前言
我们都知道数据库设计有以下三大范式,但实际应用中真的是按照这三大范式来设计吗?
本篇博客尝试阐述项目中数据库表的设计,以及查询优化的方法。
第一范式:
原子,列信息不可再分;
第二范式:
行是唯一的,有主键
代理主键:自增长的整数序列
第三范式:
其他列与主键都相关联,其他列之间无关联
目录
- 前言
- 引出
- 一、表的字段和查询优化问题
- 问题的引入
- 问题的分析
- 二、表的拆分和冗余字段
- 大表拆小表
- 冗余设计
- 三、实际应用中的数据库设计规范
- 总结
引出
1.表的列为什么不能太多?行锁
2.查询优化:大表拆小表、冗余字段存储;
3.实际中数据库设计规范:Innodb存储引擎,utf8mb4字符集. . .
一、表的字段和查询优化问题
问题的引入
1、一张表的列为什么不能太多?
2、开发中如何进行查询优化?
问题的分析
-
当一张表的字段太多,我们在更新列的时候,都会对表加一个行锁,我们的列越多,肯定加大我们我们锁行的概率。当同时更新一行中的不同列时,就会出现锁,导致mysql DML操作出现延迟等待。
-
数据冗余,浪费我们的IO的读写,例如我们的程序取数据的时候,直接select * from 操作的话,就会把所有列的数据取出来,这样比较浪费IO读写。
-
我们数据库中的日志的最小单元是一行记录,每次update记录日志时,都会保存每列的记录,会产生大量的日志
-
数据库冗余设计、大表拆小表、索引等。
二、表的拆分和冗余字段
大表拆小表
关于查询优化,除了从索引等层面回答外,也可以从数据库设计层面根本上提升查询性能,比如大表拆小表、冗余字段存储等。
比如:在我们设计数据库表的时候,面临表字段过多的情况下,我们需要充分考虑业务上的某些需求,将一些不常用的字段和常用的字段分离开来,这样能够让查询常用字段的时候速度得到一定的提升;
做到冷热数据分离,减小表的宽度,带来哪些好处?
- Mysql限制每个表最多存储4096列,并且每一行数据的大小不能超过65535字节;
- 减少磁盘IO,保证热数据的内存缓存命中率(表越宽,把表装载进内存缓冲池时所占用的内存也就越大,也会消耗更多的IO)
- 更有效的利用缓存,避免读入无用的冷数据
- 经常一起使用的列放到一个表中,可以避免更多的关联操作
冗余设计
适当的冗余,增加常用列、列的计算结果
数据库设计的实用原则是:在数据冗余和处理速度之间找到合适的平衡点。
满足范式的表一定是规范化的表,但不一定是最佳的设计。很多情况下会为了提高数据库的运行效率,常常需要降低范式标准:适当增加冗余,达到以空间换时间的目的。
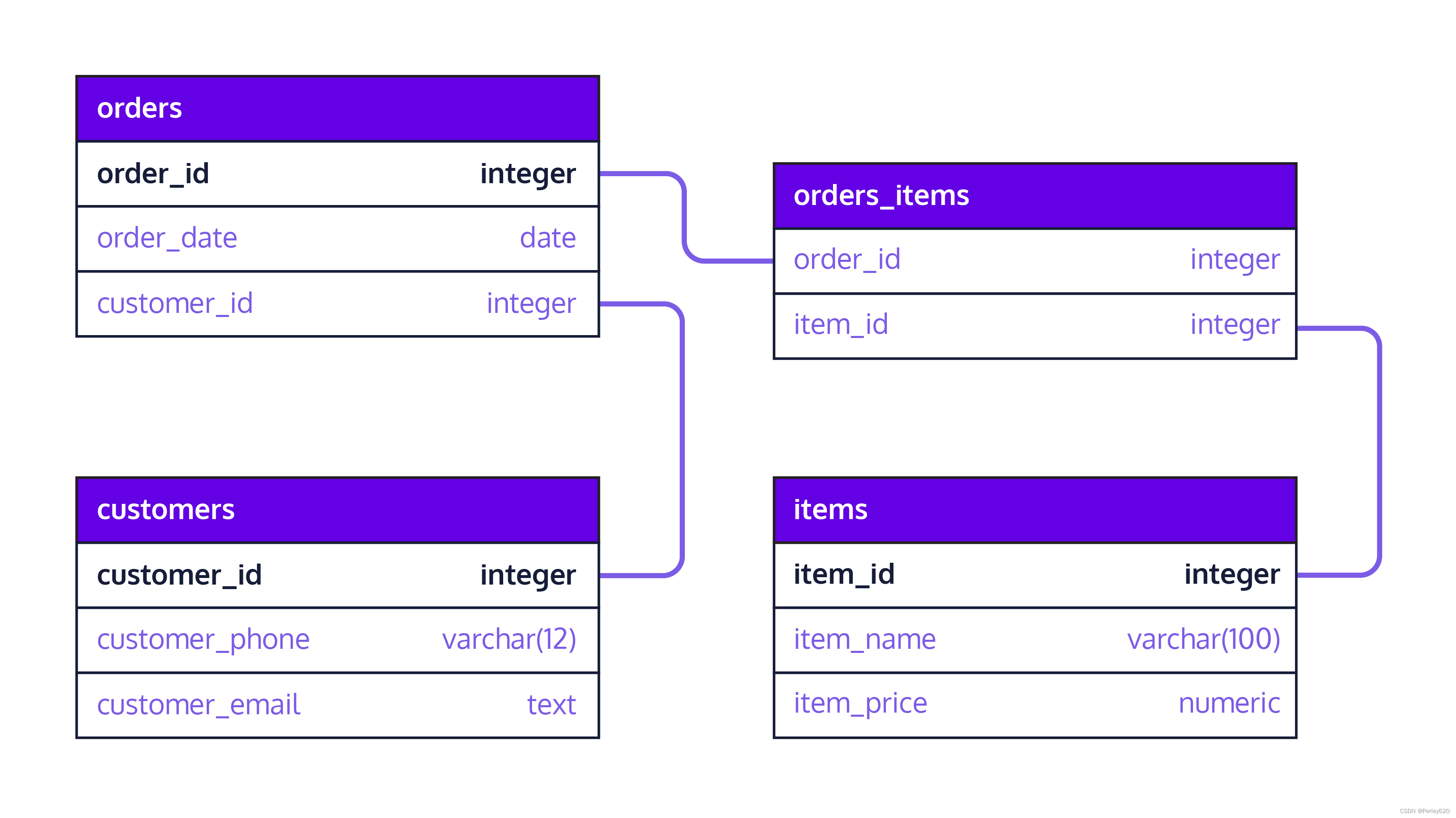
比如我们有一个product表,
| 产品名称 | 单价 | 库存量 | 总价值 |
|---|---|---|---|
| 华为手机 | 1999 | 10 | 19990 |
这个表是不满足第三范式的,因为“总价值”可以由“单价”乘以“数量”得到,说明“总价值”是冗余字段。但是,增加“总价值”这个冗余字段,可以提高查询统计的速度,这就是以空间换时间的作法。合理的冗余可以分散数据量大的表的并发压力,也可以加快特殊查询的速度。冗余字段也可以有效减少数据库表的连接,提高效率。
举例:这里有一个企业表:
| 企业ID | 企业名称 | 企业注册地 |
|---|---|---|
| 100 | 东方物流 | 上海 |
合同表:
| 合同编号 | 合同名称 | 签订企业(外键) | 企业名称 |
|---|---|---|---|
| WLHT101 | 配实合同 | 100 | 东方物流 |
