文章目录
- **RUN起来**
- **调试**
- **把控关键数据结构和函数**
- **从小的开始**
- **关注一个模块**
- **工具**
- **一、阅读开源代码存在的一些误区**
- 二、阅读代码的心态
- **三、阅读源码与**辅助材料
- **四、如何阅读开源代码**
- **《gdb 高级调试实战教程》电子书下载链接:**
- 1 下载 Nginx 源码
- 2 调试 Nginx
- **3 推荐一些 Nginx 学习书单**
- 前置准备
- 阅读文档
- 运行实例
- Debug
- 阅读 commit 历史
- 昨夜西风凋碧树](https://www.zhihu.com/search?q=昨夜西风凋碧树&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={"sourceType"%3A"answer"%2C"sourceId"%3A1984394279}),独上高楼,[望尽天涯路
- 衣带渐宽终不悔,为伊消得人憔悴。
- 众里寻他千百度,蓦然回首,那人却在灯火阑珊处。
- 一、看什么样子的开源
- 二、初步了解
- 2.1 顺一遍文档
- 2.2 重点学习思路
- 2.3 了解代码[目录结构](https://www.zhihu.com/search?q=目录结构&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={"sourceType"%3A"answer"%2C"sourceId"%3A2562876884})
- 2.4 在安装部署前补充新概念、新技术
- 三、安装部署、运行
- 3.2 成功运行的意义
- 3.3 举例子
- 四、要清楚自己的学习目的
- 4.2 学习顺序
- 4.3 数据结构和算法
- linus说:烂程序员关心的是代码,好程序员关心的是数据结构以及他们的关系。
- 五、划重点
- 安装运行:按照相关文档,安装运行项目:
- 系统测试
- 关键学习
- 六、一些建议
- 选择阅读对象
- 选择合适工具
- 从入口开始
- 结构与动手
- 修改代码测试
- 第一:阅读前的准备
- 第二:从最简单的源码开始
- 第三:先让项目跑起来
- 第四:明确阅读方向
- 第五:带着问题阅读
- 第六:学习源码风格
- 小结:
最近刚好在读Python部分源码,这几条建议一定能帮你更好的阅读开源项目
不管是阅读公司项目代码还是开源代码,都不要一开始一头扎进代码里,试图通读源码,这绝对会陷入无止境的细节。
建议先找项目的架构设计和整体流程框架的文档来看,先从顶层设计入手,掌握这个软件整体结构,它有哪些功能特性,它涉及到的关键技术、实现原理等。
接下来才是逐渐厘清模块、函数之间关系,调用图。
这个时候不建议深入看每个函数,只需要做到对整体流程有所把控即可。
RUN起来
真正去阅读的时候,最好的方式,先按着程序员正常的方式DEBUG执行跟踪一遍,也就是先跑起来,去搭建跑起来的环境这个过程也是会让你熟悉这个项目所依赖一些东西。
调试
调试一般跟找Bug差不多,两种手段:
- 打日志
- 断点
这两种有些适用场景不同,可以互相结合着使用,比如我最近在看cpython源码中,关于对象的那部分,那我就可以通过修改PyObject_Print函数,然后在其它地方调用,打印出运行时对象的一些我关注的信息。

把控关键数据结构和函数
我们说“程序=算法+数据结构”,我实际的体会是数据结构用得更多,其实不少开源项目也大多是if、else堆起来的,算法只会用到最核心的地方,但是数据结构会到处都需要。
我们可以把项目中一些核心的函数、类、数据结构逐一拿下,因为这些关键的代码往往是理解项目细节的关键。
从小的开始
最好是一些「小而美」的代码,小是指代码量少,最好就几千行,这样我们能够充分把控,美则是指代码实现写得很优雅。
我们都知道提高审美能力很重要的一环就是多看美的东西,好的设计。
那写代码也是一样的,自己学完基本语法,写出来的代码大概停留跑起来的水平。
这时候去看看大佬写的代码,你绝对会惊呼 卧槽,还能这样?
这样的代码有哪些呢?
如果你是大一的同学,我推荐你去看看 Linux 内核中关于链表的实现,简直特么太妙了,平常我们定义链表不都是这样嘛
struct Node {
int data;
struct Node* next;
}
但是这个存在的问题就是,每个想用链表存储的结构体,我们都得去写一遍,遍历、插入、删除的逻辑,显然太low了。
那 Linux kernel 中就用宏和指针变换,在对用户自定义数据结构侵入性很小的情况下,实现了其它语言中模板的功能。
相信我,看完,你会学到很多骚操作的,后面找机会写一下这块。
又比如学完 C 语言,你会不会觉得 C 中的字符串有点不灵活,那推荐你去看看 Redis 中关于动态字符串的设计–SDS。
这些代码都不长,也不难理解,但是看完对于提升我们的编码能力是有很大帮助的,这就是小而美。
提倡看源码,不是让你直接上手就啃什么 Nginx、Sqlite、Redis的源码,这些都是几万级别的代码量,一般初学者
即使要啃,我给你说个好办法,这些东西目前来看,代码量都是几万几十万的级别,有点不友好,你可以去 github fork 下来。
然后回退到第一个 commit,从第一个 commit 开始看起,看到第一个完整的版本。
也不一定非要第一个commit,反正大概理念就是尽可能看早期的具备了核心功能的版本,因为很多项目其实都是在不断完善、添加特性,但是最核心的一定是第一个MVP的实现。
这个过程也是能学到不少东西的,看看罗马都是怎么建造成的。
关注一个模块
比如我最近在研究「对象」,就去看了下Python中对象的实现,那对我最重要的就是object.c和object.h这些相关的文件,其它诸如parser、runtime就不是我关注的重点,我也不可能挨着挨着把python源码看完。
我是想通过看源码学习现代语言中对象的实现,那么就只需要关注与这部分相关的代码。
特别是开源项目每个文件上方,都有一个概要性的描述,我推荐把这样的注释看了,有助于帮助我们理解设计思路的大方向。

工具
工欲善其事必先利其器,看代码一定少不了到处跳转,这部分可以找个跳转方便的现代IDE就可以了。 比如 IDEA、Pycharm、Vscode、[source insight](https://www.zhihu.com/search?q=source insight&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={“sourceType”%3A"answer"%2C"sourceId"%3A1611527934}) 之类都可以。
为了帮助题主消除阅读开源代码的恐惧感增强信心,我先说点理论的东西,再通过几个案例来分下一下如何快速读懂开源代码,希望对你有帮助。
想在技术上有所造诣或者想成为某一技术领域的专家的同学一定要认认真真的研读几个开源项目的源码。下面我会具体来展开说下这个问题。
一、阅读开源代码存在的一些误区
部分同学阅读源码存在一些不当的习惯或者偏颇的认知方式。
比如,一些同学阅读源码其实是随波逐流的,今天有人推荐阅读 A 项目的源码,他就去阅读 A 项目的源码,明天有人推荐阅读 B 项目的源码,他就去阅读 B 项目的源码。天下源码何其多呀,找到自己感兴趣的或者对自己有用的,不要随波逐流,适合别人的不一定适合你。
有些人阅读源码非要满足了"天时地利人和"才会去阅读。例如,有些人觉得自己不懂网络编程,所以就不方便阅读 Nginx 的源码,有些人听别人说阅读某个项目的源码前必须先做 XX,而自己又不熟悉 XX,所以就放弃了阅读该项目。或者觉得当下时机不适合阅读某个项目的源码。再或者在阅读几个源码文件或者模块的代码时,因为看不懂就放弃了。其实这些做法都不可取,任何源码和你刚进入公司去接触一个新的业务项目的源码一样,只要慢慢熟悉,在这过程中针对性的补缺补差,坚持下来总会有所收获的。尤其是对那些走上工作岗位的读者来说,成年人的世界事情那么多,此生余年应该不会再有什么时间可以同时满足"天时地利人和"了吧。
代码的质量高低是相对的,不要因为一些项目的源码质量低或者不符合你的 style 就放弃。大多数完整的项目代码总有其可取之处,要学会吸取其有用之处。举个例子,很多做 Windows C++ 客户端开发的同学,应该会在网络的各个地方看到很多人抨击 MFC 的,然后一堆建议不要学习 MFC 的。从我个人的经历和感受来看,MFC 的源码还是很值得做 Windows C++ 客户端的同学学习的,尤其是其设计思想。当然,MFC 之所以被很多人抨击,是因为其臃肿笨拙,这有很多历史原因,MFC 不仅封装 Windows 界面逻辑那一套,同时实现了一套常用软件文档、视图模型的程序框架结构,同时自己实现了一套 STL 相关功能,以及其他一些常用功能(如对象的序列化和反序列化)。这些设计思想都被后来的各种软件框架借鉴和继承,例如 QT 和 Java 中的序列化和反序列化。一个开发者如果想成为架构师,其心中一定要对某个场景有一套可行的技术方案,如果你经验不足或者水平不够,拿不出来这样的方案,那就去借鉴和学习这些开源的软件。 而不是只会抨击这些软件源码的缺点,而自己又无更好的解决方案。旧的方案虽然不好,但是我们需要去学习、熟悉,只有熟悉了之后,我们才能基于其去改造和优化。
二、阅读代码的心态
阅读代码的心态,很重要。
个人觉得,一个技术人员如果想通过源码去提高自己,应该以一种"闲登小阁看新晴"的心境去阅读源码,这也许是在某个节假日的清晨,某个下过雨的午后,某个夜黑人静的深夜。看源码尤其是看高质量源码本来就是一种享受,像品茗。闲暇时间去细细品味一些开源软件的源码,和锻炼身体一样,都是人生中重要不紧急的事情,这类事情做的越多,坚持的越久,越能提高你的人生厚度。虽然阅读源码的最终目的是功利性的,但是阅读源码的心态不建议是功利性的,喜欢做一件事本身的过程,比把这件事做好的目标更快乐。
我从学生时代开始,就喜欢看一些开源软件的源码,当然,从现在的标准来看,看的很多源码都不是"高质量"的,择其善者而从之其不善者而改之,不是吗?有些源码可以学习其架构、结构设计,有些源码则可以学习其细节设计(如变量命名、编码风格等)。
看过的这些源码对我的技术视野影响很大。我上大学的时候,迷恋 Flash 编程,当时非常崇拜 Flash 界的两位前辈——鼠标炸弹(https://mousebomb.org/)和寂寞火山(现在已成币圈有名的大佬),另外还有淘沙网的沙子。多年后再看他们的代码可能质量没有那么高,但是我从他们开源出来的代码中学到了很多东西。举个例子,我喜欢在一些成对结束的花括号后面加上明显的成对结束的注释就是从沙子的代码那里学来的。虽然,现在的 IDE 会清楚的标示出来各个花括号的范围,但是这种注释风格在某些时候大大方便了代码阅读和 review。
//实例
class A
{
public:
void someFunc()
{
for (int i = 0; i < 10; ++i)
{
for (int j = 0; j < 100; ++j)
{
//some codes...
