深度强化学习 第 5 章 SARSA 算法
news2026/2/16 4:45:44

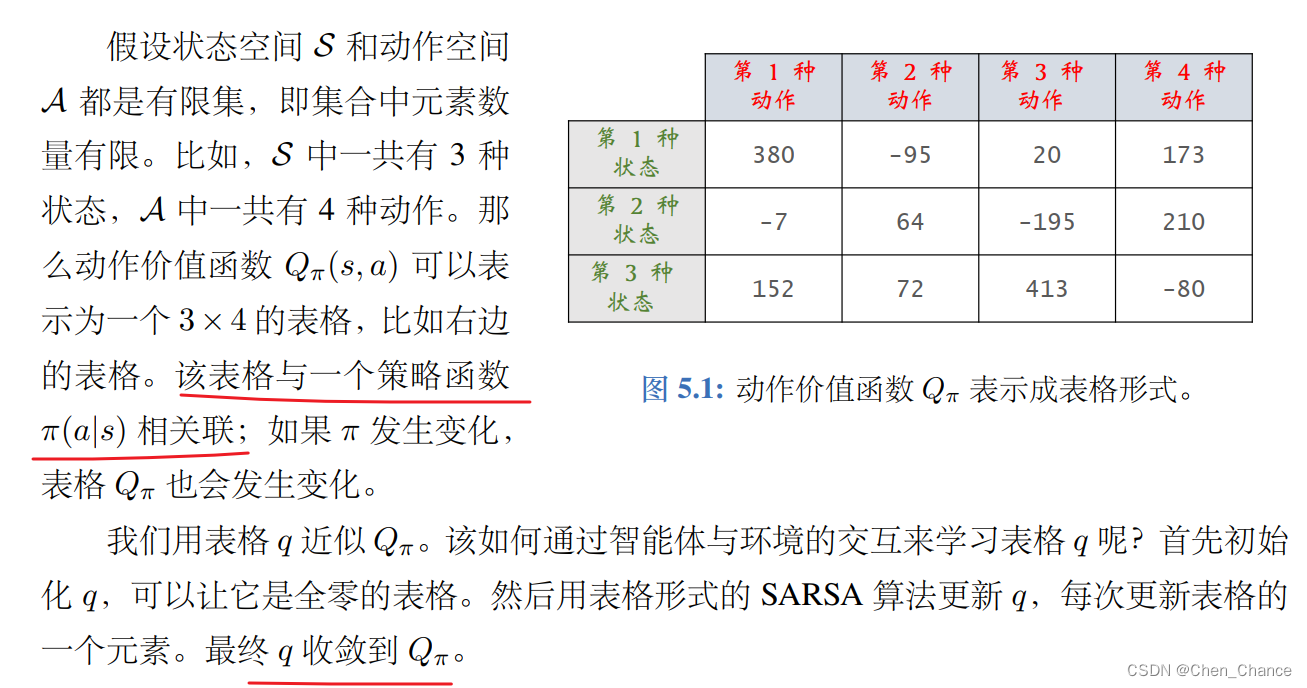
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1117734.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

vue3 + fastapi 实现选择目录所有文件自定义上传到服务器
文章目录 ⭐前言💖 技术栈选择 ⭐前端页面搭建💖 调整请求content-type传递formData ⭐后端接口实现💖 swagger文档测试接口 ⭐前后端实现效果💖 上传单个文件💖 上传目录文件 ⭐总结⭐结束 ⭐前言
大家好,…


