前言
在微服务中,随着服务越来越多,对调用链的分析越来越复杂。如何能够分析调用链,定位微服务中的调用瓶颈,并对其进行解决。
本篇博客介绍springCloud中用到的链路追踪的组件,Spring Cloud Sleuth和Zipkin,介绍基本的概念,并给出了一个入门的使用案例。
目录
- 前言
- 引出
- 链路追踪
- 有啥用?
- Spring Cloud Sleuth
- Zipkin
- 入门案例
- 1.启动zipkin 的jar包
- 2.引入依赖
- 3.进行配置
- 4.启动项目
- 5.发送请求查看zipkin
- 标记:Linux运行失败
- 总结
引出
1.链路追踪的组件,Spring Cloud Sleuth和Zipkin,介绍基本的概念;
2.给出了一个入门的使用案例;
链路追踪
有啥用?
在微服务中,随着服务越来越多,对调用链的分析越来越复杂。
出现问题:
- 1.微服务之间的调用错综复杂,用户发送的请求经历哪些服务,调用链不清楚,没有一个自动化的工具类来维护调用链;
- 2.无法快速定位调用链中哪个环节出了问题;
- 3.无法快速定位调用链中哪个环节比较耗时;
Spring Cloud Sleuth
Sleuth是SpringCloud的子项目,全称SpringCloud-Sleuth,提供分布式系统中链路追踪解决方案,同类产品还有Cat由大众点评开源,基于java开发的实时应用监控平台,包括实时应用监控、业务监控。集成方案是通过代理码埋点的方式来实现监控。
Spring Cloud Sleuth采用的是Google的开源项目Dapper的专业术语。
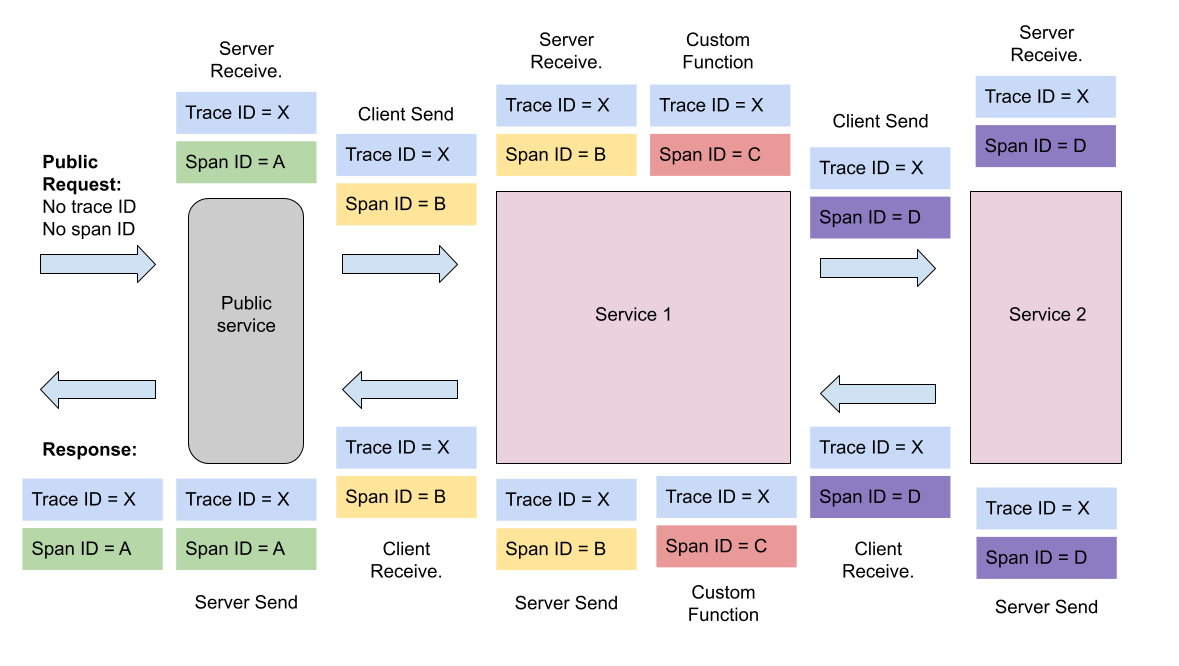
- Span:基本工作单元,发送一个远程调度任务 就会产生一个Span,Span是一个64位ID唯一标识的,Trace是用另一个64位ID唯一标识的,Span还有其他数据信息,比如摘要、时间戳事件、Span的ID、以及进度ID。
- Trace:一系列Span组成的一个树状结构。请求一个微服务系统的API接口,这个API接口,需要调用多个微服务,调用每个微服务都会产生一个新的Span,所有由这个请求产生的Span组成了这个Trace。
- Annotation:用来及时记录一个事件的,一些核心注解用来定义一个请求的开始和结束 。这些注解包括以下:
- cs - Client Sent -客户端发送一个请求,这个注解描述了这个Span的开始
- sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络传输的时间。
- ss - Server Sent (服务端发送响应)–该注解表明请求处理的完成(当请求返回客户端),如果ss的时间戳减去sr时间戳,就可以得到服务器请求的时间。
- cr - Client Received (客户端接收响应)-此时Span的结束,如果cr的时间戳减去cs时间戳便可以得到整个请求所消耗的时间。

