文章目录
- 概要
- 随机种子(Random Seed)
- 第一步
- 第二步
- 第三步
- 第四步
概要
在计算机科学和深度学习领域,随机性是一个常见而重要的概念。在一些情况下,我们需要确保代码每次运行时都能得到相同的随机结果,以便进行模型的可重复性验证、结果的一致性比较等。在 YOLOv7 这样的目标检测算法中,固定随机种子就成为了一个必要的步骤。
通过固定随机种子,我们可以控制算法中的随机因素,使得每次运行时产生相同的随机结果。这对于调试、复现实验结果以及加强模型的可靠性都有重要意义。在 YOLOv7 中,通过设置随机种子,并采用合适的库函数设置,我们能够确保每次运行代码时得到相同的随机结果。
固定随机种子的操作不仅可以应用于 YOLOv7,还可以在其他深度学习任务中使用,从而增加实验的可复现性和准确性。通过控制随机性,我们能够更好地理解算法的行为,并更有效地进行模型改进和调优。
因此,固定随机种子成为了保证可靠实验和研究的重要手段,为我们提供了稳定性和一致性的基础。在深入学习和应用 YOLOv7 算法时,固定随机种子是不可或缺的一步。
随机种子(Random Seed)
随机种子是一个用于生成随机数的起始值或种子值。在机器学习和统计学中,使用随机种子可以控制随机过程的可重复性。
随机过程通常涉及到随机数的生成,例如在数据的划分、模型的初始化、参数的随机初始化等情况下。设置随机种子可以确保每次运行时使用相同的种子值,从而获得相同的随机数序列,使得实验或模型训练的结果可以重现。
使用随机种子的好处包括:
结果可重现性:通过设置相同的随机种子,可以确保每次运行时获得相同的随机数序列,使实验结果可重现,方便调试和比较不同模型或算法的性能。
模型比较:在比较不同模型或算法的性能时,使用相同的随机种子可以确保每个模型或算法在相同的随机条件下进行比较,消除了随机性对结果的影响。
调试和开发:在调试和开发阶段,使用固定的随机种子可以使得结果可重现,方便定位问题和调整模型参数。
常见的设置随机种子的方式包括:
将随机种子设置为固定的整数值,例如 random_state = 0。
使用当前时间作为种子值,例如 random_state = None 或 random_state = int(time.time())。
使用其他可确定的值,例如数据集的标识符或任务的编号。
需要注意的是,随机种子仅在使用随机性的过程中起作用,例如数据集的划分、初始化参数的随机化等。对于不涉及随机性的操作,如简单的数学运算或特定的算法逻辑,随机种子不会产生影响。
总之,通过设置随机种子,可以控制随机过程的可重复性,保证实验或模型训练的结果可以重现,并且方便进行模型比较和调试。
第一步
话不多说,直接上。
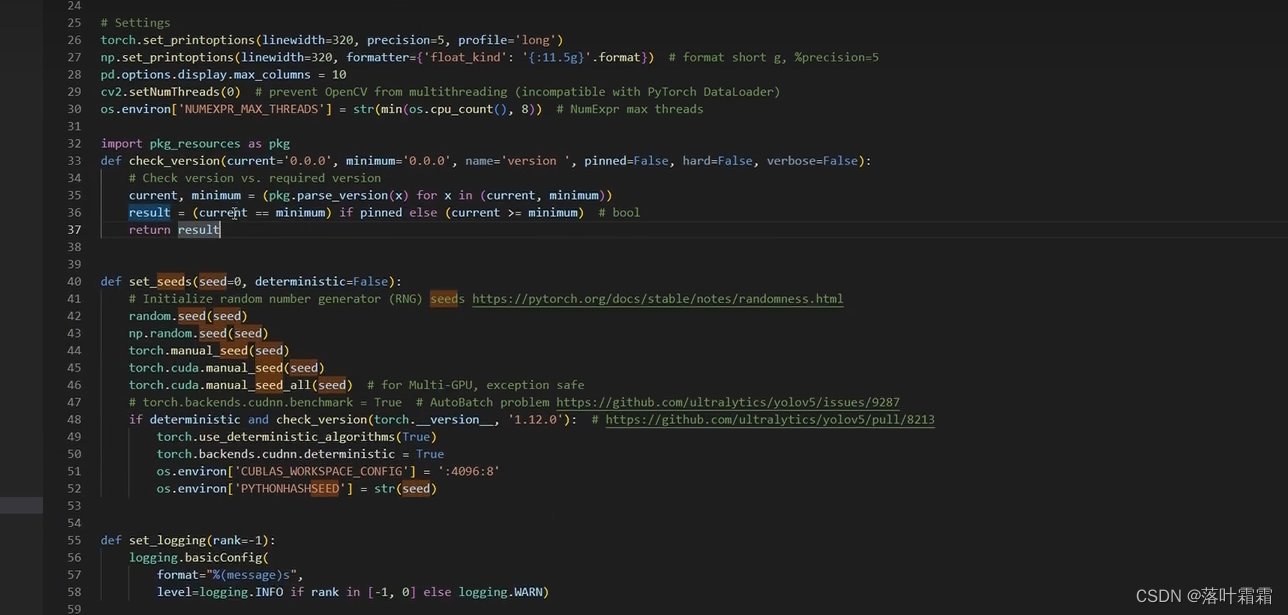
import pkg_resources as pkg
def check_version(current='0.0.0', minimum='0.0.0', name='version ', pinned=False, hard=False, verbose=False):
# Check version vs. required version
current, minimum = (pkg.parse_version(x) for x in (current, minimum))
result = (current == minimum) if pinned else (current >= minimum) # bool
return result
def set_seeds(seed=0, deterministic=False):
# Initialize random number generator (RNG) seeds https://pytorch.org/docs/stable/notes/randomness.html
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # for Multi-GPU, exception safe
# torch.backends.cudnn.benchmark = True # AutoBatch problem https://github.com/ultralytics/yolov5/issues/9287
if deterministic and check_version(torch.__version__, '1.12.0'): # https://github.com/ultralytics/yolov5/pull/8213
torch.use_deterministic_algorithms(True)
torch.backends.cudnn.deterministic = True
os.environ['CUBLAS_WORKSPACE_CONFIG'] = ':4096:8'
os.environ['PYTHONHASHSEED'] = str(seed)
上述代码复制到yolov7的utils的general.py
第二步
添加随机种子函数导入

