当我们搭建集群之前,先要想明白需要解决哪些问题,搞清楚这个之前先回想一下单节点、单实例、单机有哪些问题?
- 单点故障:只有一台Redis的话,如果出现故障,那么整个服务都不可用
- 缓存容量:单台Redis的缓存容量有限,在多数据的场景下不适合使用
- 访问压力:单台Redis在高并发的生产环境下是会承受很大压力,有可能压力过高而崩溃
问题是知道了,那么怎么解决这些问题呢?为了解决这些问题,我们需要对服务器进行集群,这儿引入一个概念:AKF拆分原则。
在了解AKF拆分原则前,先分析单节点的单点故障这个问题。既然单节点容易宕机,那么就可以进行复制,一变多。就会涉及到三个概念:主从、主主、主备。
主主:多台服务器同时对外提供读写。
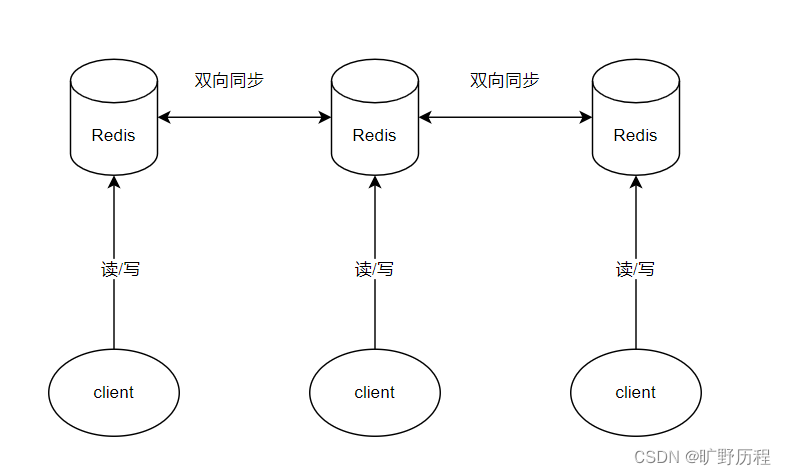
主从:主机可以读写,但是一般只对外提供写,从机对外提供读:
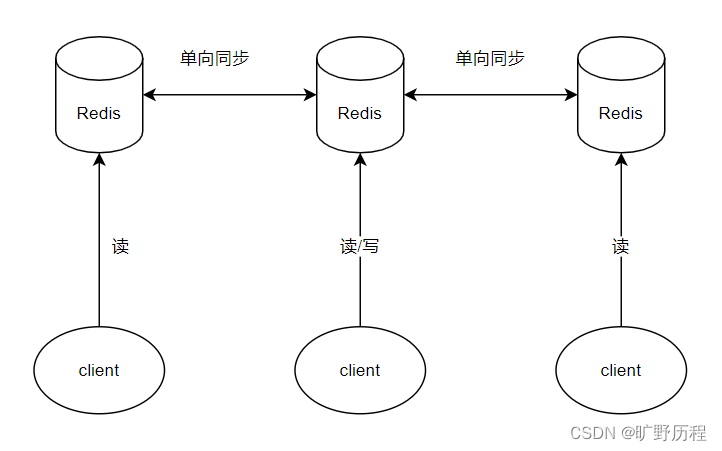
主备:主机提供读写,备机不对外提供服务,当主机挂了的时候,备机通过选举产生主机对外提供服务。

AKF拆分原则
AKF是从X、Y、Z三个轴方向去尝试解决上述3个问题。
X轴
从X角度,可以使用多台 Redis,做第一台Redis的副本,这种拆分可以看成另一台机器的镜像。这个主要是为了解决单点故障的问题!

如上图所示,将 Redis 的数据复制到多台 Redis 上,这样就算其中一台Redis出故障了,也还有其他Redis可以提供服务。
随着发展,客户端还可以对主Redis进行增删改,对副Redis进行只读,这就要实现了读写分离。

基于X轴的解决方案,是全量镜像。
X轴上的主Redis和副Redis的容量是一样的,意思是主Redis有40G,其他其他的副Redis同样也是40G,因此数据容量有限的问题就出来了。
Y轴
从Y轴角度,对库中的数据按照业务进行划分不同的实例去存储,不同的数据就会存到不同的Redis中去。
例如一台服务器中被频繁访问,涉及到的数据频繁读写,其他数据基本不怎么访问,这时候可以将这部分数据独立出来,根据功能、业务继续拆分服务器,这种拆解就是AFK中的Y轴拆分,因此就可以解决数据容量有限的问题。这个维度主要是为了解决Redis缓存容量不够大的问题!
