论文下载:https://zdzheng.xyz/files/TIP_Adaboost.pdf
备份:https://arxiv.org/pdf/2103.15685.pdf
作者:Zhedong Zheng,Yi Yang
代码链接: GitHub - layumi/AdaBoost_Seg: TIP2022 Adaptive Boosting (AdaBoost) for Domain Adaptation ? Why not !
What:
- “难”样本对于Domain Adaptation 语意分割模型来说特别重要,比如 Cityscapes中 “train”这种类别出现的场景比较少,自然在“Cityscapes”上的火车预测也特别差。 这就导致,每次训练,模型的抖动特别大, 有时候不同epoch(如data shuffle顺序不同等因素),就会在测试集上 就有 较大的performance gap。
- 所以考虑到 难样本挖掘,一个很自然的想法就是 用Adaboost, 这个是我的人脸检测老本行中一个最work的策略。具体可见(郑哲东:AdaBoost 笔记) 大概意思是,每次根据之前的“弱分类器”决定下一轮 我们应该学什么。在人脸检测上,就是根据前一个分类器分错的样本,做针对性的优化。
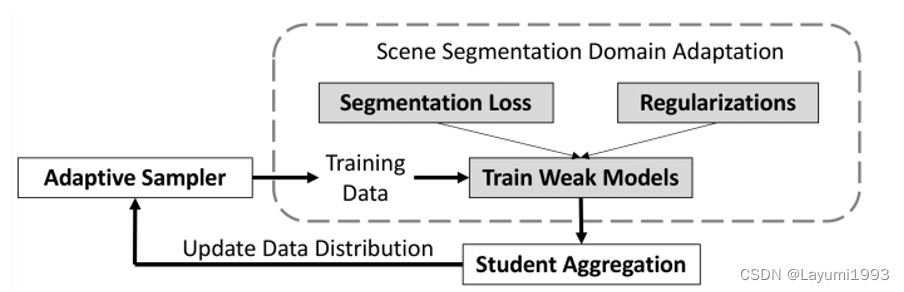
- 故本文基于Adaboost 的概念,做了一个很简单的事情,针对 Domain Adapation 这个任务 做 Adaptative Boosting。 根据训练过程中的snapshot(可以看成弱分类器),来针对性“选择”难样本,提高他们采样到的概率,如下图。
How:
- 其实思路是 还是按照以前模型训练方式,有source domain上的 Segmentation loss 和 一些正则Regularization (比如 adversarial loss 拉近两个 domain的gap)
- 通过这种方法 我们可以每轮训练一个模型,得到weak models (这都是在一次训练中的),我们通过weight moving average的方式 得到 Student Aggregation 也就是 “臭皮匠们组成的诸葛亮”。
- 我们根据“诸葛亮” 主分类器和辅助分类器意见不同的样本来估计 样本难度。 如下图,
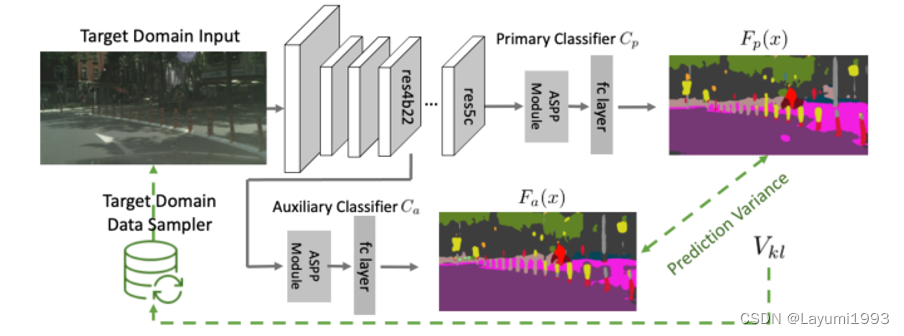