2024免费的苹果电脑杀毒软件cleanmymac X
苹果电脑怎么杀毒?这个问题自从苹果电脑变得越来越普及,苹果电脑的安全性问题也逐渐成为我们关注的焦点。虽然苹果电脑的安全性相对较高,但仍然存在着一些潜在的威胁,比如流氓软件窥探隐私和恶意软件等。那么,苹果电脑…
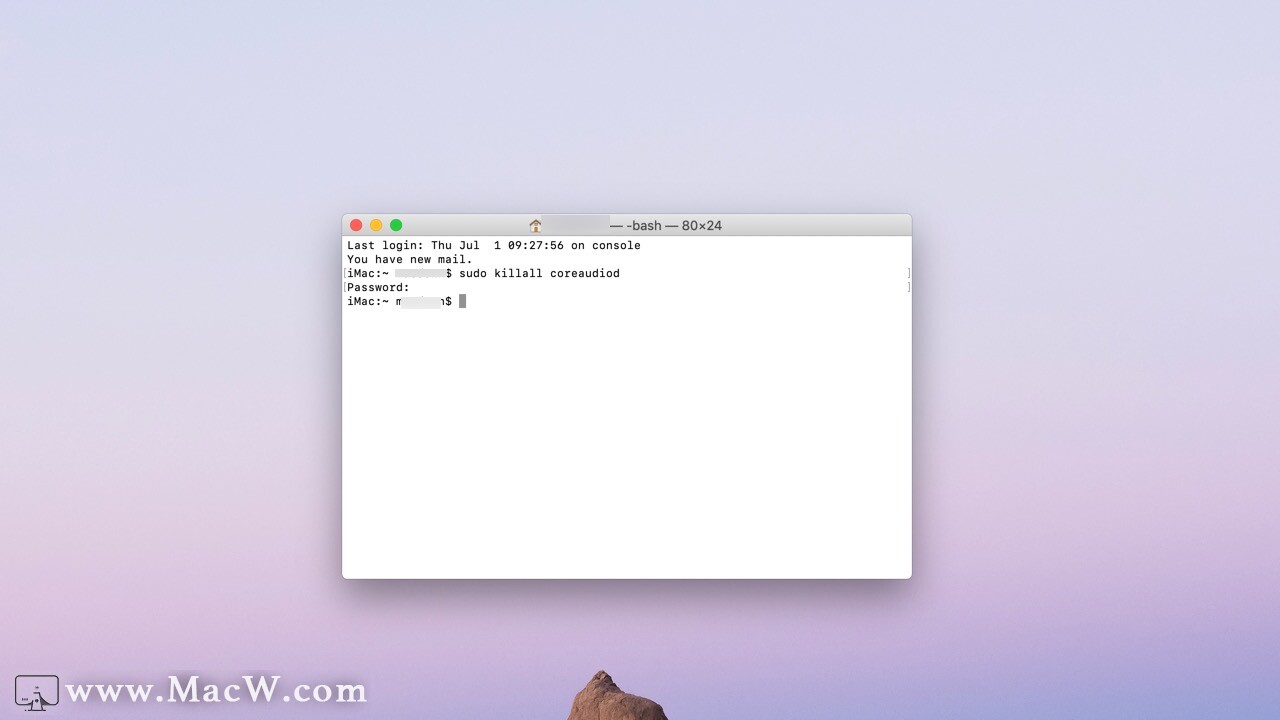
mac苹果电脑使用耳机听不到声音
大家在使用耳机收听音乐时候?是否经常遇到声音和音频播放问题的情况。这里小编为大家带来了三种不同的方法,帮助大家解决耳机在macOS系统电脑上怎么听不到任何声音的教程。如果大家对这篇文章感兴趣,那就来看下面的具体步骤吧。
方法一、检查…
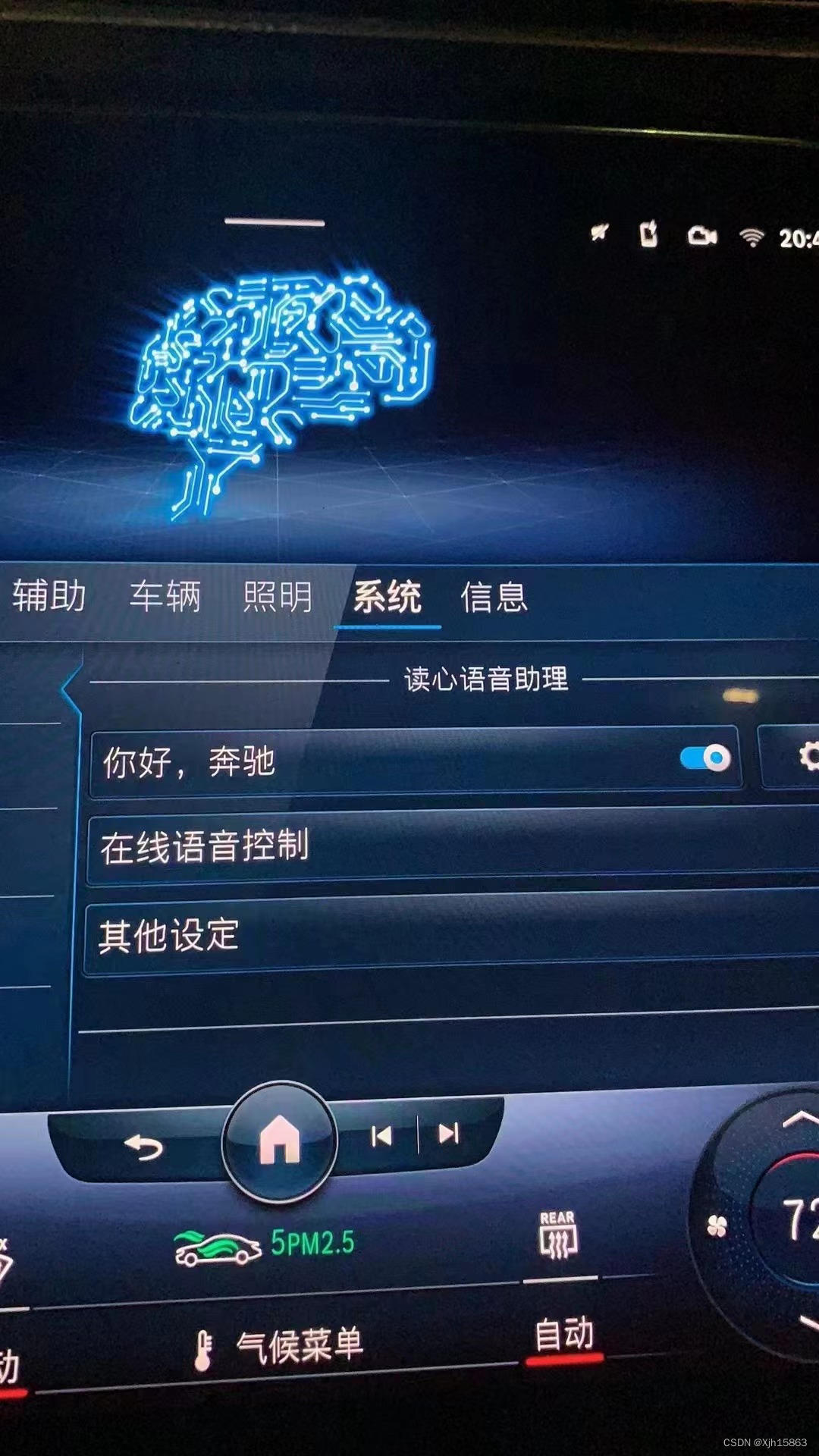
平行进口美规,加版奔驰S500 S580更换主机,汉化导航,语音交互等功能
平行进口美规,加版奔驰S500 S580更换中规主机后,有中国地图导航,AR实景画面,中文你好奔驰,汉化摄氏度,激活自动变道,增强型抬头显示还可以实现箭头指示功能,原车带流星雨大灯还可以实…

