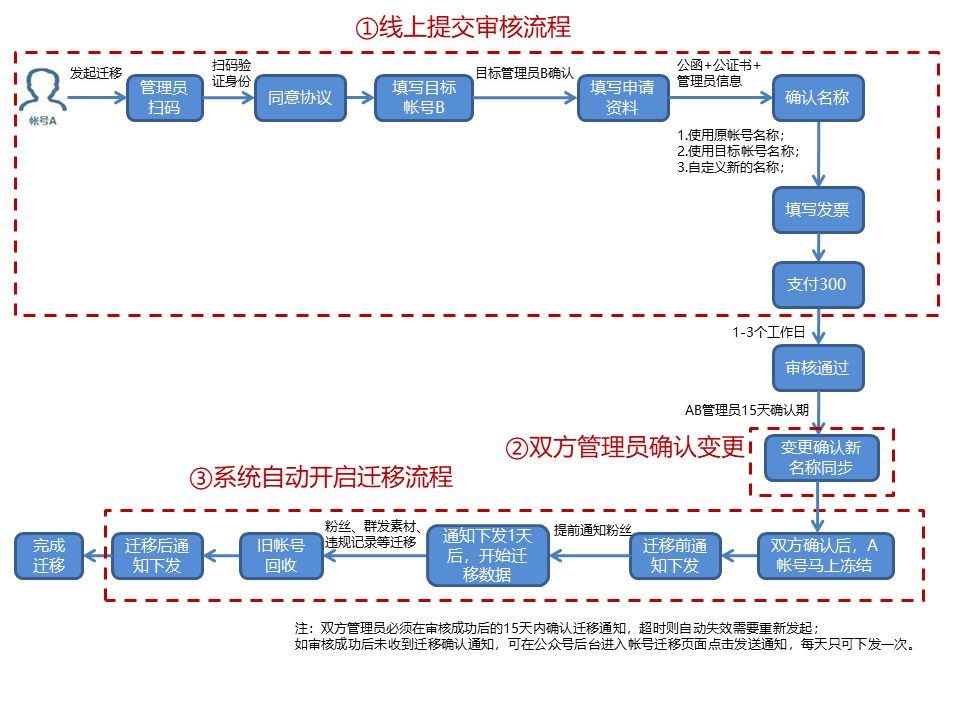
反转字符串
https://leetcode.cn/problems/reverse-string/description/
【双指针法:一前一后】
public void reverseString(char[] s) {
for (int i = 0; i < s.length / 2; i++) {
char temp = s[i];
s[i] = s[s.length - 1 - i];
s[s.length - 1 - i] = temp;
}
}
反转字符串Ⅱ
https://leetcode.cn/problems/reverse-string-ii/
每计数至2k个字符,就反转这2k个字符中的前k个字符,因此循环的步长是2k
public static String reverseStr(String s, int k) {
// 将字符串转化为 字符数组 ,方便遍历
char[] chars = s.toCharArray();
for (int i = 0; i < chars.length; i += 2 * k) {
if (i + k > chars.length) {
// 将剩余的元素反转
for (int j = 0; j < (chars.length - i) / 2; j++) {
char temp = chars[j + i];
chars[j + i] = chars[chars.length - j - 1];
chars[chars.length - j - 1] = temp;
}
} else {
// 反转前面k个
for (int j = 0; j < k / 2; j++) {
char temp = chars[j + i];
chars[j + i] = chars[i + k - j - 1];
chars[i + k - j - 1] = temp;
}
}
}
return new String(chars);
}
反转字符串中的单词
https://leetcode.cn/problems/reverse-words-in-a-string/
【移除无效的空格 迭代过程】

