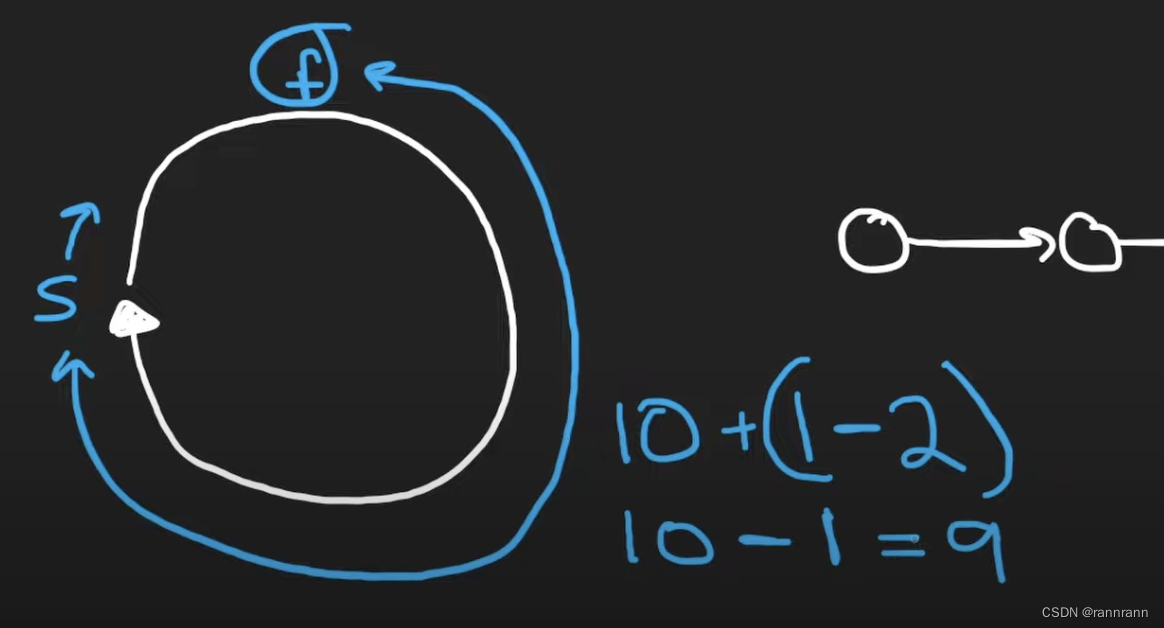目录
1. 前篇回顾
2. Redis 集群是什么?
3. Redis 集群的优点
4. Redis 集群的槽位概念
5. 什么是分片?
6. 如何找到给定key的分片?
7. 分片+槽位的设计有什么好处?
8. key映射到节点的三种解决方案
8.1 哈希取余分区
8.1.1 哈希取余分区的做法
8.1.2 哈希取余分区的优点
8.1.3 哈希取余分区的缺点
8.2 一致性哈希算法分区
8.2.1 一致性哈希算法的背景?
8.2.2 什么是哈希环?
8.2.3 redis 服务器IP节点映射
8.2.4 数据 key 的映射规则
8.2.5 一致性哈希算法的优点
8.2.6 一致性哈希算法的缺点
8.3 哈希槽分区
8.3.1 哈希槽的实质
8.3.2 用哈希槽的好处
9. 经典的高频面试题
9.1 为什么redis集群的最大槽位是16384?
9.2. 为什么集群数量最好不超过1000个?
10. Redis 不保证数据的强一致性
11. Redis 集群配置属性
提前声明:本篇文章以集群理论知识为重点,实战不作为重点,实际开发过程中集群都是运维人员或项目组长已经配置好的,或者给你一个md文档照着配就行了,掌握集群的核心原理是我们学习的重中之重,更是我们成为高级程序员以后发展为架构师的必备素养。
1. 前篇回顾
前两篇主从复制篇和哨兵篇,我们聊过了,主从复制减轻了 master 的数据访问压力,但 master 宕机会造成巨大损失;
所以为了解决 master 当即带来的巨大损失,就有了主从复制 + 哨兵选举新 master 的设计模式,解决了 master 宕机之后 slave 从机无法进行写数据的缺点;
尽管如此,主从复制+哨兵机制仍然无法100%保证数据不丢失,并且在该并发访问的系统中,单个 master 难以承受巨大的访问压力,还是有一定的缺陷的,这样看来主从模式+哨兵的设计模式似乎也没有那么优秀。