人均瑞数系列,瑞数 6 代 JS 逆向分析
声明
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未…

“时尚设计 时尚原创”首届广州(三元里)时尚设计大赛正式起航
10月18日上午,由广州市商务局、广州市工业和信息化局、白云区人民政府指导,白云区科技工业商务和信息化局、白云区三元里街道办事处主办,广东省皮具商会、三元里街工商业联合会承办,白云世界皮具贸易中心作为执行单位的首届广州(三…

免费高清壁纸下载(静态和动态壁纸)
一、网址下载(静态壁纸)
高清图片直接另存为就可以了。然后在电脑空白处右键——个性化设置即可替换壁纸。 ①网址:https://www.hippopx.com
②极简壁纸:https://bz.zzzmh.cn/index ③彼岸图网:http://pic.netbian…

大模型基础——大模型范式
大模型背后的范式
整个预训练语言模型的使用范式: 对于预训练模型,最核心的要素是从无标注的数据中去学习,通过自监督的一些任务去做预训练,得到丰富的知识。在具体的应用中,会引入一些任务相关的数据,去调…

Leetcode—2525.根据规则将箱子分类【简单】
2023每日刷题(五)
Leetcode—2525.根据规则将箱子分类 实现代码
char * categorizeBox(int length, int width, int height, int mass){long long volume;long long len (long long)length;long long wid (long long)width;long long heig (long lo…