运行时后台的日志

1.span属性
代表了一组基本的工作单元。为了统计各个处理单元的延迟,当请到达各个服务组件的时候,也通过一个唯一标识(SpanId)来标记它的开始、具体过程和结合。通过SpanId的开始和结束时间戳,就能统计该Span的调用时间,除此之外,还可以获取如事件的名称、请求信息等元数据。简单来说,服务调用链中,每一个服务都是一个Span,每个Span都有自己的spanId属性、parentId属性、traceId属性
2.trace
由一组traceId相同的Span串联形成的一个树状结构。为了实现请求跟踪,当请求到达分布式系统的入口端点时,需要服务跟踪框架为该请求创建一个唯一标识(traceId),同时在分布式系统内部流转的时候,框架始终保持传递该唯一值,直到整个请求的返回。那么就可以使用该唯一标识将所有请求串联起来,形成一条完整的请求链路。
简单来说,具有相同traceId的Span,服务调用串联起来的树状结构。
但是这些都不直观,所以需要用Zipkin
Zipkin
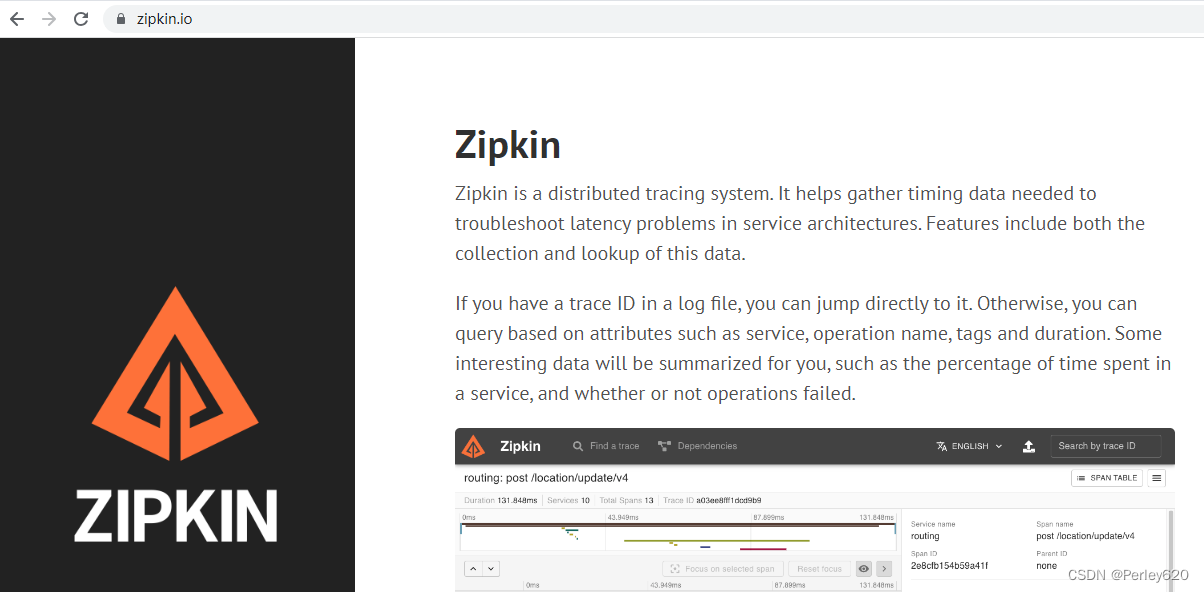
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,显示了多少跟踪请求通过每个服务,该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下来的测试为方便直接采用In-Memory方式进行存储,生产推荐Elasticsearch
官网:https://zipkin.io/
入门案例
1.启动zipkin 的jar包
java -jar