那么有没有更好的解决方案呢?当然有啦!!!就是我们本篇要讲的也是企业开发几乎必备极为常用的 redis 集群。
2. Redis 集群是什么?
集群从字面意思理解即可,就是一个群体,对于 redis 来说,一个 master 不行,那我弄多台。就像我们的分布式系统一样,注册中心,配置中心都会配置多台,多台服务器内部组成一个大的群体对外统一提供服务,就称之为集群,集群增强了系统的高可用性,并且集群之间通常可以共享数据,master1 的数据对于 master2 可见,master2的数据对于 master1也可见。用户客户端与 Redis 链接的时候,只需要连接任意一个节点即可,不需要与所有节点相连。
3. Redis 集群的优点
(1)这里要先重申一点,使用Redis ,通常可以主从复制+哨兵,也可以直接选择集群,同学们可以把集群理解为主从复制+哨兵这种模式的PLUS版;
(2)Redis 集群支持多个 master ,每一个 master 都可以对外提供读写操作,并且每个 master 之后还可以挂载多个 slave,相比单台 master ,极大的提高了系统数据吞吐能力和高并发处理能力;
(3)由于 cluster 集群内部自带了 Sentinel 哨兵故障转移机制,已经有了高可用的特性,所以在使用 redis 集群的时候,不需要再重复配置哨兵,它自身内部就有哨兵;
4. Redis 集群的槽位概念
下面是我从 Redis 官网上关于 redis 集群截图过来的一部分说明,我把红线圈出来的部分百度翻译一下
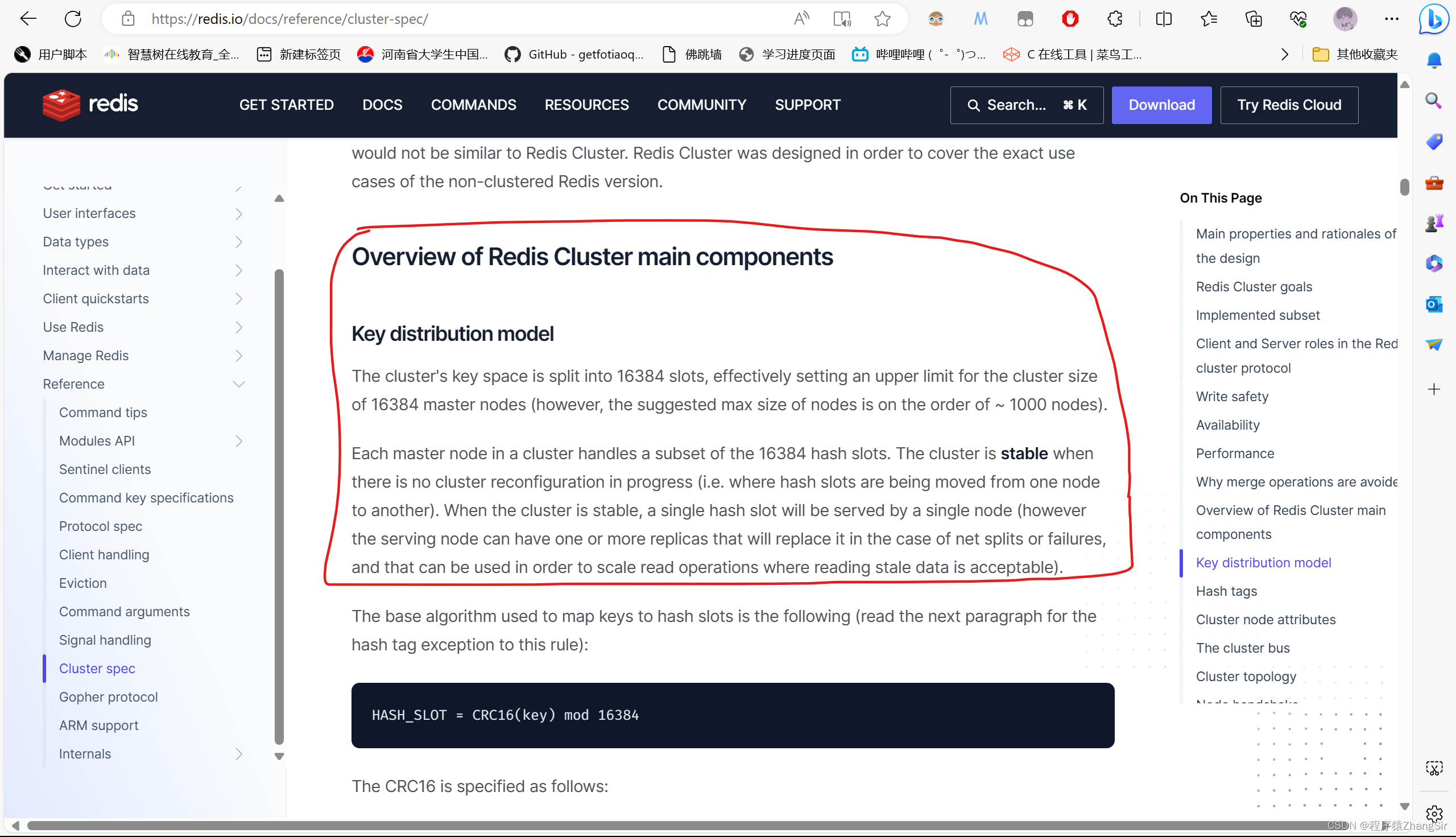
Redis Cluster主要组件概述
密钥分发模型
集群的密钥空间被划分为16384个插槽,有效地设置了16384个主节点的集群大小上限(然而,建议的最大节点大小约为1000个节点)。
集群中的每个主节点处理16384个散列槽的子集。当没有正在进行的集群重新配置时(即哈希槽从一个节点移动到另一个节点),集群是稳定的。当集群稳定时,单个哈希槽将由单个节点提供服务(但是,服务节点可以有一个或多个副本,在网络分裂或故障的情况下,这些副本将替换它,并且可以用于扩展读取过时数据的读取操作)。
官网的意思就是说,Redis 集群采用的是密钥分发模型,不管你准备用几台 Redis 服务器组成集群,集群整体会划分出来16384个槽位,在集群内部编号就是0~16383,你可以简单地把每一个槽位理解为一个储物柜,每个储物柜都可以存放很多数据,然后这些槽位通常会分散给 redis 集群中的各台服务器,也就是说集群中每台 Redis 服务器只负责一部分槽位上的数据存取。并且,官方建议 redis 集群的服务器数量不要超过1000台,通常也不会弄这么多服务器,数十台或几十台基本就可以满足 99% 的企业的项目需求。
5. 什么是分片?
一句话:"使用 Redis 集群时,我们会将存储的数据分散到多台 Redis 服务器上,这就称之为分片"。简言之,集群中的每个 Redis 服务器都可以认为是整个数据的一个分片。
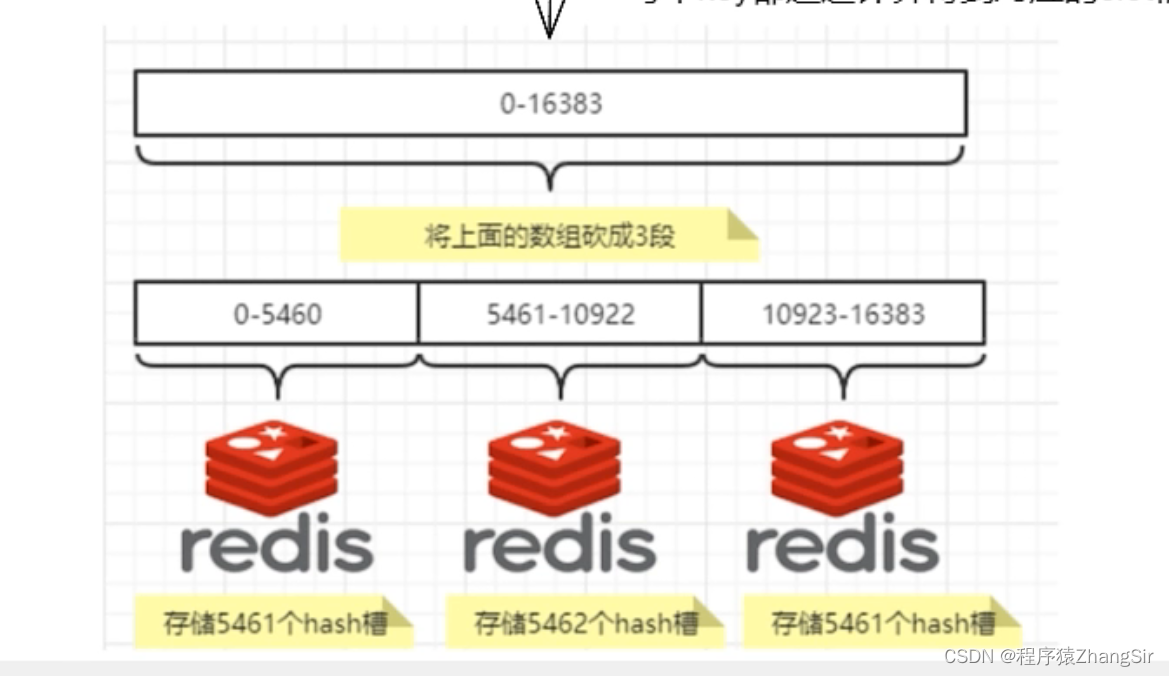
如下图举例,刚才也提到过了,16384个槽位编号分别为0~16383,现在有三台 Redis 服务器,将16384个槽位均匀分散到三台 Redis 服务器上,第一台存储0~5460号数据,第二台存储5461~10922台数据,第三台存储10923~16282号数据,这就是分片。
6. 如何找到给定key的分片?
