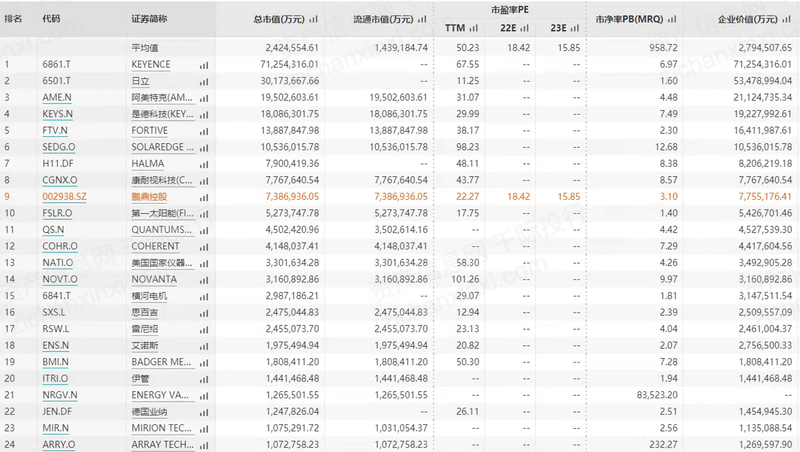
文章目录
- 1 协议层
- 1.1 协议层传输通道
- 1.2 域段
- 1.2.1 ID域段
- 1.2.2 其他关键域段
- 1.2.2.1 Address
- 1.2.2.2 Secure bit
- 1.2.2.3 Memory Attributes
- 1.2.2.4 Transaction attribute combinations
- 1.4.1 Transaction 路由
- 1.4.2 SAM 介绍
- 1.4.3 Node ID
- 1.5 节点间数据怎么传输的呢?
- 1.5.1 数据来源与数据返回方式
转自:https://blog.csdn.net/W1Z1Q/article/details/104125927
如有侵权,联系删除
1 协议层
CHI 协议层 的传输粒度是transaction,transaction 是由 packet 构成的。那么怎么理解协议层呢?既然是协议,那就是各种规定,比如数据怎么传输,数据的格式是什么样子的?所以协议层就会规定有哪些通道(channel),如何将数据进行打包及解包,这些都是协议层干的时候。
网络层做的事情主要也就是SAM做的事情,就是地址映射,指出数据向哪个节点传送。
链路层,也就是物理层,它实现了各种信号线,所有的数据传输都是要在信号线上进行的,它还会规定何时发送数据何时接收数据。协议层中的各种通道(channel) 落实到链路层之后就是一些信号线。
1.1 协议层传输通道
如上文所述,协议层会规定各种数据怎么传输,所以协议层首先会定义一些数据通路,可以理解为"高速",省道、城市道路。。。
那么我们先看下 arm 官方文档定义了哪些“车道”
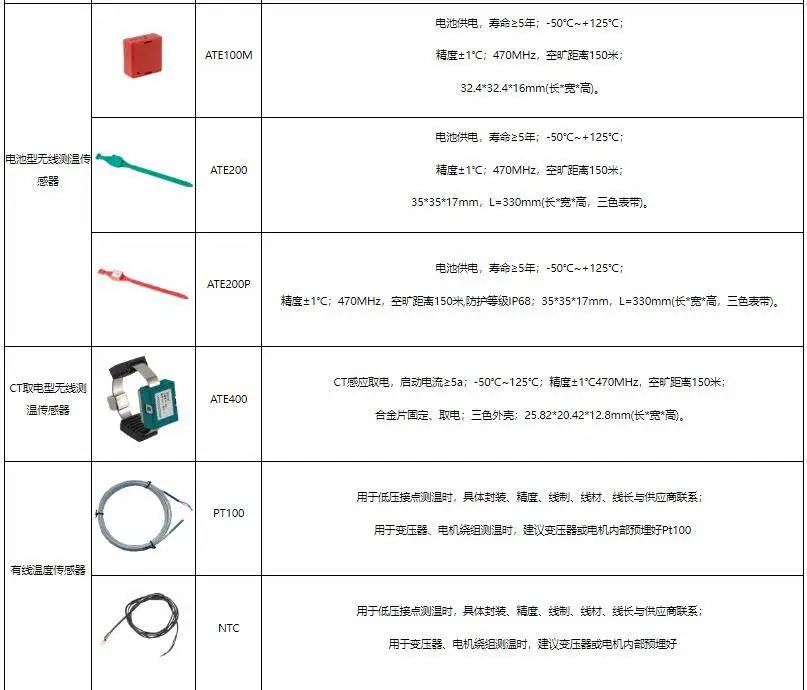
| Channel | RN channel designation | SN channel designation |
|---|---|---|
| REQ | TXREQ. Outbound Request | RXREQ. Inbound Request |
| WDAT | TXDAT. Outbound Data. Used for write data, atomic data, snoop data, forward data. | RXDAT. Inbound Data. Used for write data, atomic data. |
| SRSP | TXRSP. Outbound Response. Used for snoop response and completion acknowledge. | - |
| CRSP | RXRSP. Inbound Response Used for responses from the Completer | TXRSP. Outbound Response Used for responses from the Completer. |
| RDAT | RXDAT. Inbound Data Used for read data, atomic data. | TXDAT. Outbound Data. Used for read data, atomic data. |
| SNP | RXSNP. Inbound Snoop request. | - |
以上表 可以看到 对于 RN 6个通道全有,写数据通道、读数据通道、发响应通道、收响应通道,收SNP 通道,发REQ通道。没有发SNP通道,这个只有 HN 有。
对于 SN 只有 4个通道:收REQ通道,收数据通道,发数据通道,发 response通道。
链路层也有对应的 channel,但是它的channel不分 “收”和“发”,只是纯粹的 channel,有四种:REQ,RSP, SNP, DAT。协议层的channel 最后都是由 链路层的 channel 构成。
1.2 域段
transaction 是有许多不同的 packets 组成,而且 transaction 结构随着 packets 中的域段不同也可能不同。只有request channel和snoop channel 中的某些域段可能会影响 transaction structure。
Response packet 和 Data pacet 不会影响 transaction structure,域段上携带有packet的信息。具体每个通道包含的域段的含义可以查下CHI issueE 表2-2至2-5手册,不仔细列出了,也可以参考 ARM AMBA5 CHI 入门 12.1 – CHI 链路层详细介绍 的 1.3.1 节内容 。
1.2.1 ID域段
- Target Identifier(TgtID),Source Identifier(ScrID):用于packet在ICN上的路由;
