1、引言
Optuna是一个由日本东京大学开发的自动化超参数优化库,用于机器学习和人工智能。它可用于自动优化神经网络、随机森林等模型的超参数,以改善模型的性能和准确性。Optuna还可以与其他流行的机器学习框架(如TensorFlow和PyTorch)一起使用。 Optuna的名称来源于“最适化”(Optimization)和“羽化”(Fluttering)的结合,意味着它可以帮助机器学习模型“羽化”到最佳状态。
Optuna是一个基于Python的自动超参数优化框架,可以自动寻找最优的超参数组合,从而帮助数据科学家和机器学习工程师更快更准确地构建高性能的机器学习模型
Optuna的原理基于贝叶斯优化算法,它主要包含了三个核心组件:Trial、Study和Sampler。在Optuna中,每次试验都被称为Trial。一个Trial包含了一个超参数组合,以及对这个超参数组合所构建的模型的性能评估,通常是一个计算出来的指标,如模型的准确度、误差率等等。Optuna会根据这些指标不断地调整超参数组合,直到找到一个最优的组合。而一个Trial的集合被称为一个Study。Study管理和控制Trials的流程,包括超参数选取的范围和分布,以及停止条件等等。Optuna支持两种Study类型:简单的Random Search和基于贝叶斯优化的TPE(Tree-structured Parzen Estimator)算法。TPE算法是Optuna实现自动超参数优化的核心算法
Optuna是一个强大的优化库,它能够帮助你设计和优化机器学习模型。它的核心功能是能够自动地搜索超参数空间,以找到最佳的模型配置。尽管Optuna在机器学习领域的应用非常广泛,但它也可以用于其他需要优化的问题。
首先,Optuna能够非常有效地搜索超参数空间。它使用了一种名为TPE (Tree-structured Parzen Estimator)的算法,这种算法结合了贝叶斯优化的优点和决策树的灵活性。通过使用TPE,Optuna能够高效地搜索超参数空间,并找到最佳的模型配置。此外,Optuna还提供了其他一些功能,例如并行化和分布式计算,这使得它能够更快地搜索超参数空间。
其次,Optuna还提供了许多易于使用的接口。它允许你使用简单的Python代码来定义要优化的目标函数和搜索空间。然后,Optuna会自动地进行搜索并返回最佳的超参数配置。此外,Optuna还支持各种流行的机器学习库,例如Scikit-learn和TensorFlow,这使得它能够方便地集成到你的机器学习工作中。
最后,Optuna还提供了一些额外的功能,例如可视化工具和交叉验证。这些功能可以帮助你更好地理解你的模型和超参数搜索的结果。通过使用这些工具,你可以更好地了解你的模型的表现和超参数搜索的过程。
