【底层服务/编程功底系列】「大数据算法体系」带你深入分析MapReduce算法 — Shuffle的执行过程
- Shuffle是什么
- Shuffle的流程处理
- map任务的执行流程
- reduce任务的执行流程
- Shuffle过程分析和优化
- map任务深入分析
- 细化步骤分析
- 1. 数据分片读取
- 2. 分配计算Reduce服务
- Partitioner分区控制
- 3. 内存缓冲区(内存数据溢写+机制)
- 内存数据溢写(Spill)
- 数据合并Combine/Reduce
- 4. 数据溢写+持久化磁盘
- Reduce任务执行
- 1. Copy复制过程
- 2. Merge阶段
- 3. Reducer阶段
Shuffle是什么
Shuffle作为MapReduce的核心步骤,扮演着重要的角色。对于深入理解MapReduce,对Shuffle的了解至关重要。然而,我发现在阅读相关资料时常常感到困惑,很难理清逻辑,反而越读越迷糊。最近,我为了进行MapReduce作业性能调优,不得不深入研究代码以了解Shuffle的运行机制。
Shuffle这个词通常意味着洗牌或弄乱,对于Java API中的Collections.shuffle(List)方法,我们可能更为熟悉。它会随机打乱列表中的元素顺序。然而,在MapReduce中,Shuffle有着不同的含义和作用。
Shuffle的流程处理
在MapReduce中,Shuffle是指将Map任务的输出结果有效地传输到Reduce端的过程。你可以将Shuffle理解为描述数据从Map任务输出到Reduce任务输入的这一过程。
map任务的执行流程
如果你对MapReduce中的Shuffle概念还不太了解,让我们来看一张图来帮助理解:

Shuffle的主要目标是将Map任务的输出结果按照键(Key)进行分组,并将相同键的值(Value)聚合在一起,以便在Reduce任务中进行进一步的处理。这个过程涉及网络传输和数据排序,确保相同键的数据被正确地发送到相同的Reduce任务。
reduce任务的执行流程
通过Shuffle,Map任务的输出结果可以被合理地分发到Reduce任务中,以便进行后续的数据处理和计算。Shuffle的实现需要考虑数据传输的效率和数据的排序,以提高整个MapReduce作业的性能和效率。

在分布式集群环境中,MapReduce任务通常在不同的节点上执行。特别是在Reduce阶段,需要从其他节点拉取Map任务的结果。当集群中同时运行多个作业时,任务的执行会对网络资源造成严重的负担。尽管这种网络消耗是正常的,但我们可以尽量减少不必要的消耗。此外,在节点内部,相对于内存而言,磁盘IO对作业完成时间的影响也是显著的。
Shuffle过程分析和优化
在设计Shuffle过程时,我们的目标是完整地从Map任务端拉取数据到Reduce任务端,并尽可能减少对带宽的不必要消耗,同时减少磁盘IO对任务执行的影响。我们希望优化的重点是减少数据的传输量,并尽量利用内存而不是磁盘。