VFP GRID每行BLOB显示图片,简单几行代码就完成啦
不止一位狐友问我,想在表格里面显示图片,于是我想了想,满足狐友们的期望,升级了一个框架控件,再来个超容易的教程。 一、拖入一个表单 二、删除自动生成的TEXTBOX1 选中表格,右键->编辑 ,点击…
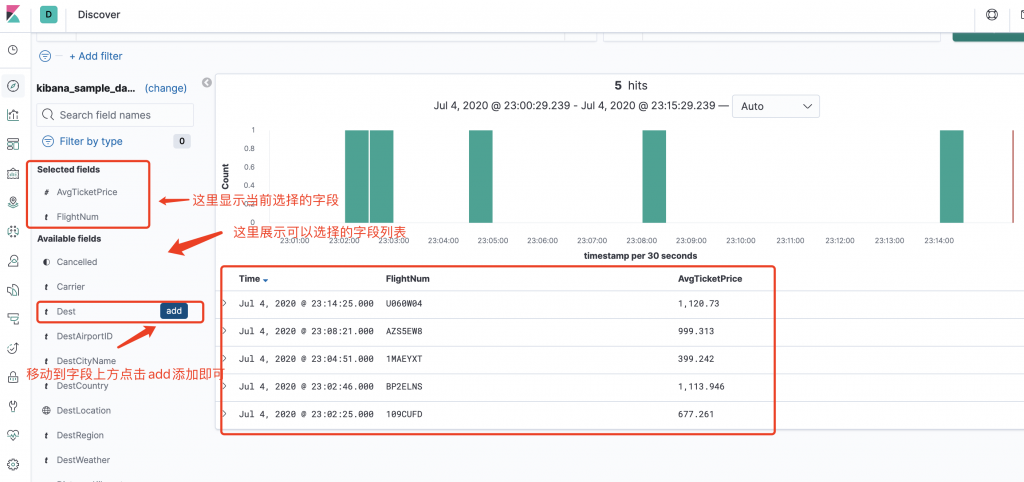
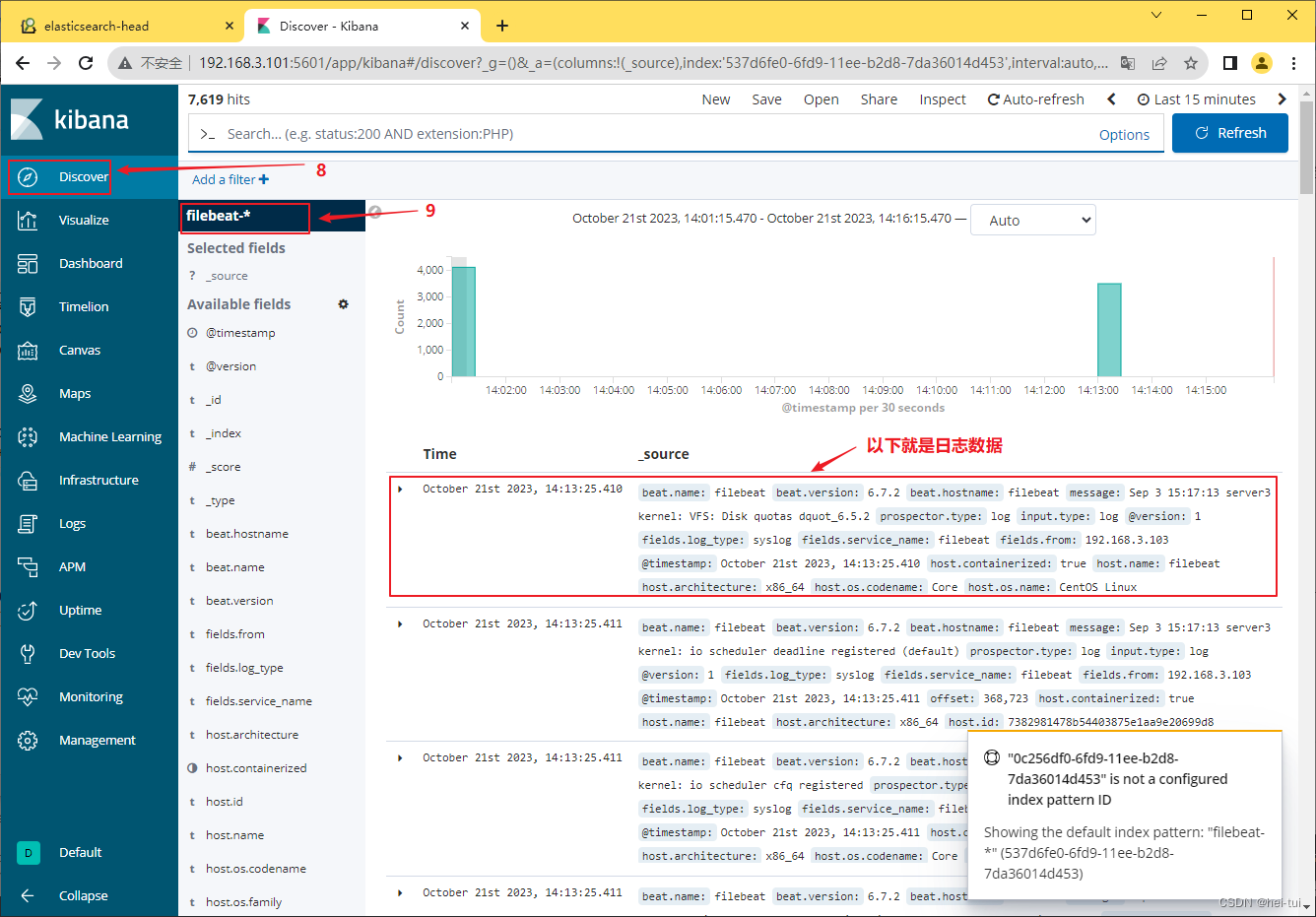
Kibana Discover数据查询
步骤1:打开管理页面(Management) 步骤2:
因为前面的章节导入航班数据的时候,自动创建了一个名字叫kibana_sample_data_flights的航班数据索引,如果我们只想搜索kibana_sample_data_flights索引的数据,则不需要通配符&…
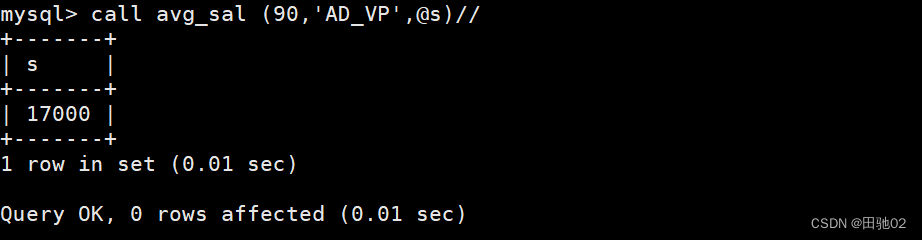
Mysql数据库表操作--存储
建表: 插入上面的数据: 1、创建一个可以统计表格内记录条数的存储函数 ,函数名为count_sch() 2、创建一个存储过程avg_sal,有3个参数,分别是deptno,job,接收平均工资(out);功能查询employees表的…
不做技术不会管理,测试人还有这个职位可以进阶
之前我们讲过,测试工程师的4层技术发展路线都需要掌握哪些技能。学而优则仕,今天我们来说说如果想做某个行业的专家应该掌握哪些技能。
如果你对测试技术不感兴趣,但对某领域的业务兴趣浓厚,可以考虑行业专家路线。
由于测试工程…

