Hi, 你好. 我是茶桁.
这一节课一开始我们要说一个非常重要的概念: 拟合.
拟合
相信只要你关注机器学习, 那么多少在某些场合下都会听到拟合这个概念.
什么叫做拟合,什么叫做过拟合或者欠拟合呢?
假如有一个模型, 这个模型在训练数据的时候效果很好, 体现在loss很小, 或者说precision很高, accuracy也比较好, 但是在实际情况下, 用到没有见过的数据的时候,效果就很差, 那么这个就过拟合了.
在这个过程中,要主一的是仅当数据label比较均衡的时候, 才有必要使用acc.
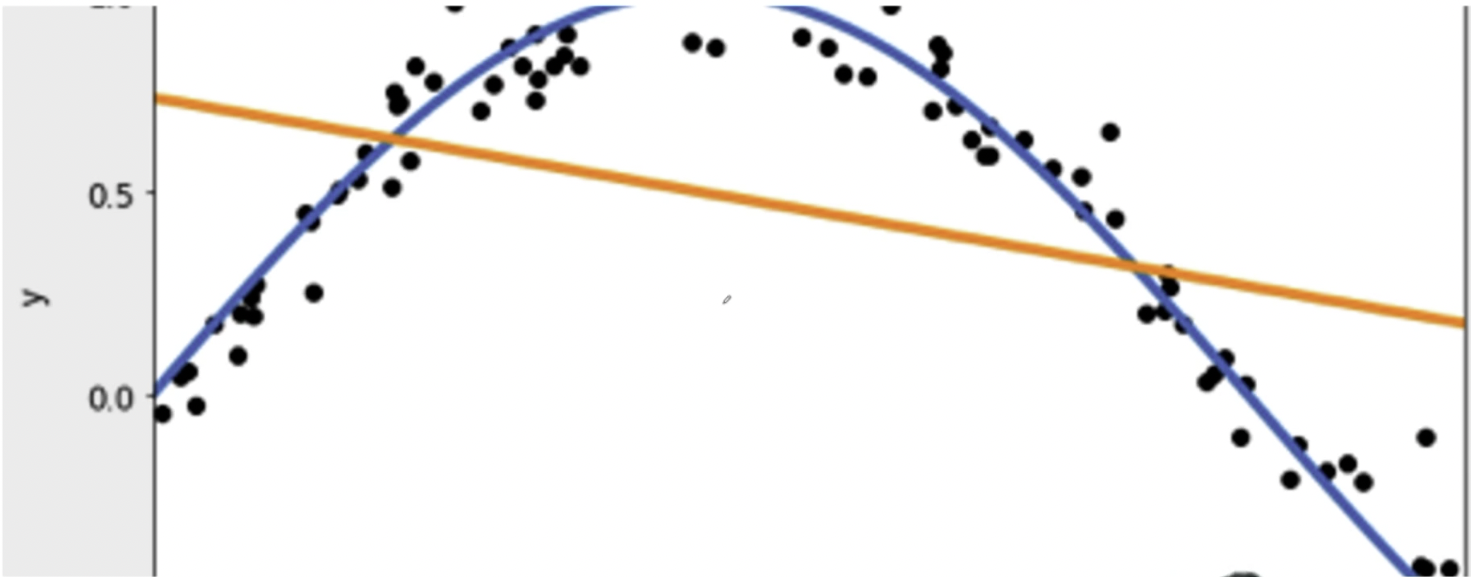
我们来看三条曲线:
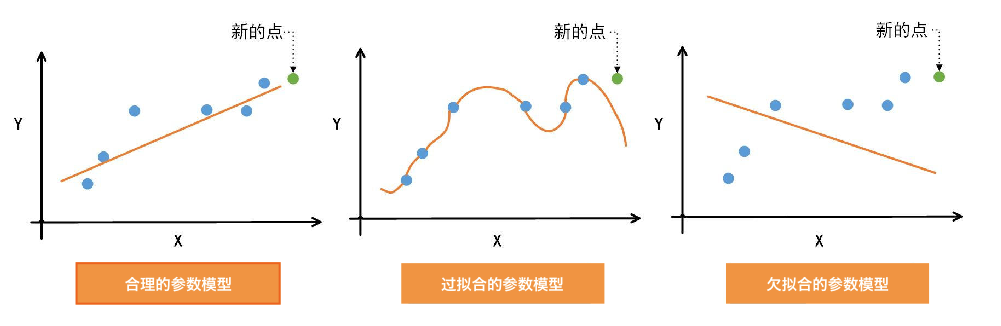
第一个图是比较合理的参数模型, 第二个图就是过拟合的参数模型.