public String reverseWordsFromStartToEnd(String s) {
char[] charArr = s.toCharArray();
// 去除无效的空格
int arrLen = removeSpace(charArr);
// 将整个字符串反转
reverse(charArr, 0, arrLen - 1);
// 反转每个单词
reverseWordsFromStartToEnd(charArr, 0, arrLen - 1);
return new String(charArr, 0, arrLen);
}
/**
* 反转字符串里面的每一个单词
*
* @param charArr
* @param startIndex
* @param endIndex
*/
private void reverseWordsFromStartToEnd(char[] charArr, int startIndex, int endIndex) {
// fast 比 slow 多一位,因为 slow 和 fast 不同时,才需要反转
int slow = startIndex, fast = startIndex + 1;
while (fast <= endIndex) {
if (charArr[fast] == ' ') {
// 当fast走到空格时,slow到fast-1的就是一个单词,需要反转
reverse(charArr, slow, fast - 1);
// slow直接跳过空格,来到下一个单词的开头
slow = fast + 1;
fast = slow + 1;
} else if (fast == endIndex) {
// 当fast走到末尾时,slow到fast的就是一个单词,需要反转
reverse(charArr, slow, fast);
break;
} else {
fast++;
}
}
}
/**
* 反转 startIndex与endIndex之间的字符
*
* @param charArr
* @param startIndex
* @param endIndex
*/
private void reverse(char[] charArr, int startIndex, int endIndex) {
for (int i = 0; i <= (endIndex - startIndex) / 2; i++) {
char temp = charArr[i + startIndex];
charArr[i + startIndex] = charArr[endIndex - i];
charArr[endIndex - i] = temp;
}
}
/**
* 移除无效的空格,如前后的空格 以及 单词与单词中间的空格
*
* @param charArr
* @return 移除无效空格之后的数组长度
*/
private int removeSpace(char[] charArr) {
int slow = 0, fast = 0;
// 表示是否已经增加了一个空格,如果增加了,就改成true
boolean addSpace = false;
while (fast < charArr.length) {
if (slow == fast && charArr[slow] != ' ') {
// 如果不是空格,不需要替换,fast和slow同时走
slow++;
fast++;
addSpace = false;
} else if (charArr[fast] != ' ') {
charArr[slow++] = charArr[fast++];
addSpace = false;
} else if (charArr[fast] == ' ') {
if (addSpace == false && slow > 0) {
// 单词与单词之间保留一个空格
charArr[slow++] = ' ';
addSpace = true;
}
fast++;
}
}
// 如果最后增加了一个空格,就将这个空格删掉
if (charArr[slow - 1] == ' ') {
slow -= 1;
}
return slow;
}
左旋转字符串
该题的链接变成其他的题目了,这里就不再放链接了,题目介绍如下:

这道题的思路非常灵活,对于lrlose | umgh,首先反转前6个元素,变成esolrl | umgh,再反转后面的剩余字符esolrl | hgmu,最后在对整一个字符串进行反转,就得到最终的结果了umghlrlose
public String reverseLeftWords(String s, int n) {
char[] chars = s.toCharArray();
// 反转前n个单词
reverse(chars, 0, n - 1);
// 反转后面的单词
reverse(chars, n, chars.length - 1);
// 反转整个字符串
reverse(chars, 0, chars.length - 1);
return new String(chars);
}
/**
* 反转两个指定索引之间的字符
* @param charArr
* @param startIndex
* @param endIndex
*/
private void reverse(char[] charArr, int startIndex, int endIndex) {
for (int i = 0; i <= (endIndex - startIndex) / 2; i++) {
char temp = charArr[i + startIndex];
charArr[i + startIndex] = charArr[endIndex - i];
charArr[endIndex - i] = temp;
}
}
找出字符串中第一个匹配项的下标
题目链接:https://leetcode.cn/problems/find-the-index-of-the-first-occurrence-in-a-string/description/
已知有一个文本串aabaabaaf和一个模式串aabaaf
暴力求解
/**
* 暴力破解
*
* @param haystack
* @param needle
* @return
*/
public int bruteForce(String haystack, String needle) {
for (int i = 0; i < haystack.length(); i++) {
boolean found = true;
for (int j = 0; j < needle.length(); j++) {
if (haystack.charAt(i + j) != needle.charAt(j)) {
found = false;
break;
}
}
if (found) {
return i;
}
}
return -1;
}
时间复杂度是O(m*n),m是haystack的长度,n是needle的长度
KMP算法
KMP思想:当出现字符串不匹配时,通过利用部分已经匹配过的内容信息来避免从头开始匹配
模式串前缀
包括模式串的第一个字母,不包括模式串的最后一个字母的所有子串,如aabaaf有如下前缀:
aaaaabaabaaabaa
模式串后缀
包括模式串的最后一个字母,不包括模式串的第一个字母的所有子串,如aabaaf有如下后缀:
fafaafbaafabaaf
最长相等前后缀(前缀表)
| 子串 | 最长相等前后缀 | 原因 |
|---|---|---|
| a | 0 | 只有一个字符,没有前缀,也没有后缀,所以长度是0 |
| aa | 1 | a与a |
| aab | 0 | |
| aaba | 1 | a与a |
| aabaa | 2 | aa与aa |
| aabaaf | 0 |
[0,1,0,1,2,0]就是前缀表,用来记录模式串与主串不匹配的时候,模式串应该从哪里开始重新匹配
如下图,模式串和主串在前面的a a b a a都是匹配的,到i=5,j=5的时候开始不匹配了