2、安装optuna与仪表盘
安装前提条件:Python版本需要大于3.7
2.1、安装optuna
pip install optuna -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
安装好了可以查看下版本:
import optuna
print(optuna.version.__version__)查看下有哪些类与方法:
dir(optuna)
['Study', 'Trial', 'TrialPruned', '_LazyImport', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '__version__', '_callbacks', '_convert_positional_args', '_deprecated', '_experimental', '_hypervolume', '_imports', '_transform', '_typing', 'artifacts', 'copy_study', 'create_study', 'create_trial', 'delete_study', 'distributions', 'exceptions', 'get_all_study_summaries', 'importance', 'integration', 'load_study', 'logging', 'multi_objective', 'progress_bar', 'pruners', 'samplers', 'search_space', 'storages', 'study', 'trial', 'version', 'visualization']
2.2、安装optuna-dashboard
可视化的仪表盘对于直观了解整个优化迭代的过程还是很有帮助的,同样的建议带上豆瓣镜像
pip install optuna-dashboard -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
安装好了之后,查看下里面的类和方法:
import optuna_dashboard
dir(optuna_dashboard)
['ChoiceWidget', 'ObjectiveChoiceWidget', 'ObjectiveSliderWidget', 'ObjectiveTextInputWidget', 'ObjectiveUserAttrRef', 'SliderWidget', 'TextInputWidget', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '__version__', '_app', '_bottle_util', '_cached_extra_study_property', '_form_widget', '_importance', '_named_objectives', '_note', '_pareto_front', '_rdb_migration', '_serializer', '_storage', '_storage_url', 'artifact', 'dict_to_form_widget', 'get_note', 'register_objective_form_widgets', 'register_user_attr_form_widgets', 'run_server', 'save_note', 'set_objective_names', 'wsgi']2.3、如何使用
对于使用方法,如果有看本人前面发布的一篇超参数优化的文章,Hyperopt:分布式异步超参数优化(Distributed Asynchronous Hyperparameter Optimization)
上手就更加简单易懂了,原理都是将参数指定在一个分布空间里面,然后对需要优化的函数进行迭代,找出最佳的参数。
我们先来看一个示例,看下对函数(x-2)²的优化情况:
import optuna
# 需要优化的函数
def objective(trial):
x = trial.suggest_float('x', -10, 10)
return (x - 2) ** 2
# 使用study对象的optimize来优化,里面的参数是上面定义的方法,以及迭代次数
study = optuna.create_study()
study.optimize(objective, n_trials=20)
print(study.best_params)
#{'x': 2.128194654190586}20次迭代的结果还是不错的,跟2比较接近了,当然这个n_trials迭代次数越多,最佳值就会越优。
2.4、鸢尾花数据集
我们依然使用鸢尾花的数据集来进行测试,这里需要用到sklearn,所以没有安装的,可以先进行安装:
pip3 install --user scikit-learn -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
import optuna