}// end inner-for-loop
}// end outer-for-loop
}// end method someFunc
}; // end class A
三、阅读源码与辅助材料
大家都知道,时下"知识付费"这个词非常火热,各大平台各个领域都推出了许多基于知识付费的课程,有图文版、语音版和视频版(包括在线实时教育直播)。当然,知识付费是一个好东西。众所周知,如今的互联网信息的特点是信息量大、有用信息少、信息质量良莠不齐,各大平台推出的各种付费课程,精心制作,用心分类和梳理,读者只要花一定的费用,就能省去大量搜索、查找和遴选信息的时间,直接专注于获得相关知识本身。
在各类知识付费课程中,有一类课程是介绍业界或者大家平常工作中用到的一些开源软件的原理的,进一步说,有的是分析这类软件的源码的,如 Nginx、Netty、Spring Boot。
我个人觉得,虽然你可以购买一些这样那样的开源软件的教程或者图书(包括电子书)去学习,但一定不要以这些学习材料为主要的学习这些开源软件的方法和途径,有机会的话,或者说你想要学习的开源软件所使用的开发语言正好是你熟悉或者使用的编程语言,那么你应该尽量多去以阅读这些开源项目的源码本身为主。举个例子,如果你是 C/C++ 后端开发者,那么像 Redis、Nginx(它们都是使用 C 编写的)这样的开源项目的源码你应该认真的去研读一下;如果你是做 Windows C/C++ 客户端或者一名 QT 客户端开发人员,那么像 MFC、DUILIB、金山卫士等源码,你可以拿来读一读;如果你是 Java 程序员,Netty、Spring 等源码是你进阶路上必须迈过去的一关。
为什么建议以阅读相关源码为主,而不是其他相关教程呢?
首先,任何其他相关教程介绍的内容都是基于这个软件的源码实现创作出来的,虽然能帮助你快速理解一些东西,但是不同的教程作者在阅读同样一份代码时的注意点和侧重点不一样,加上如果作者在某些地方有理解偏差的,这种偏差会被引入你所学习的教程或者图书里面,也就是说,你学习的这些东西其实不是第一手的,而是经过别人加工或者理解意译过的,在这个过程中如果别人理解有偏差,那么你或多或少的会受一点影响。所以,为了"不受制于人”,亲自去阅读一些源码是非常有必要的。
其次,如果你按照别人的教程大纲,那么你在学习该软件的开源项目时,可能会受限于别人的视野和侧重点,通俗的说,假设一个开源项目其可以学习和借鉴的内容有 A、B、C、D、E 五个大的点,别人的教程可能只写了 A、B、C、D 四个点,如果你只局限于别人的教程,你就错过 E 这个点了。
这里我举一个具体的例子。我刚开始工作时做的是 C/C++ 客户端开发,我无意中找到了一份完整的电驴源码,但是开始阅读这份代码比较吃力,于是我就在网上找相关的电驴源码分析教程来看。但是呢,网上的这方面的教程都是关于电驴的网络通信模块和通信协议介绍的,很多做客户端的读者是知道的,做客户端开发很大一部分工作是在开发 UI 界面方面的逻辑和布局,其实电驴源码中关于界面设计逻辑写的也是很精彩的,也非常值得当时的我去借鉴和学习。如果我只按照网上的教程去学习,那么就错过这方面的学习了。也就是说,同样一份电驴源码,不同的学习者汲取的其源码中的营养成分是不一样的。
电驴源码链接:
链接:https://pan.baidu.com/s/1DifGKQyAKawvQ80hB3CTgA
提取码:u6p2

在 Visual Studio中调试学习电驴源码
四、如何阅读开源代码
说了这么,那如何去阅读源码呢?我这里介绍三种方式。
第一种方式就是所谓的精读和粗读。
很多读者应该听说过这种所谓的阅读源代码的方式,有些观点认为有些源码只需要搞清楚其主要结构和流程就可以了,而另外一些源码需要逐行认真去研读其某个或者某几个模块的源码,或者,只阅读自己感兴趣或者需要的模块。
第二种方式,说的是先熟悉代码的整体结构,再去依次搞清楚各个模块的代码细节,学会记录。
一边学习代码一边记录,是不错的学习方法。
有些同学喜欢给开源代码加上详细的注释,然后分享出来,方便后来自己或者他人阅读。还有的同学会写一些开源项目的源码解析类文章。
数年前,我当时为了学习网络编程和 C++11 新语言特性,利用工作闲暇时间去阅读蘑菇街开源的即时通讯软件 TeamTalk:
https://github.com/balloonwj/TeamTalk
我写了十一篇关于 TeamTalk 源码分析的专栏文章:
TeamTalk源码分析(一)-- TeamTalk介绍
TeamTalk源码分析(二) – 服务器端的程序的编译与部署
TeamTalk源码分析(三) – 服务器端的程序架构介绍
TeamTalk源码分析(四) – 服务器端db_proxy_server源码分析
TeamTalk源码分析(五) – 服务器端msg_server源码分析
TeamTalk源码分析(六) – 服务器端login_server源码分析
TeamTalk源码分析(七) – 服务器端msf源码分析
TeamTalk源码分析(八) – 服务器端file_server源码分析
TeamTalk源码分析(九) – 服务器端route_server源码分析
TeamTalk源码分析(十) – 开放一个TeamTalk测试服务器地址和几个测试账号
TeamTalk源码分析(十一) —— pc客户端源码分析
TeamTalk 服务端网络拓扑图:
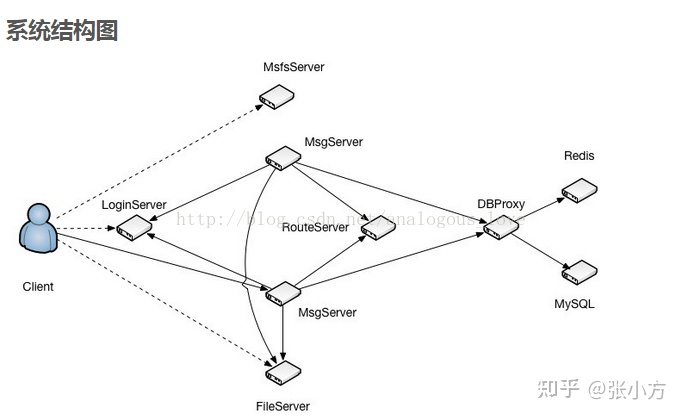
客户端运行截图:


第三种方式是所谓的调试法,通过开源项目的一个或几个典型的流程,去调试跟踪信息流,然后逐步搞清楚整个项目的结构。
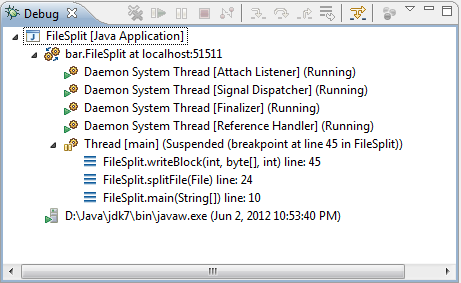
我之前在携程旅行网做基础架构时,为了学习 Redis,我一边研究 Redis 的源码,一边编写了利用 GDB 调试 Redis 的教程。
调试是学习开源项目非常好用的一个方法。对于做 Linux C++ 开发一定要会用 GDB 调试 C/C++ 程序。熟练掌握 gdb 调试等于拥有了学习优秀 C 和 C++ 开源项目源码的钥匙,只要可以利用 gdb 调试,再复杂的项目,在不断调试和分析过程中总会有搞明白的一天。
我当时写这套教程有两个初衷:
- 网上很多关于 gdb 的教程都是零散的,不成体系;
- GDB 用来教学的调试的都是各种玩具型程序,看完之后很多读者还是不知道如何利用 GDB 调试大型 C/C++ 项目。
因此我结合自己的工作经验,写了一套《gdb 高级调试实战教程》,这个教程有如下特点:
- 以调试开源项目 Redis-Server 为例,项目不是玩具型的,具有实战意义;
- 按调试流程,从 gdb 附加调试程序,到启动 gdb 调试再到使用 gdb 中断 Redis 查看各种状态,循序渐进地介绍各种 gdb 调试命令;
- 介绍了实际工作中 gdb 的各种高级调试技巧,例如如何显示超长字符串、如何使用 gdb 调试多进程程序等等;
- 也介绍了基于 gdb 的一些高级工具,如 cgdb、VisualGDB,这些章节是为不习惯 gdb 显示源码方式的同学量身定制。
电子书目录如下图所示:



《gdb 高级调试实战教程》电子书下载链接:
链接: https://pan.baidu.com/s/1fS8571m6KYcR4tQ05Lbkgw 提取码: wiw3
相关的配套资源:
- Redis 4.0.11 源码下载:https://github.com/balloonwj/redis-4.0.11
- Redis 6.0.6 源码下载:https://github.com/balloonwj/redis-6.0.3