python单元测试框架(继承、unittest参数化、断言、测试报告)
一、继承
继承能解决什么问题?
unittest每个模块都要用到前提条件以及清理,如果有上百个模块,我们要改域名和浏览器,就会工作量很大特别麻烦,这时我们可以用继承的思想只用改一次
我们可以将前提和清理提出来单独放…
日志分析系统——ELK
目录
一、ELK概述
ELK的组成
1、ElasticSearch
2、Logstash
3、Kiabana
完整日志采集系统基本特征
ELK的工作原理
二、ELK的部署
1、环境准备
2、部署ElasticSearch软件
3、安装Elasticsearch-head插件
4、Logstash部署
5、Kibana部署
三、FilebeatELK部署
1、安…

python基础教程:递归函数教程
嗨喽,大家好呀~这里是爱看美女的茜茜呐 1.递归的定义:
在函数内部直接或者间接调用函数本身 👇 👇 👇 更多精彩机密、教程,尽在下方,赶紧点击了解吧~
python源码、视频教程、插件安装教程、资…
数据科学中常用的应用统计知识
随着大数据算法技术发展,数据算法越来越倾向机器学习和深度学习相关的算法技术,概率论和应用统计 等传统的技术貌似用的并不是很多了,但实则不然,在数据科学工作,还是会经常需要应用统计概率相关知识解决一些数据问题&…