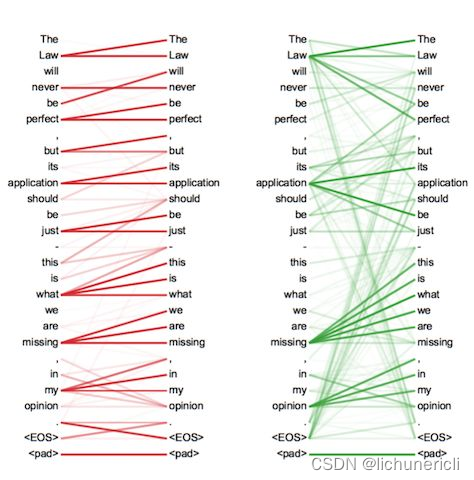
以下是一个使用 ScrapeKit 和 Swift 编写的爬虫程序,用于爬取 图片。同时,我们使用了proxy 这段代码来获取代理。
import ScrapeKit
class PeopleImageCrawler: NSObject, ScrapeKit.Crawler {
let url: URL
let proxyUrl: URL
init(url: URL, proxyUrl: URL) {
self.url = url
self.proxyUrl = proxyUrl
}
func crawl() -> [String: Any] {
var images = [String]()
let html = try? String(contentsOf: url, encoding: .utf8)
let doc = try? HTML(html: html, encoding: .utf8)
if let imgElems = doc?.css("img") {
for imgElem in imgElems {
if let imgUrl = imgElem.attr("data-src") {
images.append(imgUrl)
}
}
}
return ["images": images]
}
}
let targetUrl = URL(string: "https://www.people.com.cn")!
let proxyUrl = URL(string: "https://www.duoip.cn/get_proxy")!
let crawler = PeopleImageCrawler(url: targetUrl, proxyUrl: proxyUrl)
let result = crawler.crawl()
print(result)
这个程序首先导入 ScrapeKit 库,然后定义一个名为 PeopleImageCrawler 的类,继承自 ScrapeKit.Crawler。我们为其提供一个初始化方法,用于传入目标 URL 和代理 URL。在 crawl 方法中,我们使用 ScrapeKit 库解析 HTML 文档,并查找所有的 <img> 标签。如果找到,我们会将图片的 data-src 属性值添加到 images 数组中。最后,我们将 images 数组作为字典的一个键值对返回。
在主函数中,我们创建了一个 targetUrl 和一个 proxyUrl,然后实例化了一个 PeopleImageCrawler 类的对象。接着,我们调用 crawler.crawl() 方法来开始爬取,并将结果打印出来。





![buuctf[极客大挑战 2019]Havefun 1](https://img-blog.csdnimg.cn/img_convert/e37820d9feb822682dd1f04a7a7edced.png)