- cgdb 下载地址:cgdb
- VisualGDB 破解版下载地址:
链接:https://pan.baidu.com/s/1f4Y275wEhljVK1-ChEdUkw 提取码:snwb
再比如,后来我创业了,我们的项目需要用到 Nginx,另外一点就是很早就听说 Nginx 的性能非常高,使用非常广,我一直也想找个时间去系统地研究一下 Nginx 的源码,例如 Nginx 多进程模式是如何设计的、反向代码是如何实现的等等。我学习 Nginx 源码仍然是调试大法。
注意:Nginx 的功能点比较多,涉及到的新概念和设计思路对于新手也不是特别友好,我建议在了解Nginx 的一些基本用法之后,再通过调试来学习 Nginx 源码。
1 下载 Nginx 源码
从 Nginx 官网下载最新的 Nginx 源码,然后编译安装(回答此问题时,nginx 最新稳定版本是 1.18.0)。
## 下载nginx源码
[root@iZbp14iz399acush5e8ok7Z zhangyl]# wget http://nginx.org/download/nginx-1.18.0.tar.gz
--2020-07-05 17:22:10-- http://nginx.org/download/nginx-1.18.0.tar.gz
Resolving nginx.org (nginx.org)... 95.211.80.227, 62.210.92.35, 2001:1af8:4060:a004:21::e3
Connecting to nginx.org (nginx.org)|95.211.80.227|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1039530 (1015K) [application/octet-stream]
Saving to: ‘nginx-1.18.0.tar.gz’
nginx-1.18.0.tar.gz 100%[===================================================================================================>] 1015K 666KB/s in 1.5s
2020-07-05 17:22:13 (666 KB/s) - ‘nginx-1.18.0.tar.gz’ saved [1039530/1039530]
## 解压nginx
[root@iZbp14iz399acush5e8ok7Z zhangyl]# tar zxvf nginx-1.18.0.tar.gz
## 编译nginx
[root@iZbp14iz399acush5e8ok7Z zhangyl]# cd nginx-1.18.0
[root@iZbp14iz399acush5e8ok7Z nginx-1.18.0]# ./configure --prefix=/usr/local/nginx
[root@iZbp14iz399acush5e8ok7Z nginx-1.18.0]make CFLAGS="-g -O0"
## 安装,这样nginx就被安装到/usr/local/nginx/目录下
[root@iZbp14iz399acush5e8ok7Z nginx-1.18.0]make install
注意:使用 make 命令编译时我们为了让生成的 Nginx 带有调试符号信息同时关闭编译器优化,我们设置了"-g -O0"选项。
2 调试 Nginx
可以使用如下两种方式对 Nginx 进行调试:
方法一
启动 Nginx:
[root@iZbp14iz399acush5e8ok7Z sbin]# cd /usr/local/nginx/sbin
[root@iZbp14iz399acush5e8ok7Z sbin]# ./nginx -c /usr/local/nginx/conf/nginx.conf
[root@iZbp14iz399acush5e8ok7Z sbin]# lsof -i -Pn | grep nginx
nginx 5246 root 9u IPv4 22252908 0t0 TCP *:80 (LISTEN)
nginx 5247 nobody 9u IPv4 22252908 0t0 TCP *:80 (LISTEN)
如上所示,Nginx 默认会开启两个进程,在我的机器上以 root 用户运行的 Nginx 进程是父进程,进程号 5246,以 nobody 用户运行的进程是子进程,进程号 5247。我们在当前窗口使用gdb attach 5246命令将 gdb 附加到 Nginx 主进程上去。
[root@iZbp14iz399acush5e8ok7Z sbin]# gdb attach 5246
...省略部分输出信息...
0x00007fd42a103c5d in sigsuspend () from /lib64/libc.so.6
Missing separate debuginfos, use: yum debuginfo-install glibc-2.28-72.el8_1.1.x86_64 libxcrypt-4.1.1-4.el8.x86_64 pcre-8.42-4.el8.x86_64 sssd-client-2.2.0-19.el8.x86_64 zlib-1.2.11-10.el8.x86_64
(gdb)
此时我们就可以调试 Nginx 父进程了,例如使用 bt 命令查看当前调用堆栈:
(gdb) bt
#0 0x00007fd42a103c5d in sigsuspend () from /lib64/libc.so.6
#1 0x000000000044ae32 in ngx_master_process_cycle (cycle=0x1703720) at src/os/unix/ngx_process_cycle.c:164
#2 0x000000000040bc05 in main (argc=3, argv=0x7ffe49109d68) at src/core/nginx.c:382
(gdb) f 1
#1 0x000000000044ae32 in ngx_master_process_cycle (cycle=0x1703720) at src/os/unix/ngx_process_cycle.c:164
164 sigsuspend(&set);
(gdb) l
159 }
160 }
161
162 ngx_log_debug0(NGX_LOG_DEBUG_EVENT, cycle->log, 0, "sigsuspend");
163
164 sigsuspend(&set);
165
166 ngx_time_update();
167
168 ngx_log_debug1(NGX_LOG_DEBUG_EVENT, cycle->log, 0,
(gdb)
使用 f 1 命令切换到当前调用堆栈#1,我们可以发现 Nginx 父进程的主线程挂起在src/core/nginx.c:382处。
此时你可以使用 c 命令让程序继续运行起来,也可以添加断点或者做一些其他的调试操作。
再开一个 shell 窗口,使用gdb attach 5247将 gdb 附加到 Nginx 子进程:
[root@iZbp14iz399acush5e8ok7Z sbin]# gdb attach 5247
...部署输出省略...
