一、前言
昨天门店POS系统发生了一次因为OOM引起的Down机事件,本文我们就来讲一下故障排查和解决问题过程。
二、故障发生
吃完中饭正在休息,业务方说POS的后台管理系统进行库存盘点出错,截图过来的报错信息里有:连接POS前台系统的HTTP请求报Readtime Out,第一反应是澳洲的网络出问题了,然后让业务方把条码给我自己操作了一下也不行,紧接着业务方又发信息过来说所有门店POS系统都无法下单,这时候人就紧张起来了,马上登录到机器上执行Top命令查Load状况,机器负载没有什么问题,处于低水位运行,这时候就猜想极有可能是JVM OOM了,不管3721重启应用再说吧,一般重启应用能解决99%的问题,重启后系统恢复正常。
注:在处理故障的时候都是先解决问题再说,很难有时间去考虑保留现场,所以需要通过监控或者日志保存数据都应该事先做好。
三、事后分析过程
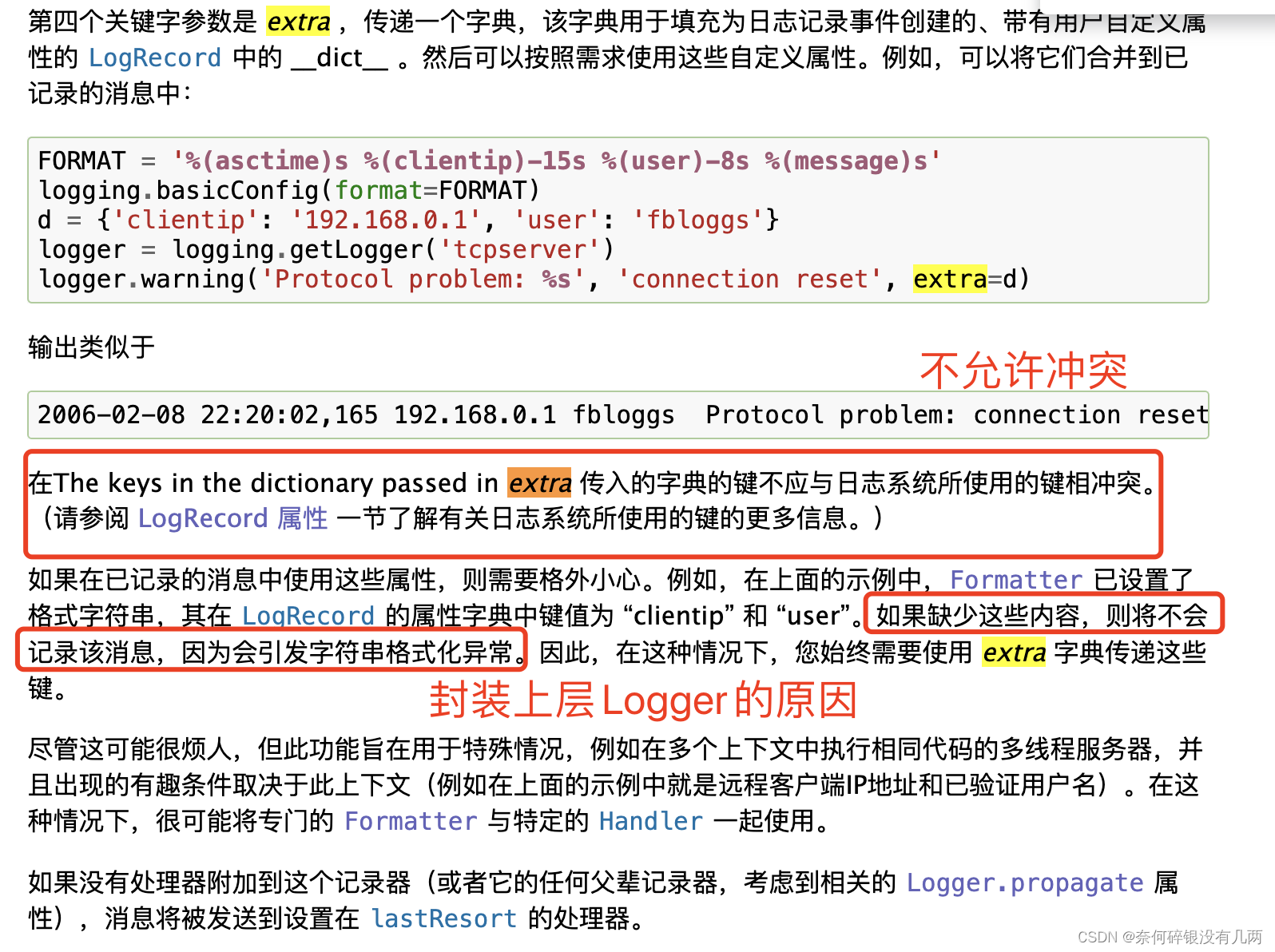
1、查看JVM内存变化情况以及FuLLGC的状况。
使用自己写的一个小工具查看机器监控数据,小工具的代码可以看 《Linux Shell + MySQL实现一个简单监控》
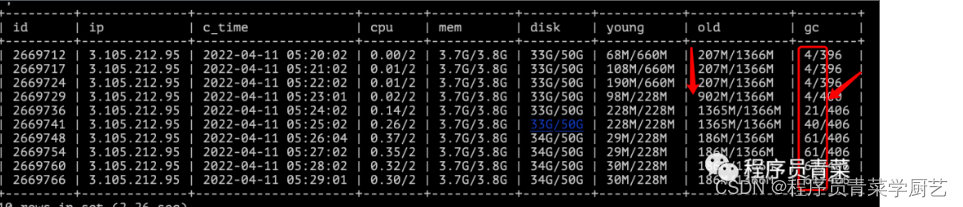
在05:23的时候 堆内存老年代占用空间猛增,并且开始触发频繁FullGC,通过该小工具故障发生时间可以明确定位出来。Gc日志因为重启已经丢失。
注:发生时间点的定位是很重要的事情,这在你排查日志时知道越准确的时间越容易定位。
2、定位access.log日志,查看当时时间节点有哪些接口请求
主要是怀疑有大量的请求或代码不严谨,造成请求数据库返回的结果集太大造成OOM,但发现那个时间点调用的接口很多,一时难定位具体是哪个接口造成问题。
3、查看JVM 崩溃日志 hs_err_pid19369.log
JVM崩溃会生成一个Log文件

