智能驾驶技术的不断发展,正在改变着我们的出行方式和交通系统。作为其中的一个关键技术,三维重建在智能驾驶系统中起着重要的作用。除去车端本身的感知、重建算法,自动驾驶技术的落地与发展需要庞大的云端重建能力支撑,火山引擎多媒体实验室通过行业领先的自研三维重建技术,结合强大的云平台资源与能力,助力相关技术在云端大规模重建、自动标注、真实感仿真等场景的落地与应用。
本文重点介绍火山引擎多媒体实验室三维重建技术在动态、静态场景的以及结合先进光场重建技术的原理与实践,帮助大家能更好的了解和认识云上智能三维重建如何服务智能驾驶领域,助力行业发展。
一、技术挑战与难点
驾驶场景重建需要对道路环境做点云级别的三维重建,与传统的三维重建技术应用场景相比,驾驶场景重建技术有以下难点:
车辆运行过程中的环境因素复杂且不可控,不同天气、光照、车速、路况等均会对车载传感器采集到的数据造成影响,这对重建技术的鲁棒性带来了挑战。
道路场景中经常会出现特征退化和纹理缺失的情况,例如相机获取到视觉特征不丰富的图像信息,或者激光雷达获取到相似性较高的场景结构信息,同时,路面作为重建中的关键要素之一,色彩单一且缺少足够的纹理信息,这对重建技术提出了更高的要求。
车载传感器数量较多,常见的有相机、激光雷达、毫米波雷达、惯导、GPS定位系统、轮速计等等,如何将多传感器的数据融合起来得到更精确的重建结果,对重建技术提出了挑战。
道路中存在运动车辆、非机动车、行人等动态物体,会对传统重建算法带来挑战,如何剔除动态物体对静态场景重建带来干扰,同时对动态物体的位置、大小、速度进行估计,也是项目的难点之一。
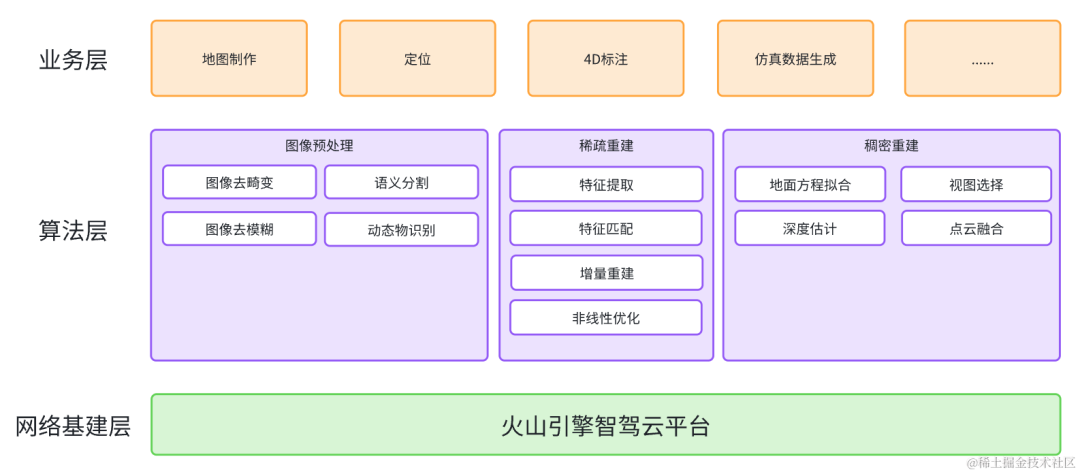
二、驾驶场景重建技术介绍
自动驾驶领域的重建算法通常会采用激光雷达、相机为主,GPS、惯导为辅的技术路线。激光雷达可以直接获取高精度的测距信息,能够快速得到场景结构,通过预先进行的激光雷达-相机联合标定,相机获取到的图像能够为激光点云赋予色彩、语义等信息。同时,GPS和惯导可以进行辅助定位,减少重建过程中因为特征退化而出现的漂移现象。但是,由于多线激光雷达售价较高,通常用于工程车辆,而在量产车上很难得到规模化的使用。
对此,火山引擎多媒体实验室自研了一套纯视觉的驾驶场景重建技术,包括静态场景重建、动态物体重建和神经辐射场重建技术,能够区分场景中的动静态物体,还原出静态场景的稠密点云,并突出路面、指示牌、红绿灯等关键要素;能够对场景中运动物体的位置、大小、朝向和速度进行有效的估计,用于后续的4D标注;能够在静态场景重建的基础上,使用神经辐射场对场景进行重建和复现,实现自由视角的漫游,可用于场景编辑和仿真渲染。这套技术解决方案不依赖激光雷达,且能够达到分米级的相对误差,用最小的硬件成本实现接近激光雷达的重建效果。
