目录
- 1.全连接层存在的问题
- 2.卷积运算
- 3.填充(padding)
- 3.1填充(padding)的意义
- 4.步幅(stride)
- 5.三维数据的卷积运算
- 6.结合方块思考
- 7.批处理
- 8.Conv2D函数解析
- 9.conv2d代码
- 9.1 stride=1
- 9.2 stride=2
- 参考文章
1.全连接层存在的问题
在全连接层中,相邻层的神经元全部连接在一起,输出的数量可以任意决定。全连接层存在什么问题呢?那就是数据的形状被“忽视”了。比如,输入数据是图像时,图像通常是高、长、通道方向上的3维形状。但是,向全连接层输入时,需要将3维数据拉平为1维数据。实际上,前面提到的使用了MNIST数据集的例子中,输入图像就是1通道、高28像素、长28像素的(1, 28, 28)形状,但却被排成1列,以784个数据的形式输入到最开始的Affine层。图像是3维形状,这个形状中应该含有重要的空间信息。比如,空间上邻近的像素为相似的值、RBG的各个通道之间分别有密切的关联性、相距较远的像素之间没有什么关联等,3维形状中可能隐藏有值得提取的本质模式。但是,因为全连接层会忽视形状,将全部的输入数据作为相同的神经元(同一维度的神经元)处理,所以无法利用与形状相关的信息。而卷积层可以保持形状不变。当输入数据是图像时,卷积层会以3维数据的形式接收输入数据,并同样以3维数据的形式输出至下一层。因此,在CNN中,可以(有可能)正确理解图像等具有形状的数据。另外,CNN 中,有时将卷积层的输入输出数据称为特征图(feature map)。其中,卷积层的输入数据称为输入特征图(input feature map),输出数据称为输出特征图(output feature map)。本文中将“输入输出数据”和“特征图”作为含义相同的词使用.
2.卷积运算
卷积层进行的处理就是卷积运算。卷积运算相当于图像处理中的“滤波器运算”。在介绍卷积运算时,我们来看一个具体的例子(图7-3)。

如图7-3所示,卷积运算对输入数据应用滤波器。在这个例子中,输入数据是有高长方向的形状的数据,滤波器也一样,有高长方向上的维度。假设用(height, width)表示数据和滤波器的形状,则在本例中,输入大小是(4, 4),滤波器大小是(3, 3),输出大小是(2, 2)。另外,有的文献中也会用“核”这个词来表示这里所说的“滤波器”。现在来解释一下图7-3的卷积运算的例子中都进行了什么样的计算。图7-4中展示了卷积运算的计算顺序。对于输入数据,卷积运算以一定间隔滑动滤波器的窗口并应用。这里所说的窗口是指图7-4中灰色的3 × 3的部分。如图7-4所示,将各个位置上滤波器的元素和输入的对应元素相乘,然后再求和(有时将这个计算称为乘积累加运算)。然后,将这个结果保存到输出的对应位置。将这个过程在所有位置都进行一遍,就可以得到卷积运算的输出。在全连接的神经网络中,除了权重参数,还存在偏置。CNN中,滤波器的参数就对应之前的权重。并且,CNN中也存在偏置。图7-3的卷积运算的例子一直展示到了应用滤波器的阶段。包含偏置的卷积运算的处理流如图7-5所示。如图7-5所示,向应用了滤波器的数据加上了偏置。偏置通常只有1个(1 × 1)(本例中,相对于应用了滤波器的4个数据,偏置只有1个),这个值会被加到应用了滤波器的所有元素上。


3.填充(padding)
在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比如0等),这称为填充(padding),是卷积运算中经常会用到的处理。比如,在图7-6的例子中,对大小为(4, 4)的输入数据应用了幅度为1的填充。“幅度为1的填充”是指用幅度为1像素的0填充周围。

如图7-6所示,通过填充,大小为(4, 4)的输入数据变成了(6, 6)的形状。然后,应用大小为(3, 3)的滤波器,生成了大小为(4, 4)的输出数据。这个例子中将填充设成了1,不过填充的值也可以设置成2、3等任意的整数。在图7-5的例子中,如果将填充设为2,则输入数据的大小变为(8, 8);如果将填充设为3,则大小变为(10, 10)
3.1填充(padding)的意义
使用填充主要是为了调整输出的大小。比如,对大小为(4, 4)的输入数据应用(3, 3)的滤波器时,输出大小变为(2, 2),相当于输出大小比输入大小缩小了 2个元素。这在反复进行多次卷积运算的深度网络中会成为问题。为什么呢?因为如果每次进行卷积运算都会缩小
空间,那么在某个时刻输出大小就有可能变为 1,导致无法再应用卷积运算。为了避免出现这样的情况,就要使用填充。在刚才的例子中,将填充的幅度设为 1,那么相对于输入大小(4, 4),输出大小也保持为原来的(4, 4)。因此,卷积运算就可以在保持空间大小不变
的情况下将数据传给下一层。
4.步幅(stride)