2.引入依赖

<!-- Sleuth是SpringCloud的子项目,全称SpringCloud-Sleuth,提供分布式系统中链路追踪解决方案-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<!-- Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.5.RELEASE</version>
</dependency>
3.进行配置

spring:
# zipkin配置
zipkin:
base-url: http://127.0.0.1:9411 # zipkin服务地址
discovery-client-enabled: false # 禁止zipkin把自己当做nacos-client向nacos-server注册
# sleuth配置
sleuth:
sampler:
rate: 100 # sleuth抽样率默认是10%,设置为100表示100%请求上报zipkin
4.启动项目
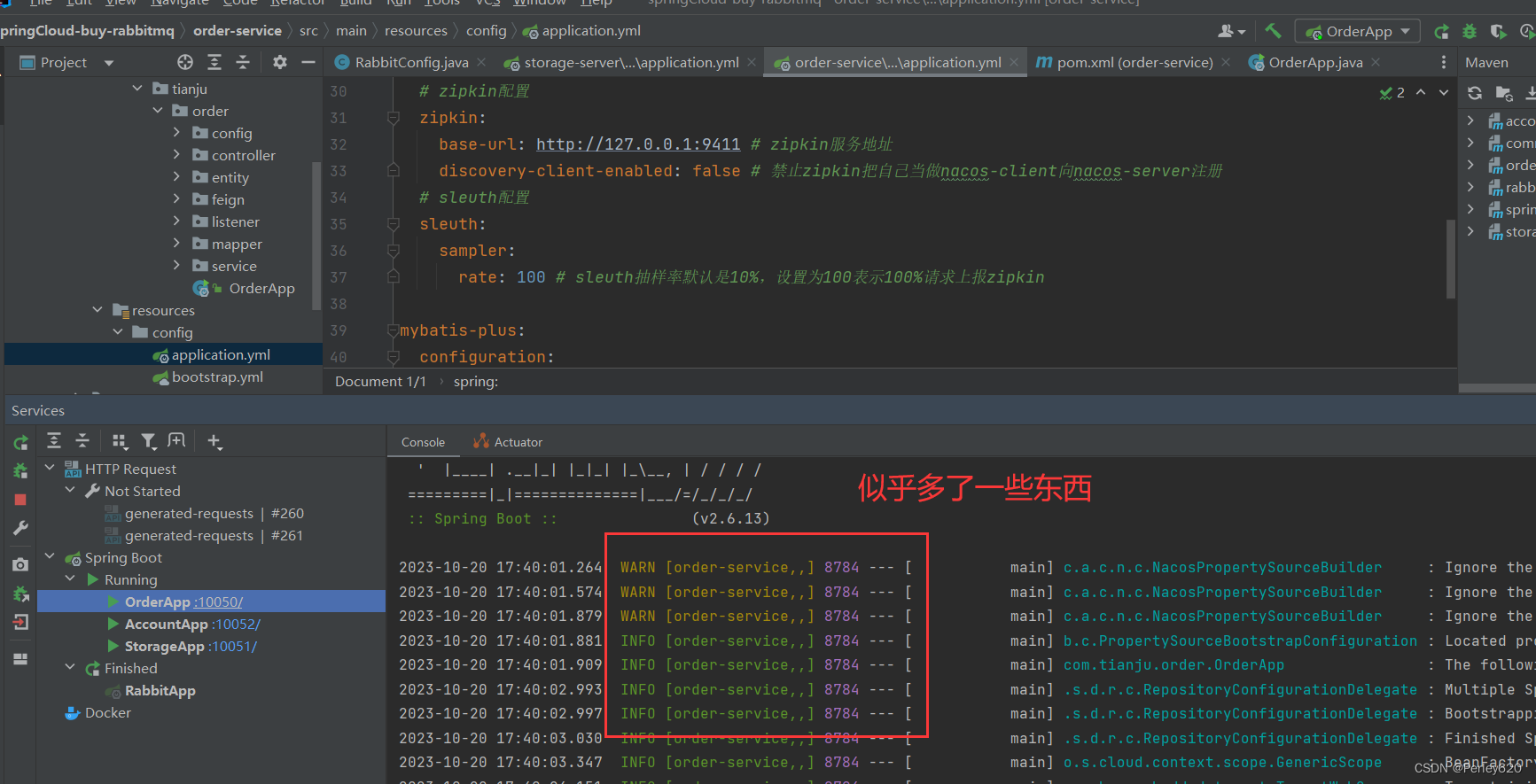
如果把依赖注释掉:
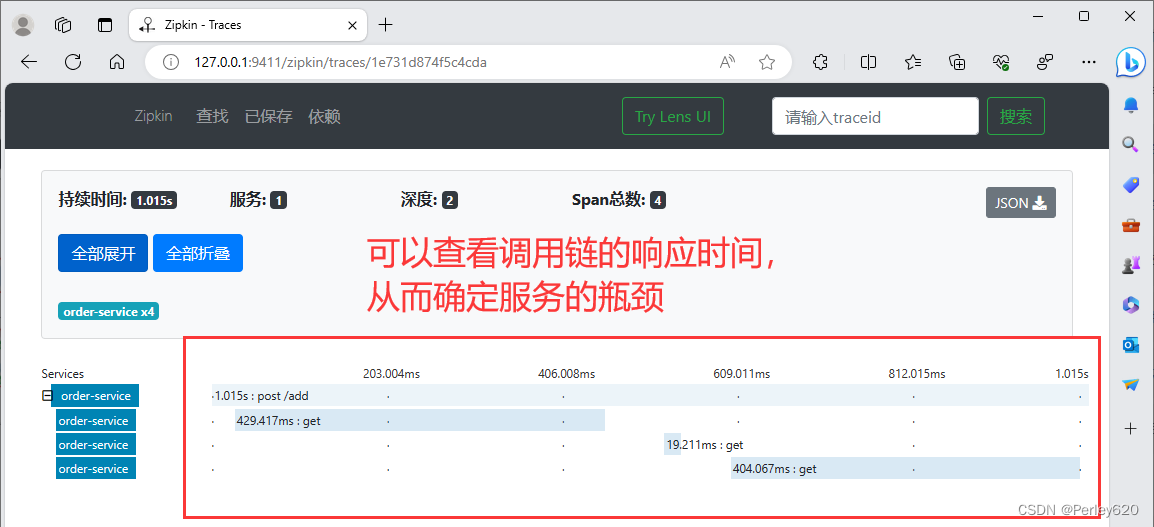
5.发送请求查看zipkin