map任务深入分析
整个流程可以简化为四个步骤。首先,每个Map任务都有一个内存缓冲区,用于存储Map的输出结果。当缓冲区接近满时,需要将缓冲区的数据以临时文件的形式存储到磁盘上。其次,当整个Map任务完成后,会对磁盘上该Map任务生成的所有临时文件进行合并,生成最终的正式输出文件。最后,Reduce任务会从这些输出文件中拉取数据进行处理。

如果与您所了解的Shuffle过程有所不同,请不吝指出。我将以WordCount作为示例,并假设有8个Map任务和3个Reduce任务。从上图可以看出,Shuffle过程涉及Map和Reduce两个端点,因此我将分两部分展开讨论。
细化步骤分析
在MapReduce中,Shuffle过程涉及多个细节和子步骤。

下面是对这些细节的总结:
1. 数据分片读取
在Map任务执行时,它的输入数据来自HDFS的数据块(block)。在MapReduce的概念中,Map任务只读取数据切片(split)。数据切片与数据块的对应关系可能是多对一的关系,默认情况下是一对一的关系。以WordCount示例为例,假设Map的输入数据都是像"aaa"这样的字符串。
在Map任务中,它会从HDFS的数据块中读取输入数据。数据切片与数据块的对应关系可能是多对一的关系,这意味着一个数据切片可能对应多个数据块。然而,在默认情况下,Map任务会一对一地读取数据切片和数据块。
以WordCount示例为例,假设Map任务的输入数据都是像"aaa"这样的字符串。这意味着每个数据切片中只包含一个字符串,而这个字符串对应一个数据块。因此,Map任务会读取每个数据切片中的字符串,并进行相应的处理和计算。
2. 分配计算Reduce服务
经过Mapper运行后,我们得到了这样一个键值对:键是"aaa",值是数值1。在当前的Map阶段,我们只进行了加1的操作,真正的结果合并是在Reduce任务中进行的。前面我们已经知道这个作业有3个Reduce任务,现在需要决定将"aaa"交给哪个Reduce任务处理。
Partitioner分区控制
MapReduce提供了Partitioner接口,它的作用是根据键或值以及Reduce任务的数量来决定将输出数据交给哪个Reduce任务处理。默认情况下,Partitioner会对键进行哈希运算,然后取模Reduce任务的数量。这种默认的取模方式旨在平均分配Reduce任务的处理能力。如果用户有特殊需求,可以自定义并将其设置到作业中。
在我们的示例中,经过Partitioner处理后,"aaa"返回0,也就是这对值应该交给第一个Reducer处理。接下来,需要将数据写入内存缓冲区中。缓冲区的作用是批量收集Map的结果,以减少磁盘IO的影响。键值对以及Partition的结果都会被写入缓冲区。在写入之前,键和值都会被序列化为字节数组。
3. 内存缓冲区(内存数据溢写+机制)