- Transaction Identifier(TxnID),Data Buffer Identifier(DBID),Return Transaction Identifier(ReturnTxnID),Forward Transaction Identifier(FwdTxnID)用于关联同一个transaction的所有packets;
- Data Identifier(DataID),Critical Chunk Identifier(CCID):用于同一个transaction内表示特定的data packets;
- Logical Process Identifier(LPID),Stash Logical Processor Identifier(StashLPID):用于同一个Requester内表示特定的处理器单元;
- Stash Node Identifier(StashNID):该域段用于标识Stash的目的节点;
- Return Node Identifier(ReturnNID),Forward Node Identifier(FwdNID):这些域表示了返回数据响应应该送到的节点;
- Home Node Identifier:该域标识了CompAck响应应该送到的节点;
在每个packer中使用到的域段也一样,如下:
- Request packet:TgtID,SrcID,TxnID,LPID,StashNID,StashLPID,ReturnNID,ReturnTxnID;
- Response packet:TgtID,SrcID,TxnID,DBID;
- Data packet:TgtID,SrcID,TxnID,HomeNID,DBID;
- Snoop packet:SrcID,TxnID,FwdNID,FwdTxnID,StashLPID;
在看transaction Identifier field flow时,记得遵循以下规定,就很easy了:
- 所有的带有相同颜色的域段的值是一样的;
- 用箭头表明后续packets是由哪个产生的;
- 包含
*的表示第一次产生,由当前agent产生该域的原始值; - 带圆括号()的表示该域是固定值,典型如Requester发送packets的SrcID,packets到达Completer的TgtID;
- 被划掉的域段表示该域段无效;
- 可以被ICN remapped的TgtID要标识上字母R;
- 任何和当前传输不相关的域段在CHI协议域段流程图上省略了;
具体的Read transactions、Write transactions、Dataless transactions和DVMOp transaction等transactions的域段传输流程图可以看下issueC的图2-24至2-33,里面有详细的各个域段转换说明;
这里补充 下LPID 这个域段的一些知识:
CHI 协议在 Request transaction里定义了一个LPID,如果在一个Requester内部包含多个logical processes,该域段用于标识唯一Logical process。在以下transactions中,LPID必须设置为正确的值:
- For any Non-snoopable Non-cacheable or Device acess:ReadNoSnp、WriteNoSnp;
- For Exclusive accesses,that can be one of the following transaction types:ReadClean、ReadShared、ReadNotSharedDirty、CleanUnique、ReadNoSnp、WriteNoSnp;
除了以上的操作,其他transaction的LPID域也可以用于标识发送transaction的original logical processor,但是该功能在CHI中是可选的。
1.2.2 其他关键域段
Packet包含了其他的定义Transactions行为的属性信息,这些属性通过Packet域段传递到总线上,总线解析这些信息并采取相对应的操作。这些信息有:address、Secure bit、memory attributes、likely shared、snoop attributes、Do not transition to SD、data formatting。
1.2.2.1 Address
CHI协议支持
- Physical Address(PA) of 44 to 52 bits, in one bit increments
- Virtual Address(VA) of 49 to 53 bits
对于REQ和SNP packet的地址域为:
- REQ channel:Addr[(MPA-1):0]
- SNP channel:Addr[(MPA-1):3]
MPA是PA的最大值;对于REQ packet的地址位宽为44bit-52bit,SNP packet的地址位宽为41bit-49bit,地址信息在不同的message类型中有不同的用途,如下:
- 对于Read、PrefetchTgt、Datelss、Write、Atomic transactions,REQ的addr域就是要访问memory的地址信息;
- 对于Snoop request,除了SnpDVMOp,Addr[(43-51):6]用于snoop cacheline;Addr[5:4]标识transaction访问的critical chunk,CHI协议建议被snoop的cache data以wrap形式且最先critical chunk的形式返回;Addr[3]不用;
- 对于DVMOp操作,Addr信息是用于携带DVM操作的相关信息;
- PCrdRetrun transaction的地址域必须为0;
1.2.2.2 Secure bit
Request transaction可以定义Secure bit来指定该操作安全和非安全;对于Snoopable transactions,secure field可以认为是附加的地址bit,因此相当于定义了两份地址空间:安全地址空间和非安全地址空间,硬件一致性没法管理安全和非安全地址空间的一致性,因此使用时要正确处理好。Secure field可以在以下操作中使用:
- 所有Read、Dataless、Write、Atomic transaction
- PrefetchTgt transaction
- 在DVMOp和PCrdRetrun中不用,且必须为0
1.2.2.3 Memory Attributes
Memory Attributes(MemAttr)是由Early Write Acknowledge(EWA),Device,Cacheable和Allocate组成的。
1、EWA
EWA用于指示写完成信号从哪个节点返回。如果EWA置位,写完成信号可以来自中间节点(如:HN),也可以来自endpoint(最终节点),来自中间节点的完成信号必须提供同样的Comp响应来保证;如果EWA不置位,写完成响应必须来自最终节点;
注意:如果不实现EWA功能的话,那么写完成响应必须来自endpoint。
EWA是否置位根据transaction分类如下:
- ReadNoSnpSep、ReadNoSnp、WriteNoSnp、CMO、Atomic transaction可以采用任意值;
- 除了ReadNoSnpSep、ReadNoSnp、CMO、WriteNoSnp之外的所有Read、Dataless和Write transaction必须将EWA置位;
- 在DVMOp或PCrdRetrun transaction中不使用,tie为0;
- 在PrefetchTgt中不使用,为任意值;
2、Device
Device属性指示访问的memory属性是Device还是Normal。
Device memory type:
Device memory type空间必须用于地址相关性的memory空间,当然用于地址不相关性的空间也允许。
访问Device type memory空间的transaction有如下要求:
- Read transaction不能读到比要求更多的数据;
- PrefetchTgt不能访问Device memory空间;
- 读数据必须来自endpoint,不能来自同地址write操作的中间节点;
- 不能将多笔访问不同地址的请求组合成一笔,也不能将访问同一个地址的多个不同请求组合成一笔;
- 写操作不能merged;
- 访问Device memory的写操作的完成信号是来自中间节点的话,需要即使使写数据对endpoint节点可见。
访问Device memory的transaction必须使用以下类型:
- 必须使用ReadNoSnp操作去读Device memory空间;
- 必须使用WriteNoSnp或WriteNoSnpPtl去访问Device memory空间;
- CMO和Atomic操作允许访问Device空间;
- PrefetchTgt不允许访问Device memory空间,该bit不用且可以为任意值;
Normal memory type:
Normal memory type空间用于地址不相关的memory空间,不能用于地址相关的memory空间。
访问Normal memory空间在prefetching或forwarding上没有和Device type memory空间同样的约束:
- EWA的读数据可以来自同地址write操作的中间节点;
- 写操作可以merged;
任何Read、Dataless、Write、PrefetchTgt、Atomictransaction类型都可以去访问Normal memory空间。具体使用的transaction type要完成的memory操作和Snoopable属性。
3、Cacheable
Cacheable属性用于指示一笔transaction是否必须执行cache查找:
- 当Cacheable置位时,transaction必须执行cache查找;
- 当Cacheable没置位时,transaction必须访问最终节点;
Cacheable attribute的值有如下要求:
- 对于任何的Device memory transaction,必须不置位;
- 除了ReadNoSnpSep和ReadNoSnp,任何Read transaction必须置位;
- 除了CMO操作,任何Dataless操作必须置位;
- 除了WriteNoSnp和WriteNoSnpPtl,任何write transaction都必须置位;
- 在ReadNoSnpSep、ReadNoSnp、WriteNoSnpFull、WriteNoSnpPtl访问Normal memory空间时,可以为任何值;
- 在CMO和Atomic transactions中可以为任意值;
- 在DVMOp和PCrdRetrun transaction中必须为0;
- 在PrefetchTgt中不会用,可以为任意值;
注意:如果一笔transaction的Cacheable可以设置为任意值,通常情况下是有page table attributes决定的。
4、Allocate
Allocate attribute是一种cache缓存分配指示,它指示一笔transaction是否推荐分配cache缓存,具体如下:
- 如果Allocate置位,出于性能考虑,建议该笔transaction的数据应该被分配到cache中,但也可以不分配;
- 如果Allocate不置位,出于性能考虑,建议该笔transaction的数据不应该被分配到cache中,但其实也可以分配的;
Allocate attribute值有如下要求:
- 可以在任意Cacheable置位的transaction中置位;
- WriteEvictFull操作必须置位;如果WriteEvictFull的Allocate没有置位,RN可以将其转换为Evict操作;
- 对于Device memory transaction必须不能置位;
- 对于Normal Non-cacheable memory transaction中不能置位;
- 在DVMOp、PCrdRetrun和Evict操作中不使用,必须设置为0;
- 在PrefetchTgt中不使用,可以设置为任意值;
5、Propagation of Attr
MemAttr属性在一笔transaction从HN发往SN时必须要保留,有一种情况除外:当知道downstream memory是Normal类型,那Device域值要设置为0来知识Normal类型;
SnpAttr attribute bit值在HN到SN中不需要保留,且必须设置为0;
由于HN的Prefetch预取或者SystemCache的eviction操作下产生的ReadNoSnp和WriteNoSnp transaction,相关属性设置如下:
- MemAttr中的EWA、Cacheable、Allocate必须全部设置为1;
- Device属性必须设置为0指示是Normal type;
- SnpAttr属性必须设置为0指示是Non-snoopable;
1.2.2.4 Transaction attribute combinations
1.4.1 Transaction 路由
- 一个RN 会产生 transaction(read,write,maintenance)给 HN;
- HN 接收,并对 RN 发来的请求进行排序,产生 transaction 给 SN;
- SN 接收这些请求,返回数据或者响应。
Transaction如何在系统中的节点间路由呢?
- 首先,系统中的每个节点必须有一个节点号(Node ID)。
- 系统中的每个 RN 和 HN 内部要有一个系统地址映射(System Address Map,以后简称SAM),负责把地址转换成目标节点的ID。
RN 的 SAM 负责把物理地址转换成 HN 的 ID;而 HN 的 SAM 需要把物理地址转换成 SN 的 ID。
1.4.2 SAM 介绍
系统中的每个组件都被分配一个唯一的节点ID。CHI使用系统地址映射(SAM)将物理地址转换为目标节点ID。
为了能够确定发出请求的目标节点ID,每个RN和HN都必须具有SAM。
以下图示展示了RN SAM将物理地址映射到HN节点ID,以及HN SAM将物理地址映射到SN节点ID:
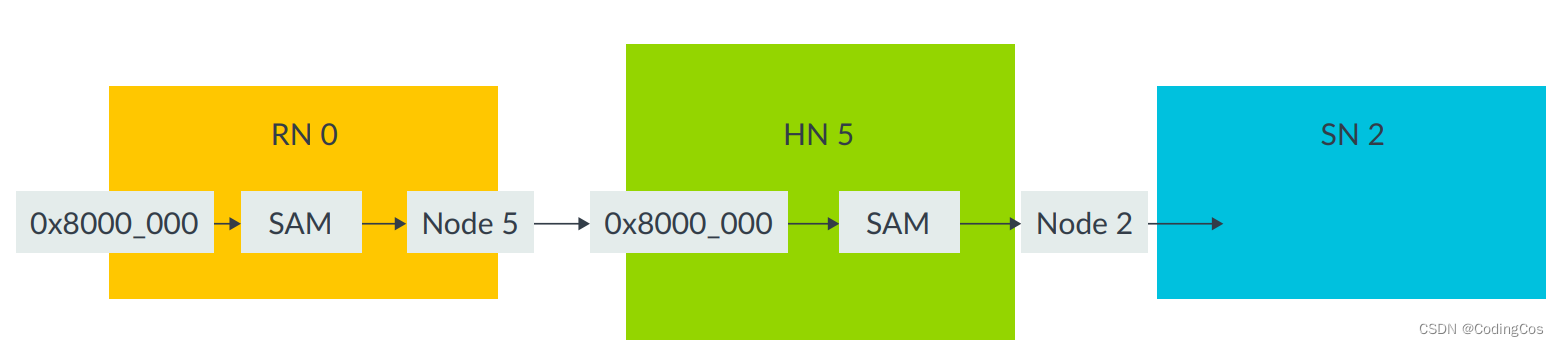
在这个图示中,事件的顺序如下:
- 地址为
0x8000_0000的事务通过节点0中的 RN SAM; - RN SAM确定目标为节点 5;
- 事务路由到节点 5 的HN;
- HN接收到事务;
- HN通过其HN SAM传递地址,并确定目标为节点2;
- 事务被路由到节点 2 的 SN。
RN SAM 必须满足以下要求:
- 它必须完全描述整个系统地址空间;
- 任何不对应于物理组件的物理地址必须映射到一个可以提供适当错误响应的节点;
- 所有 RN 必须对 RN SAM有一致的视图。例如,无论是哪个RN发出的,地址
0xFF00_0000必须始终指向同一个HN。
注:SAM的确切格式和结构完全由实现定义。CHI规范没有提供关于如何将地址映射到节点ID的指导。
再看一个简单例子:

