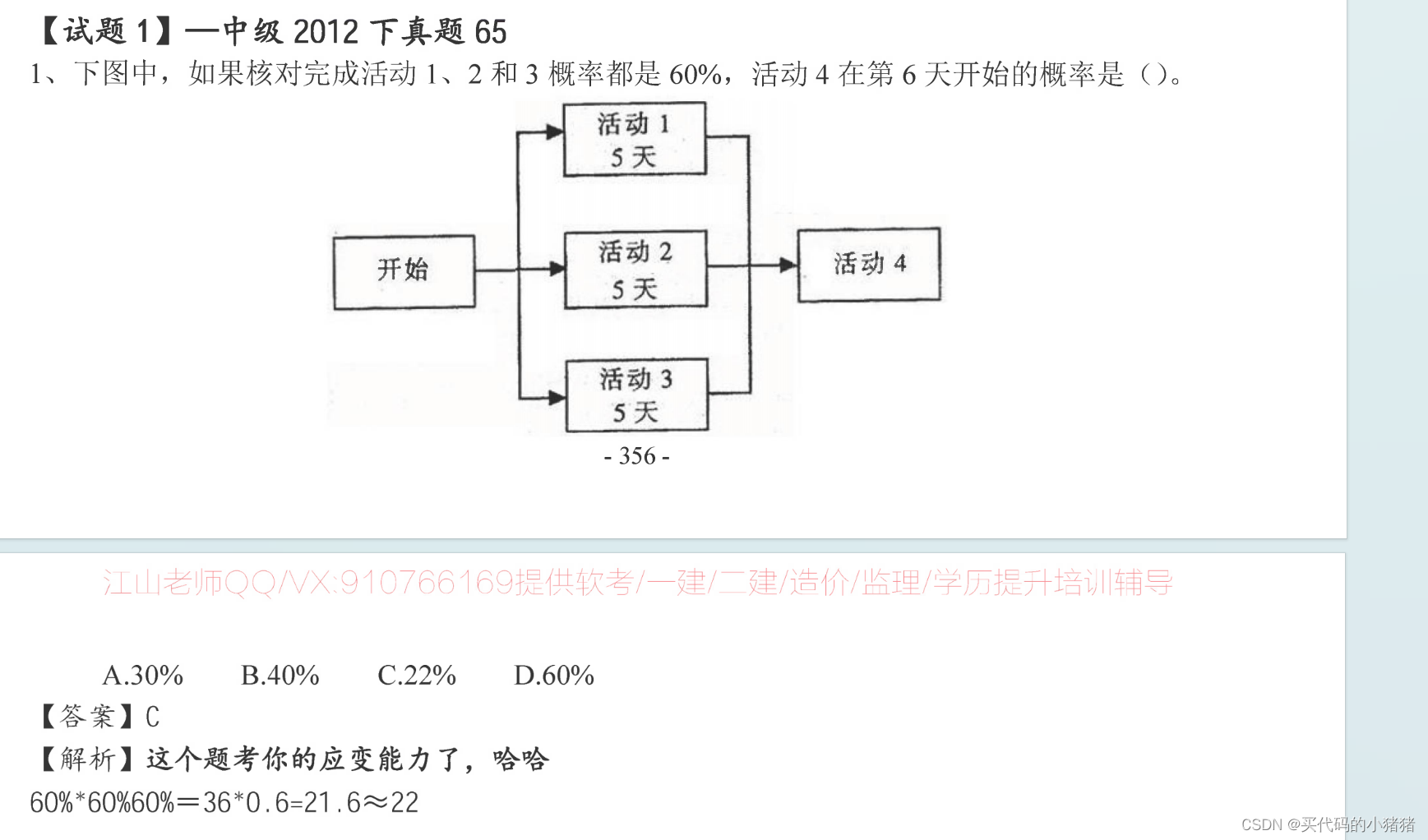
QTextCodec理论总结
- 一、概述
- 二、编码支持
- 三、使用
- 四、创建自己的编解码器类
一、概述
QTextCodec 是Qt提供的一个管理字符串编码的功能,他可以在不同编码方式中来回转换,在文件读取的时候、格式编码转换的时候用处很大。Qt使用Unicode 编码来存储、绘制和操作字符串。在许多情况下,我们可能希望处理使用不同编码的数据。例如,大多数日本文档仍然存储在Shift-JIS或ISO 2022-JP中,而俄罗斯用户的文档通常存储在KOI8-R或Windows-1251中。
Qt提供了一组QTextCodec类来帮助将非Unicode格式转换为Unicode格式。也提供了创建自己的编解码器类。

二、编码支持
支持的编码有:
- Big5
- Big5-HKSCS
- CP949
- EUC-JP
- EUC-KR
- GB18030
- HP-ROMAN8
- IBM 850
- IBM 866
- IBM 874
- ISO 2022-JP
- ISO 8859-1 to 10
- ISO 8859-13 to 16
- Iscii-Bng, Dev, Gjr, Knd, Mlm, Ori, Pnj, Tlg, and Tml
- KOI8-R
- KOI8-U
- Macintosh
- Shift-JIS
- TIS-620
- TSCII
- UTF-8
- UTF-16
- UTF-16BE
- UTF-16LE
- UTF-32
- UTF-32BE
- UTF-32LE
- Windows-1250 to 1258
三、使用
如果Qt是在启用ICU支持的情况下编译的,那么ICU支持的大多数编解码器也将可用于应用程序。
QTextCodecs可以使用如下方式将一些本地编码的字符串转换为Unicode。假设我们有一些用俄语KOI8-R编码编码的字符串,并希望将其转换为Unicode。这样做的简单方法是:
QByteArray encodedString = "...";
QTextCodec *codec = QTextCodec::codecForName("KOI8-R");
QString string = codec->toUnicode(encodedString);
在此之后,string保存转换为Unicode的文本。将字符串从Unicode转换为本地编码也很简单:
QString string = "...";
QTextCodec *codec = QTextCodec::codecForName("KOI8-R");
QByteArray encodedString = codec->fromUnicode(string);
要读取或写入各种编码的文件,请使用QTextStream及其setCodec()函数。最好显式的设置一下这些编码的格式。