这时并不需要从头开始匹配,因为②和③之前已经匹配过了,①和②又相同,因此①和③无须再匹配,直接从i=5,j=2开始匹配即可。使用了前缀表就知道aabaa的最长相等前后缀是2,由此可以知道下一个需要匹配的元素是模式串的第三个元素

如何计算填充前缀表(next数组)

时间复杂度O(n+m)
假设n为文本串长度,m为模式串长度,在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n)。除此之外,还生成next数组,时间复杂度是O(m)
代码
public int strStr(String haystack, String needle) {
if ("".equals(needle)) {
return 0;
}
int[] next = getNext(needle);
int i = 0, j = 0;
while (i < haystack.length() && j < needle.length()) {
if (haystack.charAt(i) == needle.charAt(j)) {
if (j == needle.length() - 1) {
// --if-- needle全部匹配完成,返回索引
return i - j;
}
// 匹配成功,i和j同时++,匹配下一个字符
i++;
j++;
} else {
if (j > 0) {
// --if-- 如果匹配不成功,而且j>0,对j进行回退
j = next[j - 1];
} else {
// --if-- 回退不了的话,i++,重新开始匹配
i++;
}
}
}
return -1;
}
private int[] getNext(String needle) {
int[] next = new int[needle.length()];
// j是前缀的末尾索引,i是后缀的末尾索引
int i, j = 0;
for (i = 1; i < needle.length(); i++) {
//--for-- 从next的第二个元素开始填充,next[0]为 0,因为一个字符的最长相等前后缀为 0
while (j > 0 && needle.charAt(i) != needle.charAt(j)) {
// 当后缀的末尾字符与前缀末尾字符不相等时,将j回退
j = next[j - 1];
}
if (needle.charAt(i) == needle.charAt(j)) {
//--if-- 前缀末尾字符和后缀末尾字符相等时,j++
j++;
}
next[i] = j;
}
return next;
}
重复的子字符串
题目链接:https://leetcode.cn/problems/repeated-substring-pattern/description/
感悟
这道题目的定位是简单,做起来却让我感到我的头脑简单つ﹏⊂。确实,使用暴力法很容易做出结果,但是时间复杂度太高。能想出移动匹配和用kmp方法求解的真乃大神,我连理解都需要花费好长时间/(ㄒoㄒ)/~~
暴力法
一层循环遍历模板子串的尾部元素,即[0,end]的元素为一个模板子串;另一层循环用来判断模板子串后面的字符串是否都由模板子串重复构成
时间复杂度:O(n^2)
空间复杂度:O(1)
/**
* 暴力方法求解
*
* @param s
* @return
*/
public static boolean bruteForce(String s) {
// 假如 s.length()=10,循环到索引4即可 [0,1,2,3,4] [5,6,7,8,9]
// 假如 s.length()= 9,循环到索引3即可 [0,1,2,3] [4,5,6,7,8]
for (int end = 0; end < s.length() / 2; end++) {
// 如果字符串的长度不是end+1的整数倍,说明肯定不是当前子串的循环重复
if (s.length() % (end + 1) != 0) {
continue;
}
// 从[0,end]的元素表示一个子串
int index = 0;
for (int i = end + 1; i < s.length(); i++) {
if (s.charAt(index) == s.charAt(i)) {
// 必须i == s.length() - 1 && index == end 再 return true,
// 如果缺少index == end。 aabaaba 会出现问题
if (i == s.length() - 1 && index == end) {
return true;
}
// (end+1)才是子串的数量
index = ++index % (end + 1);
} else {
break;
}
}
}
return false;
}
移动匹配(我愿称之为双S法)
方法
假设有一个字符串s= abcdabcd,首先获取ss= s+s = abcdabcdabcdabcd,然后去掉ss的首尾元素,ss=bcdabcdabcdabc,然后再判断ss里面是否包含s,如果包含,返回true,ss=bcdabcdabcdabc里面很明显是包含s的,因此字符串s里面包含重复的子字符串。如果s不包含重复子串,s自己就是一个子串,s+s去头去尾就一定不包含自己。
字符串是由子串循环重复而成→双S法返回true,如何证明充分必要性
充分性
因为字符串是由子串循环重复而成,假设子串为S’,则S=S’S’…S’S’,S至少由两个S’组成,SS=S+S,去掉SS的首尾元素只是毁掉首尾的S’,SS里面还会包含S。那为什么要毁掉首位的S’呢,因为这样会让SS中的两个S都不在成形,否则包含S也可能只是包含原来的S
必要性
下图证明来源于官方解答(我水平太低,证不出来/(ㄒoㄒ)/~~),我在图中做了一些批注,希望可以帮助大家理解

