在探索和理解复杂的金融市场行为时,时间序列分析成为了一种无法忽视的强有力工具。特别是,当我们处理的不仅是单一的时间序列,而是多个时间序列并存,并且它们之间存在一种或多种形式的互动时,多元时间序列分析的重要性就显得尤为突出。在本章节中,我们将专注于多元时间序列的传统模型,探索它们的理论基础,分析它们的构建与验证过程,以及它们在金融领域中的应用。
本文将首先探讨向量自回归模型(VAR),它为分析多元时间序列提供了一种基础框架,允许我们建立多个变量之间的动态交互关系。接下来,将讨论向量误差修正模型(VECM),一个考虑了变量间长期均衡关系的VAR模型扩展。这将引导我们进入格兰杰因果检验的领域,一个用于检测变量间“因果”关系的有力工具。最后,探讨协整分析,一种用于寻找非平稳时间序列之间长期稳定关系的方法。
这些模型和方法都是多元时间序列分析的重要部分,它们提供了理解和预测金融市场动态行为的重要视角。本文将结合理论和实证案例,详细探讨这些模型的应用,以期对金融市场的研究提供更深的洞见。
一、向量自回归模型
(一)模型介绍与理论基础
在分析复杂的多变量系统时,向量自回归模型(Vector Autoregressive Model,简称VAR)是一种无可替代的工具。VAR模型是一种多变量时间序列模型,其中每个观察值都被设定为其历史值的函数。VAR模型因其简单的数学结构和分析深度而受到广泛的应用。通过VAR模型,我们不仅可以对多个变量之间的互动关系进行量化,还可以根据已有数据进行未来值的预测。
VAR模型的基本形式是多元线性模型,我们假设有K个观测变量,采用一个p阶的VAR模型,其形式可以写成:
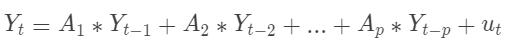
其中:
是一个 K 维向量,表示在时间 t 的所有变量的值。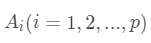 是 K x K 维的矩阵,表示各个变量对其他变量的影响力度。
是 K x K 维的矩阵,表示各个变量对其他变量的影响力度。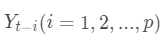 是在时间 t-i 的所有变量的值。
是在时间 t-i 的所有变量的值。
是一个 K 维向量,表示误差项,它们相互独立且同分布(i.i.d),每个误差项的期望值为0,协方差矩阵为 。在VAR模型中,我们假设所有的变量都是内生的,即每个变量都被模型内的其他变量解释。这个特性使得VAR模型能够捕捉到多个变量之间的动态交互关系。因此,VAR模型广泛应用于经济学、金融学、社会学等许多领域,尤其是在分析和预测金融市场动态行为时。
然而,VAR模型也有其局限性。首先,它只能捕捉到线性关系,对于非线性关系无法很好的处理。其次,它假设各变量间的关系不随时间变化,这在许多现实问题中是不合适的。此外,当观测变量的数量增加时,VAR模型的参数数量会快速增加,这会导致模型的估计和检验变得复杂。
尽管如此,VAR模型仍然是分析多元时间序列的重要工具。通过调整模型的阶数、变量选择等策略,我们可以有效地利用VAR模型来揭示数据背后的动态结构,并进行有效的预测。
(二)参数估计和模型验证
向量自回归模型的参数估计通常使用最小二乘法(OLS)来进行,它的基本思想是通过最小化误差的平方和来找到参数的最优解。每一个方程都可以独立地应用最小二乘法进行估计,这是VAR模型的一个显著特点。
具体步骤如下:
首先,我们将VAR模型中的每个方程都表示为一个回归模型;
对于每个回归模型,我们使用最小二乘法来估计参数;
通过最小化每个模型的残差平方和,我们可以获得每个参数的估计值。
在参数估计后,我们通常需要对模型进行验证。模型验证的目的是检查我们的模型是否满足某些统计性质,例如:
残差是否是白噪声:我们可以使用Ljung-Box检验来进行检验,如果残差是白噪声,那么说明模型已经充分捕获了数据中的信息;
参数是否稳定:我们可以绘制模型的反根图来进行检验,如果所有的反根都在单位圆内,那么模型就是稳定的。
这些检验都是在构建VAR模型时必须要进行的步骤,它们可以帮助我们确保模型的可靠性和有效性。
(三)VAR的应用及其扩展模型
VAR模型在金融领域中具有广泛的应用,可以帮助分析和预测金融市场中多个变量之间的动态关系。以下是一些VAR模型在金融领域的应用和其变种的概述:
风险管理:VAR模型可以用于评估金融资产之间的风险传播和相关性。通过构建多变量VAR模型,可以分析不同资产之间的风险溢出效应,识别系统性风险,并进行风险度量和压力测试。
投资组合分析:VAR模型可以用于评估不同投资组合的风险和收益特征。通过建立多变量VAR模型,可以分析投资组合中各个资产之间的相互关系,优化资产配置,降低投资组合的风险,并提高预期收益。
波动率建模:VAR模型的扩展形式,如VEC模型(向量误差修正模型),可以用于建模和预测金融市场的波动率。通过分析变量之间的协整关系和误差修正机制,可以估计波动率的条件方差,并进行波动率预测和波动率融资策略。
金融市场预测:VAR模型可以用于预测金融市场的变量,如股票价格、利率、汇率等。通过建立多变量VAR模型,可以捕捉变量之间的动态关系和影响,进行短期和中长期的市场预测。
除了传统的VAR模型,还有一些变种模型用于扩展和改进VAR的应用:
VARMA模型:结合向量自回归(VAR)和移动平均(MA)模型,用于处理时间序列数据中的滞后和滞后误差。它是VAR模型的扩展,可以更好地捕捉数据的动态性和非线性特征。在Python中,可以使用statsmodels库来实现VARMA模型的估计和预测。
VAR-GARCH模型:将VAR模型与广义自回归条件异方差(GARCH)模型结合,用于建模金融市场的波动率和风险溢出效应。它可以更准确地描述金融时间序列数据中的波动性和风险特征。在Python中,可以使用arch库来实现VAR-GARCH模型的估计和预测。
TVP-VAR模型:时间可变参数VAR模型,考虑VAR模型中的参数随时间变化的情况,适用于处理非稳定的时间序列数据。它可以更好地捕捉数据的动态变化和结构突变。在Python中,可以使用pyflux库来实现TVP-VAR模型的估计和预测。
SVAR模型:结构向量自回归模型,用于分析金融市场中的因果关系和冲击传递机制。在Python中,可以使用statsmodels库来实现SVAR模型的估计和分析。
这些变种模型在金融领域的应用进一步丰富了VAR模型的功能和灵活性,有助于更准确地分析金融市场的动态特征和进行相关决策。
(四)实战应用:基于VAR模型的金融市场分析
VAR模型在金融领域的应用广泛,其中一个重要的应用是用于分析金融市场中多种资产收益率之间的关系。例如,我们可以构建一个VAR模型来分析股票市场、债券市场和货币市场的动态关系。通过VAR模型,我们不仅可以发现各市场之间的影响关系,还可以进行多步预测,为投资决策提供参考。
实战案例:使用Python构建VAR模型分析金融市场
现在我们来进行一个实战案例,我们将使用Python的statsmodels库来构建VAR模型,分析中国A股市场(代表指数:沪深300指数)、债券市场(代表指数:10年期国债利率)和商品市场(代表指数:大宗商品价格)之间的关系。分别以目前可交易的'沪深300ETF','国债ETF','大宗商品ETF'分别代表A股市场、债券市场和商品市场。
以下是一个完整的VAR模型分析框架,包括模型估计、预测和脉冲响应分析:
数据准备和预处理
收集所需的金融时间序列数据,包括需要建模的多个变量。本案例使用qstock获取'沪深300ETF','国债ETF','大宗商品ETF'收盘价数据。
对数据进行清洗、处理缺失值和异常值。这里直接删除缺失值。
数据平稳性检验和差分处理,一般使用股票的对数收益率建模,是平稳序列。
import pandas as pd
import numpy as np