0x00007fd42a1c842b in epoll_wait () from /lib64/libc.so.6
Missing separate debuginfos, use: yum debuginfo-install glibc-2.28-72.el8_1.1.x86_64 libblkid-2.32.1-17.el8.x86_64 libcap-2.26-1.el8.x86_64 libgcc-8.3.1-4.5.el8.x86_64 libmount-2.32.1-17.el8.x86_64 libselinux-2.9-2.1.el8.x86_64 libuuid-2.32.1-17.el8.x86_64 libxcrypt-4.1.1-4.el8.x86_64 pcre-8.42-4.el8.x86_64 pcre2-10.32-1.el8.x86_64 sssd-client-2.2.0-19.el8.x86_64 systemd-libs-239-18.el8_1.2.x86_64 zlib-1.2.11-10.el8.x86_64
(gdb)
我们使用 bt 命令查看一下子进程的主线程的当前调用堆栈:
(gdb) bt
#0 0x00007fd42a1c842b in epoll_wait () from /lib64/libc.so.6
#1 0x000000000044e546 in ngx_epoll_process_events (cycle=0x1703720, timer=18446744073709551615, flags=1) at src/event/modules/ngx_epoll_module.c:800
#2 0x000000000043f317 in ngx_process_events_and_timers (cycle=0x1703720) at src/event/ngx_event.c:247
#3 0x000000000044c38f in ngx_worker_process_cycle (cycle=0x1703720, data=0x0) at src/os/unix/ngx_process_cycle.c:750
#4 0x000000000044926f in ngx_spawn_process (cycle=0x1703720, proc=0x44c2e1 <ngx_worker_process_cycle>, data=0x0, name=0x4cfd70 "worker process", respawn=-3)
at src/os/unix/ngx_process.c:199
#5 0x000000000044b5a4 in ngx_start_worker_processes (cycle=0x1703720, n=1, type=-3) at src/os/unix/ngx_process_cycle.c:359
#6 0x000000000044acf4 in ngx_master_process_cycle (cycle=0x1703720) at src/os/unix/ngx_process_cycle.c:131
#7 0x000000000040bc05 in main (argc=3, argv=0x7ffe49109d68) at src/core/nginx.c:382
(gdb) f 1
#1 0x000000000044e546 in ngx_epoll_process_events (cycle=0x1703720, timer=18446744073709551615, flags=1) at src/event/modules/ngx_epoll_module.c:800
800 events = epoll_wait(ep, event_list, (int) nevents, timer);
(gdb)
可以发现子进程挂起在src/event/modules/ngx_epoll_module.c:800的 epoll_wait 函数处。我们在 epoll_wait 函数返回后(src/event/modules/ngx_epoll_module.c:804)加一个断点,然后使用 c 命令让 Nginx 子进程继续运行。
800 events = epoll_wait(ep, event_list, (int) nevents, timer);
(gdb) list
795 /* NGX_TIMER_INFINITE == INFTIM */
796
797 ngx_log_debug1(NGX_LOG_DEBUG_EVENT, cycle->log, 0,
798 "epoll timer: %M", timer);
799
800 events = epoll_wait(ep, event_list, (int) nevents, timer);
801
802 err = (events == -1) ? ngx_errno : 0;
803
804 if (flags & NGX_UPDATE_TIME || ngx_event_timer_alarm) {
(gdb) b 804
Breakpoint 1 at 0x44e560: file src/event/modules/ngx_epoll_module.c, line 804.
(gdb) c
Continuing.
接着我们在浏览器里面访问 Nginx 的站点,我这里的 IP 地址是我的云主机地址,读者实际调试时改成自己的 Nginx 服务器所在的地址,如果是本机就是 127.0.0.1,由于默认端口是 80,所以不用指定端口号。
http://你的IP地址:80
等价于
http://你的IP地址
此时我们回到 Nginx 子进程的调试界面发现断点被触发:
Breakpoint 1, ngx_epoll_process_events (cycle=0x1703720, timer=18446744073709551615, flags=1) at src/event/modules/ngx_epoll_module.c:804
804 if (flags & NGX_UPDATE_TIME || ngx_event_timer_alarm) {
(gdb)
使用 bt 命令可以获得此时的调用堆栈:
(gdb) bt
#0 ngx_epoll_process_events (cycle=0x1703720, timer=18446744073709551615, flags=1) at src/event/modules/ngx_epoll_module.c:804
#1 0x000000000043f317 in ngx_process_events_and_timers (cycle=0x1703720) at src/event/ngx_event.c:247
#2 0x000000000044c38f in ngx_worker_process_cycle (cycle=0x1703720, data=0x0) at src/os/unix/ngx_process_cycle.c:750
#3 0x000000000044926f in ngx_spawn_process (cycle=0x1703720, proc=0x44c2e1 <ngx_worker_process_cycle>, data=0x0, name=0x4cfd70 "worker process", respawn=-3)
at src/os/unix/ngx_process.c:199
#4 0x000000000044b5a4 in ngx_start_worker_processes (cycle=0x1703720, n=1, type=-3) at src/os/unix/ngx_process_cycle.c:359
#5 0x000000000044acf4 in ngx_master_process_cycle (cycle=0x1703720) at src/os/unix/ngx_process_cycle.c:131
#6 0x000000000040bc05 in main (argc=3, argv=0x7ffe49109d68) at src/core/nginx.c:382
(gdb)
使用 info threads 命令可以查看子进程所有线程信息,我们发现 Nginx 子进程只有一个主线程:
(gdb) info threads
Id Target Id Frame
* 1 Thread 0x7fd42b17c740 (LWP 5247) "nginx" ngx_epoll_process_events (cycle=0x1703720, timer=18446744073709551615, flags=1) at src/event/modules/ngx_epoll_module.c:804
(gdb)
Nginx 父进程不处理客户端请求,处理客户端请求的逻辑在子进程中,当单个子进程客户端请求数达到一定数量时,父进程会重新 fork 一个新的子进程来处理新的客户端请求,也就是说子进程数量可以有多个,你可以开多个 shell 窗口,使用 gdb attach 到各个子进程上去调试。
然而,方法一存在一个缺点,即程序已经启动了,我们只能使用 gdb 观察程序在这之后的行为,如果我们想调试程序从启动到运行起来之间的执行流程,方法一可能不太适用。有些读者可能会说:用 gdb 附加到进程后,加好断点,然后使用 run 命令重启进程,这样就可以调试程序从启动到运行起来之间的执行流程了。问题是这种方法不是通用的,因为对于多进程服务模型,有些父子进程有一定的依赖关系,是不方便在运行过程中重启的。这个时候方法二就比较合适了。
方法二
gdb 调试器提供一个选项叫 follow-fork,通过 set follow-fork mode 来设置:当一个进程 fork 出新的子进程时,gdb 是继续调试父进程(取值是 parent)还是子进程(取值是 child),默认是父进程(取值是 parent)。
# fork之后gdb attach到子进程
set follow-fork child
# fork之后gdb attach到父进程,这是默认值
set follow-fork parent
我们可以使用 show follow-fork mode 查看当前值:
(gdb) show follow-fork mode
Debugger response to a program call of fork or vfork is "child".
我们还是以调试 Nginx 为例,先进入 Nginx 可执行文件所在的目录,将方法一中的 Nginx 服务停下来:
[root@iZbp14iz399acush5e8ok7Z sbin]# cd /usr/local/nginx/sbin/
[root@iZbp14iz399acush5e8ok7Z sbin]# ./nginx -s stop
Nginx 源码中存在这样的逻辑,这个逻辑会在程序 main 函数处被调用:
//src/os/unix/ngx_daemon.c:13行
ngx_int_t
ngx_daemon(ngx_log_t *log)
{
int fd;
switch (fork()) {
case -1:
ngx_log_error(NGX_LOG_EMERG, log, ngx_errno, "fork() failed");
return NGX_ERROR;
//fork出来的子进程走这个case
case 0:
break;
//父进程中fork返回值是子进程的PID,大于0,因此走这个case
//因此主进程会退出
default:
exit(0);
}
//...省略部分代码...
}
如上述代码中注释所示,为了不让主进程退出,我们在 Nginx 的配置文件中增加一行:
daemon off;
这样 Nginx 就不会调用 ngx_daemon 函数了。
接下来,我们执行gdb nginx,然后通过设置参数将配置文件 nginx.conf 传给待调试的 Nginx 进程:
Quit anyway? (y or n) y
[root@iZbp14iz399acush5e8ok7Z sbin]# gdb nginx
...省略部分输出...
Reading symbols from nginx...done.
(gdb) set args -c /usr/local/nginx/conf/nginx.conf
(gdb)
接着输入 run 命令尝试运行 Nginx:
(gdb) run
Starting program: /usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
[Thread debugging using libthread_db enabled]
...省略部分输出信息...
[Detaching after fork from child process 7509]
如前文所述,gdb 遇到 fork 指令时默认会 attach 到父进程去,因此上述输出中有一行提示”Detaching after fork from child process 7509“,我们按 Ctrl + c 将程序中断下来,然后输入 bt 命令查看当前调用堆栈,输出的堆栈信息和我们在方法一中看到的父进程的调用堆栈一样,说明 gdb在程序 fork 之后确实 attach 了父进程:
^C
Program received signal SIGINT, Interrupt.
0x00007ffff6f73c5d in sigsuspend () from /lib64/libc.so.6
(gdb) bt
#0 0x00007ffff6f73c5d in sigsuspend () from /lib64/libc.so.6
#1 0x000000000044ae32 in ngx_master_process_cycle (cycle=0x71f720) at src/os/unix/ngx_process_cycle.c:164
#2 0x000000000040bc05 in main (argc=3, argv=0x7fffffffe4e8) at src/core/nginx.c:382
(gdb)
如果想让 gdb 在 fork 之后去 attach 子进程,我们可以在程序运行之前设置 set follow-fork child,然后使用 run 命令重新运行程序。
(gdb) set follow-fork child
(gdb) run
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
[Attaching after Thread 0x7ffff7fe7740 (LWP 7664) fork to child process 7667]
[New inferior 2 (process 7667)]
[Detaching after fork from parent process 7664]
[Inferior 1 (process 7664) detached]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
^C
Thread 2.1 "nginx" received signal SIGINT, Interrupt.