时间复杂度:O(m+n),因为使用contain方法的底层实现方法的复杂度是O(m+n),可以参考上面的KMP算法
/**
* 双 ss 法
* ss = s + s
* 掐头去尾,再判断剩下的字符串是否包含 s
*
* @param s
* @return
*/
public static boolean repeatedSubstringPattern(String s) {
String ss = s + s;
ss = ss.substring(1, ss.length() - 1);
return ss.contains(s);
}
使用KMP的next数组
知识点1:为什么最小重复子串一定是原字符串的最长相等前后缀所不包含的部分

如上图所示:
- 因为前缀k=后缀t,所以
k[0]=t[0]、k[1]=t[1]、k[2]=t[2] - 又因为
k[3]=t[0]、k[4]=t[1]、k[5]=t[2](很容易理解,他们对应于原字符串的相同位置),所以k[0:2]=k[3:5]=t[3:5] k[0:2]=k[3:5]=t[3:5]=>s[0:2]=s[3:5]=s[6:8](还是将k和t分别对应到原字符串s的相同位置来理解),因此s可以看成由s[0:2]重复多次组成
从上面的推导只能证明s[0:2]是s的重复子串,那如何进一步证明s[0:2]就是s的最小重复子串?
这里使用反证法来证明:
- 假设
s[0:2]不是最小重复子串,那它一定可以拆分成更小的重复子串,如s[0:2]=aaa,更小的重复子串为a,那么s=aaaaaaaaa,很明显最长相等前后缀的长度就不是6了,而应该更长。因此s[0:2]只能是最小重复子串,前缀k和后缀t才是现在的形式
知识点2:怎么根据next数组判断一个字符串是否由子串重复而成
条件1:如果一个字符串由子串重复而成,那其最长相等前后缀的长度一定是大于0的。假设s为子串,字符串为ss,那么最长相等前后缀长度一定大于等于s的长度,因为最少有前缀s和后缀s相同。条件2:从上面的证明可知,最小重复子串一定是原字符串的最长相等前后缀所不包含的部分,如果字符串由子串重复而成,那么字符串长度一定是子串长度的整数倍,因此s.length() % (s.length() - next[next.length - 1])一定等于0。
知识点3:为什么最长相等前后缀长度>0且s.length() % (s.length() - next[next.length - 1])==0就能推出字符串由重复子串组成
- 因为一旦满足这个条件,就可以参考
知识点1推出类似s[0:2]=s[3:5]=s[6:8]的关系
/**
* 使用KMP的next数组
* @param s
* @return
*/
public static boolean kmp(String s) {
int[] next = getNext(s);
// 如果最长相等前后缀长度>0 且 字符串长度 % (字符串长度 - 最长相等前后缀长度) == 0 则存在循环
if (next[next.length - 1] > 0 && s.length() % (s.length() - next[next.length - 1]) == 0) {
return true;
}
return false;
}
private static int[] getNext(String s) {
int[] next = new int[s.length()];
// j是前缀的末尾索引,i是后缀的末尾索引
int i, j = 0;
for (i = 1; i < s.length(); i++) {
//--for-- 从next的第二个元素开始填充,next[0]为0,因为一个字符的最长相等前后缀为0
while (j > 0 && s.charAt(i) != s.charAt(j)) {
// 当后缀的末尾字符与前缀末尾字符不相等时,将j回退
j = next[j - 1];
}
if (s.charAt(i) == s.charAt(j)) {
//--if-- 前缀末尾字符和后缀末尾字符相等时,j++
j++;
}
next[i] = j;
}
return next;
}