4. 通过估计出来的预测KL差异(样本难度) Vkl 我们去更新 目标领域采样器,给难样本多采一些。 如下更新采样方式:(这里Vkl 我们做了 Softmax确保 所有样本的概率和是1。 )

5. 其实“臭皮匠们组成的诸葛亮”的方式 就很简单 ,就是 平均模型参数,在训练过程中,我们用了一个简单的动态 公式。进来一个之前臭皮匠就往下来,新来的给一个平均权重。
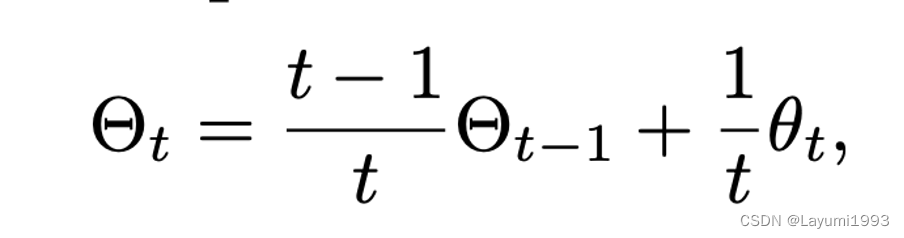
实验:
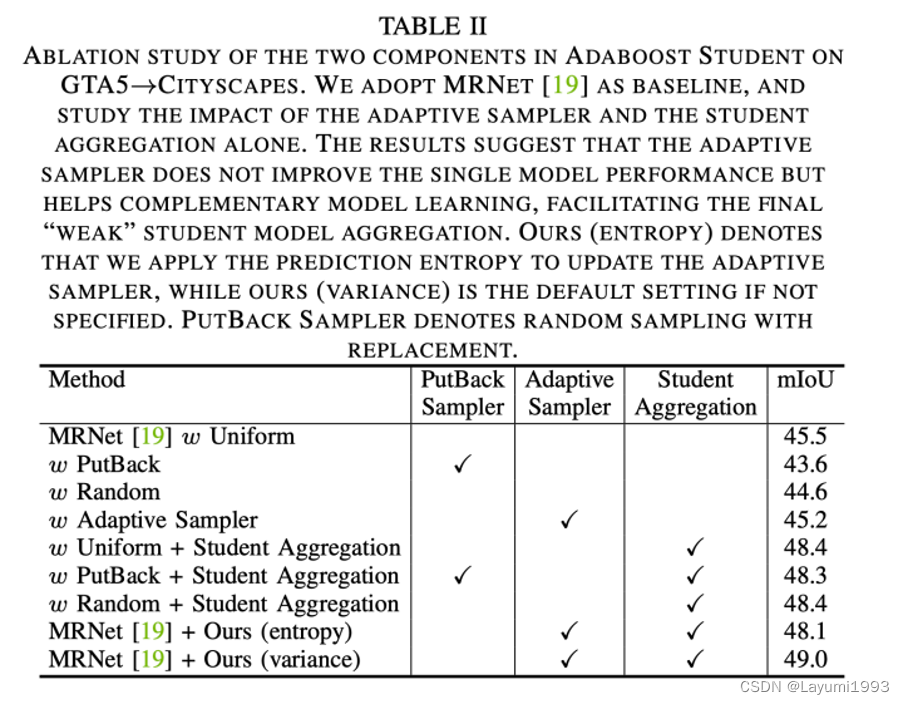
- 需要注意的是:单纯使用 难样本采样策略,是不能保证单个模型能训练得更好的。 因为就像Adaboost一样,我们让模型overfit难样本,为了获得一个互补的模型,这个单模型在单独使用的情况下,不一定能更好。我们得到了一个类似的结论,单用难样本只能到 48.1,但结合 了 模型组合 可以到 49.0 。 同时如果只能模型组合嫩到 48.4左右的 准确率。
2. 归功于弱模型组合,我们的训练过程也比较稳定。相比虚线的 传统方案,显然我们组合后的模型较为稳定。
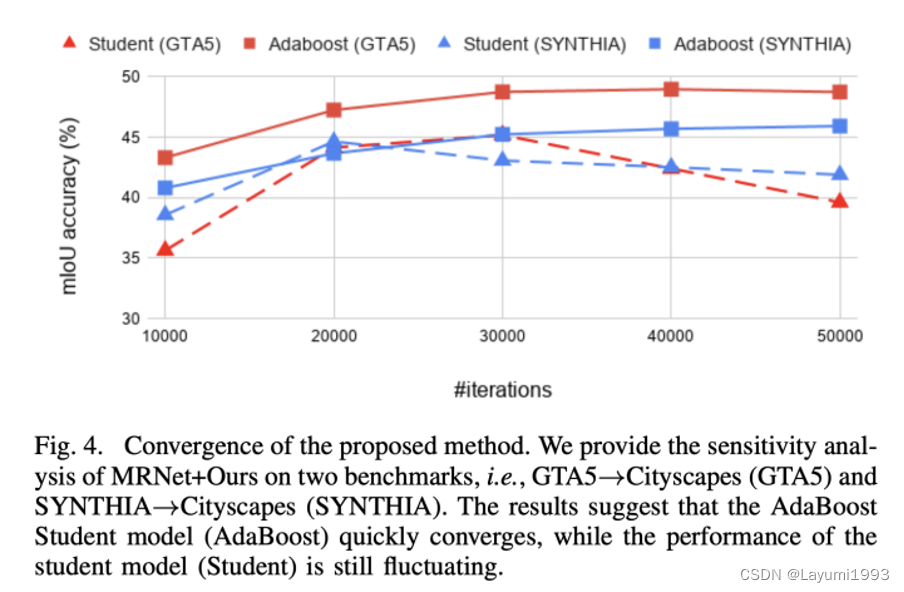