第三步
注释掉原来的种子函数

第四步
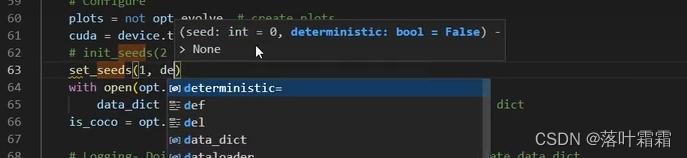
添加新的种子函数

随机性是计算机科学和深度学习领域中一个常见而重要的概念。在一些情况下,我们需要确保代码每次运行时都能得到相同的随机结果,以达到实验结果可重复的目的。在 YOLOv7 等目标检测算法中,通过固定随机种子,可以控制算法中的随机因素,使得每次运行时产生相同的随机结果,增加了模型可靠性和一致性。具体实现方法包括设置随机种子、调用相关库函数、禁用cudnn等,可以应用于其他深度学习任务中,从而增加实验的可复现性和准确性。固定随机种子成为了保证可靠实验和研究的重要手段,为我们提供了稳定性和一致性的基础,是进行深入学习和应用 YOLOv7 算法时不可或缺的一步。
随机种子(Random Seed)是一个用于生成随机数的起始值或种子值。在机器学习和统计学中,使用随机种子可以控制随机过程的可重复性。
随机过程通常涉及到随机数的生成,例如在数据的划分、模型的初始化、参数的随机初始化等情况下。设置随机种子可以确保每次运行时使用相同的种子值,从而获得相同的随机数序列,使得实验或模型训练的结果可以重现。
使用随机种子的好处包括:
结果可重现性:通过设置相同的随机种子,可以确保每次运行时获得相同的随机数序列,使实验结果可重现,方便调试和比较不同模型或算法的性能。
模型比较:在比较不同模型或算法的性能时,使用相同的随机种子可以确保每个模型或算法在相同的随机条件下进行比较,消除了随机性对结果的影响。
调试和开发:在调试和开发阶段,使用固定的随机种子可以使得结果可重现,方便定位问题和调整模型参数。
常见的设置随机种子的方式包括:
设置为固定的整数值,例如 random_state = 0。
使用当前时间作为种子值,例如 random_state = None 或 random_state = int(time.time())。
使用其他可确定的值,例如数据集的标识符或任务的编号。
需要注意的是,随机种子仅在使用随机性的过程中起作用,例如数据集的划分、初始化参数的随机化等。对于不涉及随机性的操作,如简单的数学运算或特定的算法逻辑,随机种子不会产生影响。
总之,通过设置随机种子,可以控制随机过程的可重复性,保证实验或模型训练的结果可以重现,并且方便进行模型比较和调试。