因为对数据过度拟合, 当有新的点出现的时候, 函数的趋势和新的点并不匹配. 那过度拟合就会对于未来的点就预测不对了. 为了在训练的时候效果很好, 在见过的数据里效果特别好, 结果在新的未见过的数据里, 效果就很差.
第三个图就是欠拟合的状态. 训练的时候这个效果就不好, 整个接近程度就不高.
比较好的场景就是第一张图的拟合状态, 其形成了一个合理的参数模型. 在训练的时候拟合也没有那么高, 实际中的结果会发现结果也没那么差. 这其实也就暗合了我们前几节课里所讲的[奥卡姆剃刀原理].
过拟合和欠拟合这两个概念, 在我们平时的工作中会是每天都要一直取解决的问题.遇到一个问题, 训练的时候效果很差这个欠拟合, 经过了很多调试结果发现效果还不错, 结果在实际问题中发现效果很差, 这个就是过拟合.
这两件事情其实它是互相冲突的, 这个可以通过loss来判断, 也可以通过percision来判断, 只不过在计算新问题的时候, 不存在lose函数这回事儿. 就是当你把模型已经训练完了, 去用真实数据做测试了, 那个时候是不存在loss函数的.
在整个机器学习的发展历程中, 我们一直在不断的做的事情就是怎么样提高欠拟合的准确度, 同时降低过拟合.
影响过拟合和欠拟合原因有很多, 既和数据有关系, 也和模型有关系. 但是在这个过程中有一点大家需要注意. 所有的机器学习任务里边, 在我们收集数据的时候, 有一个很重要的问题就是异常值对过拟合和欠拟合影响会很大.
OUTLINER
有一本书就叫《Outliner》(异类), 大家有空可以去看一下。
outliner为什么会对我们整个值影响很大呢?
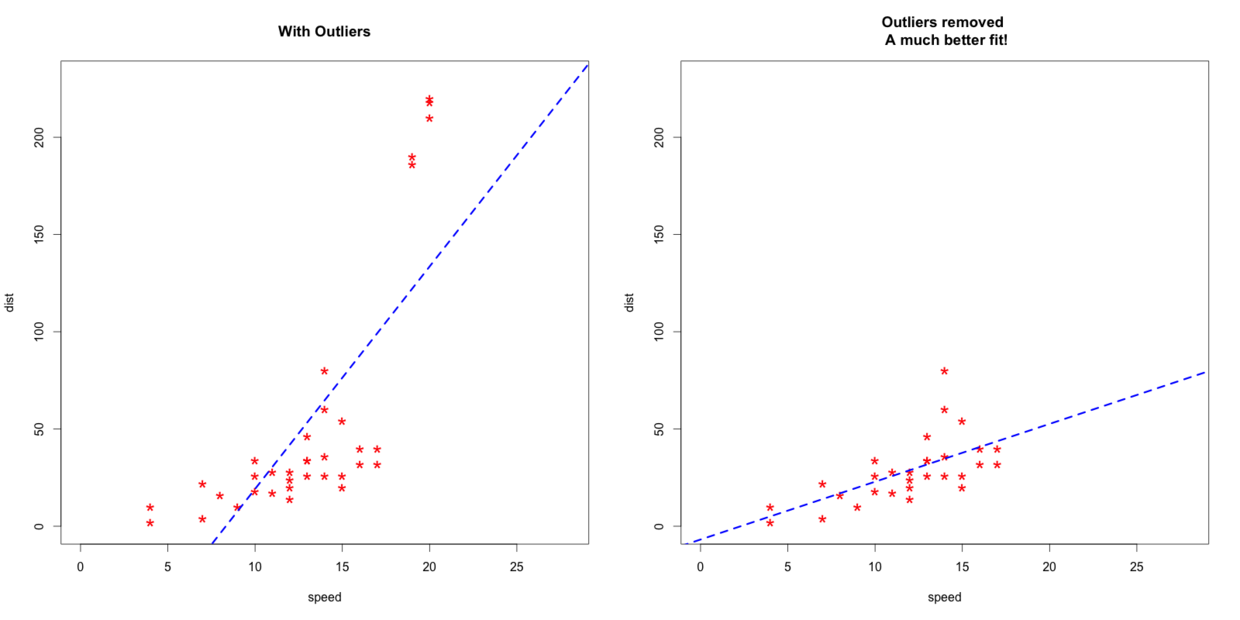
咱们来看这个图,本来正常的线性走向应该是右边这张图。可是因为存在异常值的情况,所以导致线性偏向左边这张图的情况。可是在我们的数据中,这种极端的异常值属于少数,并且因为数值偏差过大,就导致整体趋势的偏斜。
那么我们怎么样去判断异常值呢?为了把模型做好,从一开始收集数据以及清洗数据的时候就要把那些异常值给它去掉。
所谓异常值是没有一个标准定义的,但是在数学上会有一个比较常见的去除方法,就是利用百分位,常见的方法就是按百分位来解决数值型问题。
numpy里有一个persontile, 它接受一个array,和一个浮点值。
np.percentile(np.array([]), number)
那这个percentile是干嘛的呢? 比如下面这张图:
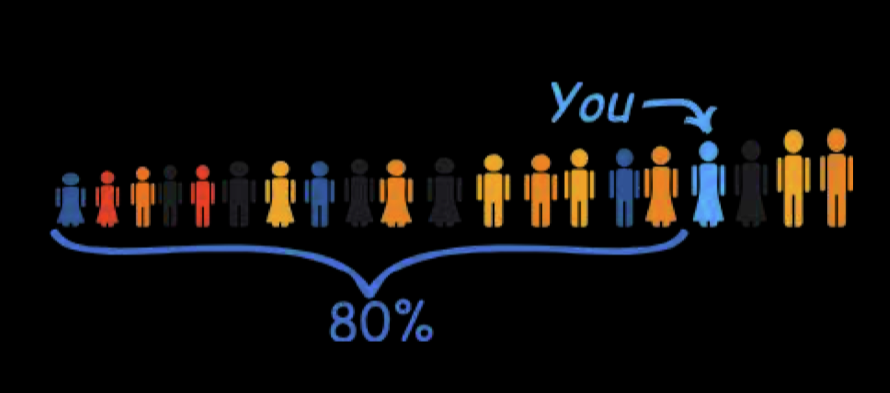
把所人从左到右排排队,比方说第80分位,就是第80%的是那一个。而我们如果是要处理数据的话,会让这些人按数值大小来排队,比如按身高, 那就是最矮的在最左边。