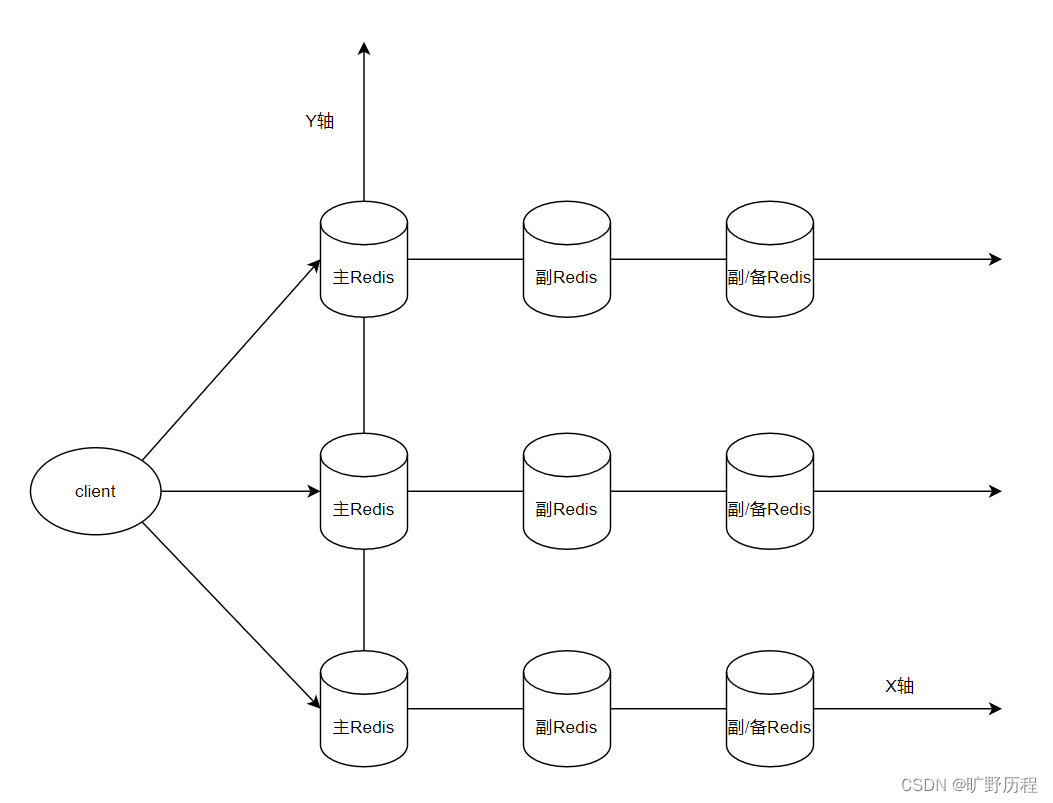
Y轴一般是按照业务、功能等来划分数据,但Y轴上的每个节点也要解决单点故障问题,所以就需要X轴、Y轴同时部署Redis实例矩阵。
Z轴
X轴和Y轴拆分之后,对节点做了主从主备复制,然后拆分不同的业务,根据不同的节点分配负责不同的业务请求。而从Z轴角度,是对Y轴进行再次拆分。
如果Y轴上一个节点访问特别大时,就需要对请求进行AFK的Z轴拆分。例如根据数据情况或访问来源分为华北、华中、华东、华南等。虽然不同的Redis虽然是负责不同的数据,但是负责的业务是一样的。
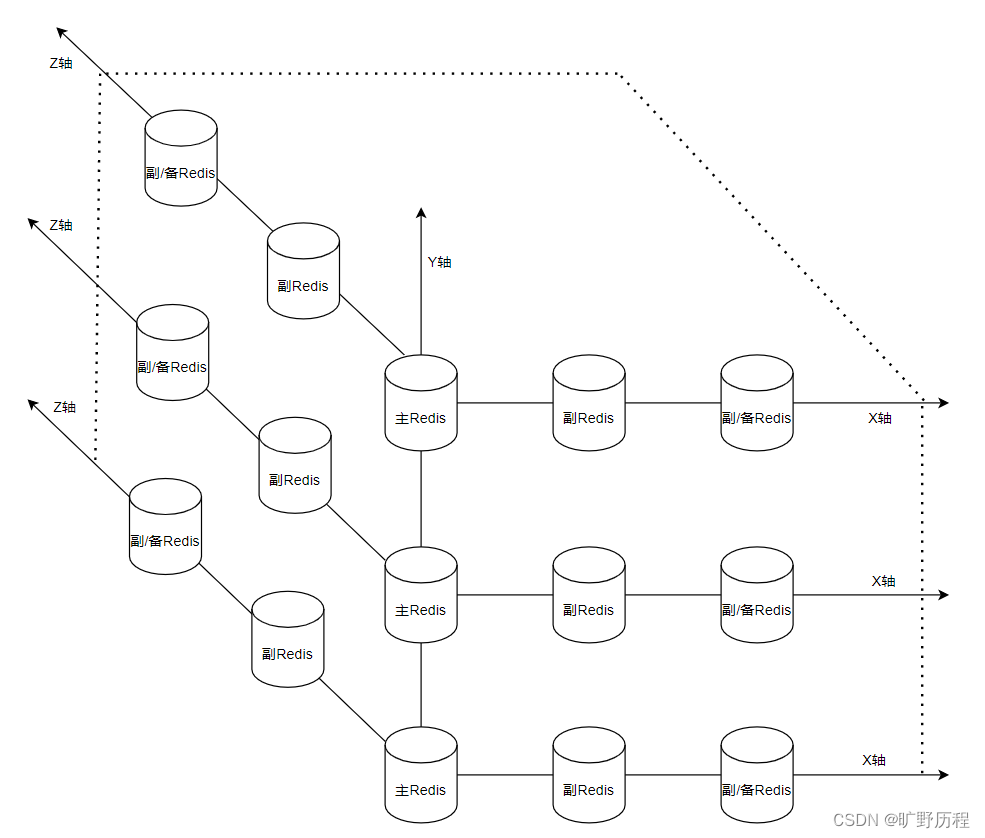
Z轴的出现是按照优先级或者特定的逻辑再进行拆分,是为了确保解决数据容量有限和访问压力的问题。
结论
经过X、Y、Z轴拆分之后,每台实例能够发挥单机的性能,再也没有了容量的限制,而且主Redis都还有多台副Redis,就不会出现单点故障问题,访问量自然不会大。
- X轴拆分:水平复制,就是讲单体系统多运行几个实例,做集群加负载均衡的模式,主主、主备、主从。
