公众号:算法一只狗

文章目录
- 第一个,一切都可以进行分割
- 第二个,开源图文回答工具
- 第三个,视频转换风格生成
- 第四个,免费好用的文档对话工具
- 文档对话能力
- 文档联系功能
今年,我们见证了人工智能算法的起飞,还有各种围绕大模型、AIGC等领域算法百花齐放。
如果说去年人工智能领域的关键词是“元宇宙”的话,那么2023年无疑是属于“大模型”的一年。迄今为止,国内外的科技公司、高校、研究机构已经发布了多款人工智能大模型,“百模大战”不断加码。
当然,作为AI从业者的我们,当然要不断学习。尽管目前大模型AI还不能够替代我们,但是也要求我们学会使用它,帮助自己提升工作效率。

因此这期我们来总结一下上半年的一些好玩有趣的AI算法。大家有兴趣的可以查看我公众号的详细文章。
- 一切都可以进行分割
https://mp.weixin.qq.com/s/HROpJHlcRX64J1kMz4L9Dw
- 开源图文回答工具
https://mp.weixin.qq.com/s/prJ9p9NAXYio9G8WCGomqQ
- 视频转换风格生成
https://mp.weixin.qq.com/s/UN5meK7YKEfd32TPpiQCLQ
- 免费好用的文档对话工具
https://mp.weixin.qq.com/s/e4bN6ciw5vzh9KR_Vc1YCw
第一个,一切都可以进行分割
一直沉静许久的CV圈,被Meta发布的SAM模型给炸出圈来。
发布的新模型,宣称能够“剪切”任何的图像。它可以对不熟悉的物体和图像进行零样本泛化,而无需额外的训练,就可以识别任意的图像。
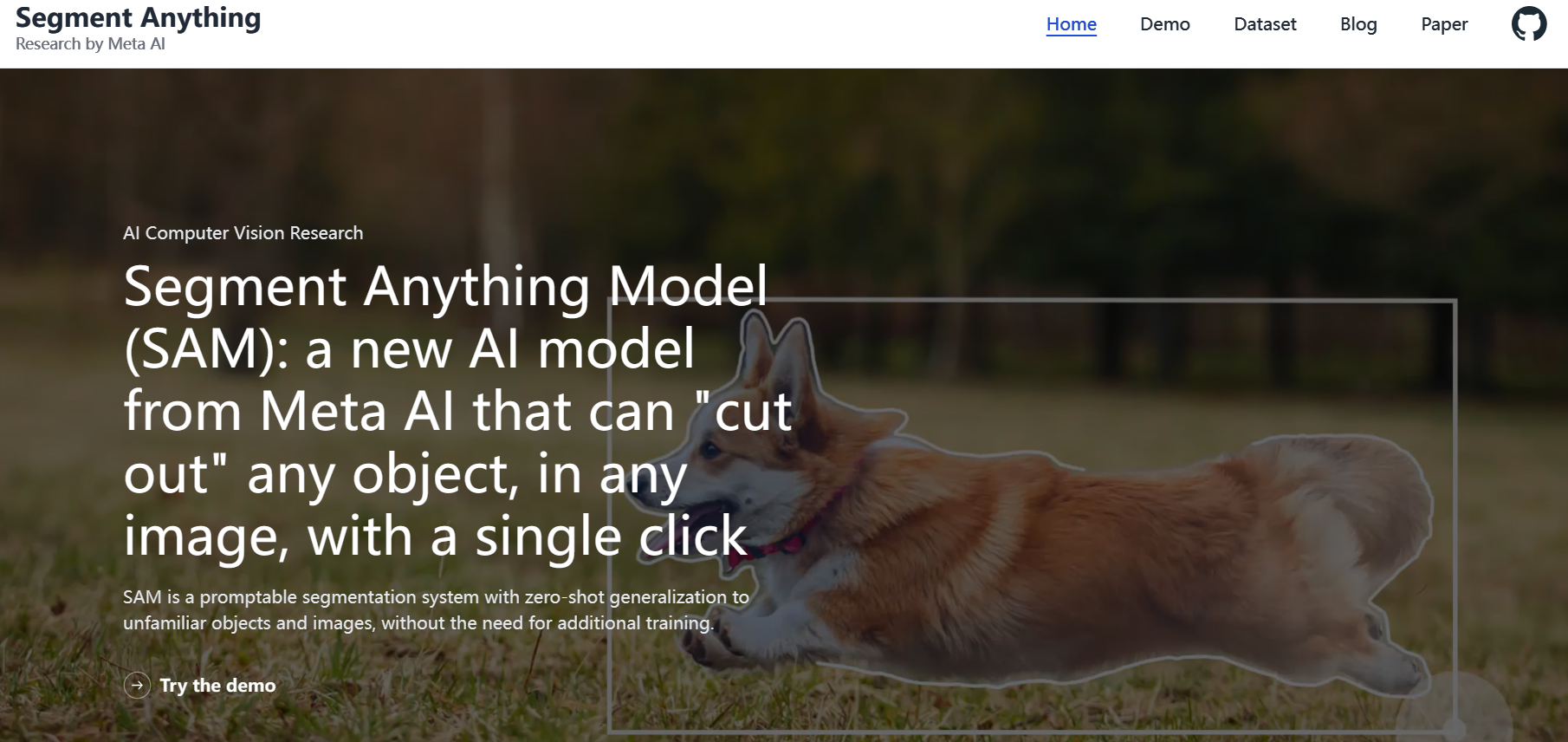
从官方放出的demo来看,只需要通过鼠标点击对应的物体,就可以有效识别:

又或者给定一张图片,让它识别出图像中所有的物体:

现在大模型都需要有通用的,自适应于下游任务的能力。SAM模宣称可以直接理解不熟悉的物体和图像进行零样本分割,而无需额外的训练。

第二个,开源图文回答工具
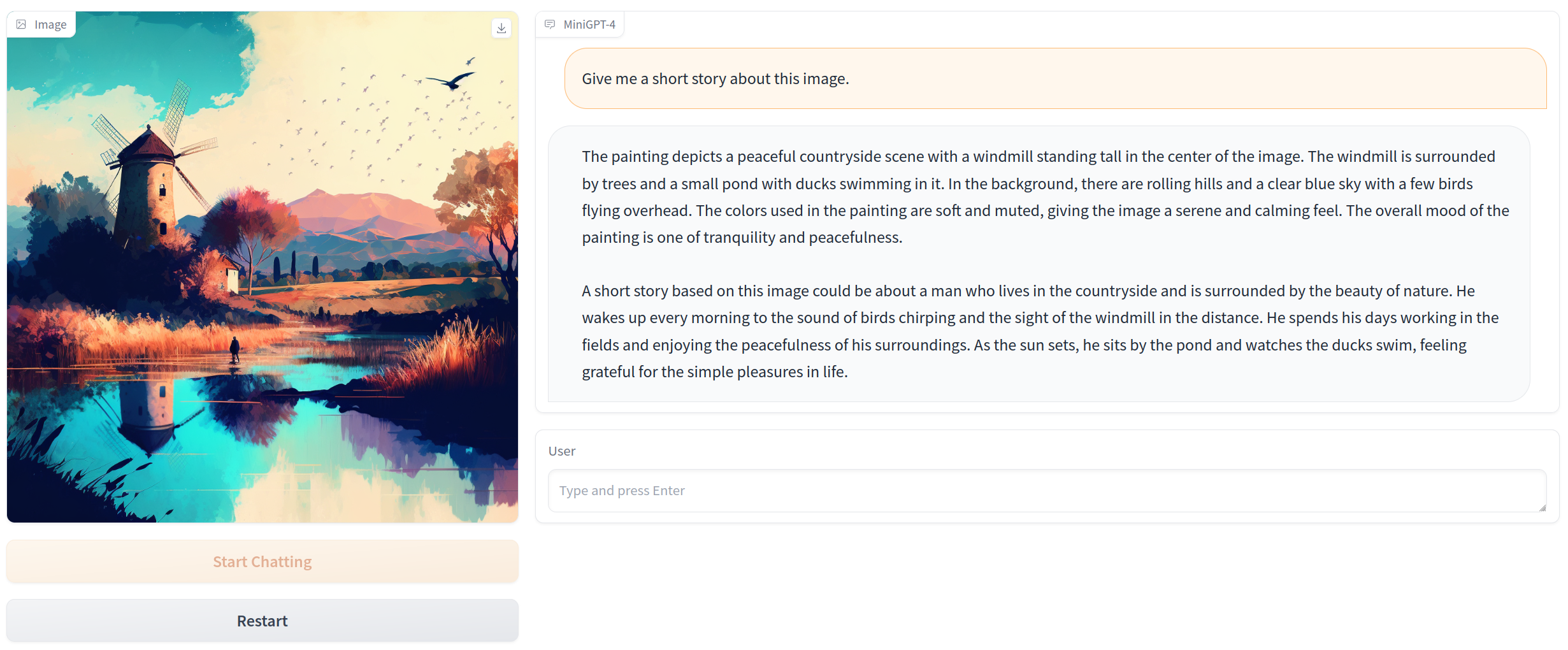
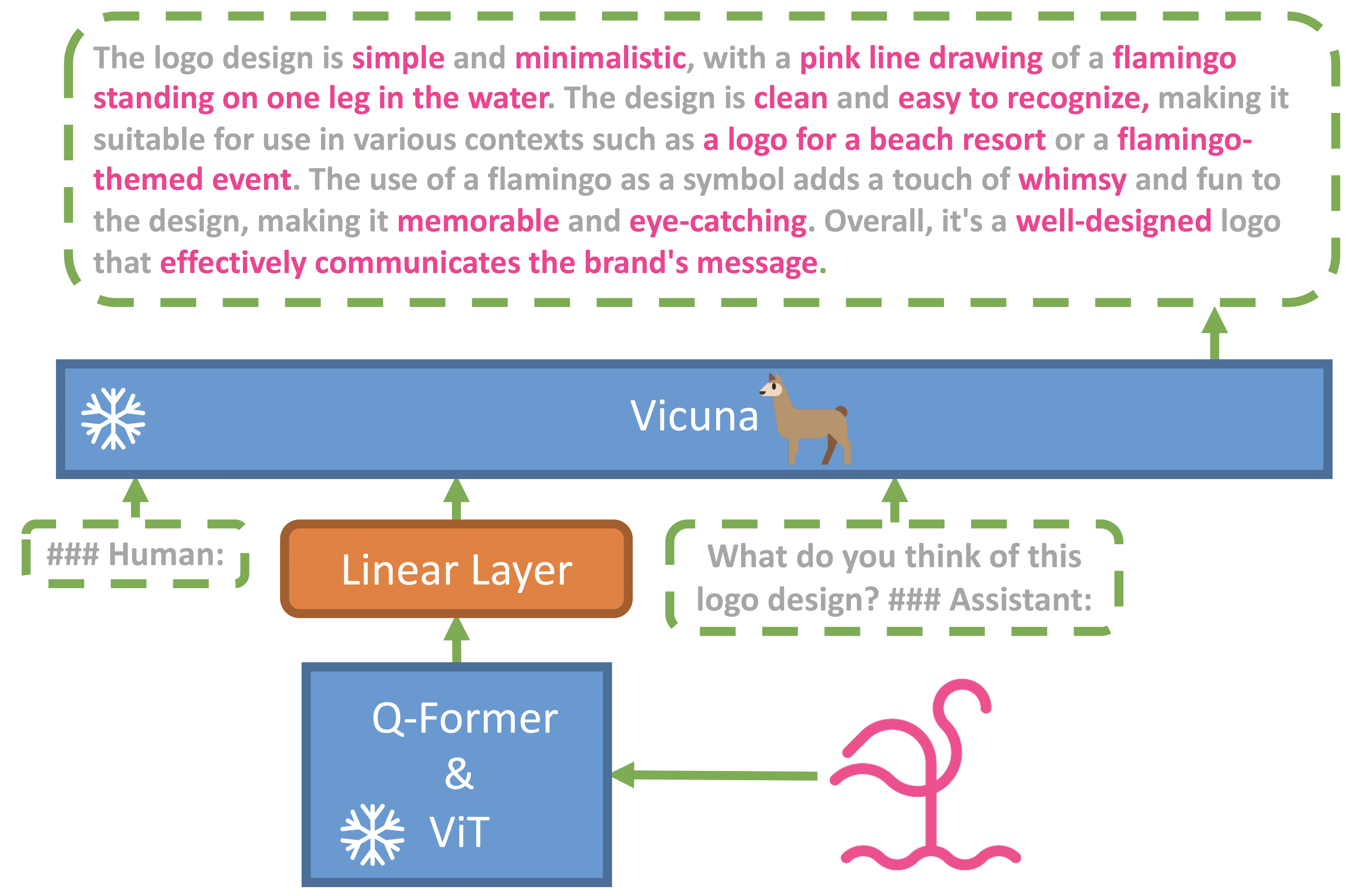
在大模型的加持下,图片+文字的多模态模型也雨后春笋般。其中比较出名的MiniGPT-4,它产生了类似于 GPT-4 中新兴的视觉语言能力。
在MiniGPT-4模型中,你可以围绕一张图片和它进行对话:
从模型实现上来看,主要分为两步进行训练:
- MiniGPT-4冻结一个视觉编码器和LLM
- 在第一个阶段,使用100万个图像文本对进行训练。通过第一阶段后,模型能够有效理解图像,但是其生成能力变差