上例中的合同表的“企业名称”就是冗余存储, 查询合同所属企业时候可以有效减少数据库表连接查询,提高查询效率。
三、实际应用中的数据库设计规范
(1)、遵循三大范式;允许合理的冗余设计
(2)、所有表必须使用Innodb存储引擎
没有特殊要求(即Innodb无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用Innodb存储引擎(mysql5.5之前默认使用Myisam,5.6以后默认的为Innodb)Innodb 支持事务(redo log)日志,支持行级锁,更好的恢复性,高并发下性能更好
(3)、库表字段名称禁止使用mysql保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来)
(4)、所有存储相同数据的列名和列类型必须一致(一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低)
(5)、数据库和表的字符集统一使用UTF8
兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效,如果数据库中有存储emoji表情的需要,字符集需要采用utf8mb4字符集
(6)、所有表和字段都需要添加注释
使用comment从句添加表和列的备注从一开始就进行数据字典的维护
(7)、尽量控制单表数据量的大小,建议控制在500万以内
500万并不是Mysql数据库的限制,过大会造成修改表结构,备份,恢复都会有很大的问题可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小
(8)、禁止在数据库中存储图片,文件等大的二进制数据
通常文件很大,会短时间内造成数据量快速增长,数据库进行数据库读取时,通常会进行大量的随机IO操作,文件很大时,IO操作很耗时通常存储于文件服务器,数据库只存储文件地址信息
(9)、优先选择符合存储需要的最小的数据类型
原因是:列的字段越大,建立索引时所需要的空间也就越大,这样一页中所能存储的索引节点的数量也就越少也越少,在遍历时所需要的IO次数也就越多,索引的性能也就越差
(10)、 避免使用TEXT、BLOB数据类型;最常见的TEXT类型可以存储64k的数据
-
建议:把BLOB或是TEXT列分离到单独的扩展表中。 -
Mysql内存临时表不支持TEXT、BLOB这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。而且对于这种数据,Mysql还是要进行二次查询,会使sql性能变得很差。 -
但也不是说一定不能使用这样的数据类型,如果一定要使用,建议把BLOB或是TEXT列分离到单独的扩展表中,查询时一定不要使用select *, 而只需要取出必要的列,不需要TEXT列的数据时不要对该列进行查询。 -
并且TEXT或BLOB类型只能使用前缀索引,因为MySQL对索引字段长度是有限制的,所以TEXT类型只能使用前缀索引,并且TEXT列上是不能有默认值的。 -
前缀索引:MySQL是支持前缀索引的,也就是说,你可以定义字符串的一部分作为索引。如果不指定前缀索引,那么索引就是整个字符串。 -
例子:alter table User add index index1(email); 创建的索引就是将email整个字符串作为索引alter table User add index index2(email(6)); 只取email字符串的前6个字节作为索引。
总结
1.表的列为什么不能太多?行锁
2.查询优化:大表拆小表、冗余字段存储;
3.实际中数据库设计规范:Innodb存储引擎,utf8mb4字符集. . .