- Y轴拆分:基于不同的业务拆分
- Z轴拆分:基于数据拆分。
AFK三轴拆分后,会涉及到数据一致性问题
强一致性
当客户端对Redis进行写的时候,主Redis先不返回客户端是否写入成功,而是先去通知副Redis同步复制写入,主Redis在阻塞等待着,直到数据全部一致,主Redis再返回客户端写入成功。
强一致性的缺陷也很明显,当有一个节点出现问题,就会导致所有的写入失败,所以强一致性极容易破坏可用性。
弱一致性
主Redis写入成功后就直接和客户端说返回成功了,然后副Redis异步复制写入Redis数据。
弱一致性的缺陷在于,有可能主Redis写入成功,但是副Redis没有成功写入,就导致副Redis丢失部分数据。
最终一致性
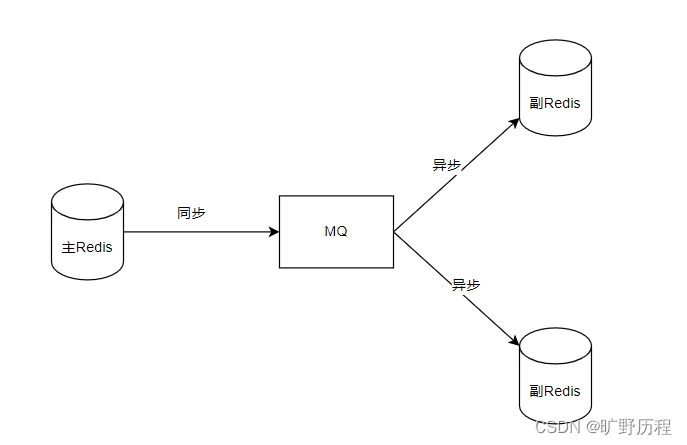
为了解决强一致性和弱一致性问题,可以在主Redis和众多副Redis钟搭建MQ去解决问题。主Redis和MQ是阻塞的,主Redis必须等MQ返回成功才可以向客户端返回成功,而MQ中的数据副Redis自己从中去取,然后写入库中。