[Switching to Thread 0x7ffff7fe7740 (LWP 7667)]
0x00007ffff703842b in epoll_wait () from /lib64/libc.so.6
(gdb) bt
#0 0x00007ffff703842b in epoll_wait () from /lib64/libc.so.6
#1 0x000000000044e546 in ngx_epoll_process_events (cycle=0x71f720, timer=18446744073709551615, flags=1) at src/event/modules/ngx_epoll_module.c:800
#2 0x000000000043f317 in ngx_process_events_and_timers (cycle=0x71f720) at src/event/ngx_event.c:247
#3 0x000000000044c38f in ngx_worker_process_cycle (cycle=0x71f720, data=0x0) at src/os/unix/ngx_process_cycle.c:750
#4 0x000000000044926f in ngx_spawn_process (cycle=0x71f720, proc=0x44c2e1 <ngx_worker_process_cycle>, data=0x0, name=0x4cfd70 "worker process", respawn=-3)
at src/os/unix/ngx_process.c:199
#5 0x000000000044b5a4 in ngx_start_worker_processes (cycle=0x71f720, n=1, type=-3) at src/os/unix/ngx_process_cycle.c:359
#6 0x000000000044acf4 in ngx_master_process_cycle (cycle=0x71f720) at src/os/unix/ngx_process_cycle.c:131
#7 0x000000000040bc05 in main (argc=3, argv=0x7fffffffe4e8) at src/core/nginx.c:382
(gdb)
我们接着按 Ctrl + C 将程序中断下来,然后使用 bt 命令查看当前线程调用堆栈,结果显示确实是我们在方法一中子进程的主线程所在的调用堆栈,这说明 gdb 确实 attach 到子进程了。
我们可以利用方法二调试程序 fork 之前和之后的任何逻辑,是一种较为通用的多进程调试方法,建议读者掌握。
总结起来,我们可以综合使用方法一和方法二添加各种断点调试 Nginx 的功能,慢慢就能熟悉 Nginx 的各个内部逻辑了。
3 推荐一些 Nginx 学习书单
必看 Nginx 经典书籍(含下载方式)mp.weixin.qq.com/s/uP6_2UaTFZkwvGhNopWzSg
以上三种方式都是不错的阅读源码的方式,读者可以根据自己的水平、目的和所处阶段去使用。
最后,阅读源码不是做给别人看的,如果你之前从未意识到阅读各种大大小小的开源项目的源码的重要性,从现在开始,循序渐进,少买点在线课程,少囤点书,多读些开源代码吧。
看开源代码一行一行读肯定是不行,因为人脑的缓存和内存都非常低,短期之内记不住几行代码,阅读量上来,如果没有纲领,基本就是浪费时间。下面的几个方法可以快速的建立纲领:
- 阅读文档
- 运行实例
- Debug
- 阅读 commit 历史
前置准备
首先,需要准备该语言的 IDE 或者具有 IDE 功能的编辑器,比如代码调转、补全、类型推断等等功能。
然后,把代码拉到本地,用 IDE 打开。
最后,确保可以编译 或者 解释 某个实例。
阅读文档
如果对一个开源项目感兴趣,特别是想学到一些新知识,阅读文档是最佳的途径。一般的开源项目文档组织如下:
-
用户说明
-
- 项目说明:解释这个项目的目的、设计原则等等
- 快速开始:一般包括几个运行实例
-
API 说明
一般如果某个项目属于你比较熟悉的业务领域,那么稍微阅读一下用户说明,就可以看看 API 的组成,主要关注:
- 命名规则
- 功能分类规则
上面这些内容有助于理解项目整体的一些特性,非常有助于后面阅读源代码。
运行实例
这部分就是把代码 Pull 回本地,然后运行之前看到的一些实例。注意最好不要安装二进制或者包后运行。而是pull代码回本地后编译运行,这样可以为下一步 Debug 关键功能做好准备。
通过运行实例,可以熟悉该项目一些基本的使用方法和规则,找到自己感兴趣的部分,就可以开始进行 Debug 操作了。
Debug
阅读文档和源代码属于静态分析,软件的运行时需要在大脑中就行模拟(大脑就变成了一个解释器)。可是有些项目抽象比较复杂,大脑往往很难完成这个解释运行时的工作。Debug 就成了快速熟悉代码运行时的最佳方式。
把一个自己感兴趣的实例运行在 Debug 模式,然后一步一步的 Step in,观察数据是如何变化、函数调用如何发展等等。
很多语言都有函数调用分析的静态分析工具,但是个人感觉对于大项目,函数的调用栈非常复杂,今天分析工具生成的图表不一定非常直观。大部分时候,还是 Debug 某个 code path 比较直接。
阅读 commit 历史
再熟悉了一些 Code path 以后就可以聚焦在自己最为感兴趣的功能或者模块上。这时候我们应该利用好版本控制工具。
比如,对于一个项目,我们可以回滚的某个早期的版本,观察代码的演变;也可以观察某个函数的变化历史。这些 Commit 往往体现了贡献者对该函数或者模块理解的变化。会帮助我们进一步理解项目。
为什么人们都愿意“重新造轮子”?一个重要的原因就是:读别人的代码比自己写还难!
开源代码不适合新手学习,除非是那种具有良好文档的,而且深入浅出的优秀代码。
但这几乎是不可能的。因为:
1、文档的写作是很枯燥的;
2、开源代码是免费的,其作者没有义务为你解释服务;
3、开源代码更倾向于使用一些“复杂”的“新”技术,而不是朴实的保守的旧技术。
如果题主英语好,情况可能会好一点,因为有限的开源代码文档资料绝大部分都是英文的。
如果题主有兴趣的话,我开源了两个项目,正在进行中:
英雄帖:开源项目招募英才
。但不得不说,写文档真是件苦逼的事!
"没有经验的技术差底子薄的初级程序员,如何阅读项目源码? "
“有人阅读过 mybatis 的源码吗 ?就看一个初始化过程就看的已经头晕眼花了,小伙伴们支支招吧!”
"源码应该怎么阅读,我曾经尝试阅读一些源码,例如alibaba的druid中sqlparser部分,spring-mvc,但是发现很吃力,都说debug是最好的阅读方式,我在debug时经常有跟丢的现象……就是走着走着感觉好像进入了一些我当前不太关注细枝末节。 "
。。。。。。
估计很多人都有这样的疑惑。
我非常能理解小伙伴们的痛苦,因为我也是这么痛苦着走过来的。
阅读优秀源码的好处想必大家都知道,学习别人优秀的设计,合理的抽象,简洁的代码… 总之是好处多多。
但是真的把庞大的代码放到你的面前,就如同一个巨大的迷宫,要在其中东转西转寻出一条路来,把迷宫的整个结构搞清楚,理解核心思想,真心不容易。
在阅读由面向对象的语言如Java写的代码时,会发现接口和具体的实现经常对应不起来,不太清楚一个功能到底是怎么在哪个实现类中才能找到。 不像C语言,就是函数调用函数,相对还好点。
如果是动态语言如Ruby,Python, 一个变量的类型甚至都不容易知道,阅读的难度大大增加。
还有一个重要的原因,现在我们看到的源码基本上都经过若干年发展、经过很多人不断地完善的,枝枝蔓蔓非常多,魔鬼都在细节中。 阅读的时候很容易陷进去, 看了几十层函数调用以后,就彻底懵了,就放弃了: 甭管你把源码吹得天花乱坠, 老子再也不看了。
经过很多痛苦的挣扎以后,我也算有一些成功的经历,今天用治学的三个境界来类比, 给大家分享一下:
昨夜西风凋碧树,独上高楼,望尽天涯路
想把源码搞懂,吃透,首先得登高望远,瞰察路径,明确目标与方向,了解源码的概貌。
所以有些准备工作必须得做。
1. 阅读源码之前,需要有一定的技术储备。
比如设计模式,在很多Java源码中几乎就是标配,尤其是这几个:模板方法,单例,观察者,工厂方法,代理,策略,装饰者。
再比如阅读Spring源码,肯定得先了解IoC是怎么回事,AOP的实现方式,CGLib,Java动态代理等,自己动手,写点相关的代码,把这些知识点掌握了。
2. 必须得会使用这个框架/类库, 最好是精通各种各样的用法。
上面刚提过,魔鬼都在细节中,如果有些用法根本不知道,可能你能看明白代码是什么意思,但是不知道它为什么这些写。
3. 先去找书,找资料,了解这个软件的整体设计。
都有哪些模块? 模块之间是怎么关联的?怎么关联的?
可能一下子理解不了,但是要建立一个整体的概念,就像一个地图,防止你迷航。
在读源码的时候可以时不时看看自己在什么地方。
4. 搭建系统,把源代码跑起来!
相信我,Debug是非常非常重要的手段, 你想通过只看而不运行就把系统搞清楚,那是根本不可能的!