import qstock as qs
import matplotlib.pyplot as plt
#VAR模型和单位根检验
import statsmodels.api as sm
from statsmodels.tsa.api import VAR
from statsmodels.tsa.stattools import adfuller
#协整分析
from statsmodels.tsa.stattools import coint
from statsmodels.tsa.vector_ar.vecm import coint_johansen
#VECM分析
from statsmodels.tsa.vector_ar.vecm import coint_johansen, VECM
#格兰杰因果检验
from statsmodels.tsa.stattools import grangercausalitytests
#过滤警告信息
import warnings
warnings.filterwarnings('ignore')#获取价格数据
codes=['沪深300ETF','国债ETF','大宗商品ETF']
df = qs.get_price(codes,end='20230619').dropna()
# 判断序列是否平稳,如果不平稳需要进行差分
def test_stationarity(timeseries):
dftest = adfuller(timeseries, autolag='AIC')
return dftest[1] < 0.05
# 差分直到序列平稳
def difference_until_stationary(df):
while not df.apply(test_stationarity).all():
df = df.diff().dropna()
return df
#df_diff = difference_until_stationary(df)
#对数收益率,一般是平稳序列
returns=np.log(df/df.shift(1)).dropna()估计VAR模型
确定滞后阶数(lag order selection):使用信息准则(如AIC、BIC)或统计检验(如Ljung-Box检验)来确定VAR模型的合适滞后阶数。使用模型选择方法,如逐步回归或网格搜索,来找到最优的滞后阶数。
使用选定的滞后阶数,通过最小二乘法(OLS)或其他估计方法,估计VAR模型的系数矩阵。计算模型的标准误差、残差和协方差矩阵。
# 建立VAR模型
model = VAR(endog=returns)
lags = range(1, 10) # consider lag lengths from 1 to 10
criterion = 'aic' # or 'bic'
# 使用循环计算每个滞后阶数的AIC或BIC值
criteria = []
for lag in lags:
result = model.fit(lag)
criteria.append(result.info_criteria[criterion])
# 找到AIC或BIC值最小的滞后阶数
best_lag = lags[criteria.index(min(criteria))]
# 估计模型参数
results = model.fit(best_lag)
# 输出VAR回归结果
#print(results.summary())使用Python中的Statsmodels库来进行向量自回归(VAR)的拟合可以得到详细的输出结果,但这些输出结果可能过于详细,不利于阅读。我们可以通过自定义输出函数来让结果更加整洁、美观。
以下是一个简单的例子,使用pandas库来构造一个更易于理解和展示的结果表格:
def show_result(df):
# 创建一个空的DataFrame来保存结果
results_df = pd.DataFrame()
# 对每个自变量进行操作
for var in results.names:
# 获取该自变量的系数和统计值
coeffs = results.params[var].round(3)
pvalues = results.pvalues[var].round(3)
# 将系数和统计值放入DataFrame
for i in range(len(pvalues)):
if pvalues[i]<0.01:
coeffs[i]=str(coeffs[i])+'***'
elif pvalues[i]<0.05:
coeffs[i]=str(coeffs[i])+'**'
elif pvalues[i]<0.1:
coeffs[i]=str(coeffs[i])+'*'
results_df[var + '_coeff'] = coeffs
results_df[var + '_pvalue'] = pvalues
return results_dfshow_result(results)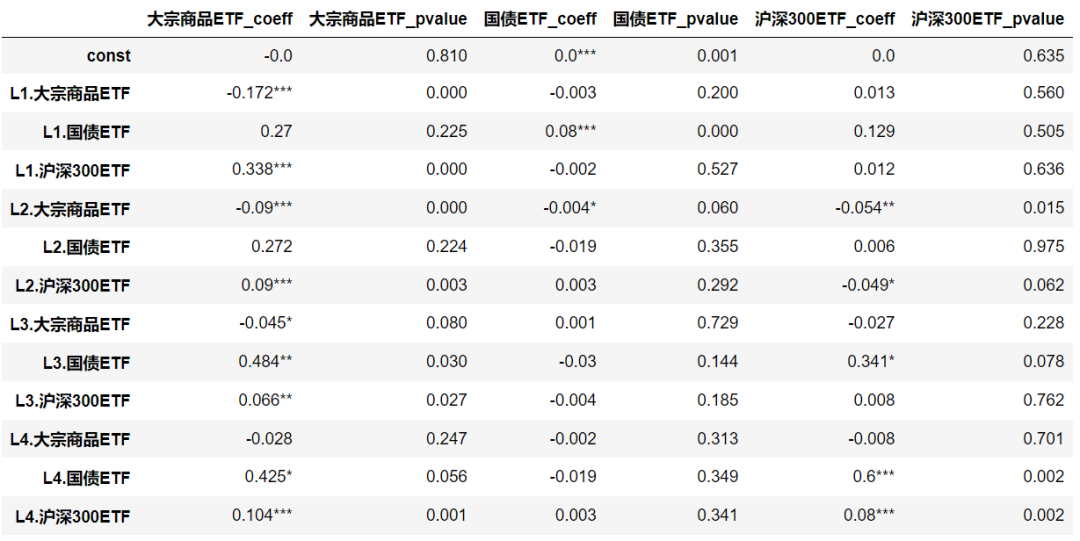
根据提供的VAR模型结果,我们可以观察到各个变量之间的关系和显著性。在滞后阶数为1和2的情况下,我们观察到沪深300ETF对自身的滞后值具有正向影响,但这个影响不显著。大宗商品ETF对自身的滞后值具有显著负向影响。国债ETF对其自身的滞后值的影响不显著。在滞后阶数为3和4的情况下,沪深300ETF和大宗商品ETF对自身的滞后值都具有显著正向影响。国债ETF对自身的滞后值的影响在滞后阶数为3时较为显著。这些结果提供了关于不同变量之间动态关系的见解,有助于我们理解金融市场中各个资产之间的互动和影响。
模型诊断:
检查模型的残差序列是否满足白噪声假设,可以进行残差平稳性检验、正态性检验和自相关性检验。
如果残差序列存在问题,可以尝试使用适当的修正模型,如VECM模型或SVAR模型。
本案例关于模型诊断不详细展开,后面将在VECM模型中介绍。
预测和脉冲响应分析
使用估计的VAR模型进行未来期的预测。可以使用滚动窗口法进行逐步预测,或使用整体样本进行一次性预测。
计算预测值的置信区间,以评估预测的不确定性。
脉冲响应分析:
计算脉冲响应函数(Impulse Response Function,IRF),以衡量一个变量对其他变量的冲击响应。
分析脉冲响应曲线,观察冲击对各变量的影响强度、持续时间和传导效应。
绘制脉冲响应函数图表或计算累积脉冲响应函数(Cumulative Impulse Response Function,CIRF)来进一步分析。
基于脉冲响应分析,可以评估金融市场的冲击传导机制和系统性风险。脉冲响应分析是一种用于研究VAR模型中冲击的传导效应的方法,可以帮助我们理解金融市场中不同变量之间的相互作用和反应。在VAR模型中,脉冲响应函数展示了一个变量对于其他变量的冲击作用下的动态响应。通过分析脉冲响应函数,我们可以得出以下几个方面的评估:
(1)冲击的传导路径:脉冲响应函数展示了冲击如何在不同变量之间传导。通过观察响应函数的图形,我们可以确定冲击从一个变量到另一个变量的传导路径。这对于理解金融市场中冲击的扩散和传播机制非常重要。
(2)响应的强度和持续时间:脉冲响应函数还显示了响应的强度和持续时间。通过分析响应函数的幅度和持续时间,我们可以评估不同变量之间的冲击传导的强度和持久性。这有助于确定系统中哪些变量对冲击更敏感,以及冲击的影响会持续多久。
(3)系统性风险的评估:脉冲响应分析还可以帮助评估金融市场的系统性风险。通过分析响应函数的图形,我们可以确定系统中的关键变量,它们对冲击的响应程度是否高于其他变量。这有助于识别系统中的脆弱性和潜在的风险传导路径,从而更好地评估系统性风险。
关于图形的解读:
坐标轴解释:脉冲响应图通常具有两个坐标轴,一个表示时间或滞后阶数,另一个表示变量。时间轴显示了观察的时间段或滞后的数量,而变量轴显示了参与模型的变量。
线条解释:脉冲响应图上的每条线表示一个变量对于其他变量的冲击传导效应。每个变量都有一条线,通过线的形状和趋势,可以分析冲击的传导路径和强度。
线条的方向:线条的方向显示了冲击的传导方向。如果线条从一个变量向另一个变量延伸,表示冲击从前者传导到后者。通过观察线条的延伸方向,可以确定冲击的传导路径。
线条的幅度:线条的幅度表示了冲击的强度。较大的幅度表示较强的冲击效应,而较小的幅度表示较弱的冲击效应。通过比较不同线条的幅度,可以评估不同变量之间冲击传导的强度。
线条的形状和趋势:线条的形状和趋势显示了冲击的持续时间和衰减程度。如果线条在初始冲击后逐渐衰减,并最终趋于稳定,表示冲击效应是短暂的。如果线条在初始冲击后保持较高的幅度,并逐渐趋于零,表示冲击效应是持久的。
# 预测
forecast = results.forecast(returns.values[-best_lag:], steps=10) # 预测未来10个时间步长
# 脉冲响应分析
irf = results.irf(10) # 计算脉冲响应函数
irf.plot(orth=True) # 绘制脉冲响应函数图表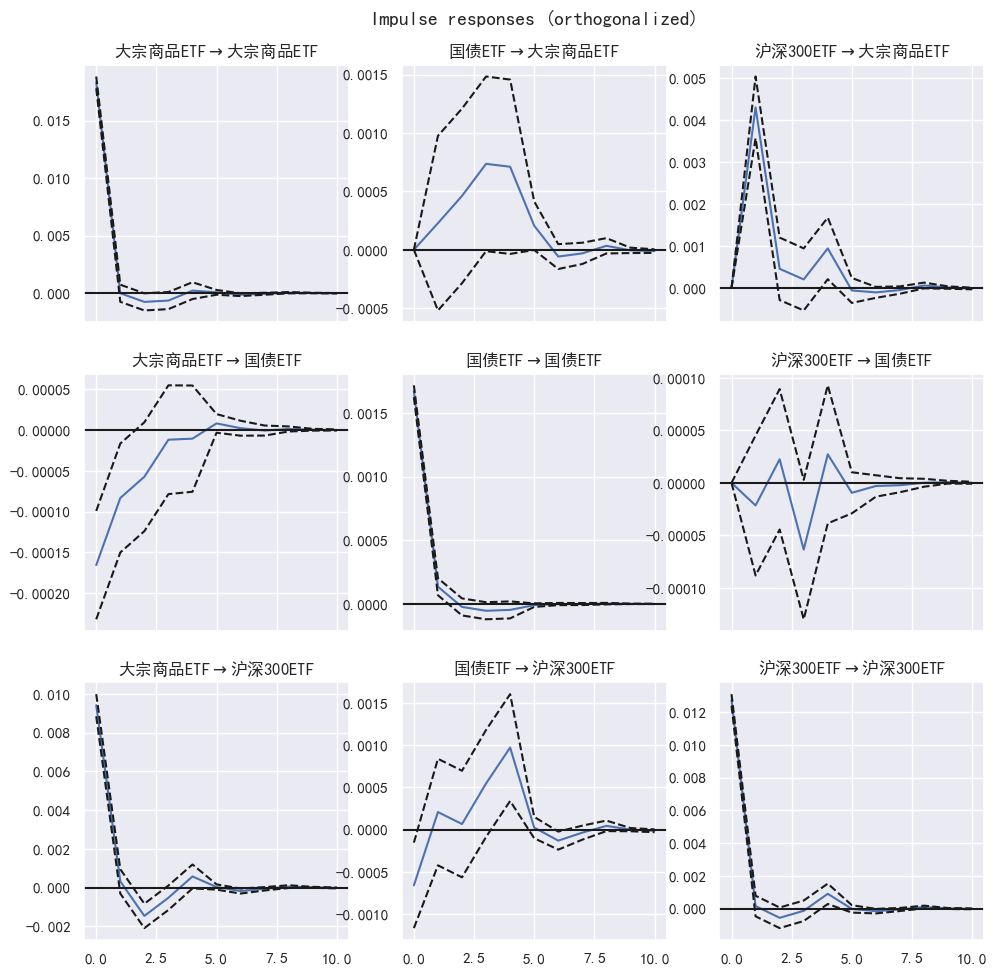
二、协整分析
在时间序列分析中,我们常常遇到这样一种情况:单独看,一个时间序列可能是非平稳的,但是将两个或者多个非平稳时间序列进行某种线性组合后,得到的新序列却是平稳的。如果存在这样的线性组合,我们就说这些序列之间存在协整关系。从数学语言来理解,设有n个非平稳时间序列X1, X2, …, Xn,如果存在一个向量β=(β1, β2, …, βn),使得序列Z=β1X1+β2X2+…+βnXn是平稳的,那么我们就说这n个序列存在协整关系。
让我们来考虑一个典型的金融市场案例:两个股票的价格序列。我们可能发现,虽然两个股票的价格序列本身都是非平稳的,但是它们的价格差却可能是平稳的,这就意味着这两个股票的价格存在协整关系。
statsmodels库的coint函数基于Engle-Granger两步法进行协整检验。这是一种常用的协整检验方法,但并不是唯一的方法。其他的协整检验方法,比如Johansen协整检验,可能会得到不同的结果。不同的协整检验方法可能会对样本数据的特性、数据的处理方法、检验的假设等有不同的要求,因此可能会得到不同的检验结果。Johansen协整检验和Engle-Granger协整检验的原假设是不同的。Engle-Granger协整检验的原假设是存在协整关系,而Johansen协整检验的原假设是不存在协整关系。因此,在解读检验结果时需要注意这个差异。
下面分别使用statsmodels库的coint和Johansen构建协整检验函数,说明如何对两个或多个金融时间序列检验协整性。
#基于coint的协整检验
def check_coint(df):
'''df是包含两个序列的dataframe'''
s1=df.iloc[:,0]
s2=df.iloc[:,1]
coint_t, p_value, crit_value = coint(s1,s2)
if p_value < 0.05:
return True
else:
return False
#基于Johansen的协整检验
def check_johansen(df):
'''df是包含两个序列的dataframe'''
# 进行Johansen协整检验
johansen_test = coint_johansen(df.values, det_order=0, k_ar_diff=1)
# 判断是否存在协整关系
if johansen_test.lr1[0] > johansen_test.cvt[0, 1]: # 5%显著性水平
return True
else:
return Falsestatsmodels库的coint函数返回三个值:协整检验的t统计量,对应的p值,以及临界值。判断是否存在协整关系主要依据p值的大小。如果p值小于0.05,就认为存在协整关系,否则就认为不存在协整关系。
Johansen协整检验的结果包括两个统计量:lr1和lr2,以及对应的临界值cvt和cvm。lr1和cvt是用于检验r个协整向量存在的假设,即检验有多少个协整关系存在。lr2和cvm是用于检验有增加一个协整向量的假设。cvt和cvm都是一个2维数组,每一行对应一个统计量,每一列对应一个显著性水平(90%,95%,99%)。也就是说,cvt[0,1]表示在5%的显著性水平下,检验有一个协整关系存在的临界值。注意:johansen_test.lr1[0]和johansen_test.cvt[0, 1]是检验有一个协整关系存在的统计量和临界值。如果你的时间序列中有超过两个变量,你可能需要检查johansen_test.lr1[1]、johansen_test.lr1[2]等与对应的临界值johansen_test.cvt[1, 1]、johansen_test.cvt[2, 1]等的关系,以判断是否存在更多的协整关系。另外,Johansen协整检验的k_ar_diff参数是进行检验时使用的滞后阶数。这个参数的选择可能会影响检验的结果。一般来说,可以通过信息准则(如赤池信息准则)来选择最优的滞后阶数。但是,在实际应用中,可能需要根据具体的数据特性和研究问题来进行选择。
下面基于上述函数对A股市场上常见的几个指数进行协整性检验分析。代码如下:
#获取指数最近200个周价格数据
codes=['sh','sz','sz50','cyb','hs300','zxb']
data=qs.get_price(codes,end='20230620',freq='w').dropna()[-200:]
#价格走势对比
fig,ax=plt.subplots(3,2,figsize=(12,10))
k=0
for i in range(3):
for j in range(2):
data.iloc[:,k].plot(ax=ax[i,j]);
ax[i,j].set_title(data.columns[k]);
k+=1
plt.tight_layout()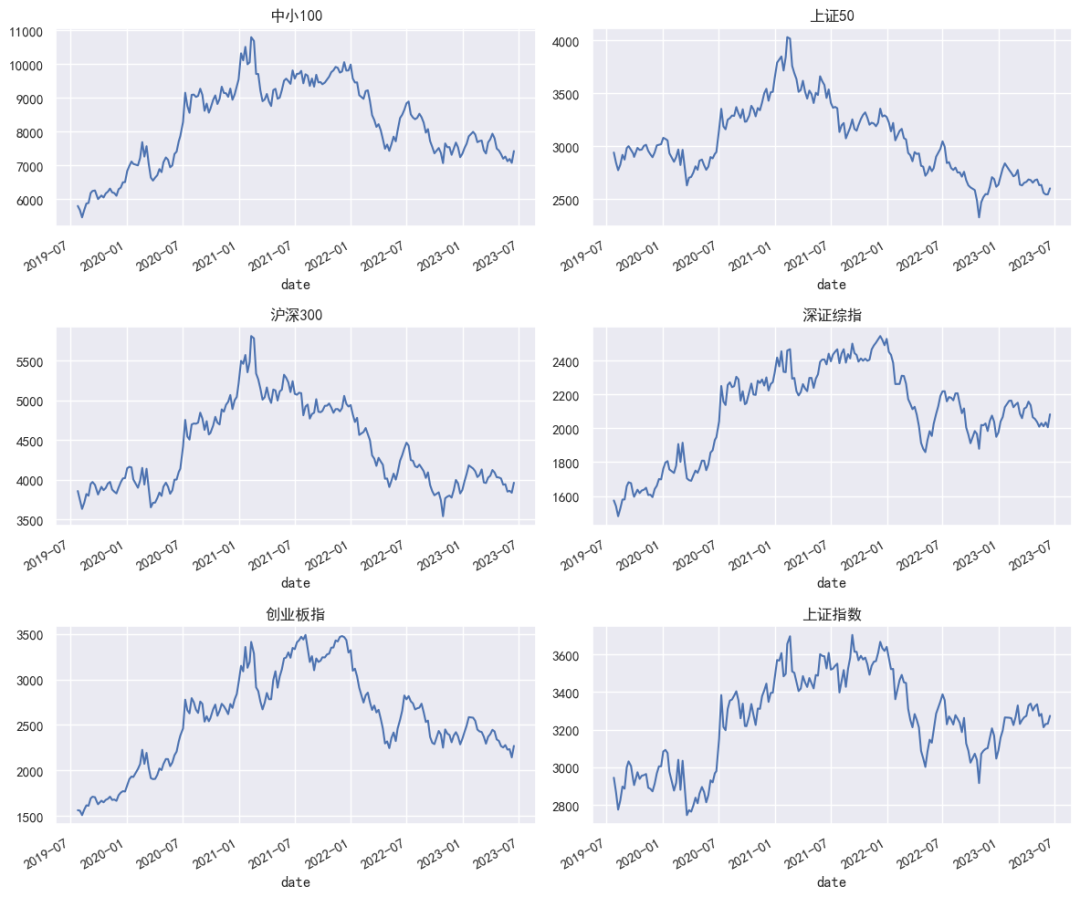
从上图可以看出,各大指数价格走势相似度较高,两两指数之间可能存在一定的协整关系。下面分别基于coint和Johansen函数进行协整检验。
import itertools
ss=[list(i) for i in list(itertools.combinations(data.columns,2))]
for i in range(len(ss)):
if check_coint(data[ss[i]]):
print(f'{ss[i]}存在协整关系')['深证综指', '上证指数']存在协整关系
['创业板指', '上证指数']存在协整关系for i in range(len(ss)):
if check_johansen(data[ss[i]]):
print(f'{ss[i]}存在协整关系')['深证综指', '创业板指']存在协整关系
['深证综指', '上证指数']存在协整关系
['创业板指', '上证指数']存在协整关系上述结果显示,基于coint和Johansen函数进行协整检验存在一些差异,coint检验得出深证综指和上证指数存在协整关系、创业板指和上证指数存在协整关系,而Johansen检验还得出深证综指和创业板指也存在协整关系。值得注意的是,协整检验的结果可能会受到样本的影响,例如样本数量的多少、样本的选择等都可能会影响到检验的结果。因此,除了协整检验,还需要结合实际情况和其他方法来确定是否存在协整关系。