经过上面槽位和分片的概念了解,现在已经基本清楚,每一个分片负责管理不同的槽位。我们往 Redis 集群中存储一条数据,实际上是存储到了整个 Redis 集群中某一个分片 Redis 服务器上负责的一个槽位中。
那么如何确定一个给定的数据存储到哪台分片的哪个槽位中的?我们可以在官网上找到答案
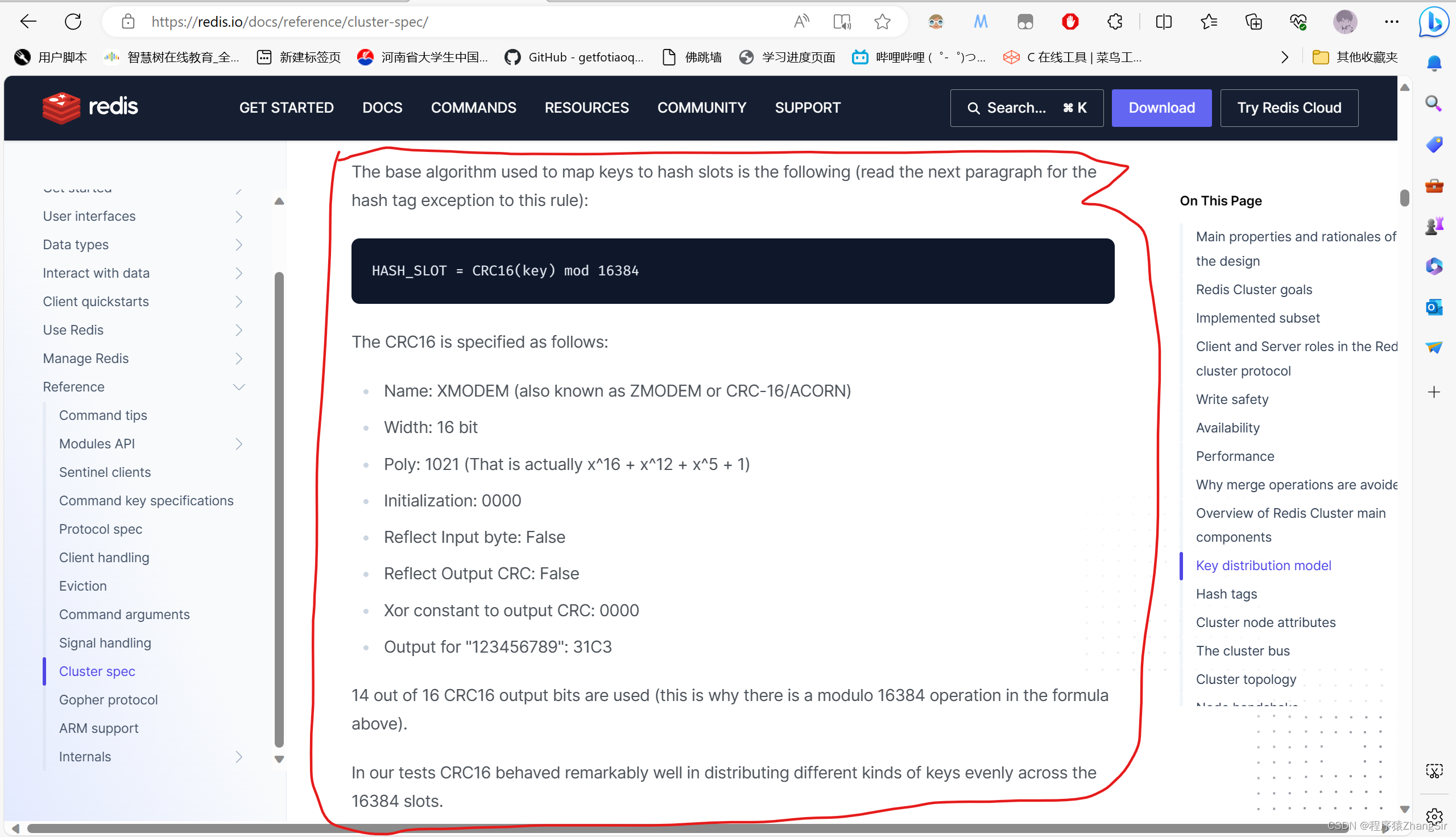
英文看不懂我们先翻译一下,如下
用于将密钥映射到哈希槽的基本算法如下(请阅读下一段以了解此规则的哈希标记异常):
HASH_SLOT=CRC16(密钥)mod 16384
CRC16的规定如下:
名称:XMODEM(也称为ZMODEM或CRC-16/ACORN)
宽度:16位
Poly:1021(实际上是x^16+x^12+x^5+1)
初始化:0000
反射输入字节:False
反射输出CRC:错误
X或常数输出CRC:0000
“123456789”的输出:31C3
使用了16个CRC16输出比特中的14个(这就是为什么在上面的公式中存在模16384运算的原因)。
在我们的测试中,CRC16在16384个插槽中均匀分布不同类型的密钥方面表现得非常好。
很多内容就算翻译过来暂时也看不懂,但没关系!至少从翻译的前两行我们能知道,给定一个确定的数据key,Redis 是基于算法来计算出这个key应该存储到哪个槽位中的,一个数据在存入 Redis 之前,会先对 key 进行CRC16算法计算出一个值,然后再对16384进行取模,计算出了这个数据应该存储在哪个槽位中。下次在取数据的时候,也是利用相同的算法计算出要取的数据存放在哪个槽位中,然后直接去对应的槽位取数据。
这个原理同学们有没有发现类似于 Java 中的 HashMap,我们存储数据会先计算键的哈希值,通过哈希值找到当前数据应该存储的数据。
7. 分片+槽位的设计有什么好处?