只发现了Out of Memory Error,没有更具体能直接定位的的输出。
4、分析OOM时dump出来的堆内存日志
首先需要在启动应用时添加如下的JVM参数,在JVM发生OOM时才会将当时堆内存情况DUMP出来。

然后把日志文件Down到自己电脑,jvisualvm打开分析
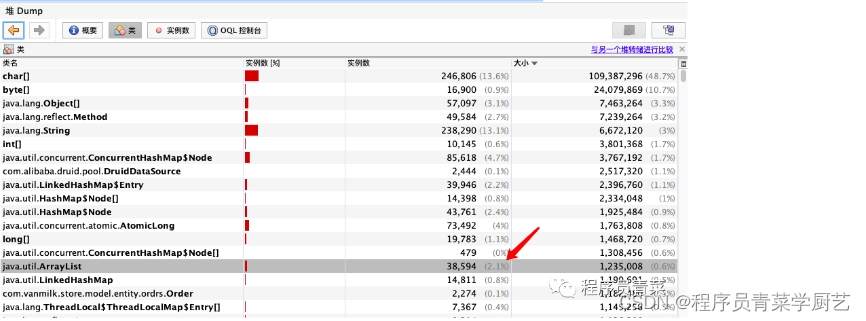
四、真正定位问题
一般造成OOM常见原因有如下这些
-
超出预期的访问量/返回数据量,比如促销活动造成业务峰值,但我们门店POS系统流量相对平稳,不太可能有这种事情发生。
SQL返回的数据量,一般SQL请求批量返回数据都是分页查询,统计数据也不会有大量的数据返回,存在一种情况就是根据某个字段去查,但符合条件的数据记录数量很大。
-
创建一个超大对象,大数组。
-
内存泄露,造成大量对象的引用没有被回收,这种在Android客户端开发经常会发生,这与Android对象的生命周期有关,服务端相对来讲要好很多。
根据我们业务场景分析最大的怀疑还是在偶然情况下触发了SQL返回大量的数据,那如何定位哪条SQL呢,druid监控的SQL日志因为JVM重启也已经丢失。然后发现我们的日志有输出SQL执行结果影响的行数。

但直接去那个时间段异常的数据SQL也很难,这时候我们就可以使用AWK来分析日志了。
cat tmp.log | awk '{print $1,$2,$7,$8}' > tmp.log,就可以查到有一个DAO接口返回了 2274条数据,这个就比较异常了,日志如下:
2022-04-11 05:22:57 DEBUG com.vanmilk.store.dao.order.OrderDao.getOrd[159] - <== Total: 2274
根据接口查调用栈分析后,然后发现我们有一些老订单(从另外一个系统导过来)没有发票号,在订单列表点击发送邮件或者打印小票(想不通这种几年前的老订单门店的人为什么还要去瞎操作),会根据发票号去查询订单数据,,造成大量数据直接返回,内存占用马上就飚上了,然后触发了几十次FullGC。FullGC后老年代还没有被释放,然后内存无法分配,直接就OOM了,找到问题了就好解决了在发送邮件或打印小票请求接口加一下requrie=true就可以,另外在做SQL查询的时候当不确定返回的数据量是否会过大时可以考虑加一下Limit 限制一下。
OOM发生时JVM其实并没有挂掉,而是假死,无法响应请求了,发生OOM时会把抛出这个异常的线程给杀掉,但抛出OOM那个线程并一定是造成内存溢出的大头。所以发生OOM时一般都需要手工重启一下JVM,靠他自己恢复基本上是不太可能的。