- 第二个阶段则使用高质量的图像文本对数据集,共3500个进行微调,以显着提高其生成可靠性和整体可用性。这个阶段的计算效率很高,使用单个 A100 只需要大约7分钟。
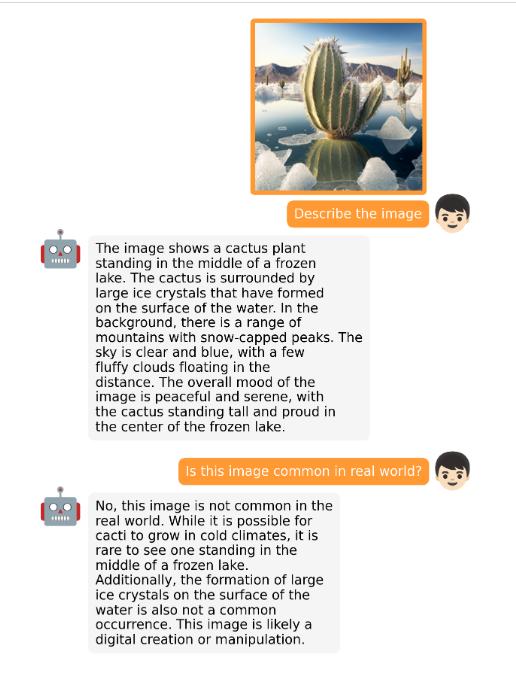
在官网放出的例子中,它可以描述这张图片的内容:
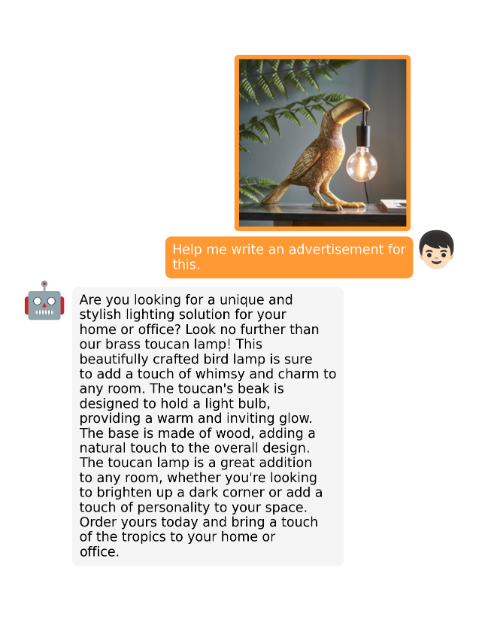
或者可以给这张图定制一个广告语:
第三个,视频转换风格生成
https://www.yuque.com/yuqueyonghumaryyq/fmvho1/rwh3g25ekk25kt2p
在以前如果要对现有的视频进行风格转换,往往会造成视频闪烁。
但是这个难题近期被南洋理工大学的团队很好的解决。首先来看看他们生成的视频效果:

可以看到,生成的视频很丝滑,而且人物的动作衔接的很连贯。
不仅仅在人物方面能够解决“闪烁”问题,就连建筑上也能够很好的hold住不同的风格:

同时帧与帧之间比较流畅,已经能够和正常的视频相媲美了。
![comparison_1[00_00_03--00_00_23].gif](https://img-blog.csdnimg.cn/img_convert/97f50c0e53d5e6d790c747fa4537956f.gif)
第四个,免费好用的文档对话工具
文档对话能力
我们知道,目前有一众收费的ChatPDF等文档问答网站,而Claude2直接可以说秒杀这些大部分的网站
它可以在官网上传文件进行对话 :
而且最大可以上传5个文件,每个文件最大可以10MB.
比如我这里把Claude2的技术文档上传上去,让它进行总结。它能够在几秒内把PDF进行总结:

同时也可以不断询问文档中的细节,这个能力和ChatPDF相当:

当然,我们也能够利用它的能力,进行excel数据分析:

文档联系功能
而且,只要我们上传更多的文档,就可以让它总结其中之间的联系,省去了我们看多个文档写总结的时间:









![[SQL开发笔记]创建SQL数据库](https://img-blog.csdnimg.cn/69e1c63a0f8b4819b96e725b4ccc922f.png)