此外,相关性和协整性是两个不同的概念。它们虽然在某些情况下可能会有所关联,但在许多情况下它们并不一定会同时存在。即使两个变量具有高度的相关性,它们也可能不具有协整性,因为它们可能并没有长期的稳定关系。反之,即使两个变量在短期内的相关性不高,只要它们之间存在长期的稳定关系,它们就可能是协整的。在实际研究中,我们需要根据研究的目的和问题的性质,选择适当的方法来研究变量之间的关系。
协整分析在金融市场上有着广泛的应用。以下是一些主要的应用场景:
配对交易(Pairs Trading):这是协整分析在金融领域中最广泛的应用之一。配对交易的策略是找出两只协整的股票,当它们的价格差距超过历史平均水平时,就会进行交易,购买价格较低的股票,同时卖空价格较高的股票,等待价格回归到均衡状态来获取利润。
风险管理:在多元投资组合管理中,协整分析可以帮助识别各种资产之间的长期稳定关系,这对于风险管理和投资组合优化非常重要。通过找出协整的资产,投资者可以构建出稳定的投资组合,降低风险。
预测和决策:由于协整关系反映了一种长期的均衡状态,因此在经济决策和预测中,协整分析也非常有用。比如,经济政策制定者可以通过分析宏观经济指标的协整关系来预测未来的经济趋势,为政策决策提供依据。
套利策略:在金融市场上,协整关系也常常被用来寻找套利机会。比如,如果两个不同国家的债券市场存在协整关系,那么当两个市场的价格出现偏离时,交易员就可以在一个市场购买,同时在另一个市场卖空,等待价格恢复到均衡状态时再平仓,从而获取无风险收益。
这些只是协整分析在金融市场上的一部分应用,实际上,只要是涉及多个时间序列的分析问题,协整分析都可能发挥重要作用。
三、向量误差修正模型(VECM)
向量误差修正模型(Vector Error Correction Model, VECM)是多元时间序列分析的一个重要工具,用于处理存在协整关系的变量间的长期均衡关系以及短期调整动态。在金融领域,例如股票市场分析、经济预测、风险管理等,VECM的应用十分广泛。
VECM是VAR模型的扩展,它在VAR的基础上添加了一个长期均衡误差项。这是因为实际中许多经济和金融序列间不仅存在短期内的因果关系,还存在长期的均衡关系。当这种均衡关系被短期冲击打破后,系统会通过调整各变量使得整个系统重新回归均衡状态,VECM就是在描述这个过程。
考虑一个二元的VECM,形式如下:
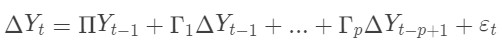
其中, 是一个 k 维的向量,Π是一个 kk 矩阵,表示长期的均衡关系, 是一个 kk 矩阵,表示短期的动态调整, 是误差项。
我们以股票市场为例进行说明。假设我们关注两只股票A和B,希望通过对它们的历史价格数据建立VECM模型,以此来分析两只股票之间的长短期关系并进行预测。
首先,我们需要收集两只股票的历史价格数据,然后检查这两个价格序列是否存在协整关系,如果存在,我们就可以利用VECM模型进行分析。设股票A和B的价格序列分别为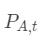 和
和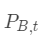 ,它们的VECM模型可以表示为:
,它们的VECM模型可以表示为:
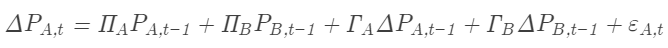
{B,t} = Π'AP{A,t-1} + Π'BP{B,t-1} + Γ'AΔP{A,t-1} + Γ'BΔP{B,t-1} + ε_{B,t}ΔPB,t=ΠA′PA,t−1+ΠB′PB,t−1+ΓA′ΔPA,t−1+ΓB′ΔPB,t−1+εB,t
通过估计这个模型,我们可以获取到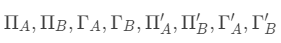 这些参数,以及误差项。通过这些参数,我们可以了解到股票A和股票B之间的长短期关系,并进行预测。
这些参数,以及误差项。通过这些参数,我们可以了解到股票A和股票B之间的长短期关系,并进行预测。
在Python中,我们可以使用statsmodels库中的VECM类来进行VECM模型的建立。以下是一个简单的代码示例:
check_johansen(data)True# 1. 获取数据与预处理
data = qs.get_price(['sh','sz'],freq='w').dropna()[-200:]
# 2. 检查协整关系
johansen_test = coint_johansen(data, det_order=0, k_ar_diff=1)
print('Eigenvalues: ', johansen_test.lr1)
print('Critical values: ', johansen_test.cvt)
# 3. 建立VECM模型
vecm = VECM(data, coint_rank=1)
vecm_fit = vecm.fit()
# 4. 输出模型参数和统计信息
print(vecm_fit.summary())
# 5. 预测
pred = vecm_fit.predict(steps=5)
print('Predictions: \n', pred)
#可视化
data.plot(subplots=True,figsize=(15,7));Eigenvalues: [17.2132184 6.26766465]
Critical values: [[13.4294 15.4943 19.9349]
[ 2.7055 3.8415 6.6349]]
Det. terms outside the coint. relation & lagged endog. parameters for equation 深证综指
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
L1.深证综指 -0.0688 0.166 -0.413 0.679 -0.395 0.258
L1.上证指数 -0.0011 0.135 -0.008 0.994 -0.266 0.264
Det. terms outside the coint. relation & lagged endog. parameters for equation 上证指数
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
L1.深证综指 -0.1088 0.206 -0.529 0.597 -0.512 0.295
L1.上证指数 -0.0143 0.167 -0.086 0.932 -0.342 0.313
Loading coefficients (alpha) for equation 深证综指
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ec1 -0.0491 0.031 -1.580 0.114 -0.110 0.012
Loading coefficients (alpha) for equation 上证指数
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ec1 -0.0207 0.038 -0.539 0.590 -0.096 0.055
Cointegration relations for loading-coefficients-column 1
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
beta.1 1.0000 0 0 0.000 1.000 1.000
beta.2 -0.6588 0.015 -45.233 0.000 -0.687 -0.630
