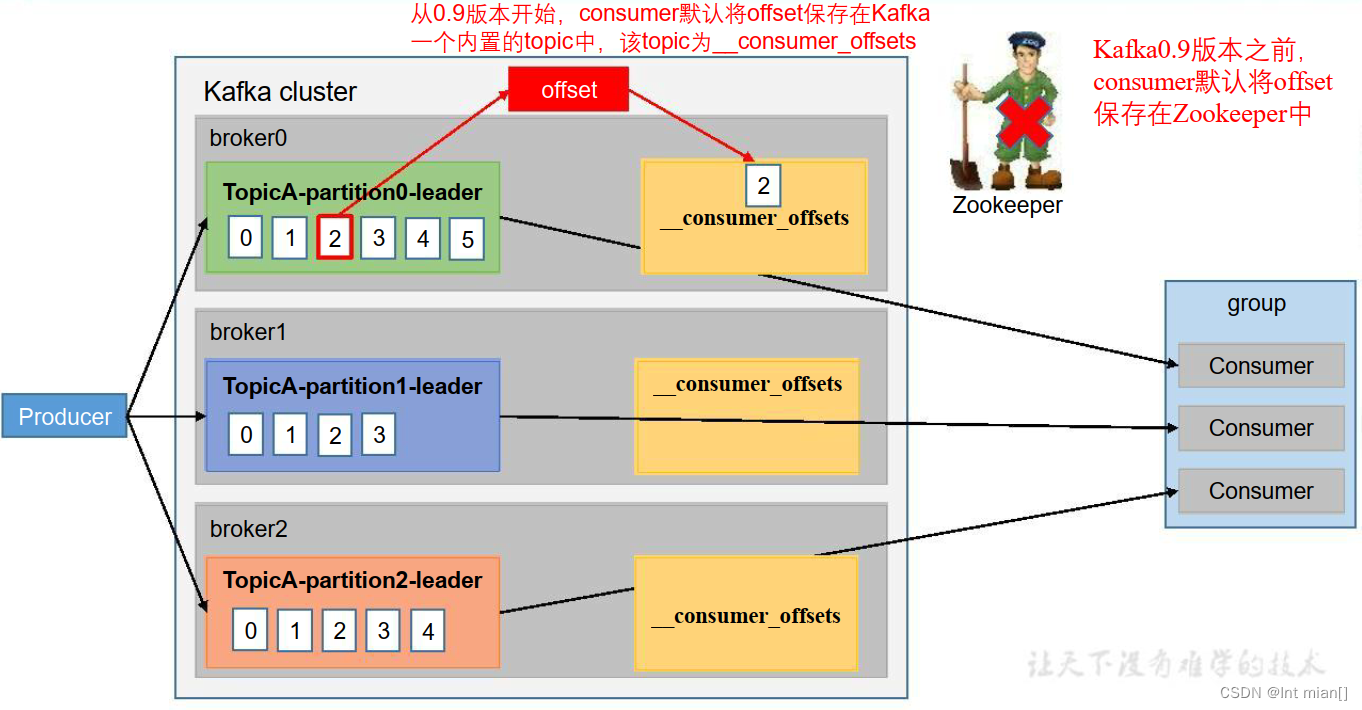
__consumer_offsets 主题里面采用 key 和 value 的方式存储数据。key 是 group.id+topic+ 分区号,value 就是当前 offset 的值。每隔一段时间,kafka 内部会对这个 topic 进行compact,也就是每个 group.id+topic+分区号就保留最新数据
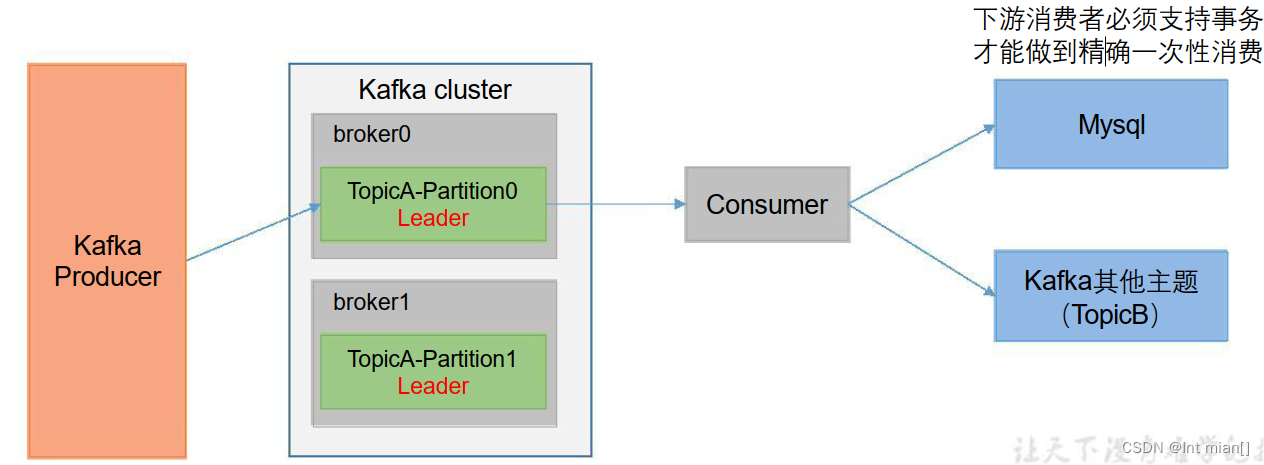
👩🚀消费者事务
如果想完成Consumer端的精准一次性消费,那么需要Kafka消费端将消费过程和提交offset过程做原子绑定。此时我们需要将Kafka的offset保存到支持事务的自定义介质(比如MySQL)
👩🚀数据积压(消费者如何提高吞吐量)
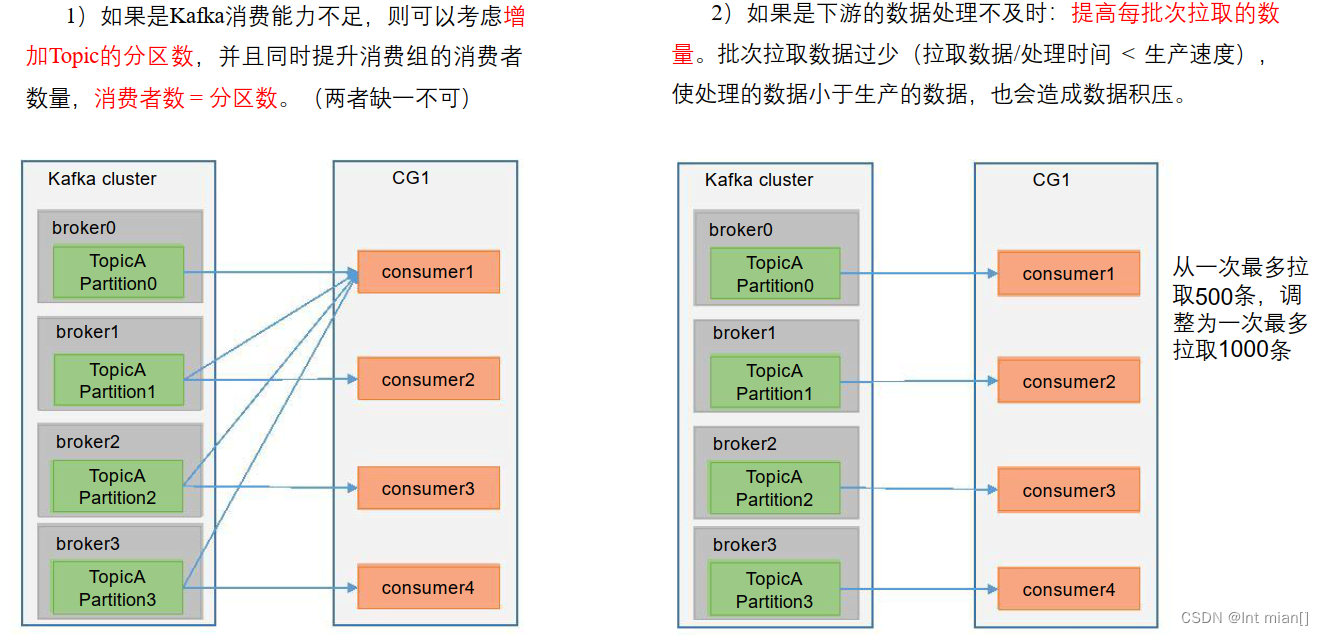
💃Kafka-Eagle 监控
Kafka-Eagle 框架可以监控 Kafka 集群的整体运行情况,在生产环境中经常使用。
安装 改配置
修改KAFKA_HOME/bin/kafka-server-start.sh
其中一段改为,分发
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
# export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
Kafka-Eagle 安装
https://github.com/smartloli/kafka-eagle-bin/archive/v3.0.1.tar.gz
解压两重tar文件到自己的目录
修改配置文件 HOME/conf/system-config.properties
######################################
# multi zookeeper & kafka cluster list
# Settings prefixed with 'kafka.eagle.' will be deprecated, use 'efak.' instead
#######################################
efak.zk.cluster.alias=cluster1
cluster1.zk.list=hadoop1:2181,hadoop:2181,hadoop3:2181/kafka
#####################################
# kafka offset storage
#####################################
# offset保存在 kafka
cluster1.efak.offset.storage=kafka
# 配置 mysql连接
efak.driver=com.mysql.jdbc.Driver
efak.url=jdbc:mysql://hadoop102:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=123456幻景变量
# kafkaEFAK
export KE_HOME=/opt/module/efak
export PATH=$PATH:$KE_HOME/bin 原神启动
启动之前需要先启动 ZK 以及 KAFKA。
[2023-10-23 11:18:02] INFO: Port Progress: [##################################################] | 100%
[2023-10-23 11:18:06] INFO: Config Progress: [##################################################] | 100%
[2023-10-23 11:18:09] INFO: Startup Progress: [##################################################] | 100%
[2023-10-23 11:17:59] INFO: Status Code[0]
[2023-10-23 11:17:59] INFO: [Job done!]
Welcome to
______ ______ ___ __ __
/ ____/ / ____/ / | / //_/
/ __/ / /_ / /| | / ,<
/ /___ / __/ / ___ | / /| |
/_____/ /_/ /_/ |_|/_/ |_|
( Eagle For Apache Kafka® )
Version 2.0.8 -- Copyright 2016-2021
*******************************************************************
* EFAK Service has started success.
* Welcome, Now you can visit 'http://192.168.88.128:8048'
* Account:admin ,Password:123456
*******************************************************************
* <Usage> ke.sh [start|status|stop|restart|stats] </Usage>
* <Usage> https://www.kafka-eagle.org/ </Usage>
*******************************************************************
[root@hadoop1 efak]#
登录页面查看监控数据 http://192.168.88.128:8048

💃Kafka-Kraft 模式
优点
干掉了zk
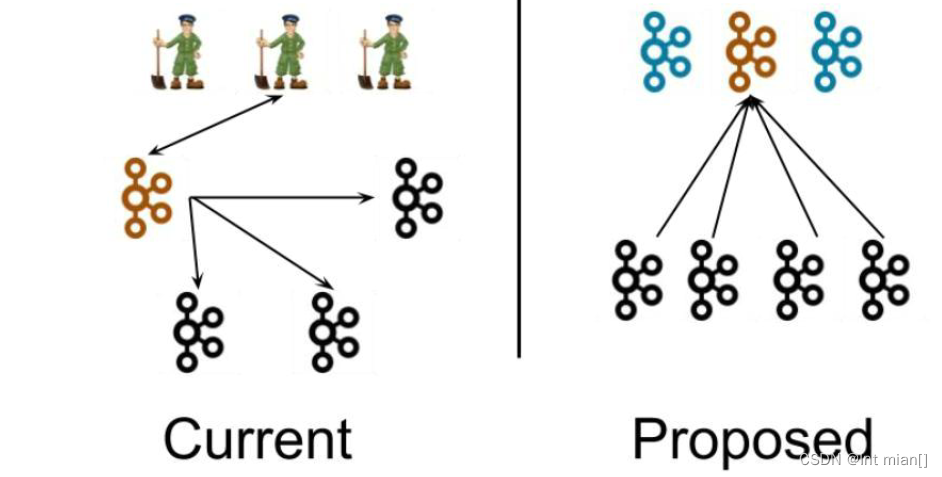
左图为 Kafka 现有架构,元数据在 zookeeper 中,运行时动态选举 controller,由controller 进行 Kafka 集群管理。右图为 kraft 模式架构(实验性),不再依赖 zookeeper 集群, 而是用三台 controller 节点代替 zookeeper,元数据保存在 controller 中,由 controller 直接进行 Kafka 集群管理。
- Kafka 不再依赖外部框架,而是能够独立运行;
- controller 管理集群时,不再需要从 zookeeper 中先读取数据,集群性能上升;
- 由于不依赖 zookeeper,集群扩展时不再受到 zookeeper 读写能力限制;
- controller 不再动态选举,而是由配置文件规定。这样我们可以有针对性的加强
- controller 节点的配置,而不是像以前一样对随机 controller 节点的高负载束手无策。
安装配置
重新解压一个新的kafka安装包
cd /export/server/kafka2/config/kraft/
vim server.properties
# The node id associated with this instance's roles
node.id=1、2、3(三个集群分别分别分别设置不同的id)# The connect string for the controller quorum(每个都这么设)
controller.quorum.voters=1@hadoop1:9093,2@hadoop2:9093,3@hadoop3:9093
advertised.listeners=PLAINTEXT://hadoop1、2、3:9092(三个分别设)# A comma separated list of directories under which to store log files 日志目录改了
log.dirs=/export/server/kafka2/datas
分发
初始化集群数据目录
bin/kafka-storage.sh random-uuid
omVzwxZORTqQuFNIFX8Rnw
用该 ID 格式化 kafka 存储目录(三台节点)
bin/kafka-storage.sh format -t J7s9e8PPTKOO47PxzI39VA -c /opt/module/kafka2/config/kraft/server.properties
缘神启动
bin/kafka-server-start.sh -daemon config/kraft/server.properties