(1)方便扩容。假如说现在我们设置了三台 master 三台 slave,随着时间的推移,我们的用户数量越来越庞大,三台 master 不够用了,我们就可以再多增加几台,进行水平扩容,再增加新的服务器之后,我们可以将原来的16383个槽位重新打乱分片,也可以让原来的三台 master 各自均出来一些数据给新的 master。
(2)方便缩容。这个和刚才的扩容一个道理,可以重新打乱分片,也可以让即将下线的 master 将数据分给其他的 master。
(3)平滑迁移数据。在使用了 Redis 集群之后,如果我们要更换数据库服务器,或添加减少数据库服务器,Redis 集群可以做到不停止服务器的迁移数据,这个功能是非常强大的,因为正常情况下,Redis 要停机修复,就会对外停止服务,但 Redis 集群就不需要,直接平滑升级,做到安稳迁移数据,用户完全感知不到。
(4)方便数据的分块查找。因为我们是基于CRC16算法+取模算法得出的槽位,所以在取的时候是精确查找,再加上 Redis 是内存数据库,时间复杂度为O(1),速度非常非常快。
8. key映射到节点的三种解决方案
Redis 集群有很多台服务器,除了上面官方提供的一种槽位映射存储方式,还有另外两种方式,加上官方提供的方式,一共有三种,也是现在大多数企业内用三种,下面对它们分别进行深度解析。
8.1 哈希取余分区
8.1.1 哈希取余分区的做法
这个方式非常简单粗暴,假如说我的系统部署了三台Redis 服务器,那么就直接对要存储的数据 key做哈希运算,对服务器数量3做哈希取模,算出来是多少就存储到那台服务器。
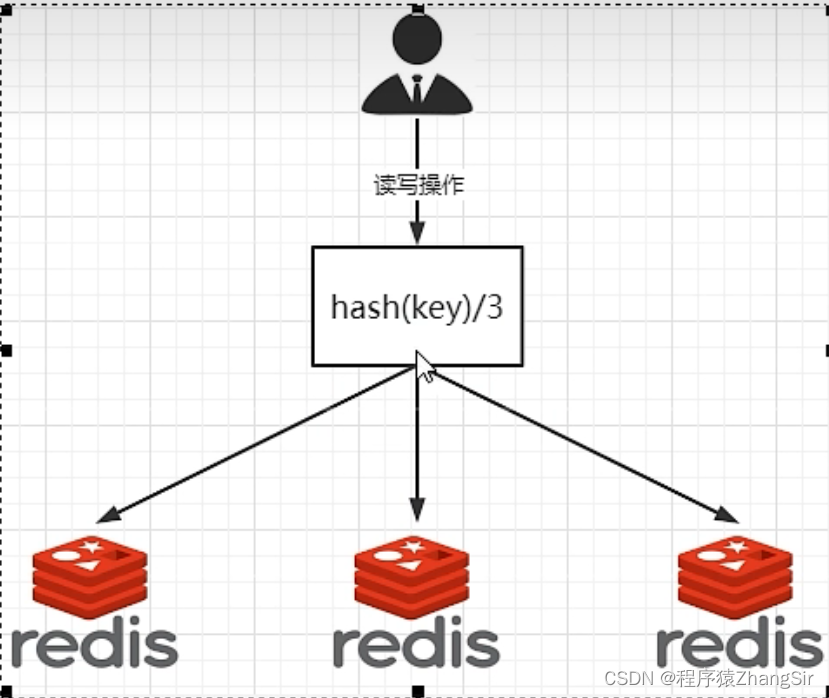
8.1.2 哈希取余分区的优点
简单粗暴,直接有效,只需要预估数据规划节点,例如3台,5台,7台,就能保证一段时间内的数据支撑。使用哈希算法让一部分固定的请求落在同一台服务器上,每台服务器固定处理同一批请求,起到了负载均衡,分而治之的目的。
8.1.3 哈希取余分区的缺点
进行扩容和缩容时比较麻烦,每次节点变动都会导致数据发生变化,映射关系都需要重新进行计算,如果 master 出故障,取模公式就变成了 Hash(key)/? 由于台数发生变化,会导致哈希取余重新发生变化。
8.2 一致性哈希算法分区
8.2.1 一致性哈希算法的背景?
因为哈希取余分区算法有一定的缺点,后来又推出了一致性哈希算法分区。它是由麻省理工学院在1997年提出的,目的就是为了解决分布式缓存数据变动与映射问题,某台服务器宕机了,哈希算法的分母发生了变化,取余就会出现问题,对应了上面哈希取余算法的缺点。
8.2.2 什么是哈希环?