在图7-7的例子中,对输入大小为(7, 7)的数据,以步幅2应用了滤波器。通过将步幅设为2,输出大小变为(3, 3)。像这样,步幅可以指定应用滤波器的间隔。综上,增大步幅后,输出大小会变小。而增大填充后,输出大小会变大。如果将这样的关系写成算式,会如何呢?接下来,我们看一下对于填充和步幅,如何计算输出大小。这里,假设输入大小为(H, W),滤波器大小为(FH, FW),输出大小为(OH, OW),填充为P,步幅为S。此时,输出大小可通过式(7.1)进行计算。
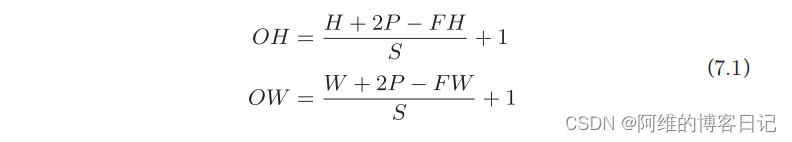

5.三维数据的卷积运算
之前的卷积运算的例子都是以有高、长方向的2维形状为对象的。但是,图像是3维数据,除了高、长方向之外,还需要处理通道方向。这里,我们按照与之前相同的顺序,看一下对加上了通道方向的3维数据进行卷积运算的例子。图7-8是卷积运算的例子,图7-9是计算顺序。这里以3通道的数据为例,展示了卷积运算的结果。和2维数据时(图7-3的例子)相比,可以发现纵深方向(通道方向)上特征图增加了。通道方向上有多个特征图时,会按通道进行输入数据和滤波器的卷积运算,并将结果相加,从而得到输出。


需要注意的是,在3维数据的卷积运算中,输入数据和滤波器的通道数要设为相同的值。在这个例子中,输入数据和滤波器的通道数一致,均为3。滤波器大小可以设定为任意值(不过,每个通道的滤波器大小要全部相同)。这个例子中滤波器大小为(3, 3),但也可以设定为(2, 2)、(1, 1)、(5, 5)等任意值。再强调一下,通道数只能设定为和输入数据的通道数相同的值(本例中为3)。
6.结合方块思考
将数据和滤波器结合长方体的方块来考虑,3维数据的卷积运算会很容易理解。方块是如图7-10所示的3维长方体。把3维数据表示为多维数组时,书写顺序为(channel, height, width)。比如,通道数为C、高度为H、长度为W的数据的形状可以写成(C, H, W)。滤波器也一样,要按(channel, height, width)的顺序书写。比如,通道数为C、滤波器高度为FH(Filter Height)、长度为FW(Filter Width)时,可以写成(C, FH, FW)。

在这个例子中,数据输出是1张特征图。所谓1张特征图,换句话说,就是通道数为1的特征图。那么,如果要在通道方向上也拥有多个卷积运算的输出,该怎么做呢?为此,就需要用到多个滤波器(权重)。用图表示的话,如图7-11所示。

图7-11中,通过应用FN个滤波器,输出特征图也生成了FN个。如果将这FN个特征图汇集在一起,就得到了形状为(FN, OH, OW)的方块。将这个方块传给下一层,就是CNN的处理流。如图 7-11 所示,关于卷积运算的滤波器,也必须考虑滤波器的数量。因此,作为4维数据,滤波器的权重数据要按(output_channel, input_channel, height, width)的顺序书写。比如,通道数为3、大小为5 × 5的滤波器有20个时,可以写成(20, 3, 5, 5)。卷积运算中(和全连接层一样)存在偏置。在图7-11的例子中,如果进一步追加偏置的加法运算处理,则结果如下面的图7-12所示。图7-12中,每个通道只有一个偏置。这里,偏置的形状是(FN, 1, 1),滤波器的输出结果的形状是(FN, OH, OW)。这两个方块相加时,要对滤波
器的输出结果(FN, OH, OW)按通道加上相同的偏置值。另外,不同形状的方块相加时,可以基于NumPy的广播功能轻松实现(1.5.5节)。