2.1 静态场景重建技术:剔除动态干扰、还原静态场景
视觉重建技术以多视角几何作为基础的理论依据,要求待重建的场景或者物体具有帧间一致性,即在不同图像帧中处在静止状态,因此需要在重建过程中剔除动态物体。根据场景中的不同要素的重要性,稠密点云中需要去除无关紧要的点云,而保留一些关键要素点云,因此需要事先对图像进行语义分割。对此, 火山引擎 多媒体实验室结合AI技术与多视角几何基本原理,搭建了一套先进的鲁棒、精确完整视觉重建算法框架。重建过程包括三个关键步骤 :图像预处理、稀疏重建和稠密重建 。
车载相机拍摄过程中处在运动状态,由于曝光时间的存在,采集到的图像中会随着车速提高而出现严重的运动模糊现象。另外,出于节约带宽和存储空间考虑,传输过程中会对图像进行不可逆的有损压缩,造成画质的进一步降低。为此, 火山引擎多媒体实验室使用了端到端的神经网络对图像进行去模糊处理,能够在抑制运动模糊现象的同时对图像质量进行提升。去模糊前后的对比如下图所示。
 去模糊前(左) 去模糊后(右)
去模糊前(左) 去模糊后(右)
为了区分出动态物体,火山引擎多媒体实验室使用了基于光流的动态物体识别技术,能够得到像素级别的动态物体掩膜。在之后的静态场景重建过程中,落在动态物区域上的特征点将被剔除,只有静态的场景和物体将得到保留。

光流(左) 运动物体(右)
稀疏重建过程中需要同时计算相机的位置、朝向和场景点云,常用的有SLAM算法(Simultaneous localization and mapping)和SFM算法(Structure from Motion,简称SfM)。在不要求实时性的情况下,SFM算法能够得到更高的重建精度。但是,传统的SFM算法通常将每个相机当作独立相机来进行处理,而车辆上通常会在前后左右不同方向布置多个相机,这些相机之间的相对位置其实是固定不变的(忽略车辆振动带来的细微变化)。如果忽视相机与相机之间的相对位置约束,计算出来的各相机位姿误差会比较大。另外,当遮挡比较严重时,个别相机的位姿会难以计算。对此,火山引擎多媒体实验室自研了基于相机组整体的SFM算法,能够利用相机之间的先验相对位姿约束,以相机组作为整体来计算位姿,同时使用了GPS加惯导的融合定位结果对相机组中心位置进行约束,可有效地提高位姿估计的成功率和准确率,并能改善不同相机之间的点云不一致现象,减少点云分层现象。

 传统SFM(左) 相机组SFM(右)
传统SFM(左) 相机组SFM(右)
