阿里在农历2021到来之前却是又搞了一个大动作!把阿里这一年在应对高并发流量的技术经验整合成一份技术小册开源分享供大家学习借鉴。我也是昨天才发现这份小册开源至Github上居然一夜爆火!
看了小册之后才知道,原来阿里在应对高并发大流量时也会采用类似“抵御洪水”的方案,我简单总结归纳了一下,大概可以分为三种方法:
分治∶采用分布式部署的方式把流量分流开,让每个服务器都承担一部分并发和流量。
缓存:使用缓存来提高系统的性能,就好比用“拓宽河道”的方式抵抗高并发大流量的冲击。
异步:在某些场景下,未处理完成之前,我们可以让请求先返回,在数据准备好之后再通知请求方,这样可以在单位时间内处理更多的请求。
这三种方法也细化出来很多内容,不多bb,下面我就为大家展示一下主要内容:
小册分为7大部分,一共有323页,如果有朋友需要,查看我工作经历一栏,即可百分百免费获取高清小册。
阿里高并发小册

池化技术:减少频繁创建数据库连接的性能损耗
数据库传统调用方式下,每次执行SQL都需要重新建立连接,这部分带你解决频繁地建立数据库连接耗费时间长导致了访问慢的问题。

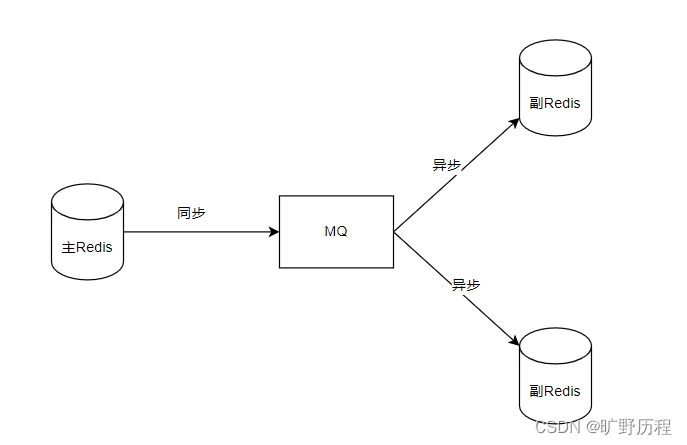
高并发场景下,数据库和NoSQL互补
以垂直电商系统为例,带你掌握如何用NoSQL 数据库和关系型数据库互补,共同承担高并发和大流量的冲击。

缓存的正确使用姿势
这部分带你了解一下使用缓存的正确姿势,比如缓存的读写策略是什么样的,如何做到缓存的高可用以及如何应对缓存穿透。通过了解这些内容,你会对缓存的使用有深刻的认识,这样在实际工作中就可以在缓存使用上游刃有余了。

如何选择缓存的读写策略?

缓存如何做到高可用?

缓存穿透了怎么办?
消息队列
关于消息队列是什么,你可能有所了解了,这一部分主要带大家揭开消息队列的神秘面纱。

秒杀时如何处理每秒上万次的下单请求?

如何降低消息队列系统中消息的延迟?
分布式微服务


微服务拆分原则

分布式系统寻址
服务端监控

降级熔断

实战
实战部分用完整的实例把前面所有的技术串起来

计数系统设计

信息流设计




![【点云检测】OpenPCDet 教程系列 [1] 安装 与 ROS运行](https://img-blog.csdnimg.cn/8b5aa81bc78f4f6fa46080dcec6d8d72.png)