查看调用链的响应时间,从而确定服务的瓶颈
点击可以更详细地查看

标记:Linux运行失败

启动了zipkin
开放了端口

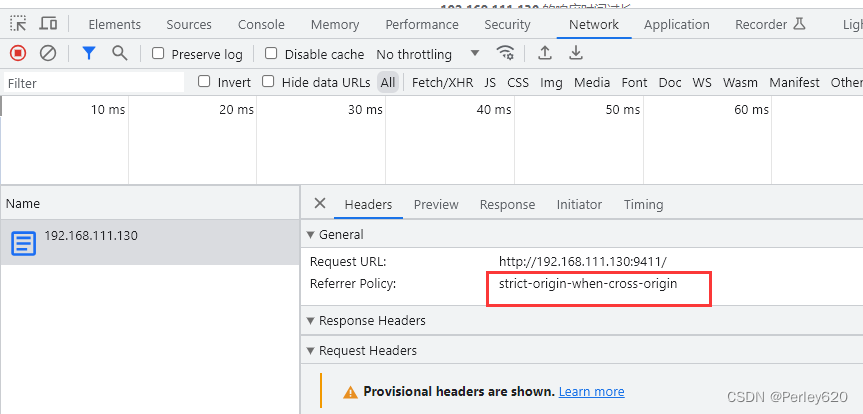
访问失败,似乎是跨域的问题
总结
1.链路追踪的组件,Spring Cloud Sleuth和Zipkin,介绍基本的概念;
2.给出了一个入门的使用案例;