由于地面色彩单一、纹理缺失,传统的视觉重建很难还原出完整的地面,但是地面上存在车道线、箭头、文字/标识等关键要素,因此火山引擎多媒体实验室采用了二次曲面来拟合地面,辅助进行地面区域的深度估计和点云融合。和平面拟合相比,二次曲面更贴合实际道路场景,因为实际的路面往往并不是一个理想平面。以下是分别用平面方程和二次曲面方程来拟合地面的效果对比。
 平面方程(左) 二次曲面方程(右)
平面方程(左) 二次曲面方程(右)
将激光点云视作真值,并将视觉重建结果与之叠加,可以直观地衡量重建点云的准确性。从下图中可以看到,重建点云和真值点云贴合度非常高,经过测量得到重建结果的相对误差在15cm左右。
 火山引擎多媒体实验室重建结果(彩色)与真值点云(白色)
火山引擎多媒体实验室重建结果(彩色)与真值点云(白色)
以下是火山引擎多媒体实验室视觉重建算法和某主流商业重建软件的效果对比。可以看到,和商业软件相比,火山引擎多媒体实验室的自研算法重建效果更好、更完整,场景中的路牌、红绿灯、电线杆,以及路面上车道线、箭头等还原度非常高,而商业软件的重建点云非常稀疏,且路面大范围缺失。
 某主流商业软件(左) 火山引擎多媒体实验室算法(右)
某主流商业软件(左) 火山引擎多媒体实验室算法(右)
2.2 动态重建技术:
在图像上对物体进行3d标注十分困难,需要借助于点云,当车辆只有视觉传感器时,获取场景中目标物体的完整点云十分困难。特别是动态物体,无法使用传统的三维重建技术获取其稠密点云。为提供运动物体的表达,服务于4d标注,使用3d bounding box(以下简称3d bbox)对动态物体进行表示,通过自研动态重建算法获取每一时刻场景中动态物体的3d bbox姿态、大小、速度等,从而补全动态物体重建能力。
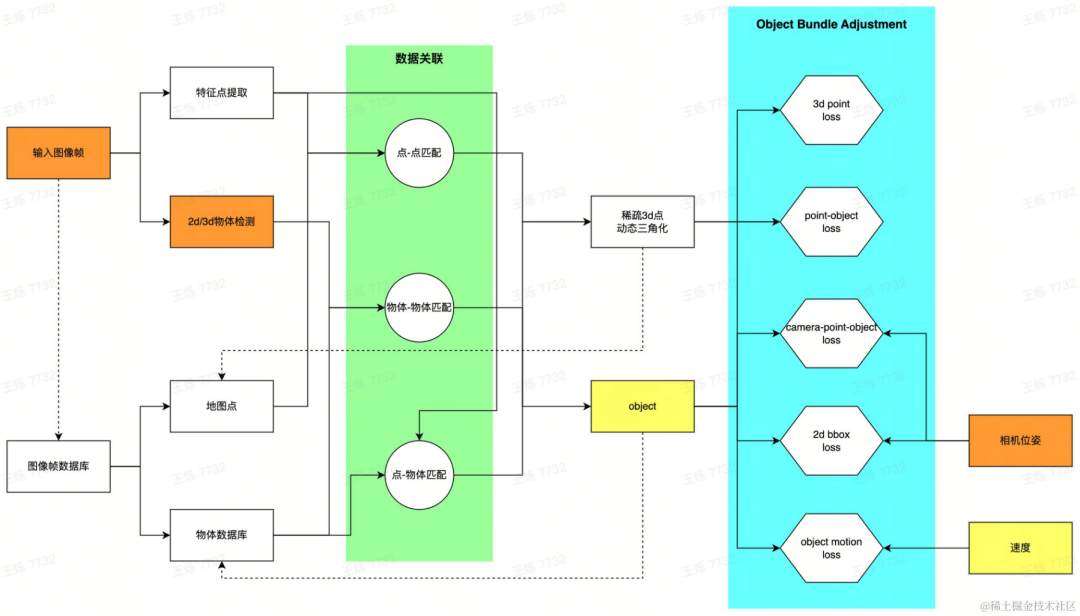 动态重建pipeline
动态重建pipeline
对车辆采集的每一帧图像,首先提取场景中的动态目标,生成3d bbox的初始提议,提供两种方式:使用2d目标检测,通过相机位姿估计对应的3d bbox;直接使用3d目标检测。两种方式针对不同数据可以灵活进行选择,2d检测泛化性好,3d检测可以获得更好的初值。同时,对图像动态区域内部的特征点进行提取。获取单帧图像初始3d bbox提议及特征点后,建立多帧间数据关联:通过自研多目标跟踪算法建立物体匹配,并通过特征匹配技术对图像特征进行匹配。获取匹配关系后,将有共视关系的图像帧创建为局部地图,构建优化问题求解全局一致的目标bbox估计。具体地,通过特征点的匹配以及动态三角化技术,恢复动态3d点;对车辆运动建模,联合优化物体、3d点、相机之间的观测,从而获得最优估计的动态物体3d bbox。
