文章目录
- (155)纠删码原理
- 纠删码原理
- 纠删码相关命令
- 纠删码策略解释
- (156)纠删码案例实操
- 参考文献
(155)纠删码原理
纠删码原理
默认情况下,一个文件在HDFS里会保留3个副本,以此提高数据的可靠性(容灾),但也带来了2倍的存储上的冗余开销。
于是Hadoop3.x引入了纠删码,采用计算的方式来提高数据的可靠性,可以节省50%左右的存储空间。
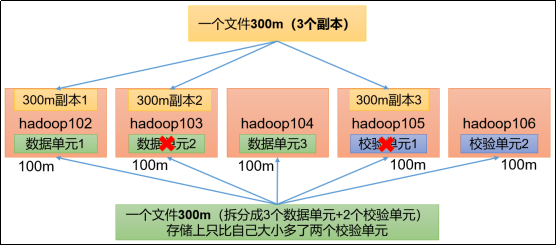
如上图(黄色部分),默认情况下,对于一个300M大小的文件,实际上HDFS会消耗300M*3=900M的空间来存储。
那纠删码是怎么做的呢?(上图中绿色部分)
对于一个300M大小的文件,会拆分成3个数据单元和2个校验单元,每个单元占用100M,总共占用500M。(占用空间比默认情况下要少)
那纠删码是怎么保障数据的可靠性的呢?
如果其中任意两个单元挂掉,不管是校验单元还是数据单元,其他还存活的单元仍然可以通过计算的方式,将挂掉的单元恢复出来,不影响数据的正常使用。
因此纠删码属于是 节省了物理存储空间,但是牺牲了集群的计算资源 。这个优缺点要注意,因为一般来讲,计算资源更重要些,所以纠删码的应用场景相对会比较窄。
这里其实有个问题,就是纠删码能够恢复的上限是多少,即最多允许在丢失多少个单元的情况下,能够完成数据恢复?
这个教程里没有讲,我简单查了一下,是不超过校验单元的数量就可以,比如说上例里,校验单元数量为2,如果丢失3个及以上数量的单元,就没法恢复了。
纠删码相关命令
hdfs ec:查看帮助文档;
hdfs ec -listPolicies:列出所有支持的纠删码策略;
hdfs ec -getPolicy -path <path>:获取某一个路径的纠删码策略。可以看到纠删码策略很灵活啊,是可以分路径来配置不同的策略。
hdfs ec -setPolicy -path <path> -policy <policy>:对某一个路径设置纠删码策略;
其他不表。
查看当前支持的纠删码策略:
[atguigu@hadoop102 hadoop-3.1.3] hdfs ec -listPolicies
Erasure Coding Policies:
ErasureCodingPolicy=[Name=RS-10-4-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=10, numParityUnits=4]], CellSize=1048576, Id=5], State=DISABLED
ErasureCodingPolicy=[Name=RS-3-2-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=3, numParityUnits=2]], CellSize=1048576, Id=2], State=DISABLED
ErasureCodingPolicy=[Name=RS-6-3-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=1], State=ENABLED
ErasureCodingPolicy=[Name=RS-LEGACY-6-3-1024k, Schema=[ECSchema=[Codec=rs-legacy, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=3], State=DISABLED
ErasureCodingPolicy=[Name=XOR-2-1-1024k, Schema=[ECSchema=[Codec=xor, numDataUnits=2, numParityUnits=1]], CellSize=1048576, Id=4], State=DISABLED
可以看到,当前启用的纠删码策略只有一个,即RS-6-3-1024k。因为只有它是State=ENABLED。
纠删码策略解释
RS-3-2-1024k:使用RS编码,每3个数据单元,生成2个校验单元,共5个单元,也就是说:这5个单元中,只要有任意的3个单元存在(不管是数据单元还是校验单元,只要总数=3),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。
RS-10-4-1024k:使用RS编码,每10个数据单元(cell),生成4个校验单元,共14个单元,也就是说:这14个单元中,只要有任意的10个单元存在(不管是数据单元还是校验单元,只要总数=10),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。
RS-6-3-1024k:使用RS编码,每6个数据单元,生成3个校验单元,共9个单元,也就是说:这9个单元中,只要有任意的6个单元存在(不管是数据单元还是校验单元,只要总数=6),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。
RS-LEGACY-6-3-1024k:策略和上面的RS-6-3-1024k一样,只是编码的算法用的是rs-legacy。
XOR-2-1-1024k:使用XOR编码(速度比RS编码快),每2个数据单元,生成1个校验单元,共3个单元,也就是说:这3个单元中,只要有任意的2个单元存在(不管是数据单元还是校验单元,只要总数= 2),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。
这里的1024K怎么理解哈,以RS-3-2-1024K策略为例解释一下。
可以简单的理解成是大单元和小单元的区别。或者把1024K理解成一个常规情况下的最小size。
可以认为,1024K是一个小单元的大小,假设你有300M数据,要划分成3个大数据单元,那么每个大数据单元就包含了100个小数据单元。
假设你有2M数据,那就只能划分出2个小数据单元,分别分给2个大数据单元,每个大数据单元只有一个小数据单元。
假设你有1M以内的数据,那就最终都放在一个大的数据单元里。
(156)纠删码案例实操
纠删码策略是给具体一个路径设置。所有在此路径下存储的文件,都会执行此策略。
默认只开启对RS-6-3-1024K策略的支持,其他策略如果想使用,必须要先手动开启。
教程里接下来的示例,都是以RS-3-2-1024K为例讲解,因为这样只需要5台节点就可以了。
具体步骤
(1)开启对RS-3-2-1024k策略的支持
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs ec -enablePolicy -policy RS-3-2-1024k
Erasure coding policy RS-3-2-1024k is enabled
(2)在HDFS创建目录,并设置RS-3-2-1024k策略
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfs -mkdir /input
[atguigu@hadoop202 hadoop-3.1.3]$ hdfs ec -setPolicy -path /input -policy RS-3-2-1024k
(3)上传文件,并查看文件编码后的存储情况
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfs -put web.log /input
注:你所上传的文件需要大于2M才能看出效果。(低于2M,只有一个数据单元和两个校验单元)
(4)查看存储路径的数据单元和校验单元,删掉部分数据,来作破坏实验,会发现很快就恢复回来了。
注意,纠删码应用后,数据的副本相当于是只有1份了。只不过是这一份数据,分布在5台节点上。直接查看存储的内容是看不懂的,因为是有自己的保存形式,用来计算的。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】






![2023年中国纸箱机械优点、市场规模及发展前景分析[图]](https://img-blog.csdnimg.cn/img_convert/1627efa273e9d7f4a633393bb15c4acf.png)