==============================================================================
Predictions:
[[2053.98324907 3207.10865867]
[2056.72407462 3208.09498749]
[2059.32192557 3208.95977373]
[2061.83015766 3209.79980141]
[2064.2485943 3210.60939999]]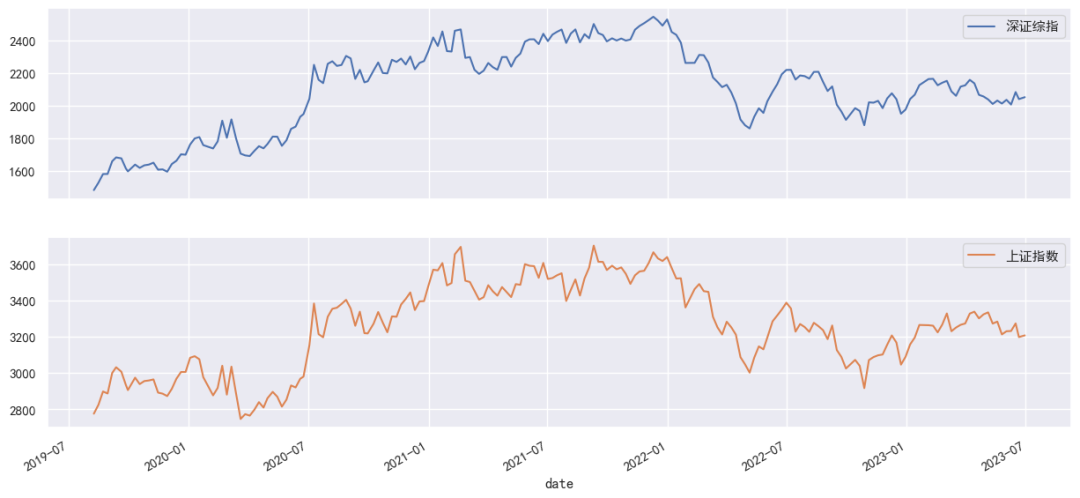
首先,我们查看特征值(Eigenvalues),有两个特征值 17.30929776 和 6.56626887。这些特征值越大,说明协整关系越强。
其次,我们查看临界值(Critical values) [[13.4294 15.4943 19.9349] [2.7055 3.8415 6.6349]]。Johansen检验提供了多个显著性水平(例如,10%,5%,1%)的临界值。特征值应大于对应的临界值才能认为存在协整关系。在这里,对于第一个特征值,它大于5%和1%的临界值,所以我们可以认为存在一个协整关系;而对于第二个特征值,它小于10%的临界值,所以我们不能认为存在第二个协整关系。
再次是参数的估计结果。coef列是各个参数的估计值,P>|z|列是参数估计的p值,[0.025, 0.975]列是参数估计的95%置信区间。在这里,无论是上证指数还是深证综指,滞后1期的上证指数和深证综指对现期的影响都不显著(p值大于0.05)。ec1的值表示了上证指数和深证综指之间的长期均衡关系,即协整关系。coef列是参数的估计值,P>|z|列是参数估计的p值,[0.025, 0.975]列是参数估计的95%置信区间。从结果来看,对于上证指数,协整关系不显著(p值大于0.05);对于深证综指,协整关系显著(p值小于0.10)。
最后,"Cointegration relations for loading-coefficients-column 1"部分表示的是协整向量,其中beta.1为1,beta.2为-1.5178,表示的是上证指数和深证综指的协整关系可以由上证指数 - 1.5178 * 深证综指 = 0这个方程来表示。"Predictions"部分给出了上证指数和深证综指的未来5个值的预测。
总的来说,上证指数和深证综指之间存在一个显著的协整关系,且这个协整关系主要体现在深证综指上。
四、格兰杰因果检验
格兰杰因果检验(Granger Causality Test)是一种用于检验一个时间序列是否能够预测另一个时间序列的统计假设检验方法。如果我们发现序列X可以帮助预测序列Y,那么我们就可以说“X对Y具有格兰杰因果关系”。
需要注意的是,格兰杰因果关系并不是我们通常所说的因果关系。在格兰杰的语境中,“因果”并不意味着X直接导致了Y的变化,而仅仅是X可以预测Y。这是一个预测的概念,而不是传统意义上的因果关系。因此,格兰杰因果检验仅仅是为了检验预测关系,而不能确定实际的因果关系。
(一)基本原理
假设我们有两个时间序列X和Y,我们想要检验X是否对Y具有格兰杰因果关系。我们可以建立以下两个模型:
一个只包含Y的自回归模型:
Y(t) = α0 + α1 * Y(t-1) + α2 * Y(t-2) + … + αn * Y(t-n) + ε(t)
一个包含Y和X的向量自回归模型:
Y(t) = β0 + β1 * Y(t-1) + β2 * Y(t-2) + … + βn * Y(t-n) + γ1 * X(t-1) + γ2 * X(t-2) + … + γm * X(t-m) + u(t)
如果第二个模型的预测效果显著优于第一个模型,那么我们就可以认为X对Y具有格兰杰因果关系。
(二)应用领域及局限性
格兰杰因果检验在经济金融领域有广泛的应用。一些常见的应用包括:
宏观经济研究。例如,检验通货膨胀率和失业率之间的关系,或者货币供应量和股票市场指数之间的关系。
金融市场研究。例如,检验股票市场和债券市场之间的相互影响,或者金融市场的各种因素(例如,金融政策,投资者情绪等)对金融市场的影响。
投资决策。例如,检验公司的财务报告数据和公司股票价格之间的关系,以帮助投资者做出更好的投资决策。
然而,格兰杰因果检验也有其局限性:
格兰杰因果关系并非真正的因果关系。格兰杰因果关系只是表示两个变量之间存在一种预测关系,而并不能说明这两个变量之间存在因果关系。例如,如果我们发现市场的交易量增加可以预测股票价格的上涨,但这并不能证明交易量的增加就是导致股票价格上涨的原因。
可能存在滞后效应。格兰杰因果检验通常假设变量之间的关系在滞后期间内就会显现,但实际上可能存在更长的滞后效应。
可能存在遗漏变量问题。格兰杰因果检验通常是基于两个变量进行的,如果存在其他未考虑的变量也对被预测变量有影响,那么检验结果可能会受到影响。
预设的滞后阶数可能会影响检验结果。在进行格兰杰因果检验时,需要预设滞后阶数,这个滞后阶数的设定可能会影响检验结果。一般来说,滞后阶数的设定需要根据具体的经济理论和实证数据来进行。
因此,当我们使用格兰杰因果检验时,需要谨慎解释检验结果,并结合实际的经济理论和其他统计检验方法来进行分析。
(三)格兰杰因果检验的Python实现
在Python中,我们可以使用statsmodels库中的grangercausalitytests函数进行格兰杰因果检验。下面是一个示例:
# 模拟两个存在格兰杰因果关系的时间序列
# 设定随机数生成器的种子,以保证结果的可重复性
np.random.seed(123)
# 生成第一个序列
X = np.random.normal(size=1000)
# 生成第二个序列,该序列的值依赖于X序列前一期的值
Y = np.roll(X, shift=-1) + np.random.normal(size=1000)
# 将两个时间序列合并成一个二维数组
data = np.column_stack([X, Y])
# 进行格兰杰因果检验,最大滞后阶数设为3
results = grangercausalitytests(data, maxlag=2)Granger Causality
number of lags (no zero) 1
ssr based F test: F=1237.5676, p=0.0000 , df_denom=996, df_num=1
ssr based chi2 test: chi2=1241.2952, p=0.0000 , df=1
likelihood ratio test: chi2=806.8005, p=0.0000 , df=1
parameter F test: F=1237.5676, p=0.0000 , df_denom=996, df_num=1
Granger Causality
number of lags (no zero) 2
ssr based F test: F=618.6395, p=0.0000 , df_denom=993, df_num=2
ssr based chi2 test: chi2=1243.5090, p=0.0000 , df=2
likelihood ratio test: chi2=807.5330, p=0.0000 , df=2
parameter F test: F=618.6395, p=0.0000 , df_denom=993, df_num=2上述代码生成了两个序列X和Y,其中Y的值取决于X的前一期值和一个随机噪音。我们期待格兰杰因果检验能够检测到这种关系。对于每一个滞后阶数,我们都有一组检验结果,包括四种不同类型的检验统计量(F test, chi-square test, likelihood ratio test和parameter F test),以及对应的p值。如果p值小于设定的显著性水平(比如0.05),我们就可以拒绝原假设,认为存在Granger因果关系。在这个例子中,滞后阶数为1和2时,所有检验的p值都约等于0,所以我们拒绝原假设,认为存在Granger因果关系。