衣带渐宽终不悔,为伊消得人憔悴。
5. 根据你对系统的理解,设计几个主要的测试案例,定义好输入,输出。
运行系统,慢慢地debug ,一步步地走,这是个死功夫,没有办法绕过。
Debug一遍肯定是不行的,需要Debug很多遍。
第一遍尽可能抛弃细节,抓住主要流程, 比如有些看起来不重要的方法就不进去看了。
第二遍、第三遍…再去看那些细节。
一个非常重要的工作就是记笔记(又是写作!),画出系统的类图(不要依靠IDE给你生成的), 记录下主要的函数调用, 方便后续查看。
文档工作极为重要,因为代码太复杂,人的大脑容量也有限,记不住所有的细节。 文档可以帮助你记住关键点, 到时候可以回想起来,迅速地接着往下看。
要不然,你今天看的,可能到明天就忘个差不多了。
给大家看看我做的一些笔记, 格式不重要,很随意,方便自己看懂就行。




6. 主要的测试案例搞明白了,丰富测试案例,考虑一些分支流程。
继续Debug…
总之,静态地看代码 + 动态地debug (从业务的角度), 就会慢慢揭开这个黑暗森林的面纱。
这一步会非常非常地花费时间,但是你做完了,对系统的理解绝对有质的飞跃。
众里寻他千百度,蓦然回首,那人却在灯火阑珊处。
没有千百度的上下求索,不会有瞬间的顿悟和理解,衷心祝愿阅读源码的朋友们都能达到这一境界。
最后一点,也是最关键的一点: 要能坚持下去。
我不是一个聪明人, 但是笨人自有笨办法:什么事都架不住不断的重复,一遍看不明白,再来第二遍, 两遍搞不明白,再来第三遍…
可能有人要问: 你怎么能这么坚持地刨根问底呢?
答案就是好奇心: 这玩意儿到底是怎么实现的?!
今天一文分享怎么学习开源代码,纯干货纯干货!可以复制到自己的笔记本!
一、看什么样子的开源
- 开源项目中要有**全套的源码和配套工具,**刚开始学开源的时候可别找那种没有工具或者少源码的给自己增加难度。
- 需要有完善的文档,比如新手指南、项目整体的架构设计文档、模块详细的设计文档,配置说明文档和注意事项。
- 看社区是否活跃,是否还在更新和完善。
这几点非常非常重要,基本上是一个初学者学开源的必备内容。
二、初步了解
2.1 顺一遍文档
很少有小伙伴可以好好的看一遍官方文档,因为一开始的心态就是扎进去学。
这样非常容易造成:
- 给自己添加难度,很多细节的内容,根本不懂。
- 着急动手实践,发现自己连基本的使用方式都没弄明白。
- 或者你能找到和黑马程序员一样给大家按照官方文档讲解的课程
2.2 重点学习思路
首先是项目的背景:项目用了什么技术?提供了什么特性?它实际解决了什么问题?
项目的适用场景是:优点是什么?缺点呢?适合与不适合的场景是什么?
哪些公司在生产环境中使用?
有欧少公司在生产环境中部署并维护过此开源项目?
一方面经历过生产环境的质量相对较好,及时用bug其他公司或多或少也遇到过,自己解决起来也不至于孤立无援。
2.3 了解代码目录结构
在下载源码之后,先看下代码目录的结构,或者是从示例测试代码入手,比如:
- base代表基础库
- net代表网络库
- demo/example代表示例代码
- tests:测试代码
- docs:文档目录(类图、流程图、活动图、业务知识相关资料等)
刚刚入手的时候,建议从标粗的内容开始看起来。
2.4 在安装部署前补充新概念、新技术
在已有的知识体系纸上去学习新的开源项目,需要对概念或者新技术有个大概的了解,才能更好地理解项目的整体实现思路,做起来才可以事倍功半。
千万不要一上来就看代码,核心概念不清楚,原理不懂,核心算法没吃透,看代码非常费劲。
三、安装部署、运行
好的开源项目,文档都是比较完善的,安装部署文档一般会有的,更好的甚至都会有rpm安装包和docker镜像。
先把程序运行起来,这只是第一遍!
运行起来之后,精简自己的环境,减少后面调试过程中会出现的干扰信息。
比如,Nginx使用多进程的方式处理请求,为了调试跟踪Nginx的行为,我经常把worker数量设置为1个,这样调试的时候就知道待跟踪的是哪个进程了。
3.2 成功运行的意义
第一:先来体验项目的功能,对开源项目的功能从上帝视角了解。
第二:下断点>调试>修改代码>观察>再调试,从这个反复的步骤中了解程序的逻辑。
3.3 举例子
安装配置环境>从最简单的例子入门>研究复杂一点的例子>自己写个demo;
常见的安装目录是conf存放配置文件,logs存放日志文件,bin存放日志文件。有一些特殊情况,Nginx有html目录,这种目录能促使我们带着相关疑问继续研究学习,带着问题学习是最高效的。
四、要清楚自己的学习目的
我遇到很多同学上来就是找我,老师给我推荐点什么的开源项目,我说为什么学?很多同学的回答都是感觉该学点源码了。但是完全不知道自己为什么要学。
是要了解其中一个模块,比如是基础模块还是业务模块?
4.2 学习顺序
- 第一步:业务逻辑的实现流程,中间调用了第三方库函数、utils函数、定制的数据结构和算法等;还要了解对外的接口,这些接口的入口,出口参数以及作用。
- 第二步:看看内存池的实现代码、调度器代码、dpdk中对于海量数据包是如何处理的。
- 第三步:制作成excel表格,记录走读进度
- 第四步:批判性的思维,为什么要这样做?
比如:从main函数进入,使用gdb单步跟踪清理一次完整流程(如程序初始化)的代码调用路径,这可以通过debug来观察运行时的变量和行为。
如果实在是读不下去的话,先找到自己的兴趣所在,如果你对网络通讯感兴趣,就阅读网络层代码,深入到实现细节。比如:它用了什么库、采用了什么设计模式、为什么这么做?如果可以,debug的细节是什么?
或者是,看1.0版本的源码,1.0版本的内容,从复杂度上来说,都小很多,比较容易。
4.3 数据结构和算法
如果上面的步骤都完成了,在来这里。如果真的不明白可以跳过去!比如判断参数的就可以跳过不看的,其次就是代码中有没有一些非顺序的代码,如果有你能理解么?比如通过中间件MQ继续后续的流程等等,所以大家要学会分析。
优秀的开源项目当中都有很多经典的算法,可以全部跳过之后再来学习!
因为结构定义了一个程序的架构,结构定下来了才有具体的实现,好比盖房子。数据结构就是框架的结构,至于算法,暂时属于不需要深究的细节。先了解入口出口参数以及作用就可以了。
linus说:烂程序员关心的是代码,好程序员关心的是数据结构以及他们的关系。
所以在,读一份代码的时候,理清楚核心的数据结构之间的关系很重要。
五、划重点
将上面说的学习事项再次总结梳理一遍!
安装运行:按照相关文档,安装运行项目:
- 系统的依赖组件:
**因为依赖组件是系统设计和实现的基础,可以了解系统关键信息。**比如Memcached最重要的一来是高性能的网络库libevent,我们大概就能推测出Memached的网络实现应该是Reacyor模型。 - 系统提供的工具:
**需要特别关注命令行和配置文件,通过这两个非常重要的信息,**我们可以知道系统具备哪些能力和系统将会如何运行。这些信息是我们学习系统内部机制和原理的窗口。
系统测试
如果只是自己学习和研究是可以参考网上测试和分析的文档,但是大家是要在生产环境投入使用必须进行测试。思路如下:
- 核对每个配置项的作用和影响,识别出关键配置项
- 进行多场景的性能测试
- 进行压力测试:连续跑几天,观察CPU、内存、磁盘IO等指标拨动
- 进行故障测试:kill、断点、拔网线等等
关键学习
有人学了源码跟没学一样,主要是读了,连API都没有调用过,这是灾难式学习。所以这个阶段的关键学习如下:
在IDE拿到调用栈:
在IDE里面读,这里方便跳转,方便查看定义,比网页上效率高。
通过IDE工具,运行example程序进行跟踪调试,通过打断点可以的刀片程序运行的调用栈。
尽可能编译调试,只要调试了,基本没有看不懂的代码。
重点注意是,平常的时候多了解一些设计模式,这样看到名字里比如有proxy之类的直接就明白了。代码都是分模块的,要知道自己看的是哪个层哪个模块。
小的项目分层不明显的话就无所谓了,更多是注重语法的技巧。读没读懂,最简单的标准是,有没有信心可以写出一个差不多的东西。
六、一些建议
上面说的全部内容都是认真学开源的步骤,完全不能少的步骤。
大家如果抱着多学几个开源的心态,不如集中全部时间,把一个项目吃透,哪怕用了半年的时间。积累几年下来的数量还是非常可观的。而且很多项目的思想是共同的,比如高可用方案、分布式协议等。
一定要记得,不断的总结复盘,最好可以不仅写笔记还在论坛上分享。一方面锻炼自己的思维,一方面建立知识索引。
阅读源码的速度与你自身的水平成正比,所以经验不足,基础不好是快不起来的。一般来说,建议先读一些小而全的代码,对类似的工程有初步的认识,然后再去看成熟的开源项目。
具体阅读的时候要确定目标,从庞大的系统中抽离出你想研究的内容, 同时最好有好的ide工具方便搜索。剩下的按照
1.运行程序,观察表现
2.打断点调试,增加log输出
3.查看堆栈、画流程图
4.提出问题
5.解决问题
的流程梳理与分析,需要重复执行。
我之前写过一篇文章,描述了我在一个百万代码级别的项目里是如何学习的,可以参考一下
原创: Jerish 微信公众号——游戏开发那些事
最近有朋友突然问我一个问题 “你怎么把UE4引擎代码看的那么深入的?”