7.批处理
神经网络的处理中进行了将输入数据打包的批处理。之前的全连接神经网络的实现也对应了批处理,通过批处理,能够实现处理的高效化和学习时对mini-batch的对应。我们希望卷积运算也同样对应批处理。为此,需要将在各层间传递的数据保存为4维数据。具体地讲,就是按(batch_num, channel, height, width)的顺序保存数据。比如,将图7-12中的处理改成对N个数据进行批处理时,数据的形状如图7-13所示。图7-13的批处理版的数据流中,在各个数据的开头添加了批用的维度。像这样,数据作为4维的形状在各层间传递。这里需要注意的是,网络间传递的是4维数据,对这N个数据进行了卷积运算。也就是说,批处理将N次的处理汇总成了1次进行.

8.Conv2D函数解析
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’, device=None, dtype=None)
-
in_channels:输入通道数,也就是图7-13中的C,指示多少张H×W -
out_channels:输出通道数,也就是图7-13中的FN -
kernel_size:卷积核大小,也就是滤波器大小,可以自定义为num或者是num1×num2
当kernel_size为num时,表示卷积核大小为num×num. -
stride:当stride=1,卷积核如图9-1所示移动,第一行卷积完毕时,到第二行卷积,其中卷积核每次卷积在水平方向上移动时相差stride=1个格子,垂直方向移动时,相差stride=1个格子.当stride=2时,卷积核如图9-2所示移动,第一行卷积完毕时,从第一行蹦到第三行卷积.水平方向移动时相隔stride=2个格子移动,垂直方向上移动时,相差stride=2个格子移动. -
padding:padding=0是表示不填充任何0,padding=1表示从(A,A)大小填充为(A+2,A+2),因为是上下左右同时填充1个,所以都要加2. -
dilation,这个参数涉及到空洞卷积的东西,但是这个我不太理解,只知道dilation=1时就是我们正常卷积.

空洞卷积参考
👉:🔗深入理解空洞卷积
👉:🔗Convolution arithmetic -
groups分组卷积,一般取值groups = in_channels.这个不太理解,只知道取值一般就是这样,原因以后再补充.现在研一啥也不懂 -
bias即是否要添加偏置参数作为可学习参数的一个,默认为True。 -
padding_mode='zeros':即padding的模式,默认采用零填充
9.conv2d代码
9.1 stride=1

import torch
import torch.nn as nn
# 设定一个[1, 3, 5, 5]的输入
input = torch.Tensor([[[[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5]],
[[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5]],
[[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5]]]])
# 设定一个卷积
conv = nn.Conv2d(in_channels=3,
out_channels=3,
kernel_size=3,
#这里的kernel_size=3和kernel_size=(3,3)意思一样
stride=1,
padding=0,
# 注意,这里padding=0意思是不填充任何数字
# 若padding=1,则举个例子,原来的(3,3)是填充为(5,5),而非(4,4)
dilation=1,
groups=3)
# 设定卷积的权重数值
conv.weight.data = torch.Tensor([[[[1, 1, 1],
[1, 1, 1],
[1, 1, 1]]],
[[[2, 2, 2],
[2, 2, 2],
[2, 2, 2]]],
[[[3, 3, 3],
[3, 3, 3],
[3, 3, 3]]]])
# 利用卷积得到输出
output = conv(input)
print(output)
9.2 stride=2

import torch
import torch.nn as nn
# 设定一个[1, 3, 5, 5]的输入
input = torch.Tensor([[[[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5]],
[[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5]],
[[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5]]]])
# 设定一个卷积
conv = nn.Conv2d(in_channels=3,
out_channels=3,
kernel_size=3,
stride=2,
padding=0,
dilation=1,
groups=3)
# 设定卷积的权重数值
conv.weight.data = torch.Tensor([[[[1, 1, 1],
[1, 1, 1],
[1, 1, 1]]],
[[[2, 2, 2],
[2, 2, 2],
[2, 2, 2]]],
[[[3, 3, 3],
[3, 3, 3],
[3, 3, 3]]]])
# 利用卷积得到输出
output = conv(input)
print(output)
参考文章
[1]🔗Pytorch的nn.Conv2d详解
[2]🔗深入理解空洞卷积
[3]🔗Convolution arithmetic








![洛谷 P1216 [USACO1.5] [IOI1994]数字三角形题解](https://img-blog.csdnimg.cn/6744dd4a7e5a4921b44b637a4122c13f.png)