然而,注意到,这些检验结果可能受到滞后阶数的设定影响。这个滞后阶数的设定需要根据具体的经济理论和实证数据来进行。因此,在使用Granger因果检验的时候,我们需要谨慎处理并解读结果。
下面我们将模拟两个白噪声时间序列,因为我们知道白噪声时间序列的数据是随机产生的,因此一个白噪声时间序列不可能对另一个白噪声时间序列有任何预测力,即它们之间不存在格兰杰因果关系。
# 模拟两个白噪声时间序列
np.random.seed(123)
X = np.random.normal(size=10000)
Y = np.random.normal(size=10000)
# 将两个时间序列合并成一个二维数组
data = np.vstack([X, Y]).T
# 进行格兰杰因果检验,最大滞后阶数设为2
results = grangercausalitytests(data, maxlag=2)Granger Causality
number of lags (no zero) 1
ssr based F test: F=0.0008 , p=0.9768 , df_denom=9996, df_num=1
ssr based chi2 test: chi2=0.0008 , p=0.9768 , df=1
likelihood ratio test: chi2=0.0008 , p=0.9768 , df=1
parameter F test: F=0.0008 , p=0.9768 , df_denom=9996, df_num=1
Granger Causality
number of lags (no zero) 2
ssr based F test: F=0.0488 , p=0.9524 , df_denom=9993, df_num=2
ssr based chi2 test: chi2=0.0976 , p=0.9524 , df=2
likelihood ratio test: chi2=0.0976 , p=0.9524 , df=2
parameter F test: F=0.0488 , p=0.9524 , df_denom=9993, df_num=2这个结果表明,无论是滞后阶数为1还是2,对于每种检验(包括F检验,χ^2检验,和似然比检验),p值都远大于常用的显著性水平0.05,因此我们无法拒绝零假设,也就是说,我们没有足够的证据来认为序列X对序列Y有任何的预测作用,即不存在格兰杰因果关系。这与我们模拟的两个白噪声序列是独立的,不存在任何因果关系的事实是一致的。
(四)实战应用:上证指数与标准普尔格兰杰因果分析
对于投资者而言,理解并预测这两个指数之间的动态关系是极为关键的,因为这可以帮助他们更好地制定投资策略,避免风险,获取利润。然而,要精准地判断这两个指数之间的关系,并非易事。虽然直观上我们可以观察到它们之间的某些联系,但要准确并定量地描述这种联系,就需要使用更为科学的统计方法。
下面使用格兰杰因果检验来考察上证指数与深证综指之间的因果关系,通过数据挖掘上证指数与标准普尔500指数之间的动态互动关系,为投资者提供有价值的策略性建议。具体代码如下:
#获取上证指数与标准普尔500指数价格数据
data=qs.get_price(['sh','sz']).dropna()
returns=data.pct_change().dropna()
# 检验时间序列的平稳性
for column in data.columns:
result = adfuller(data[column])
if result[1] > 0.05:
print(f"{column} 非平稳,需要进行差分")
else:
print(f"{column} 平稳")
# 选择滞后阶数
model = VAR(returns)
lag_order = model.select_order(maxlags=10)
print(f"最大滞后阶数:{lag_order.selected_orders['aic']}")
# 进行格兰杰因果检验
maxlag = lag_order.selected_orders['aic']
test_result = grangercausalitytests(data, maxlag=maxlag)
#输出结果如下:深证综指 非平稳,需要进行差分
上证指数 非平稳,需要进行差分
最大滞后阶数:10
Granger Causality
number of lags (no zero) 1
ssr based F test: F=0.0000 , p=0.9995 , df_denom=6580, df_num=1
ssr based chi2 test: chi2=0.0000 , p=0.9995 , df=1
likelihood ratio test: chi2=0.0000 , p=0.9995 , df=1
parameter F test: F=0.0000 , p=0.9995 , df_denom=6580, df_num=1
Granger Causality
number of lags (no zero) 2
ssr based F test: F=3.1125 , p=0.0446 , df_denom=6577, df_num=2
ssr based chi2 test: chi2=6.2298 , p=0.0444 , df=2
likelihood ratio test: chi2=6.2268 , p=0.0444 , df=2
parameter F test: F=3.1125 , p=0.0446 , df_denom=6577, df_num=2
Granger Causality
number of lags (no zero) 3
ssr based F test: F=2.5114 , p=0.0568 , df_denom=6574, df_num=3
ssr based chi2 test: chi2=7.5422 , p=0.0565 , df=3
likelihood ratio test: chi2=7.5379 , p=0.0566 , df=3
parameter F test: F=2.5114 , p=0.0568 , df_denom=6574, df_num=3
Granger Causality
number of lags (no zero) 4
ssr based F test: F=2.0192 , p=0.0889 , df_denom=6571, df_num=4
ssr based chi2 test: chi2=8.0877 , p=0.0884 , df=4
likelihood ratio test: chi2=8.0828 , p=0.0886 , df=4
parameter F test: F=2.0192 , p=0.0889 , df_denom=6571, df_num=4
Granger Causality
number of lags (no zero) 5
ssr based F test: F=2.8230 , p=0.0150 , df_denom=6568, df_num=5
ssr based chi2 test: chi2=14.1388 , p=0.0148 , df=5