内存缓冲区是有大小限制的,默认为100MB。当Map任务的输出结果很大时,可能会超出内存的限制,因此需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个将数据从内存写入磁盘的过程被称为Spill,中文可译为"溢写",字面意思很直观。
内存数据溢写(Spill)
Spill过程由单独的线程完成,不会阻塞写入Map结果的线程。为了确保Spill过程不会阻止Map结果的输出,整个缓冲区有一个溢写的比例(spill.percent)。默认情况下,这个比例为0.8,也就是当缓冲区的数据达到阈值(缓冲区大小 * 溢写比例 = 100MB * 0.8 = 80MB)时,Spill线程启动,锁定这80MB的内存,执行溢写过程。Map任务的输出结果仍然可以写入剩余的20MB内存,互不影响。
数据合并Combine/Reduce
当溢写线程启动后,需要对这80MB空间内的键进行排序(Sort)。排序是MapReduce模型的默认行为,它对序列化的字节进行排序。
在溢写过程中,我们需要将具有相同键的键值对合并在一起,以减少与分区相关的索引记录。这样可以减少发送到不同Reduce端的数据量。
在合并数据时,有些数据可能会出现重复的键。例如,在WordCount示例中,我们只是简单地统计单词出现的次数。如果在同一个Map任务的结果中有很多个相同的键,我们应该将它们的值合并在一起。这个过程被称为Combine,也可以称为Reduce。
如果客户端设置了Combiner,它会在Map端对具有相同键的键值对的值进行合并,以减少写入磁盘的数据量。Combiner会优化MapReduce的中间结果,因此在整个模型中会被多次使用。然而,使用Combiner时需要注意,它的输出应该与Reducer的输入键值对类型完全一致,并且不会改变最终的计算结果。因此,Combiner通常用于累加、最大值等不影响最终结果的场景。使用Combiner时需要谨慎,如果使用得当,它可以提高作业的执行效率,否则可能会影响最终结果的准确性。
4. 数据溢写+持久化磁盘
每次溢写都会在磁盘上生成一个溢写文件。如果Map的输出结果非常大,可能会发生多次溢写,导致磁盘上存在多个溢写文件。当Map任务真正完成时,内存缓冲区中的数据也会全部溢写到磁盘上形成一个溢写文件。最终,磁盘上至少会有一个溢写文件存在(如果Map的输出结果很少,那么在Map执行完成时只会产生一个溢写文件)。由于最终只需要一个文件,因此需要将这些溢写文件进行合并,这个过程被称为Merge。
Merge的过程是将多个溢写文件归并到一起。以前面的例子为例,对于键"aaa",从一个Map任务读取的值是5,从另一个Map任务读取的值是8。因为它们具有相同的键,所以需要将它们合并成一个组(group)。对于"aaa"来说,合并后的结果可能是这样的:{ “aaa”, [5, 8, 2, …] },数组中的值是从不同的溢写文件中读取出来的,然后将这些值相加。需要注意的是,由于Merge是将多个溢写文件合并成一个文件,所以可能会存在相同的键。在这个过程中,如果客户端设置了Combiner,也会使用Combiner来合并相同键的值。