一致性哈希算法的核心是哈希环。哈希算法必然会有一个哈希函数,通过哈希函数产生哈希值,是0~2^32-1 范围内的其中一个值,我们将所有可能的哈希值构成一个集合,那么这个集合就是[0,2^32-1],它本身是一个线性结构从小到大排列,如下图所示
 但我们通过适当的逻辑运算,让 0=2^32-1,使其首尾相接,这样这个线性结构在逻辑上就会形成一个环。如下图
但我们通过适当的逻辑运算,让 0=2^32-1,使其首尾相接,这样这个线性结构在逻辑上就会形成一个环。如下图
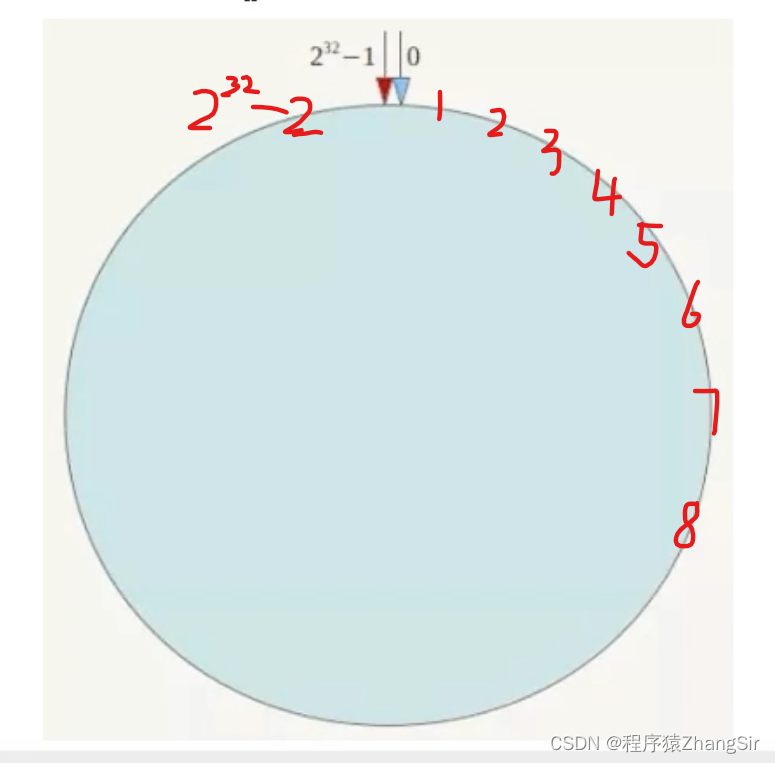
然后,我们将哈希函数得到的值对2^32进行取模,即 Hash(key) mod 2^32,计算后得到的值一定是在 [0,2^32-1] 这个集合之内的某个值。换言之,经过计算得到的值一定会落在这个环上,这样就避免了哈希取余分区算法中服务器宕机导致哈希函数分母不确定的问题。
8.2.3 redis 服务器IP节点映射
经过上面哈希环的构建之后,然后就需要将 redis 服务器上的各个IP节点映射到环上的某一位置,这里的映射方法有很多种,可以选择IP进行哈希映射,也可以选择主机名进行哈希映射。
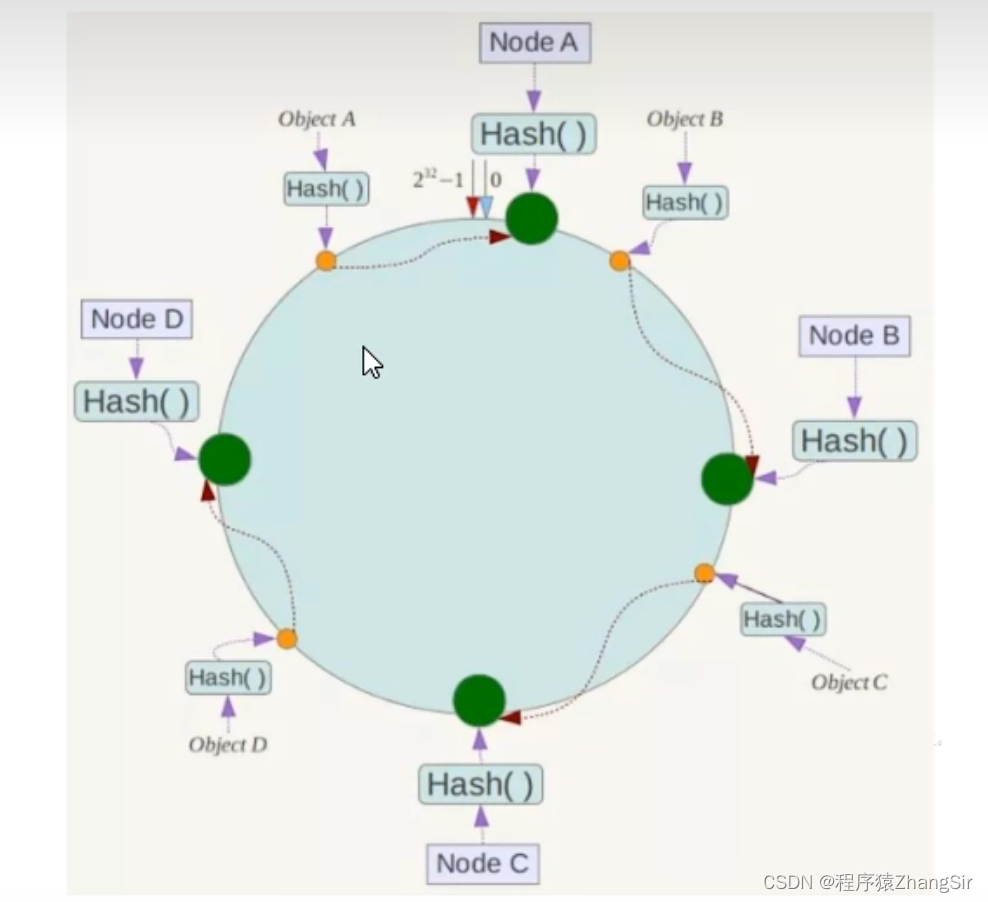
如下图,假设现在有四台 redis 服务器,经过映射之后如下图所示,分别分布在哈希环上的四个点

8.2.4 数据 key 的映射规则
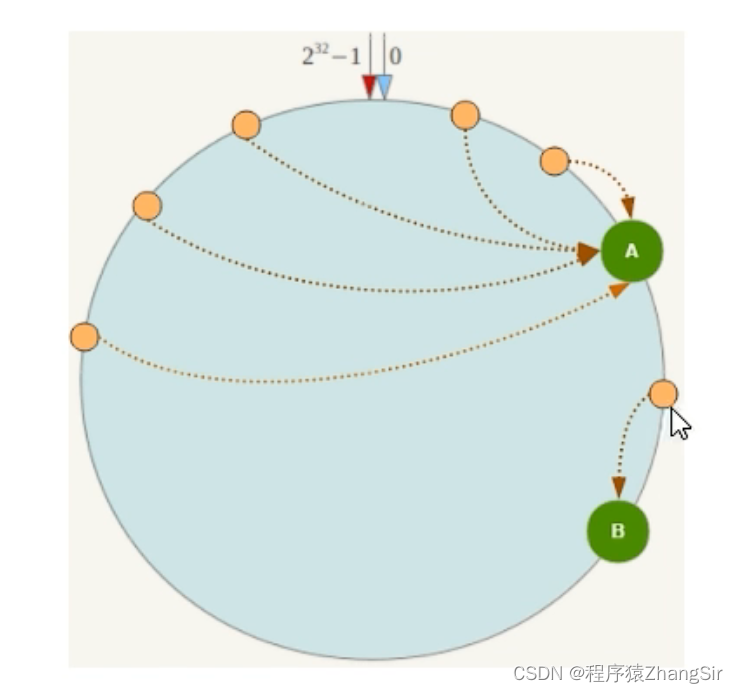
数据 key 的映射规则与节点服务器映射规则相似,当我们的用户要存储一个 key 的时候,会和节点一样,先计算哈希值 Hash(key),然后对 2^32 取模运算,即 Hash(key) mod 2^32,得到数据之后,它会落在换上的某个点,只要没有落在某台 redis 节点上,那么该 key 就要沿着环顺时针行走,直到遇到第一个节点,遇到的第一个节点就是它应该存储的 redis 服务器。
如下图,数据 ObjectA 经过计算落在了 NodeA和NodeD 之间,那么它沿着环顺时针行走,就会首先遇到 NodeA,它就要存储在 NodeA 节点服务器中;
数据 ObjectB 经过计算落在了 NodeA和NodeB 之间,那么它沿着环顺时针行走,就会首先遇到NodeB,它就要存储在NodeB节点服务器中;