看到问题后我还愣了一下,因为这是第一次有人给我打了个"深入UE4"的标签。其实我接触虚幻引擎满打满算也就两年,确实谈不上深入。只是靠着平时的学习习惯积累,写了一些相关的技术文章。
但这个事却让我突然意识到最容易被我忽略的学习习惯很可能是有一定价值和意义的。我只想着分享我对引擎学习的心得总结,却从没有想过分享我的学习方法,或许后者更为重要。
每一个人做事都有自己的风格与习惯。当你发现身边一个人很优秀的时候,你去看一下他的24小时是怎么度过的,然后再对比一下你的24小时,答案就很明了了。同理,如果你觉得学习源码很困难,不妨请教一下那些比较牛的"过来人",看一下别人学习源码模块的流程。当然具体来说,影响一个事物的维度,细节,前提条件都很多,别人的方法照搬过来可能是行不通的,比如说别人能一天雷打不动地学10个小时,这个放到有些人身上几乎不可能。这些道理大家都明白,我也不过多阐述。
回归主题,既然标题是“如何学习大型项目的源码”,所以下面我把自己学习虚幻引擎源码(C++)的思路和过程给分享给大家。
虚幻引擎源码大概有几百万行(没有确切统计过,可以参考下面的纯代码加静态库文件夹截图),最早可以追溯到1998年Epic自主研发的3D游戏——虚幻。对于一个提供了如此完善功能的游戏引擎,可以想象到他的代码是相当复杂的。所以,在学习的一开始你要明确,你的目的不应该是从头到尾地读遍他所有的源码,而是确定好学习目标后,抽丝剥茧地且有条理的整理出某一个具体模块的内容。

UE4纯源码文件夹信息
这里先给出简化版的总结,然后我会针对每条做进一步的阐述。
**准备工作:**建议准备大块且连续的时间(细碎的时间容易中断类关系的梳理),一个比较方便查找的IDE或工具(VS,Notepad++,UltraEdit,Source Insight等。评论区有朋友推荐Source Insight效果与VS+Visual AssistX差不多),类图工具(staruml,Edraw等)
学习步骤(简化版):
1.决定要学习的模块,查找官方文档、相关的总结文章,整理出大概的学习内容与目标
2.运行程序,观察表现
3.运行源码,断点调试,从头跟一边源码的执行流程,注意函数堆栈
4.画类图、流程图,先把遇到的重要类记录下来,表明各个类的关系
5.记录问题,把不理解的类或者内容以问题的方式记录下来
6.写文章、笔记,尝试逐个解决之前遗留的问题
2-6可能需要持续的重复进行
学习步骤(详细版):
1. 查找官方文档、相关的总结文章
比如说我想研究网络模块,首先去官方文档、论坛、wiki里面过一遍网络相关的所有内容,这时候遇到不懂的问题尽可能解决,解决不了的就把问题记下来,先去官方文档看我觉得是非常有必要的,因为这里的文章是最权威的,错误率非常低。然后,去Google、百度搜索相关的文章与帖子,同时可以加入一些技术qq群(有一些水群果断退了就行,保留一些优质的交流群),过一遍这些文章和资料。目前能看到比较好的技术网站大体上就是各个技术对应的官方网站(论坛)、StackOverflow、知乎、博客园、简书、CSDN、一些个人网站等,当然有些网站复制粘贴现象严重,需要自己筛选。建议能找到原文链接的尽量去原文里面看,因为你有可能从原创作者那里看到更多优秀的文章。
2. 在运行程序的时候,我们需要调整各种参数来执行不同的情况,进而观察其表现效果来验证我们的猜想与结论
比如说,对于一个处于休眠状态的Actor属性是否能正常同步,如果客户端属性与服务器一样是否还会执行回调函数等。执行程序可以快速的得到结论,然后根据结论我们可以更快速准确的进行分析。为了提高效率,最好在一开始就设置不同的配置、GM等来在项目运行时动态改变运行内容,因为大型项目一般都是编译型语言,我们可能可能需要频繁的修改代码编译再重新运行。
3.调试可以说是最为关键的一步了,80%的细节需要你在调试中去理解
函数什么时候执行到这里(函数断点)?每一步每一个属性值是多少?属性值什么时候发生变化(条件断点,内存断点)?一个完整的执行流程是什么样的(函数堆栈)?这些问题需要你一点一点的进行跟踪调试,最后再去解决。
4.画图的习惯可能很多人没有,但是我个人觉得这是一个必不可少的环节,因为他可以大幅度提高你对框架理解的速度
对于任何一个复杂的项目,每一个模块都会牵扯到大量的类(排除纯C项目),类的关系错综复杂,而且为了降低耦合还可能用到各种设计模式,这些都大大提高了代码的阅读难度,很有可能你看了3、4个类之后就完全搞混了他们都是干什么的。举例来说,我在看UE4属性同步模块的时候,完全被各个类之间的关系搞蒙了,所以我看到一个类就把他的类图画下来,看到相关的类就记录他们的关系,最后得到了下面这样一个简化的类图。经过梳理后,几句话我就可以概括他们之间的关系。
当然,除了类图以外,还有流程图、时序图,甚至是你自己为了方便发明的“模块关系图”,这时候图的种类与规范其实没有那么重要,只要能帮助你理解就行。

更新一下:我后来意识到VS其实是自带显示类图功能的,可以直接使用这个功能。点击菜单栏——视图——类视图,然后右键你要查看的项目——查看类视图。效果如下图,很明显问题比较多,一是格式太死板不方便阅读,二是不能很好的表示各个类间更进一步的关系(StarUML对于模板类支持的也不好),三是不方便修改。如果是一个小的模块倒是可以用它查看,比较方便。

5.记录的问题有两种:别人给你的问题以及你自己给自己的问题
别人给你的问题:你在阅读的时候不可能一帆风顺,可能在第一步的时候,就已经遇到了无数的问题。这时候不要着急,按照重要程度顺序依次解决,简单的问题直接网上搜一搜,解决不了可以找身边的大神,网上的牛人解决。如果还是不行,就把问题记下来,然后继续学习,当你深入到一定程度的时候,你的问题可能就不攻自破了。
自己给自己的问题:当你解决了别人给你的问题后,你应该已经理解了一大半了。不过,任何人写的文章都不可能覆盖到全部,你需要自己挖掘更多更深的问题,然后自己再去解答,这样你才能做到比别人了解的更多,更能体现出你自己的价值。
6.写文章和写笔记是有区别的,但是都很有意义
写文章这件事相比上面的步骤我觉得不算是必须的,这个适合那些追求完美还能挤出时间的人。你写的东西是要给别人看的,所以你的目的是给别人讲清楚。我在写文章的时候会去考虑这个东西我说的真的对么,有没有把握,考虑的是否全面。在这种自我拷问下,我会尽可能的完善我的知识体系,修改文章中那些看起来不够准确的内容。如果最后能做到给读者讲清楚的话,那你是真的会了。
写笔记相比写文章要轻松很多,我只是把我总结的内容,学习的收获记录下来,不需要考虑太多的东西。虽然没有写文章那么追求完美,但是这个过程中我们可能也会多了很多思考,在之后的学习过程中快速的回忆起自己学习的经验。
备注:第一次执行这个过程是相当漫长和艰难的,如果和我一样一开始知识储备不够,那么几乎每走一步都需要大量的学习和查资料。不过只要坚持下去,你最后会发现自己的收获非常大,阅读其他模块的源码也变得容易很多。
上面只是我学习源码的一个方法,可能并不适合所有人,也还有很多地方可以进一步完善。
最后,我再强调一点,如果只是为了使用好一个工具,你不需要彻彻底底的理解所有内容,因为你的时间是有限的。如果你真的是抱着学习的态度去研究源码细节,那请做好花费大量时间的准备并坚持下去。
有哪些更好的方法或者建议,欢迎留言评论。
读代码是个好事情啊,不过呢,你要想读好,确实是一个要努力的工作。我自己读的代码不太多:JavaSE的代码,Eclipse的代码,SpringMVC的代码,所以算是有些经验吧。简单分享一下我怎么读吧。好像都是Java相关的,没办法,当时初做程序确实是从Java开始的。
选择阅读对象
好的开源代码读起来确实是像一本好书一样,可以让你领略到一个世界的精彩。但是不同于课本的方式,在于开源代码大部分好的系统本身的设计,代码的简洁,相对统一的编码规范,还有某种有目的性的优化,这些东西都是不一样的。有些会让你感到困惑,有些会让你赞叹不已。但是当你从全局的角度看,这些东西还都有合理性。所以怎么选择入门,确实是一个需要想好的东西。
