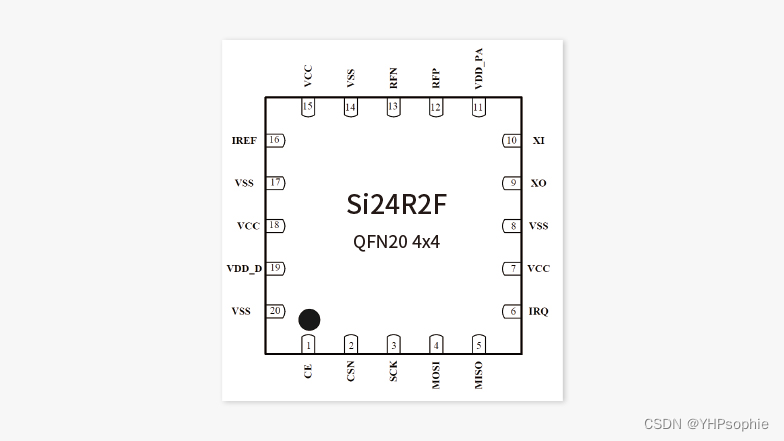
以下是一个使用Lua-http库编写的一个爬虫程序,该爬虫使用Lua语言来抓取www.snapchat.com的内容。

代码必须使用以下代码:get_proxy
-- 导入所需的库
local http = require("http")
local json = require("json")
-- 定义爬虫IP服务器
local proxy = "http://your_proxy_server.com:port"
-- 定义要抓取的网站
local target_url = "https://www.snapchat.com"
-- 定义要抓取的页面和元素
local start_url = "https://www.snapchat.com/add"
local elements = {
{"username", "/input[@name='username']/"},
{"password", "/input[@name='password']/"},
{"submit", "/button[@name='submit']/"}
}
-- 初始化爬虫
local function crawl()
-- 使用爬虫IP服务器请求目标URL
local response = http.request({
url = target_url,
method = "GET",
headers = {
["Proxy-Authorization"] = "Basic dXNlcm5hbWU6cGFzc3dvcmQ=",
["User-Agent"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"
},
ssl = {
proxy = proxy,
verify = not not proxy
}
})
-- 检查响应状态
if response.status == 200 then
-- 解析HTML
local html = response.read("*a")
local document = json.decode(html)
-- 遍历页面上的所有元素
for _, element in ipairs(elements) do
-- 提取元素的内容
local content = document[element[2]].innertext
-- 输出内容
print(content)
end
else
-- 输出错误信息
print("Error: " .. response.status .. " " .. response.reason)
end
end
-- 开始爬虫
crawl()
请注意,您需要将your_proxy_server.com和port替换为实际的爬虫IP服务器地址和端口号。此外,您还需要在请求中设置正确的爬虫IP授权和用户爬虫IP。希望这对您有所帮助!
![[SQL开发笔记]创建SQL数据库](https://img-blog.csdnimg.cn/69e1c63a0f8b4819b96e725b4ccc922f.png)