数据 ObjectC和ObjectD 同理分别存储到C节点和D节点中;
8.2.5 一致性哈希算法的优点
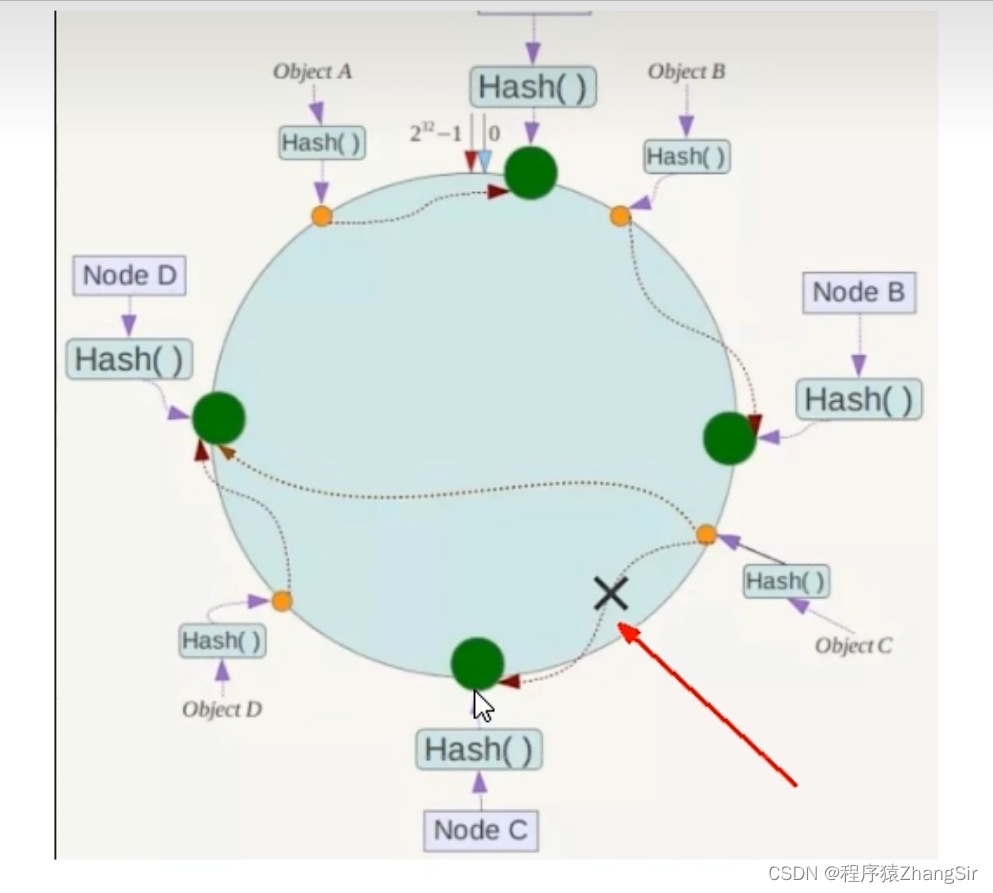
(1)解决了服务器宕机当值哈希计算出现错误的情况。
如下图,如果NodeC服务区出现了故障,那么ObjectC会越过NodeC继续顺时针滑动,寻找下一个节点服务器,就能找到NodeD,数据ObjectC就能顺利存储到NodeD服务器节点中。
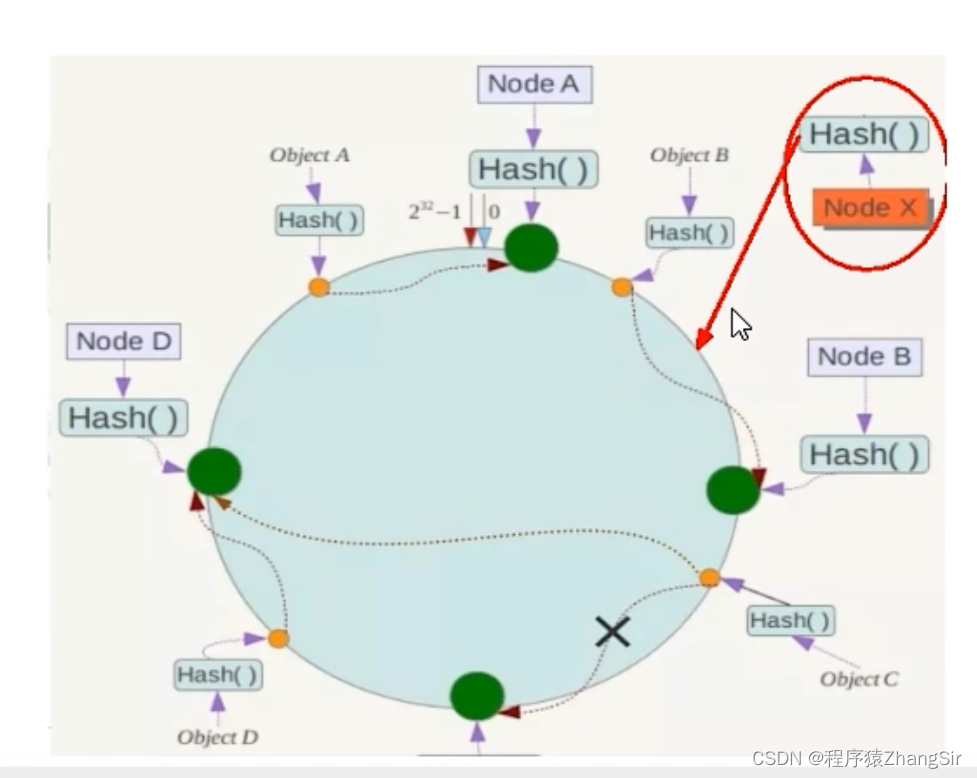
(2)增加服务器时受影响的数据量小,扩展性强。
如下图,假如说我们在NodeA和NodeB之间在加一台新的服务器节点NodeX,那么受到影响的数据只有NodeA~NodeX之间的数据,数据量较小,对业务产生影响也较小。
8.2.6 一致性哈希算法的缺点
(1)节点较少时,会导致数据倾斜问题。
如下图,假如只设置了两台节点服务器,而且经过IP映射之后两者相距较近。那么大部分数据都会经过滑动最终存储到NodeA,只有少量数据存储到了NodeB,数据分散不均匀,产生数据倾斜问题。
8.3 哈希槽分区
8.3.1 哈希槽的实质
哈希槽它的实质是一个数组,大小是 2^14,大家可以算一下,2^10 = 1024,2^4 = 16,1024 * 16 = 16383。这16384个槽位的编号则是 0~16383。
8.3.2 用哈希槽的好处
(1)解决了均匀分配问题
实际上这个哈希槽是等于在数据和redis节点服务器之间又加了一层,如下图
 前面哈希取余算法和一致性哈希算法都是直接找节点服务器存储。而哈希槽则是在中间加了一层,用户存储一个数据时,先经过计算得出这个数据应该存储在哪个槽位,然后通过槽位取寻找特定的节点服务器。
前面哈希取余算法和一致性哈希算法都是直接找节点服务器存储。而哈希槽则是在中间加了一层,用户存储一个数据时,先经过计算得出这个数据应该存储在哪个槽位,然后通过槽位取寻找特定的节点服务器。
(2)便于数据的分配和移动
因为哈希槽本身并不是与redis节点服务器处于高度绑定的状态,我们可以人为的随时更改每一个节点服务器上的哈希槽数量。这样的话,我们再增加修改服务器数量时,数据都不会受到较大的影响,便于数据的分配和移动。
9. 经典的高频面试题
9.1 为什么redis集群的最大槽位是16384?