一般统计学上常见的几个数字,一个是0.5,还有0.25和0.75。
比如我们之前的lstat数据, 我们来找一下其中的异常值:
import numpy as np
np.where(np.array(lstat) < np.percentile(np.array(lstat), 0.25) / 1.5)
---
(array([], dtype=int64),)
np.where(np.array(lstat) > np.percentile(np.array(lstat), 0.75) * 2.5)
---
(array([ 1, 6, 7, 8, 9, 10, 11, 12, 13, 14, ...
500, 501, 502, 505]))
在寻找极大值的时候, 我们找到了一堆的数字。 如果当异常值比较多的时候,很难把它们定义成异常值。我们总结异常值规律的时候,其实它的和周围的信状它很不一样。
BIAS AND VARIANCE
好,再接下来我们来一起看看BIAS和VARIANCE。
在整个机器学习过程中,我们持续的有一个问题就是它的过拟合和欠拟合一直在互相PK。那么不管是欠拟合比较严重还是过拟合比较严重,这都是问题。但这两种问题在统计学里有两个名字。
The bias is an error from erroneous assumptions in the learning algorithm. High bias can cause an algorithm to miss the relevant relations between feature and target outputs. (underfitting);
我们把欠拟合这种问题叫做偏见,BIAS叫做偏见。
假如说对于一个人来说,你对一件事情的判断判断错了,有BIAS,就是有偏见。这个就是你的脑子对这件事情的抽象程度不够,脑子的判断模型就错了。所以效果就不好。
就比方说分明是一个二次函数,你硬是要拿直线去怼出来,那你怎么怼?这就叫BIAS。
而VARIANCE是什么呢?它指的是你的那个变化太大。
The variance is an error from sensitivity to small fluctuations in the training set. High variance can cause an algorithm to model the random noise in the training data, rather than the intended outputs (overfitting).
也就是说,这个训练集对未来比较敏感,实际的值稍微有一点不一样就会产生很差的结果。高VARIANCE最后会导致模型产生的结果都很随机,效果很差。
产生VARIANCE的背后有一个很重要的特性,就是模型复杂度。
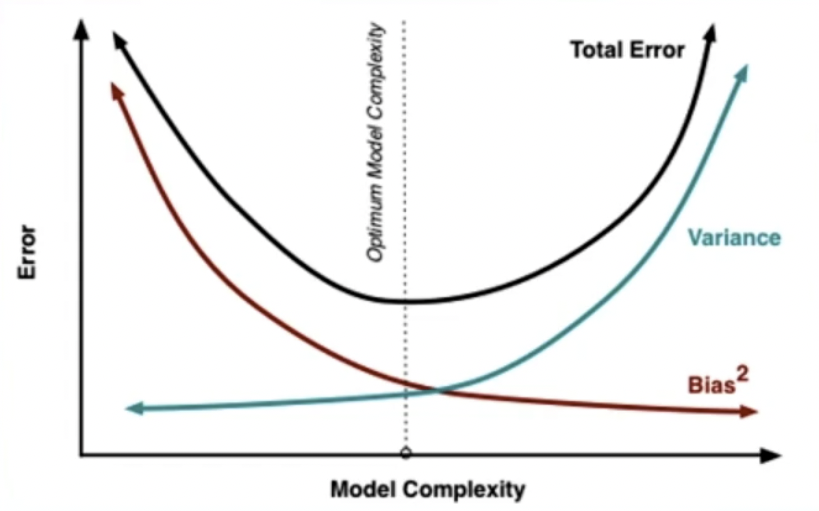
随着模型越来越复杂,它的BIAS会越来越低,就是模型越来越复杂。
就比方下面这个图中的模型:
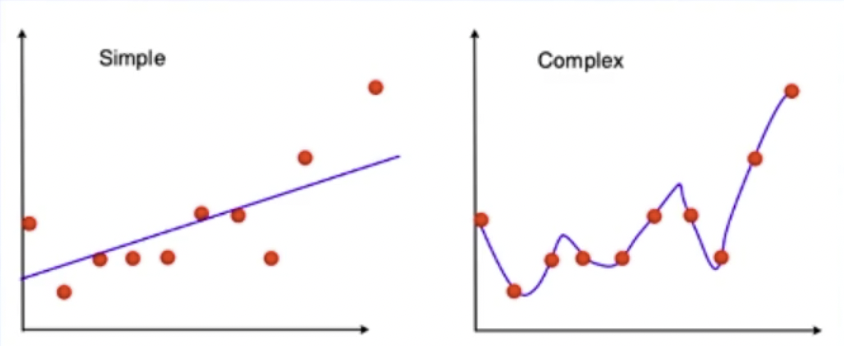
右边的这个曲线就是用了一个很复杂的模型,它的BIAS就会很低,BIAS低的时候它的VARIANCE就会变大。
因为模型复杂,所以之后问题稍微变化了,这个模型就会产生出来变化比较大的输出值。而模型越简单,BIAS就会越高,对于未来也会变化没有那么大。
这是一个非常重要的一个Dilemma,是一个两难问题,进退两难的一个问题叫Dilemma。
这两类错误背后其实都是和我们的模型复杂程度有关。
那么讲到这里我们就可以来谈谈,BIAS和VARIANCE,过拟合和欠拟合背后的原因有哪些。
| 过拟合 overfitting | 欠拟合 Underfitting |
|---|---|
| 训练数据占总体数据过少 | 训练数据占总体数据过多 |
| 模型过于复杂 | 模型过于简单 |
| 采样过于不均衡 | |
| 没有正则化… |
模型过于简单可能会产生欠拟合情况,模型过于复杂呢有可能会产生一个过拟合的情况。如果产生了过拟合,还有一个很重要的特点就是有可能模型采样非常不均衡。
模型复杂不复杂,单不简单,采样均衡不均衡。其实背后都有一个重点叫做『训练数据占总体数据的比例』,就是训练数据是不是够多。
所谓的采样均衡不均衡,异常值的出现最终都指向的是一个问题,就是我们的训练数据不够多。
为什么训练数据不够多会引起模型过于复杂之类的情况呢?在整个机器学习里是个非常重要的概念,叫做维度灾难。
我们举例来说明下,就比如,在一个平面坐标轴上有几百个点,我们用两点去确定了一根直线,但是这根直线并不能代表这几百个点确定的走向,我们需要去确定更多的点来调整这根线。
但是如果是三维轴上,我们为了去确定一个平面,就需要更多的点,比二维轴上确定直线的点多的多。为了能更加精确地确定一个平面,需要更多的数据才行。
在机器学习中算是一个经验,当机器学习的维度每增加一个,那么所需要的样本量基本上要增加一个数量级。
举个例子,假如班上有一个老师,这个老师要预测同学能不能考上重点大学。假如现在是高一,还没有开始考试,他预测这个同学有这么几个情况:
- 第一个情况是这个同学做作业的情况;
- 第二个情况是这个孩子每天上课时回答问题的活跃程度
假如是这两个点,如果他靠这两个features来预测这个孩子能不能考上大学,准确度能够做到不错,假如到百分之八九十,他需要50个学生能够预测。
那么现在又加一个features,这个features还是和前两个值不相关的,又加了一个孩子的家庭收入情况。那么它得变成上百个学生数据才能预测对。因为每增加一个features,在这个世界中就会增加很多不确定的情况。
所以模型之所以过于复杂,其实背后本质上还是数据量太少。
就在我们今天大数据的情况下,模型其实进步的并没有非常大,但是数据量变大之后,整个的效果就好多了。在机器学习里有一个点就是算法再好,模型再好,抵不过不过数据量大。
真正工作、学习的时候,一定要想办法提前检测出来过拟合、欠拟合的情况。为了提前检测出这些,有一个很简单的方法。
假如现在给了许多的训练数据,不要把这训练数据全部拿上做完。而是选一部分,拿其中的一部分数据做训练,比方80%。然后,剩下20%不给模型去看,然后把模型拿到这20%上去看一下结果。这样,我们就可以测试出结果。这就叫做训练集和数据集。
为什么要有训练集和测试集呢?有一个非常极端的情况,如果不做训练集和数据集想获得好的结果,直接把所有label对应的值记下来,也就是小时候我们背诵古诗散文。
你的模型只会阅读并背诵全文,那想想训练的时候,acc、precision、recall等评测指标就非常高,但是效果就很差,过拟合的情况就会很严重。
在实际的工作中,除了train_set和test_set,还有一个值叫validation_set。
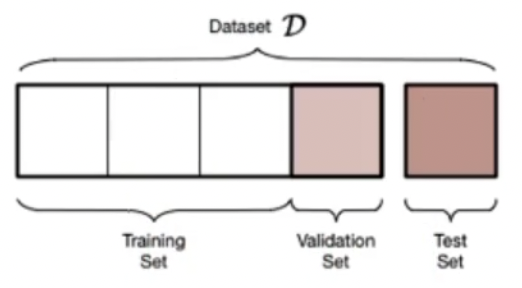