我建议的原则,自己工作中用到,广泛被使用,可以找到大量的辅助参考资料,至少本身文档写的不错的。
建议难度顺序:JavaSE的IO,Collection两个包的代码,然后SpringMVC的核心Code,再然后有意愿可以读Eclipse的代码(虽然大家可能慢慢不用这个IDE了,但是它的Plugin设计,是我见过的最精典的设计之一)。
选择合适工具
工欲善其事,必先利其器。现在的代码阅读工具其实有好多了,大部分的IDE都可以充当阅读工具。我个人是比较喜欢Eclipse的。因为它自带的Java,CPP等代码编辑部分还是很好用的,现时提供了Bookmark功能,再加上一个便签类的就好了。用它们的好处,主要是两个注意点:
- 快速的调用关系查询,对于c/cpp一类的来讲,基本上都是函数名,类方法名就能找到,但是Java本身由于接口的关系,你需要注意的是那个接口被那个类实现了,然后当前方法中调用的是那个具体的实现。这时就要靠bookmark与便签的功能了。另外就是,你要是能把这个代码运行起来,IDE的好处马上就可见了,Breakpoint一下,马上就知道了。同时再看一下调用栈,
\2. 类的继承关系,及接口的实现关系。
理解它们,是你真正理解设计的一个好的观看方式。但是要熟知这块的东西,我建议你先把设计模式的基本概念看明白。或者说先看一遍设计模式的书后,再边看代码边理解这些模式。因为Java本身这个社区,可以说从JavaSE到Eclipse,到SpringMVC本身都是结合了大量精典的设计模式的概念做出来的产品。所以你不明白设计模式,差不多就相当于不懂一门外语的语法 了。
从入口开始
main、main、main
这个东西很重要,你一定要找到一个程序的最初的入口才能更好的理解程序的加载。就像你要进一个屋子,一定要找到门一样。从这儿才可能抽丝剥茧,一层层的理解好程序的内容。不过我推荐你的三个代码阅读对象,只有eclipse才有main, 还是在它的c代码里 😦 。
但是对于别的程序,如果从入口 开始,结合IDE的调试功能,做个断点,确实是最快的理解调用关系的方式。
结构与动手
光看与通过IDE或者其它代码编辑器去看代码,可能是有一些概念,但是这样是没有反馈的。不要光想,还要动手画一下。如果你对UML这个设计语言比较熟悉,建议你画一些UML的图。画下来,才能真正确定你是不是理解了。我最喜欢的两种图:类图与Sequence图,在表达静态关系与动态关系上,最直观。这个时候我喜欢用的工具是一个开源的小玩意:Umlet

修改代码测试
不知道你小的时候,干没干过拆家里电器的事。我呢,拆过无数次,好在都安然无恙的把它们都安回去了。现在干软件的好处就是不怕这样折腾被骂了。
所以,安心的动手去改一下你想了解的代码吧。改了,运行了,自然就知道这个代码的功能自己理解的是不是对的。
所以对于代码的改动,也是阅读理解代码的一个重要组成。千万别忘了。
根据我的经验,把握粒度很重要,每行每行读是不现实的,这样容易造成只见树木不见森林,但是又不能读的太粗糙,否则错过很多精华部分,以c代码为例,我一般是先以文件为单位,看看每个文件大致是干嘛的,然后再以函数为单位,这时不关心函数的具体实现细节,而是将注意力放在函数接口上,大致理解下函数的意图,控制流的流动等,然后觉得哪个函数比较重要,在看看其实现。。。
如果一上来就一行一行的啃就图样图森破了,上述过程完成之后,如果还有余力,最好亲手实现一下,正所谓知者行之始,行者知之成,知行合一,如果能自己写一个,就说明真的掌握了。。。
用拼图、搭积木的心态来学习源码,如果你想了解它们是怎么组装在一起的,那你就需要把它分解成每一小块,再去弄清楚每一个模块是如何实现的,整体架构是怎样的。
关于源码阅读的三层境界:
**初级:记流水账——**初期的源码阅读文章基本上是记流水账,例如对源码一行行加注释,只关注底层实现细节,但并未形成更高层次认知,对其设计理念没有提炼与深度领悟。
**中级:能提问、思考、提炼——**要求我们在阅读源码的时候多思考,并反问自己如果自己实现的话该如何着手,如何设计,带着疑问去研究源码。通过对比,思考,会对其背后的理念有了更深刻的理解。
**高级:思考、质疑、验证——**不管是什么代码,都会存在BUG或者实现并不合理的地方,如果大家在阅读源码的时候能够深入思考, 合理质疑,并能通过验证证明自己的观点,说明我们的能力、思考得到了极大的提升。
第一:阅读前的准备
为了有效地阅读源码,你可以准备好下面这些工具:
- 编辑器:你需要一个可以熟练使用的编辑器,这能让你拥有快速搜索关键字或变量名、、查找函数的引用和定义等
- Git工具:掌握基本的Git或其他版本控制工具的技能,这样你就能比较代码在版本间的差异
- 相关文档:阅读官方源码文档可以帮助你快速了解项目,如设计文档、编码规范等文档
第二:从最简单的源码开始
不知道如何下手,就先从最简单的源码开始阅读。
开源项目有很多种,有数据库连接池,还有Spring框架类的,当然还有特别重型的中间件类的,比如Kafka、Redis,更有上百万行的大数据类的,比如Hadoop、Spark。
很多人还没掌握阅读源码的顺序、技巧和方法,所以看过一些源码但依旧不懂。所以大家先要明白一个前提,Kafka的作者,Hadoop的作者,他们本身就是有很多经验、技术功底很扎实的技术大牛,他们本身站在一个很高的角度去设计和开发出来了这些极为出色的分布式系统。
如果你还达不到他们的水平,你是无法直接去阅读他们写出来的代码的,因为其中蕴含的各种底层技术细节,分布式架构设计思想,还有复杂的算法和机制,这些都不是能简单理解的。
所以,建议大家可以挑一些简单的,适合自己水平的去看。
第三:先让项目跑起来
阅读项目源码的第一步,是先让项目能够通过你自己编译通过并且顺利跑起来。
有的项目很复杂,依赖的组件很多,搭建起一个调试环境并不容易,所以不见得所有项目都能顺利的跑起来。
第四:明确阅读方向
在开始阅读一个项目时候,需要明确自己的目的,是需要了解其中的一个模块实现,还是要了解这个框架的大结构,还是需要具体熟悉其中的一个算法的实现等。
代码阅读过程中,大家可以分成这两个方向来看:
- 纵向——顺着代码的顺序阅读,了解清楚流程、算法
- 横向——区分不同的模块进行阅读,梳理项目整体框架
建议大家两个方向进行交替阅读,以整体为首,先了解清楚脉络,暂时先不要纠结某个函数、数据结构这些,不影响整体的阅读就可以。
第五:带着问题阅读
如果阅读代码只是输入(Input),那么还需要有输出(Output)。只有你能真正输出的时候,就是你彻底掌握的时候。
比如在阅读代码的时候,大家可以带着问题去阅读,多问自己一些问题,如:
- 1.如果我来做一个,会如何去做?
- 2.如果能够对这个项目做减法,我可以去掉那些模块和代码?真的能够去掉吗?
- 3.通过阅读单元测试,理解开发者的设计思路。
- 4.尝试做一些破坏或者修改,来理解项目中的那些做法。
越是主动积极的思考,就越有助于大家的学习,输出质量和学习质量是成正比的。
第六:学习源码风格
不管是学习新技术还是代码风格,看源码都是一种不错的学习方式,尤其是优秀的开源代码,总是能有我们值得借鉴的地方。
比如,大家可以侧重学习这几方面内容:
**学习语言:**代码风格、规范、惯用法、高级语法。对于某个语言的新手,找一个熟悉领域的开源项目来深入掌握这门语言,也是一个不错的注意。
**学习设计:**数据接口、框架、整体架构
**学习理论:**算法、协议。光看论文是很枯燥的,而且算法理论到工程实践还是有一定的差距,这个时候结合开源项目实现往往更事半功倍。
小结:
上面分享了几点源码阅读的方法,但其实源码阅读没有统一的标准。大家可以自己不断练习,找到适合自己的方法和工具,慢慢的就会形成一套自己源码阅读方式。