官网上说明了,在存放 key 之前,会对 key 做CRC16(key)算法。但是,CRC16算法可以产生16个bit 位,那么最大值为 2^16 = 65536,槽位号为 0~65535。既然如此,redis在设计的时候为什么不用 65536 而要用16384,你探究过原因吗?
下图是在网上截取的一幅图片,在GitHub中,有人问 Redis 的作者为什么不用 65536 而用 16384,我们一起看看 Redis 的作者是如何回答这个问题的。

我给大家翻译一下作者的解释,
(1)正常的心跳包带有节点的完整配置,可以用幂等的方式用旧的节点替换新的节点,以便更新旧的配置。这意味着它们包含原始节点的插槽配置,该节点使用2K的空间和16K的插槽,但是会使用8K的空间,(使用65K的插槽)。
(2)同时,由于其他设计初衷,Redis集群不太可能扩展到1000个以上的主节点。
(3)因此16K处于正确的范围内,以确保每个主机具有足够的插槽,最多可容纳1000个矩阵,但数量足够少,可以轻松地将插槽配置作为原始位图传播。请注意,在小型集群中,位图难以压缩,因此当N较小时,位图将设置的 slot(插槽数) / N位占设置位的很大百分比。
作者的回答并不是很好理解,其实我在看到这里的时候也是一脸懵逼,这里涉及到了 Redis 的底层架构,Redis 使用C语言编写的,非常复杂。我结合网上的一些资料和视频给大家总结了一个比较好理解的解释,结合下图。
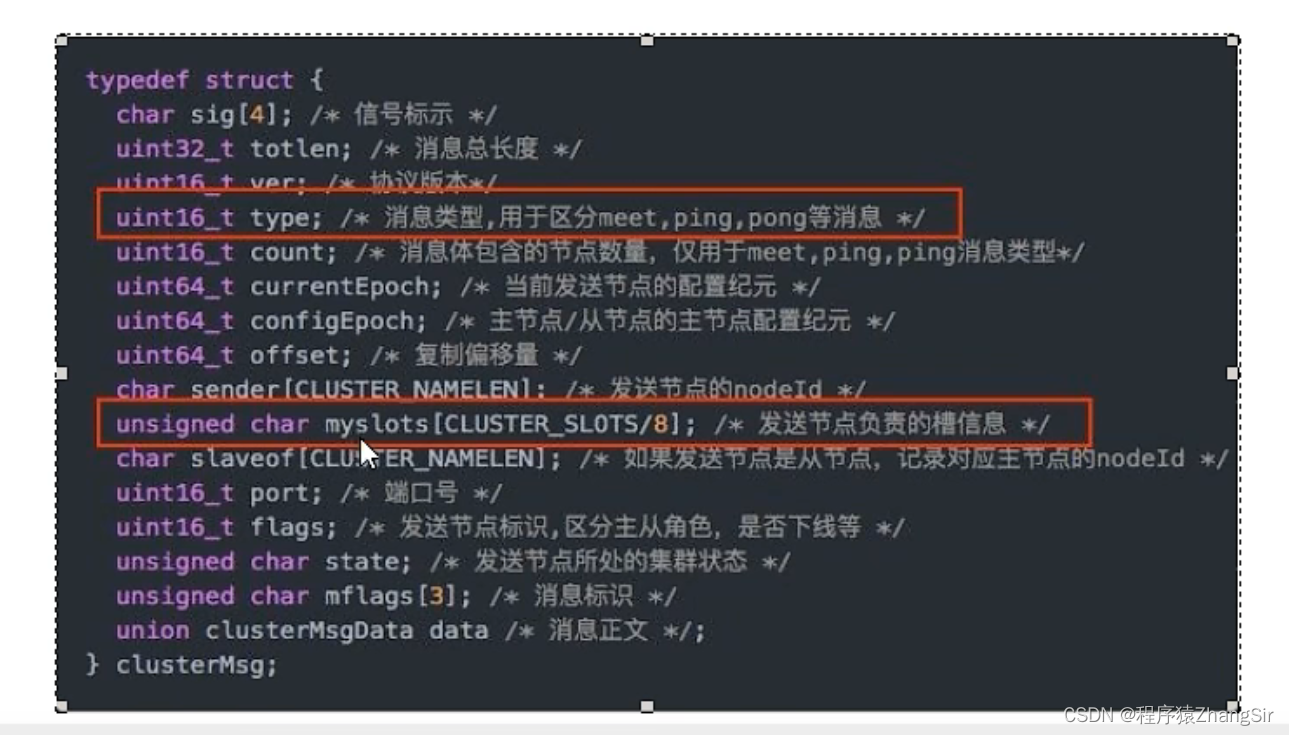
(1)如上图,这是 Redis 底层关于集群的一些配置信息,看红线圈出来的部分,第一个说明集群内部服务器之间是通过网络传输 ping 心跳包来互相发送信息的;
(2)第二个是关于发送服务器负责的槽信息,所发送的信息包的大小是 集群数量 / 8,如果采用2^16 = 65536,那么每次集群内部服务器与服务器之间传输信息的心跳包就需要发送 65536 / 8 = 8192 bit,换算一下就是8KB;但如果采用 16384,每次传输的心跳包大小为 16384 / 8 = 2048,换算一下为 2KB。在网络传输过程中,2KB的数据包明显比8KB的数据包传输速率更快并且不容易出现丢包情况;
9.2. 为什么集群数量最好不超过1000个?