if (data.open(QFile::WriteOnly | QFile::Truncate)) {
QTextStream out(&file);
out.setCodec("UTF-8");
out << "Result: " << qSetFieldWidth(10) << left << 3.14 << 2.7;
// writes "Result: 3.14 2.7 "
}
在尝试转换数据块时,例如在通过网络接收数据时,必须非常小心。在这种情况下,一个多字节字符可能会被分成两个块。在最好的情况下,这可能导致丢失一个字符,在最坏的情况下,导致整个转换失败。在这些情况下使用的方法是为编解码器创建一个QTextDecoder对象,并在整个解码过程中使用这个QTextDecoder,如下所示:
QTextCodec *codec = QTextCodec::codecForName("Shift-JIS");
QTextDecoder *decoder = codec->makeDecoder();
QString string;
while (new_data_available()) {
QByteArray chunk = get_new_data();
string += decoder->toUnicode(chunk);
}
delete decoder;
QTextDecoder对象维护块之间的状态,因此即使在块之间分割多字节字符也能正常工作。
四、创建自己的编解码器类
Qt可以通过创建QTextCodec子类来支持新的文本编码。
纯虚函数向系统描述编码器,编码器根据需要在QTextStream支持的不同文本文件格式中使用,并在X11下用于特定于语言环境的字符输入和输出。
要为Qt添加对另一种编码的支持,创建QTextCodec的子类并实现下表中列出的函数j即可。
| 函数 | 描述 |
|---|---|
| name() | 返回编码的正式名称。如果编码在IANA字符集编码文件中列出,则该名称应该是该编码的首选MIME名称。 |
| aliases() | 返回编码的备选名称列表。QTextCodec提供了一个返回空列表的默认实现。例如,“ISO-8859-1”有“latin1”、“CP819”、“IBM819”和“iso-ir-100”作为别名。 |
| mibEnum () | 如果编码列在IANA字符集编码文件中,则返回对应的MIB枚举。 |
| convertToUnicode () | 将8位字符串转换为Unicode。 |
| convertFromUnicode () | 将Unicode字符串转换为8位字符串。 |









![2023年中国人力资源咨询发展历程及市场规模前景分析[图]](https://img-blog.csdnimg.cn/img_convert/2ab417914ba1299e9cfe55bf9219f1b3.png)