数据处理之N——>BatchSize
N——>batch_size
train_data = TensorDataset(torch.Tensor(x_train).double(), torch.Tensor(y_train).double())
train_loader = DataLoader(train_data, batch_size=args.bs, shuffle=True, drop_last=True)
for batch_idx, (inputs, results) in enumerate(train_data):
print(inputs.shape, results.shape)
不过我得说,train_loader局限于第一维,做的事如下代码:
for i in range(0, num_samples, batch_size):
batch = data[i:i + batch_size]
yield batch
维度
- 分块:iter.chunk(分成几块,dim)
- 连接:torch.cat( [ tensor1, tensor2 ](放在列表中),dim)
- 升维1 / 降维1:squeeze(dim), unsqueeze(dim)
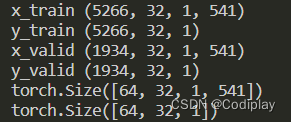
[64, 32, 1, 541]维度互换有影响吗?怎么去想这个事
数据本身并没有改变,只是数据在张量中的排列顺序发生了变化,也就是索引方式变了。
例如,如果你将形状为[5266, 32, 541, 1]的张量的第3和第4维度交换,你得到的张量仍然包含相同的元素,但它们在张量中的排列方式不同,变成了形状为[5266, 32, 1, 541]的张量。这在某些情况下可能对特定的计算或模型操作更有用。
既然要求你按照什么样的维度去排列索引,而且你也知道每个数字代表的对应的是什么意思,你就直接按照他说的顺序去改就是了啊!
只要你给的数据的维度能对得上就没有任何问题,最主要的是首先要搞明白你需要几维的数据,并搞明白每一维的意思,要对上,不然就会出现channel对到T上的尴尬问题。
s
e
q
_
l
e
n
seq\_len
seq_len:序列长度
i
n
p
u
t
_
s
i
z
e
input\_size
input_size:序列的个体的维度
举一个例子,你的目的是要跑RNN,用RNNCELL,那么首先外部循环的肯定是seq_len,每次输入
[
b
s
,
c
h
a
n
n
e
l
,
i
n
p
u
t
_
s
i
z
e
]
[bs, channel, input\_size]
[bs,channel,input_size]的数据到model里面。
那么如果如果提供的数据是
[
5266
,
32
,
1
,
541
]
,
N
=
5266
[5266, 32, 1, 541],N = 5266
[5266,32,1,541],N=5266
s
e
q
_
l
e
n
=
32
,
i
n
p
u
t
_
s
i
z
e
=
541
,
c
h
a
n
n
e
l
=
1
seq\_len = 32, input\_size = 541, channel = 1
seq_len=32,input_size=541,channel=1
那么每一批次的维度比如是
[
128
,
32
,
1
,
541
]
[128, 32, 1, 541]
[128,32,1,541]
你的目标也就是得到每次的输入
[
128
,
1
,
541
]
[128, 1, 541]
[128,1,541]
要按照第二个维度展开,即将第二个维度分成32个块——>pytorch带的chunk函数
用法:iter.chunk(要分的快数量,沿着哪个维度)
seq.chunk(seq.size(1), dim = 1)#传入的是seq.size(1)即要分成每个为1的
然后得到:
[
128
,
1
,
1
,
541
]
[128, 1, 1, 541]
[128,1,1,541]
再使用seq.squeeze(1)
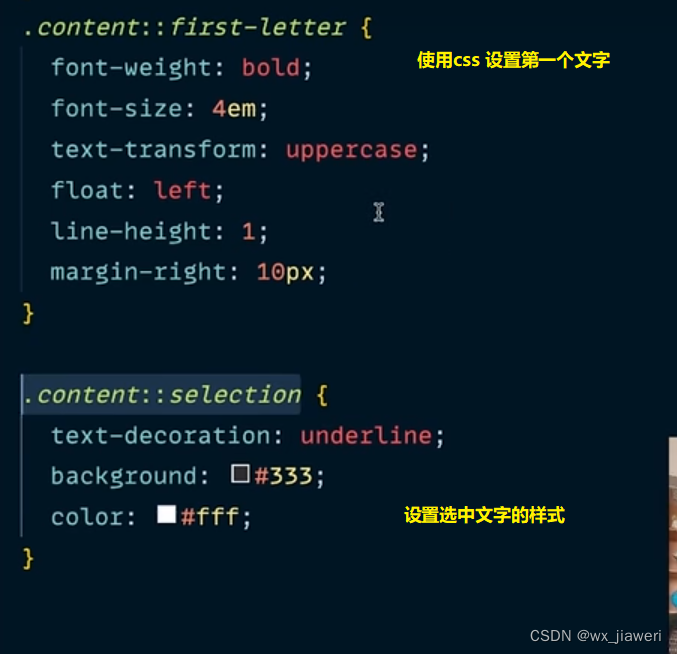
squeeze 函数有一个可选的参数,即 dim,它指定了要挤压的维度。如果指定 dim,则 squeeze
仅删除指定的维度,如果该维度大小为1。如果不指定 dim,则默认情况下会删除所有尺寸为1的维度。
没看懂的深浅拷贝,clone,copy etc.
https://www.jb51.net/article/201724.htm









![[架构之路-241]:目标系统 - 纵向分层 - 企业信息化与企业信息系统(多台企业应用单机组成的企业信息网络)](https://img-blog.csdnimg.cn/b7afb51632e94ebab1554df75704c066.png)