(1)但如果我们集群内部服务器节点较多,假设有10000台,每台节点互相传递都需要发送 2KB 的心跳包,非常容易网络拥堵。而且,16384个槽位,分配给1000台节点也够用了,所以不需要把节点数量设置的过大。
(2)此外,Redis 主节点的配置信息中它所负责的哈希槽是通过一张 bitmap 来进行压缩传输的,bitmap 的压缩率 = slots / N节点数量,如果节点数量过大,压缩率就会降低,如果槽位少节点还多的话,压缩率更低,不利于网络之间的传输;相反,如果槽位数量少,节点数量还多,压缩率就会很大,节点之间的传输速率也自然会提高。
10. Redis 不保证数据的强一致性
这个问题与微服务CAP定理有一定的相似性。我结合官网给出的回答,总结成了下面的一段话。
redis 集群中 master 主节点与 slave 从节点是采用的异步通信,也就是说用户向 master 主节点下达的写数据操作无法第一时间同步给 slave 从节点,而是 master 主节点通过发送复制文本传递给 slave 从节点让从节点同步数据。如果 master 主节点还没有来得及将客户端最新下达过来的写入数据命令复制到传输文本中就已经死亡,而且短时间内 master 主节点还无法恢复正常,那么新选举出来的 master 主节点就会丢失那一部分没来得及写入到复制传出文本中的最新客户段数据,客户在与新选组出来的 master 主节点进行数据交互时,是无法得到刚才用户已经在上一个 master 中存储的数据的,因为新 master 里面根本就没有,因此 Redis 集群无法保证数据的强一致性,而是选择了CAP理论中的 可用性(Availability)与分区容错性(Partition tolerance)。
11. Redis 集群配置属性
想要组建Redis 集群只需要在 redis.conf 配置文件中配置几个属性就可以了。如下图,
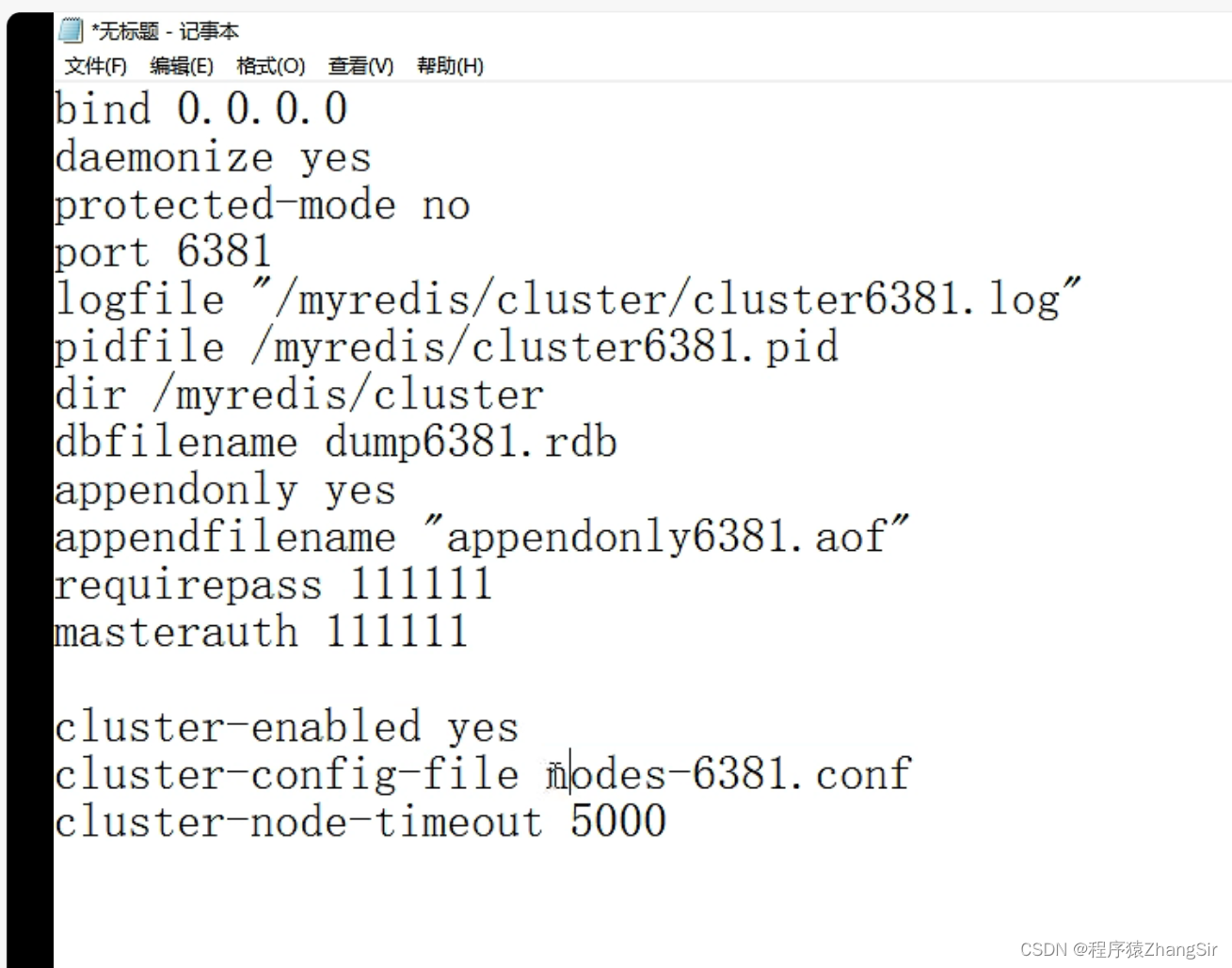
主要说最后三个,这三个才是集群的主要配置项
cluster-enable yes (yes 表示开启集群模式);
cluster-config-file (表示集群的配置文件名称,在另外的配置文件中再指定其它集群属性);
cluster-node-timeout (集群之间的超时时间);