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
def objective(trial):
C = trial.suggest_float('C', 1e-5, 1e5)
gamma = trial.suggest_float('gamma', 1e-5, 1e5)
clf = SVC(C=C, gamma=gamma)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
return score
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
print(study.best_params,study.best_value)3、仪表盘可视化
确保在前面安装了optuna_dashboard,然后我们来看下可视化的情况。
import optuna
# 需要优化的函数
def objective(trial):
x = trial.suggest_float('x', -10, 10)
return (x - 2) ** 2
# 使用study对象的optimize来优化,里面的参数是上面定义的方法,以及迭代次数
study = optuna.create_study(sampler=optuna.samplers.TPESampler(), storage='sqlite:///db.sqlite3')
study.optimize(objective, n_trials=50)
print(study.best_params)代码可以看到,我们是将数据保存在了sqlite的数据库里面,在当前目录可以看到有一个db.sqlite3数据库文件,然后可视化就是对这些保存的数据画图,也就是说省略了自己去手工画图的意思。
打开新的命令行输入:optuna-dashboard sqlite:///db.sqlite3
Listening on http://127.0.0.1:8080/
Hit Ctrl-C to quit
然后我们在浏览器中输入,上面的地址:http://127.0.0.1:8080/
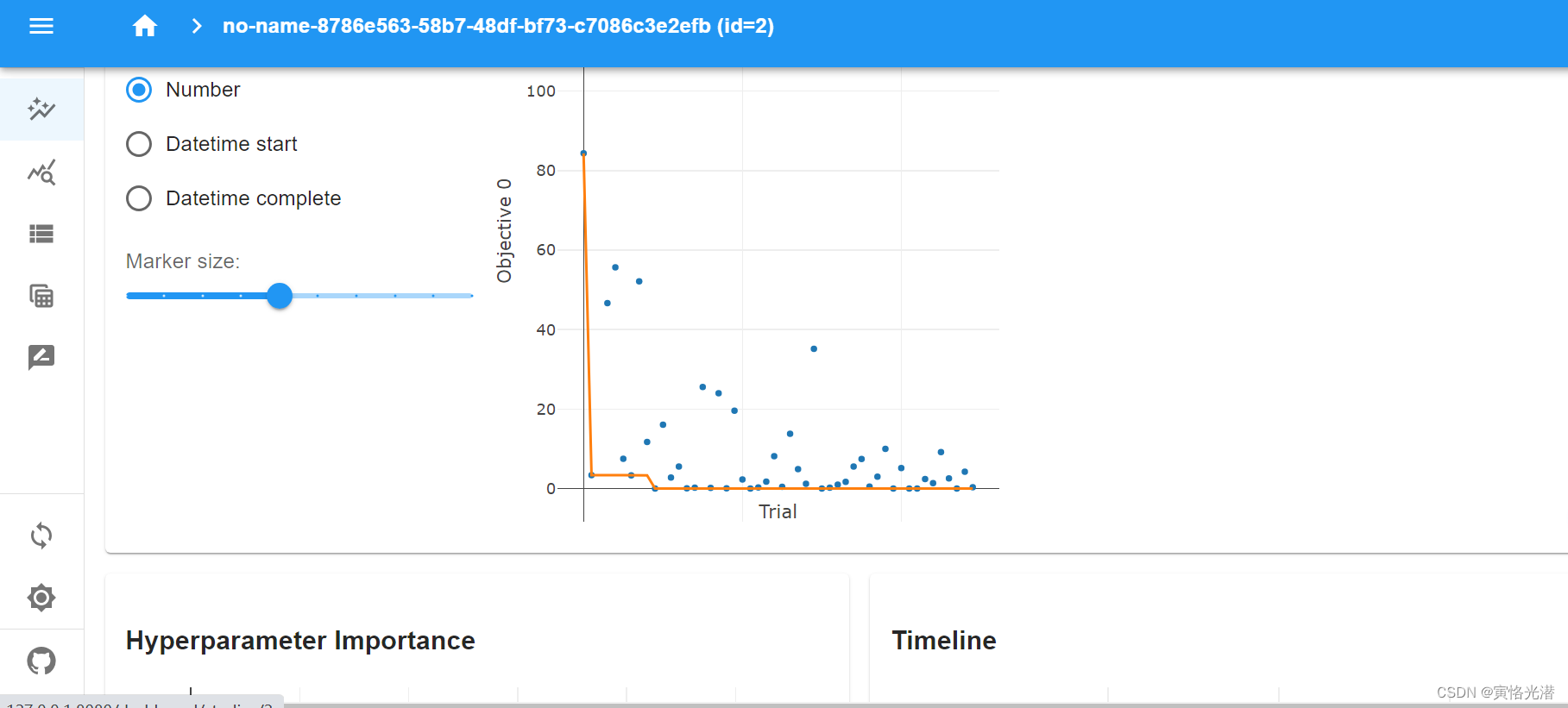
这样就会出现优化迭代的仪表盘了,如下图:
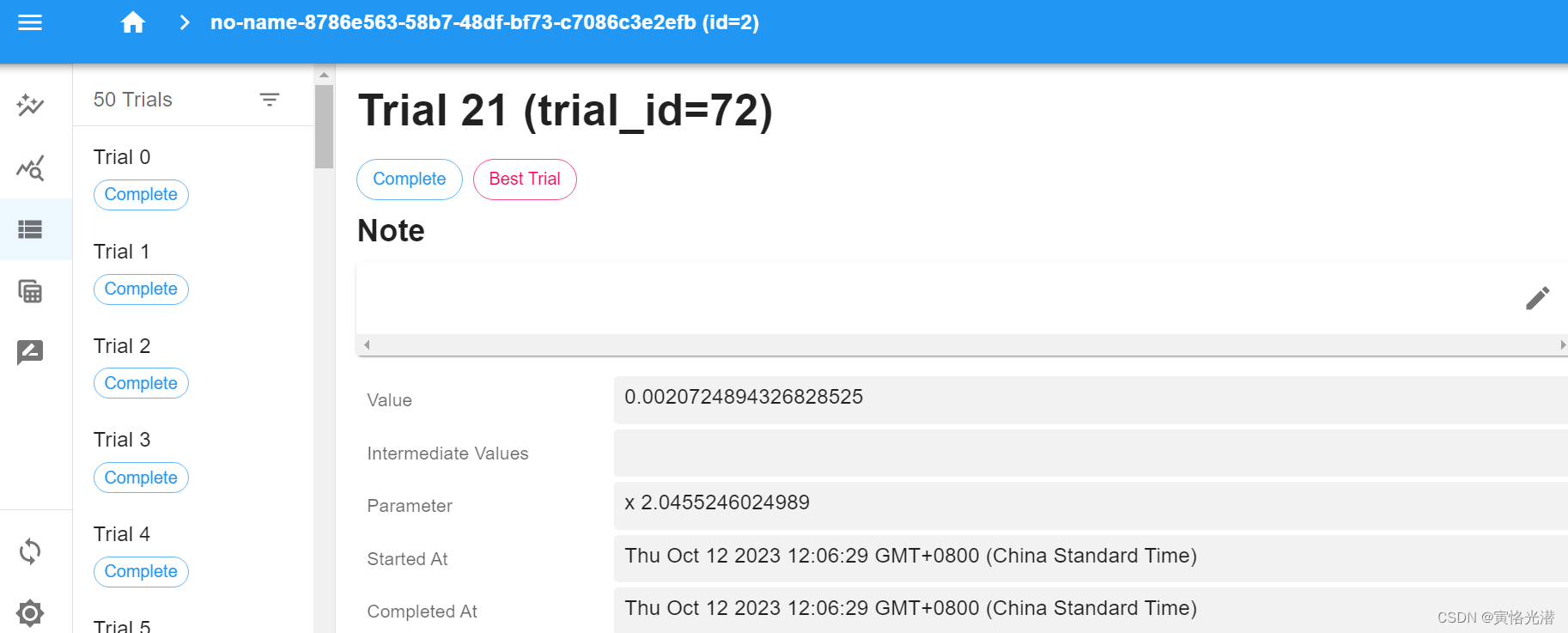
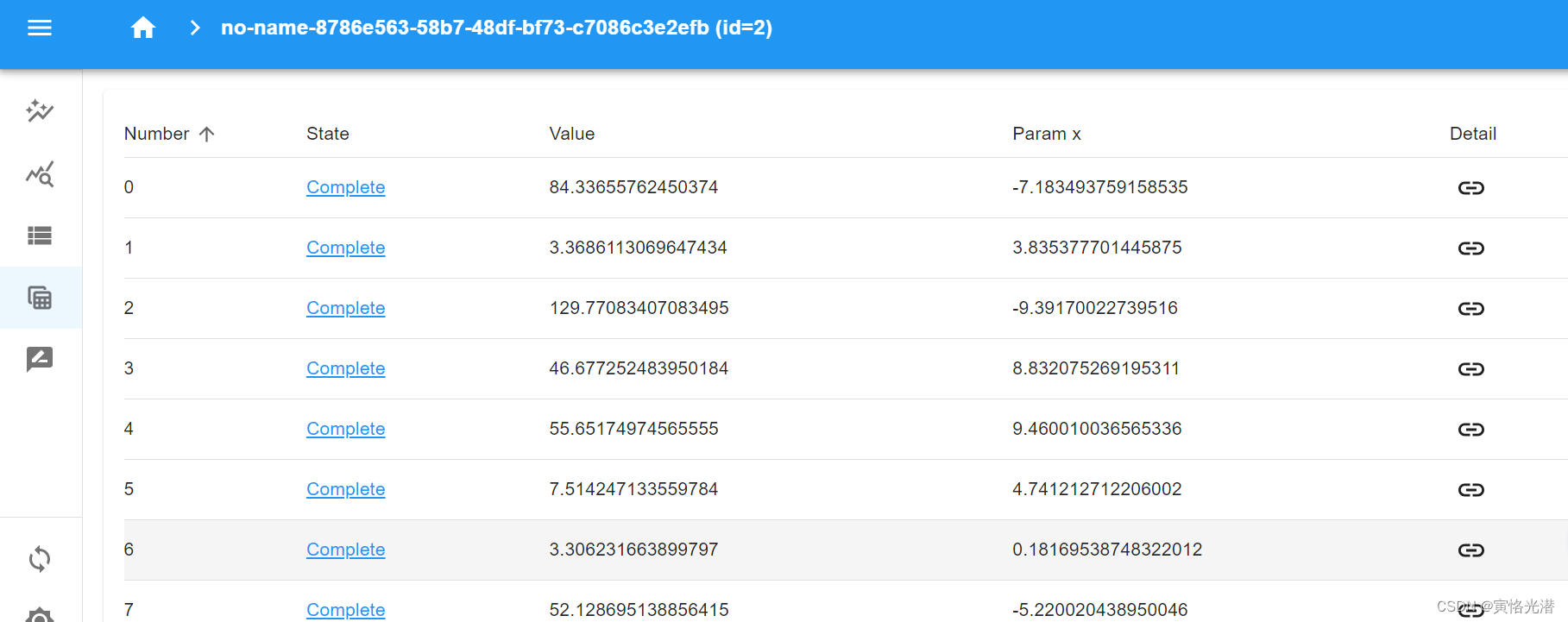 有兴趣的也可以直接查看数据库的情况:sqlite3 db.sqlite3
有兴趣的也可以直接查看数据库的情况:sqlite3 db.sqlite3
里面有很多张表,如下图: