文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。

面试官:介绍一下HashMap的扩容机制
参考答案:
1、数组的初始容量为16,而容量是以2的次方扩充的,一是为了提高性能使用足够大的数组,二是为了能使用位运算代替取模预算(据说提升了5~8倍)。
2、数组是否需要扩充是通过负载因子判断的,如果当前元素个数为数组容量的0.75时,就会扩充数组。这个0.75就是默认的负载因子,可由构造器传入。我们也可以设置大于1的负载因子,这样数组就不会扩充,牺牲性能,节省内存。
3、为了解决碰撞,数组中的元素是单向链表类型。当链表长度到达一个阈值时(7或8),会将链表转换成红黑树提高性能。而当链表长度缩小到另一个阈值时(6),又会将红黑树转换回单向链表提高性能。
4、对于第三点补充说明,检查链表长度转换成红黑树之前,还会先检测当前数组数组是否到达一个阈值(64),如果没有到达这个容量,会放弃转换,先去扩充数组。所以上面也说了链表长度的阈值是7或8,因为会有一次放弃转换的操作。
扩展阅读
例如我们从16扩展为32时,具体的变化如下所示:

因此元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:

因此,我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。可以看看下图为16扩充为32的resize示意图:
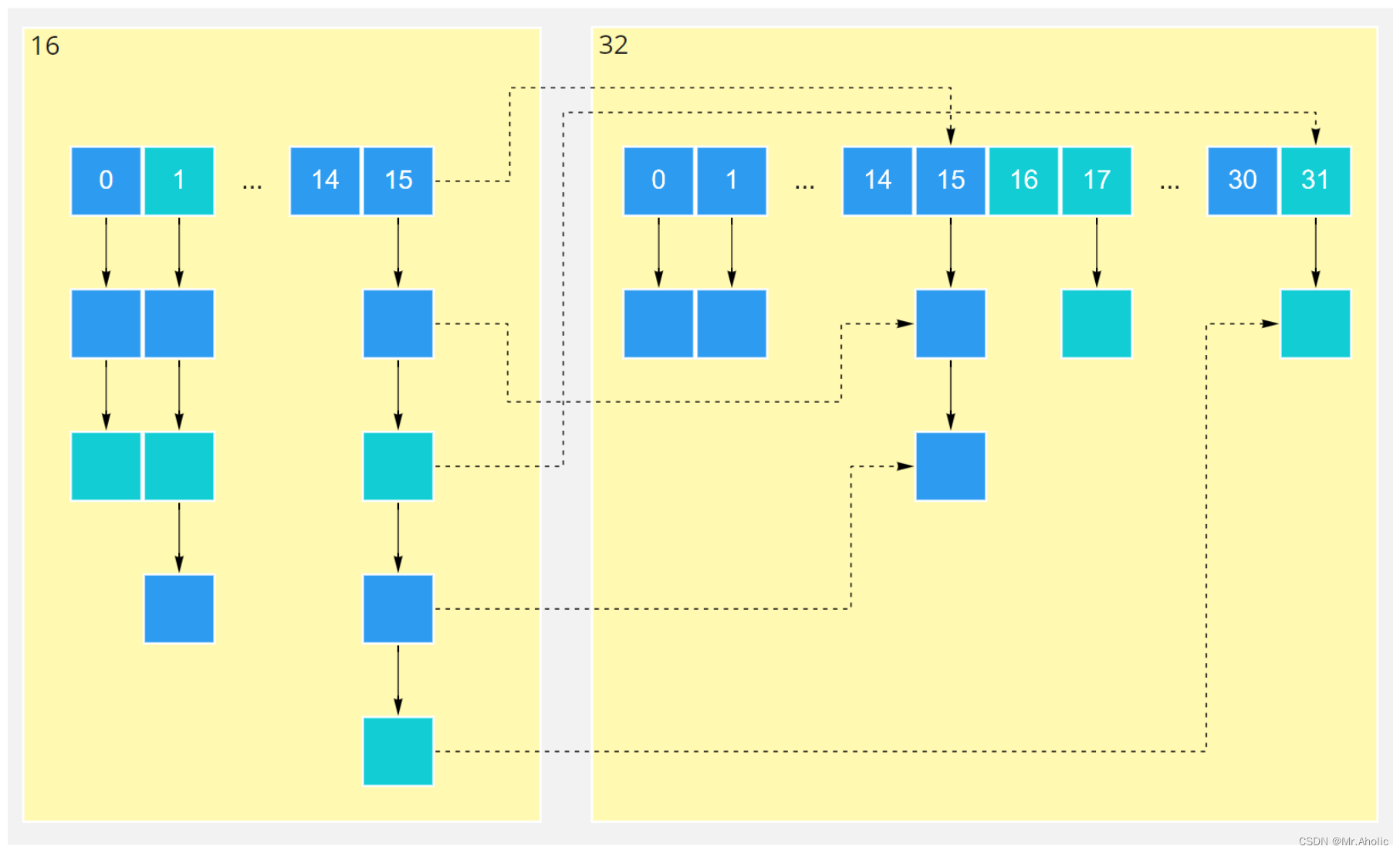
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。