likelihood ratio test: chi2=14.1236 , p=0.0148 , df=5
parameter F test: F=2.8230 , p=0.0150 , df_denom=6568, df_num=5
Granger Causality
number of lags (no zero) 6
ssr based F test: F=3.5414 , p=0.0017 , df_denom=6565, df_num=6
ssr based chi2 test: chi2=21.2906 , p=0.0016 , df=6
likelihood ratio test: chi2=21.2563 , p=0.0016 , df=6
parameter F test: F=3.5414 , p=0.0017 , df_denom=6565, df_num=6
Granger Causality
number of lags (no zero) 7
ssr based F test: F=3.3883 , p=0.0013 , df_denom=6562, df_num=7
ssr based chi2 test: chi2=23.7720 , p=0.0012 , df=7
likelihood ratio test: chi2=23.7292 , p=0.0013 , df=7
parameter F test: F=3.3883 , p=0.0013 , df_denom=6562, df_num=7
Granger Causality
number of lags (no zero) 8
ssr based F test: F=3.3646 , p=0.0007 , df_denom=6559, df_num=8
ssr based chi2 test: chi2=26.9869 , p=0.0007 , df=8
likelihood ratio test: chi2=26.9317 , p=0.0007 , df=8
parameter F test: F=3.3646 , p=0.0007 , df_denom=6559, df_num=8
Granger Causality
number of lags (no zero) 9
ssr based F test: F=3.4286 , p=0.0003 , df_denom=6556, df_num=9
ssr based chi2 test: chi2=30.9465 , p=0.0003 , df=9
likelihood ratio test: chi2=30.8739 , p=0.0003 , df=9
parameter F test: F=3.4286 , p=0.0003 , df_denom=6556, df_num=9
Granger Causality
number of lags (no zero) 10
ssr based F test: F=3.1960 , p=0.0004 , df_denom=6553, df_num=10
ssr based chi2 test: chi2=32.0623 , p=0.0004 , df=10
likelihood ratio test: chi2=31.9843 , p=0.0004 , df=10
parameter F test: F=3.1960 , p=0.0004 , df_denom=6553, df_num=10深证综指的收益率数据在某些滞后阶数下可以显著地预测上证指数的收益率。滞后阶数为1时,F-test,chi2-test,LR-test和Param F-test的p值都大于0.05,这意味着在滞后1阶时,深证综指的收益率数据并不能显著地预测上证指数的收益率。当滞后阶数增加到2时,所有测试的p值降低至0.0446或0.0444,这意味着在这个滞后阶数下,深证综指的收益率对上证指数的收益率具有显著的预测力。随着滞后阶数的继续增加,一些测试的p值在某些阶数(如5阶,6阶,7阶,8阶,9阶和10阶)下变得非常小(小于0.05或更严格的0.01),这意味着在这些滞后阶数下,深证综指的收益率对上证指数的收益率具有显著的预测力。
对于滞后阶数,我们选择了最大滞后阶数为10。实际上,在金融时间序列分析中,选择滞后阶数需要考虑到实际意义和模型的复杂度。在这个例子中,我们可以理解为过去10个交易日内的标普500指数变动对当日的上证指数有影响。
具体的因果关系可以通过估计向量自回归(VAR)模型来获取。我们可以通过下面的代码来得到两个指数之间的关系:
model_fitted = model.fit(maxlags=maxlag)
model_fitted.summary()
#输出结果如下:Summary of Regression Results
==================================
Model: VAR
Method: OLS
Date: Fri, 30, Jun, 2023
Time: 15:21:42
--------------------------------------------------------------------
No. of Equations: 2.00000 BIC: -18.0274
Nobs: 6573.00 HQIC: -18.0558
Log likelihood: 40778.3 FPE: 1.41889e-08
AIC: -18.0708 Det(Omega_mle): 1.40986e-08
--------------------------------------------------------------------
Results for equation 深证综指
===========================================================================
coefficient std. error t-stat prob
---------------------------------------------------------------------------
const 0.000486 0.000218 2.232 0.026
L1.深证综指 0.099381 0.028734 3.459 0.001
L1.上证指数 -0.059418 0.032168 -1.847 0.065
L2.深证综指 -0.033398 0.028912 -1.155 0.248
L2.上证指数 0.029700 0.032261 0.921 0.357
L3.深证综指 0.024371 0.028898 0.843 0.399
L3.上证指数 0.028606 0.032243 0.887 0.375
L4.深证综指 -0.040579 0.028906 -1.404 0.160
L4.上证指数 0.087737 0.032271 2.719 0.007
L5.深证综指 -0.076890 0.028906 -2.660 0.008
L5.上证指数 0.104802 0.032256 3.249 0.001
L6.深证综指 -0.012323 0.028871 -0.427 0.670
L6.上证指数 -0.015281 0.032271 -0.474 0.636
L7.深证综指 0.065728 0.028824 2.280 0.023
L7.上证指数 -0.048243 0.032239 -1.496 0.135
L8.深证综指 0.012918 0.028775 0.449 0.653
L8.上证指数 -0.020943 0.032188 -0.651 0.515