 2d生成3d(左二) 3d目标检测示例
2d生成3d(左二) 3d目标检测示例
多目标跟踪算法示例
动态重建结果demo
2.3 NeRF 重建:真实感渲染、自由视角
使用神经网络进行隐式重建,利用可微渲染模型,从已有视图中学习如何渲染新视角下的图像,从而实现照片级逼真的图像渲染, 即神经辐射场(NeRF)技术。同时,隐式重建具有可编辑、查询连续空间的特性,可以用于自动驾驶场景中自动标注、仿真数据构建等任务。使用NeRF技术对场景进行重建是非常有价值的。
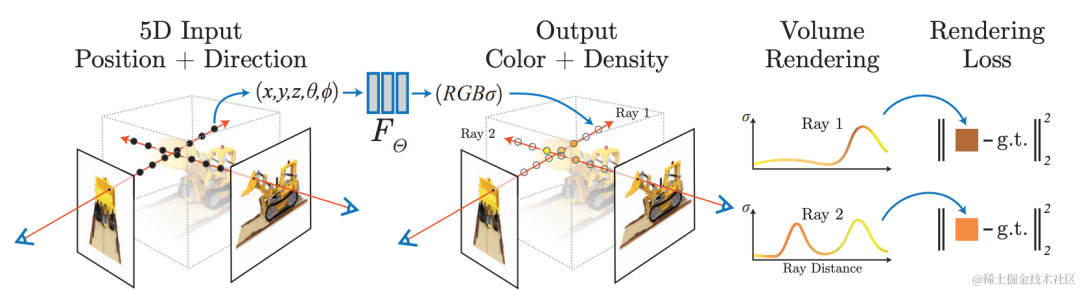
火山引擎多媒体实验室融合神经辐射场技术与大场景建模技术。在具体实践中,首先针对数据进行处理,场景中的动态物体会使NeRF重建出现伪影,借助自研动静态分割、影子检测等算法,对场景中和几何不一致的区域进行提取,生成mask,同时利用视频inpainting算法,对剔除掉的区域进行修复。借助自研三维重建能力,对场景进行高精度的几何重建,包括相机参数估计以及稀疏、稠密点云生成。另外,对场景进行拆分以减小单次训练资源消耗,并可做分布式训练、维护。在神经辐射场训练过程中,针对室外无边界大场景,团队通过一些优化策略以提升该场景下的新视角生成效果,如通过在训练中同时优化位姿提高重建精度,基于哈希编码的层次化表达提升模型训练速度,借助外观编码提升不同时间采集场景的外观一致性等,借助mvs稠密深度信息提升几何精度等。团队同毫末智行合作,完成单路采集以及多路合并的NeRF重建,相关成果已在毫末AI Day发布。
 动态物/影子剔除,填补
动态物/影子剔除,填补
单摄像头nerf重建
自由视角+几何对比







![2023年中国火焰切割机分类、产业链及市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/9b19e3bb56ecbfe0a02e94ae14245eb7.png)


![2023年中国轮胎模具需求量、竞争格局及行业市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/c07c2d1a809d79680f23831441b90477.png)
![2023年中国工业空气加热器市场规模及存在问题分析[图]](https://img-blog.csdnimg.cn/img_convert/52c223704fb82100a8f9a8b37bf15a03.png)