RN0根据内部的 SAM 知道要把请求发给HN0(TgtID是HN0,SrcID是RN0);HN0在通过内部的SAM知道要继续发给SN0(ReturnNID是RN0);SN0接收请求,返回数据(HomeNID是HN0,TgtID从HN0的ReturnNID而来);RN0接收到SN0的数据响应,返回CompAck给HN以结束此次transaction(TgtID是HN0,从HomeNID而来)。
remapping of the TgtID

只有TgID做了一次remap,从Home Node0 remap 到了Home Node1, 其它的都和上面传输一样。
Flow with interconnect-based SAM and Retry request:

1.4.3 Node ID
SAM 必须可以对系统的全部地址空间进行解码。CHI 协议建议:对于没有相应物理组件的地址访问,都发送给一个agent,该agent可以对这些无用地址的访问提供恰当的error响应。
SAM 的结构和格式是由具体实现决定的,在CHI协议中并没有规定 SAM 实现方式。每一个连接到 ICN 端口的组件都会被分配一个node ID,用于标识 ICN上packets 路由的源节点和目的节点。一个端口可以有多个 node ID,但是一个node ID只能分配给一个端口,通俗点讲就是这个ID必须是唯一的,路由的时候不能有歧义。CHI协议支持的 NodeID字段宽度在7~11bits之间,由具体实现决定,且一个系统中所有组件的NodeID字段宽度必须一样,至于每个组件的 NodeID 值也是由具体实现决定的。
1.5 节点间数据怎么传输的呢?
与 ACE 相比,CHI 使用不同的通道:
- 请求(REQ):发送读和写请求、缓存维护请求和DVM请求;
- 响应(RSP):发送各种类型消息的完成响应,范围从写和缓存管理响应到无数据监听响应和操作完成确认;
- 监听(SNP):发出监听或发送DVM操作数据传输消息和标记为DAT的,发送写和读数据,以及带数据的监听响应。
下图显示了 RN-F上CHI 请求者接口上的通道:

注:以TX字母为前缀的通道用于发送消息,以 RX 字母为前缀的通道用于接收消息。
当 RN-F 发出读请求时,它在其 TXREQ 通道上发送请求;
当读数据返回时,RN-F 在其 RXDAT 通道上接收数据。
每个节点上的 TX 信号连接到目标节点上的 RX 信号。
RN-F Interface:

RN-D Interface:

RN-I Interface:

SN-F Interface:

在 SNP 通道上发生以下约束:
- 只有HN-F和 MN 在SNP通道上发出消息;
- RN-F 仅在SNP通道上接受监听;
- MN 仅在SNP通道上接受DVM消息监听。
1.5.1 数据来源与数据返回方式
在基于CHI的系统中,读请求的数据可以来自不同的地方,如下图所示,这些源有:

- Cache within ICN;
- Slave Node;
- Peer RN-F。
对于 RN-F 或 SN-F 返回的读数据,可以发送给 Home Node,Home Node 再转发数据给原始的 Requester Node;也可以直接跳过Home Node,返回数据给原始 Requester Node,这样可以减少读数据的 latency。
有以下两种直接返回数据方式:
- Direct Memory Transfer(DMT):SN 直接返回数据给原始的 Requester;
- Direct Cache Transfer(DCT):Peer RN-F 字节返回数据给原始 Requester;
在 DCT中,数据提供者需要通知 Home Node 它已经将数据发给原始 Requester Node了,在某些情况下,数据提供者也必须发送一份拷贝数据给Home Node。
推荐阅读:
https://aijishu.com/a/1060000000220025
通过 node ID 可以在 ICN(Interconnect) 路由,RN 和 HN,HN 和 SN之间有不同的通道,每个通道有自己字段(fields),对于 transaction request,data,snoop request 和 response来说,包含的字段不一样。
从上面可以知道 所有协议消息都以 Flit 的形式发送,Flit是一种打包的控制字段和标识符集合,用于传递协议消息。
在 Flit 中发送的一些控制字段包括操作码、内存属性、地址、数据和错误响应。每个通道需要不同的 Flit 控制字段。例如,请求通道上用于读或写的Flit需要一个地址字段,而数据通道上的Flit需要数据和字节使能字段。
与PCIe或以太网协议中的字段不同,Flit中的字段不会在多个数据包上串行化。相反,它们是并行发送的。
在基于CHI的系统中,处理器的读请求可以通过很多种来源得到数据,比如:互连中的cache(一般是last level cache),SN(存储设备)或者其它的RN-F(拥有该数据的缓存行)。

对于RN-F或SN返回的读数据,可以发送给HN,HN再转发数据给原始的Requester;也可以直接跳过HN,返回数据给原始Requester,这样可以减少读数据的延时。有以下两种直接返回数据方式:
- Direct Memory Transfer(DMT):SN直接返回数据给原始的 Requester
- Direct Cache Transfer(DCT):其它RN-F直接返回数据给原始 Requester
在DCT中,数据提供者需要通知HN它已经将数据发给原始Request了,在某些情况下,数据提供者也必须发送一份拷贝数据给HN。
我们来看看CHI的 transaction flow。以下图的 snoopable read DMT为例:
- Requester通过REQ通道发送一个snoopableread request;
- ICN通过REQ通道发送一个ReadNoSnp给相应的SN;
- SN,作为completer,在RDAT通道上,使用CompData将读取的数据和任何关联的事务响应直接转发给的请求者,协议规定,completer必须在接收request之后才能发送CompData;
- Requester通过SRSP通道使用CompAck返回一个响应给ICN,表示交易完成。协议规定,requester至少需要接收到一个CompData包以后才能发送CompAck。

对于DMT,协议还有一些限制如下:

再看一个DCT的例子,流程和DMT差不多: - Requester过REQ通道发送一个snoopableread request;
- ICN通过SNP通道发送一个Snp[*]Fwdrequest给RN-F
- 该RN-F作为completer,在RDAT通道上,使用CompData将读取的数据和任何关联的事务响应直接转发给的请求者;
- 该RN-F通过SRSP通道,返回一个SnpRespFwded给ICN,表示已经把读数据发给了requester。协议规定,completer必须在接收snoop之后才能发送CompData;
- Requester通过SRSP通道使用CompAck返回一个响应给ICN,表示交易完成。协议规定,一旦接收到读取数据的第一个数据包,就可以发送CompAck。

对于DMT和DCT以外的读数据传输,RN得到的数据都是来自HN的。


对于携带数据的transaction,其数据可以分在几个包(packet)中传输,需要的包的个数取决于两点:要传输的数据字节数,和数据总线宽度。每个包中的字节数取决于数据总线宽度。
推荐阅读:
https://blog.csdn.net/W1Z1Q/article/details/104125927