Reduce任务执行
在Map端的工作完成后,最终生成的文件存放在TaskTracker的本地目录中。每个Reduce任务会通过RPC从JobTracker获取关于Map任务是否完成的信息。当Reduce任务收到通知,得知某个TaskTracker上的Map任务已经完成时,Shuffle的后半段过程开始启动。借鉴官网的一幅图,进行归纳和总结介绍,如下图所示。
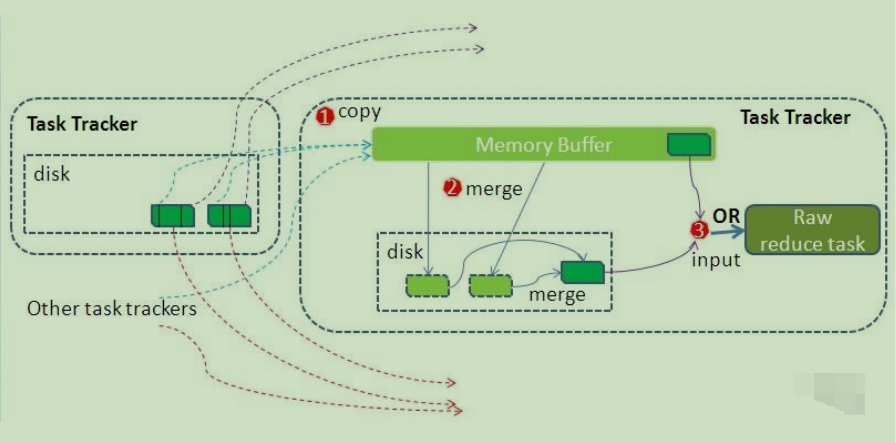
如同Map端的细节图一样,Shuffle在Reduce端的过程也可以用图上标明的三个点来概括。在Reduce端,主要的工作是拉取数据、合并数据,并不断重复这个过程。在Reducer真正开始运行之前,所有的时间都用于拉取数据和进行合并。
1. Copy复制过程
在Copy过程中,Reduce进程会启动一些数据复制线程(Fetcher),通过HTTP方式从Map任务所在的TaskTracker请求获取Map任务的输出文件。由于Map任务已经完成,这些文件由TaskTracker管理在本地磁盘中。
2. Merge阶段
在Merge阶段,类似于Map端的合并操作,但这里的合并是针对不同Map端复制过来的数据。复制过来的数据会先放入内存缓冲区中,这个缓冲区的大小基于JVM的堆大小设置,并且应该将大部分内存分配给Shuffle阶段使用。需要强调的是,Merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下,第一种形式不启用,这可能会让人感到困惑。
当内存中的数据量达到一定阈值时,会启动内存到磁盘的合并操作。与Map端类似,这也是溢写的过程。如果设置了Combiner,它也会在这个过程中启用。然后,在磁盘上生成多个溢写文件。第二种合并方式会持续运行,直到没有Map端的数据为止,然后启动第三种磁盘到磁盘的合并方式,生成最终的输出文件。
3. Reducer阶段
在Reducer阶段,经过不断的合并操作,最终会生成一个"最终文件"作为Reducer的输入。这里加上引号是因为这个文件可能存在于磁盘上,也可能存在于内存中。我们当然希望它存放在内存中,直接作为Reducer的输入。然而,默认情况下,这个文件是存放在磁盘中的。关于如何将这个文件放置在内存中,以及相关的性能优化,将在后续的性能优化篇中进行讨论。
当Reducer的输入文件确定后,整个Shuffle过程最终结束。然后,Reducer开始执行,将结果存放到HDFS上。


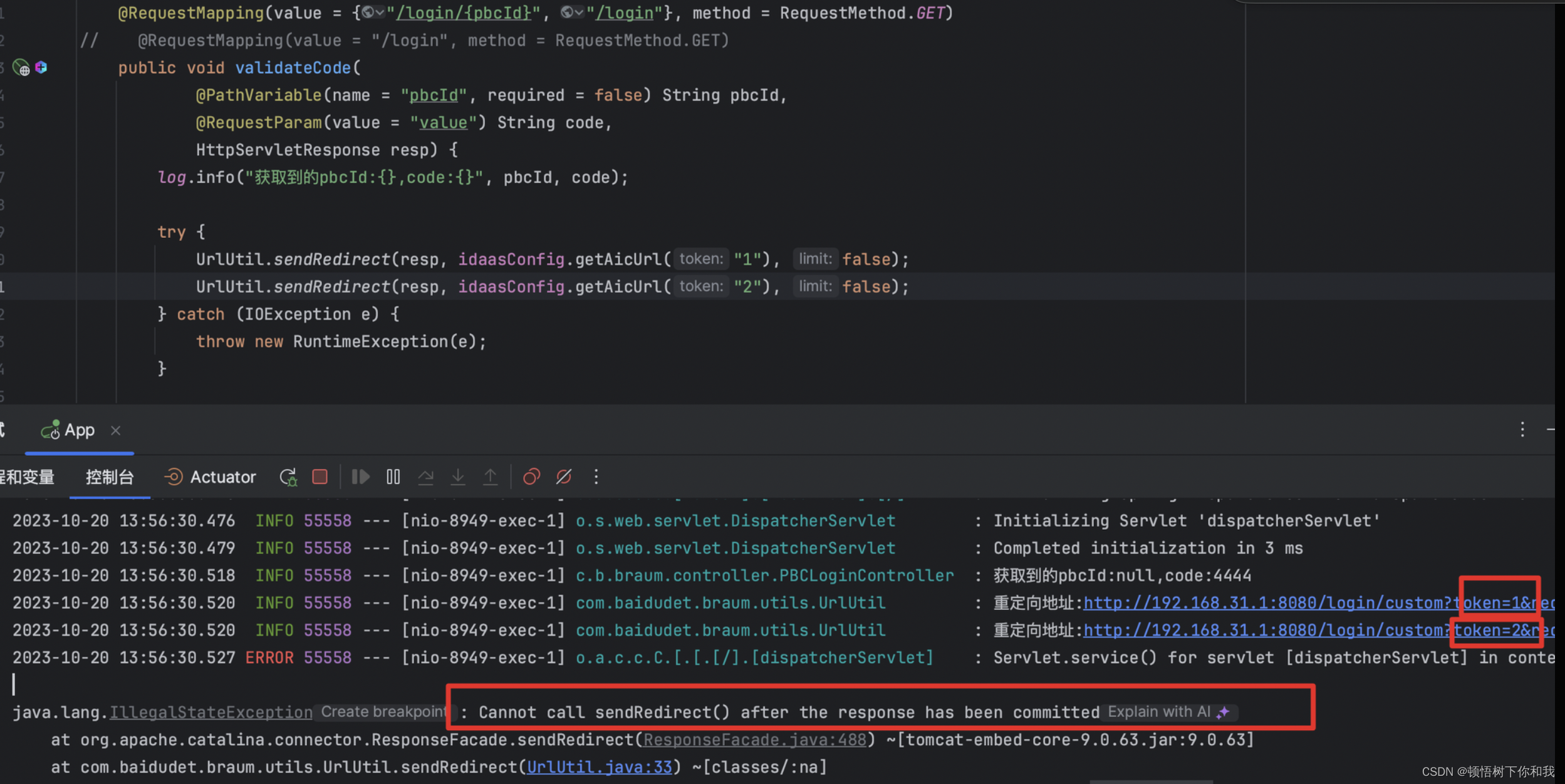



![[HCTF 2018] Hide and seek(buuctf),Unzip(ctfshow)](https://img-blog.csdnimg.cn/441d810f85894cb2bbc77638858b80ef.png)