L9.深证综指 0.020054 0.028774 0.697 0.486
L9.上证指数 -0.051043 0.032185 -1.586 0.113
L10.深证综指 0.077663 0.028495 2.725 0.006
L10.上证指数 -0.087927 0.031939 -2.753 0.006
===========================================================================
Results for equation 上证指数
===========================================================================
coefficient std. error t-stat prob
---------------------------------------------------------------------------
const 0.000355 0.000195 1.824 0.068
L1.深证综指 -0.023355 0.025673 -0.910 0.363
L1.上证指数 0.037905 0.028740 1.319 0.187
L2.深证综指 -0.038306 0.025831 -1.483 0.138
L2.上证指数 0.028714 0.028824 0.996 0.319
L3.深证综指 -0.035955 0.025819 -1.393 0.164
L3.上证指数 0.077043 0.028808 2.674 0.007
L4.深证综指 0.011588 0.025826 0.449 0.654
L4.上证指数 0.029483 0.028832 1.023 0.307
L5.深证综指 -0.000172 0.025826 -0.007 0.995
L5.上证指数 0.001930 0.028819 0.067 0.947
L6.深证综指 0.004504 0.025795 0.175 0.861
L6.上证指数 -0.048627 0.028833 -1.687 0.092
L7.深证综指 0.024992 0.025753 0.970 0.332
L7.上证指数 -0.012564 0.028804 -0.436 0.663
L8.深证综指 0.033263 0.025709 1.294 0.196
L8.上证指数 -0.045051 0.028758 -1.567 0.117
L9.深证综指 -0.021479 0.025708 -0.836 0.403
L9.上证指数 0.007156 0.028756 0.249 0.803
L10.深证综指 0.058054 0.025459 2.280 0.023
L10.上证指数 -0.056157 0.028536 -1.968 0.049
===========================================================================
Correlation matrix of residuals
深证综指 上证指数
深证综指 1.000000 0.902981
上证指数 0.902981 1.000000这些结果显示了深证综指和上证指数之间在不同滞后阶段的相互影响。例如,L10.深证综指对两个方程都有显著的正向影响,而L10.上证指数对两个方程都有显著的负向影响,这可能意味着在10期的滞后下,深证综指的变化会正向影响两个市场,而上证指数的变化会负向影响两个市场。这可能与市场的具体动态和投资者的反应有关。
五、多元时间序列未来展望及学习路径
(一)未来展望
多元时间序列模型在经济学、金融学、社会学等领域具有广泛应用,特别是在金融市场分析和预测中,它的重要性不言而喻。随着大数据和计算能力的快速发展,这一领域的研究正面临着革命性的变化。
(1)对传统模型进行扩展和深化是未来多元时间序列研究的一大方向。其中,向量自回归模型(VAR)是多元时间序列分析的基础,但在现实应用中,存在许多限制,如参数数量过多,需要大量样本支持,可能导致过拟合等问题。因此,对VAR模型进行改进和优化,减少参数数量,提高模型鲁棒性是一大趋势。比如,可以引入贝叶斯方法进行参数估计,或者考虑模型参数的稀疏性,进行变量选择等。
(2)引入非线性和异质性是另一个重要的研究方向。在实际应用中,经济变量往往存在非线性和异质性,而传统的线性模型往往不能很好的捕捉这些特性。因此,如何将非线性和异质性结构融入多元时间序列模型是未来研究的重要任务。例如,可以构建非线性向量自回归模型,考虑异质性协整模型等。
(3)多元时间序列的大数据分析和机器学习应用正在蓬勃发展。随着大数据和计算能力的发展,传统的模型和方法已经无法满足现实需求。如何处理高维度的时间序列数据,如何利用机器学习方法进行预测和分析,如何评估预测结果的准确性和稳定性等问题,都是未来研究的重要课题。例如,可以考虑使用深度学习模型如递归神经网络(RNN)或长短期记忆网络(LSTM)进行预测,或者使用支持向量机(SVM)、随机森林、梯度提升等方法进行特征提取和分类。
(4)多元时间序列的网络分析和复杂性分析是最新的研究前沿。金融市场是一个复杂的网络系统,各个变量之间存在着复杂的相互作用和反馈机制。如何从网络的角度研究多元时间序列,如何度量和分析复杂性,如何利用这些信息进行风险管理和决策支持,是未来的一个重要研究领域。例如,可以构建金融市场的网络模型,考虑节点的连通性和稳定性,或者研究网络的复杂性,如分形维度、混沌度等。
总的来说,未来的多元时间序列模型研究将是多元化、深化和综合的,需要从多个角度和层面进行探索和实践。在这个过程中,我们期待有更多的新模型、新方法和新理论的出现,以推动这个领域的发展和进步。
(二)学习路径
(1)基础数学和统计知识。金融时间序列分析的基础是统计学,因此学习者需要熟悉基本的统计概念,如均值、方差、协方差、相关性等。线性代数,微积分以及概率论的知识也会在模型的理解和使用中起到关键作用。
(2)编程和数据处理技能.R和Python是最常用于金融时间序列分析的编程语言。此外,SQL和Excel等数据处理工具也会在数据获取和清洗中发挥重要作用。
(3)时间序列模型。理解并能够实现各种时间序列模型,如AR、MA、ARIMA、ARCH、GARCH模型等,并能够识别模型的适用条件以及如何拟合和验证模型。
(4)金融知识.理解股票、债券、期权、期货等金融产品的基本概念以及它们的价格行为特点非常重要。此外,理解宏观经济指标如GDP、通胀、利率等是如何影响金融市场的也十分关键。
(5)高级统计模型和机器学习。随着数据规模和复杂性的增加,学习者应掌握更高级的统计模型,如向量自回归模型(VAR)、协整模型等。此外,对于机器学习模型,如支持向量机(SVM)、神经网络、随机森林、XGBoost等的理解也会对分析复杂的金融时间序列数据有很大帮助。后面会有一章专门介绍机器学习及深度学习的应用。
(6)实践经验。理论学习是重要的,但实际操作和经验同样重要,所以本人一直倡导“干中学”。这可能包括参与相关的课程项目,或者找到一些公开的金融数据进行实践。
最后,持续学习和更新知识是非常重要的,因为金融时间序列分析是一个快速发展的领域,新的技术和方法总是不断出现。参加相关的研讨会,阅读最新的研究论文,或者加入相关的专业社群,都是获取最新信息和技能的好方式。

关于Python金融量化

专注于分享Python在金融量化领域的应用。加入知识星球,可以免费获取qstock源代码、30多g的量化投资视频资料、量化金融相关PDF资料、公众号文章Python完整源码、与博主直接交流、答疑解惑等。添加个人微信sky2blue2可获取八五折优惠。