3. 同时我们在 几个 benchmarks 也体现出了相对的提升(已经不是sota了。。最新的sota可以关注我们的另一个工作:GitHub - chen742/PiPa: Official Implementation of PiPa: Pixel- and Patch-wise Self-supervised Learning for Domain Adaptative Semantic Segmentation )
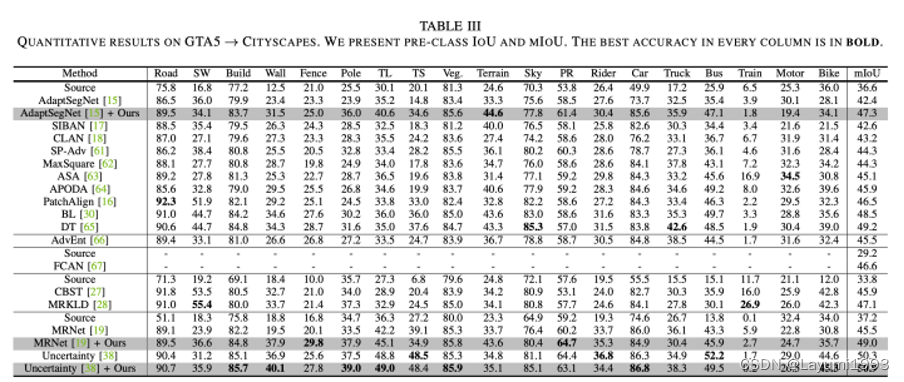
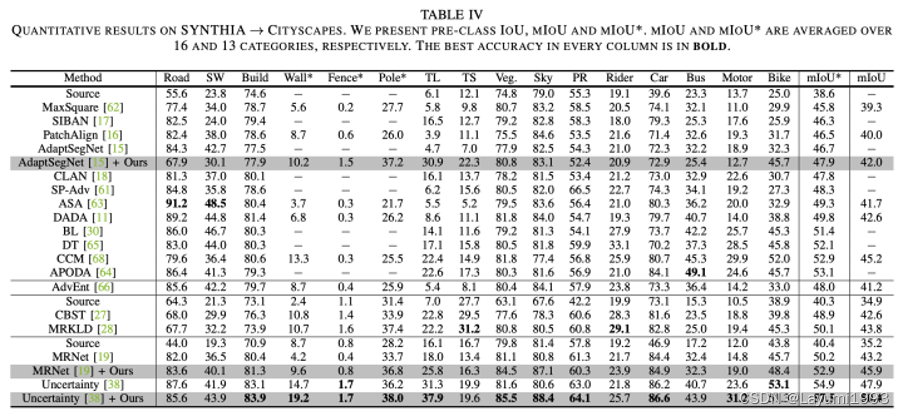
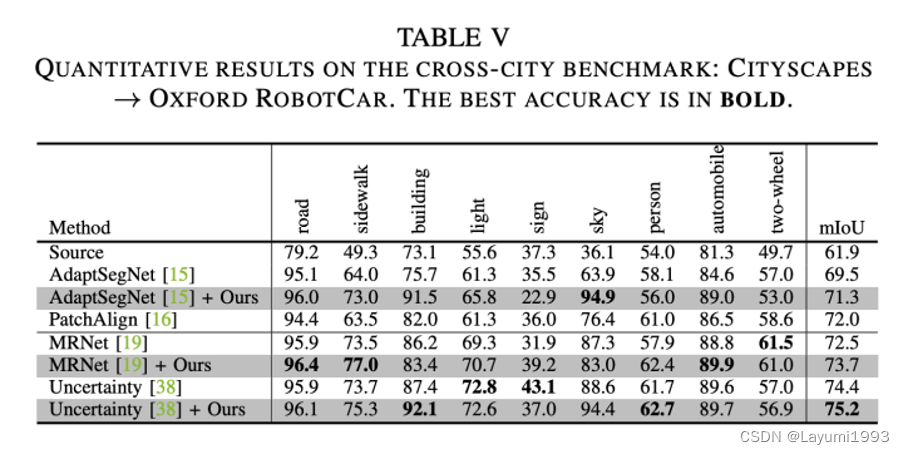
4. 另外我们提出的方法在传统 像VGG16backbone上也work。
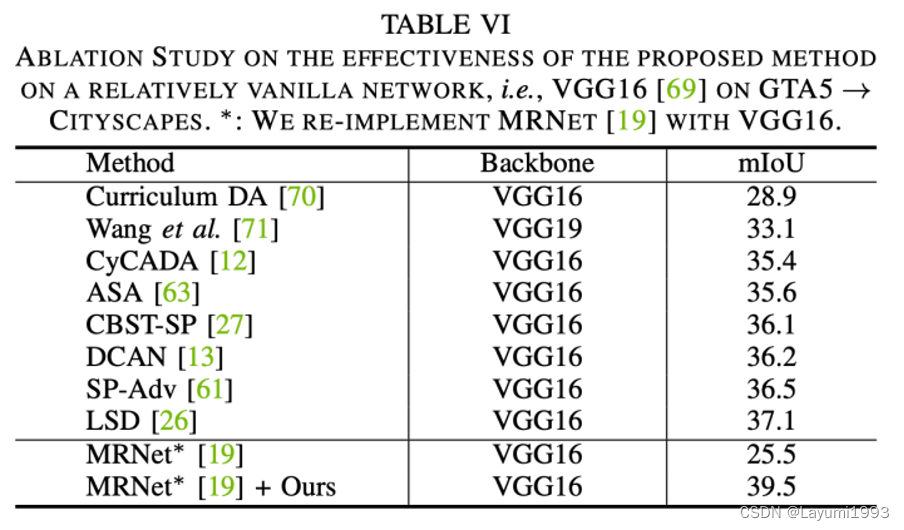
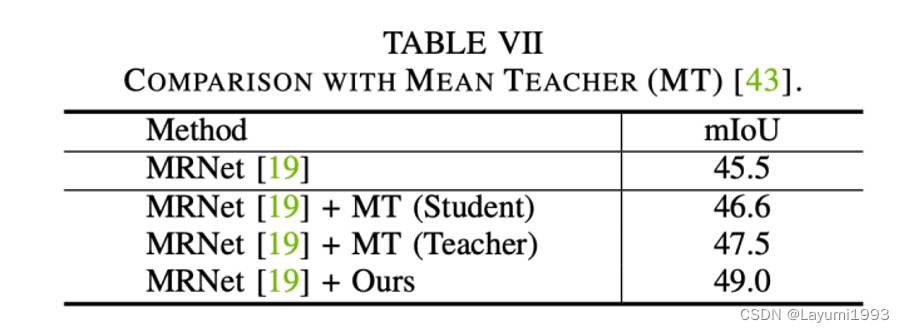
5. 我们也与 MeanTeacher做了一些比较。我们没有引入 teacher student distillation loss 所以 这样反而保证了单个模型 的 互补性。在Cifar10上 基于同一个网络结构,我们也比 MeanTeacher更高一些。

最后感谢大家看完,欢迎点赞转发~~