早些年的时候,做测试数据集只会分成训练集和测试集。然后在训练集上去训练,完事在测试集上去测试。但是人们发现一个情况,比方说在测试集上训练完了之后,在测试集上发现效果不太好,过拟合有点严重,于是分析test数据哪里做错了,找到错误之后修改代码或者修改数据。
就好比一个同学做题的时候有十套卷子,他做完8套,留了两套。再做这两套之后发现哪里不太对,然后反反复复去观察后面这两套,也就是我们的test数据。这个时候其实是在做针对性的调整,在有针对性的解决问题,整体的能力并没有提升。
为了解决这个问题,在实际的工作中我们会把数据集分成三个数据集。
训练数据集不断的去训练,然后结果给到validation set这样一个小数据集里。我们去观察validation的结果,再去调整,当validation的结果很不错的时候我们拿一套完全没做过的题来检验。这个完全没见过的题就是我们test set了。
当test set用过之后,如果考试成绩太差,那只能把数据集打乱,再重新取一份新的test数据了。因为这个时候如果再去有针对性的调整模型结果,那其实是在手动过拟合了。
在这个过程中,假设一共有100个数据,test里有20个,validation有10个, train里有70个。为了尽可能多的把所有的数据都用上,把它的效率都发挥上,有一个很简单的操作:cross validation, 也叫做交叉验证。
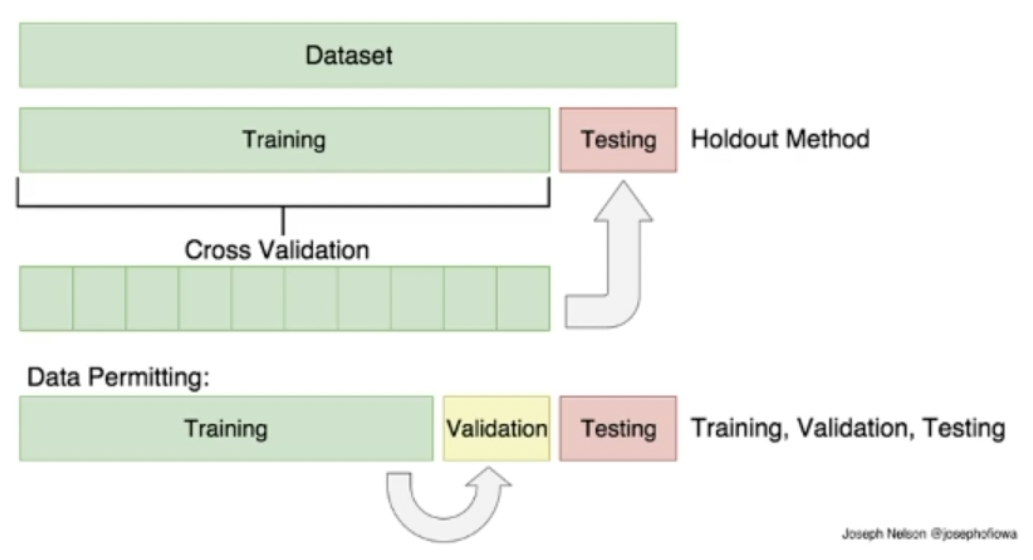
如图,假如我把数据分成很多份,我让其中一部分做validation数据集, 下一次训练的时候,我再让另外一部分做validation数据集。
再回过头来看我们之前见过的机器学习的通用框架,这几节课学习了评价指标之后,我们就应该知道,在这个背后多了一个acc和precision, 我们要持续的去观测它的结果。
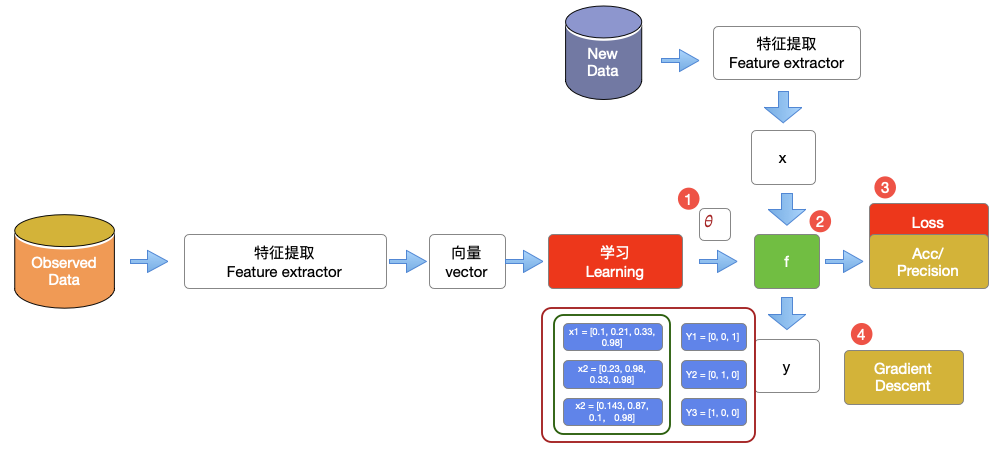
在这个过程中有了数据,然后定义一个𝜃, 这个𝜃就是我们的参数。然后根据loss function,gradient descent不断优化这个参数。结果并不是要一个低的loss参数,是期望有一个好的acc和precision。这个是在之前的基础上完善的整个学习过程。
好,下节课呢,咱们来看看FEATURE SCALING, 特征缩放。