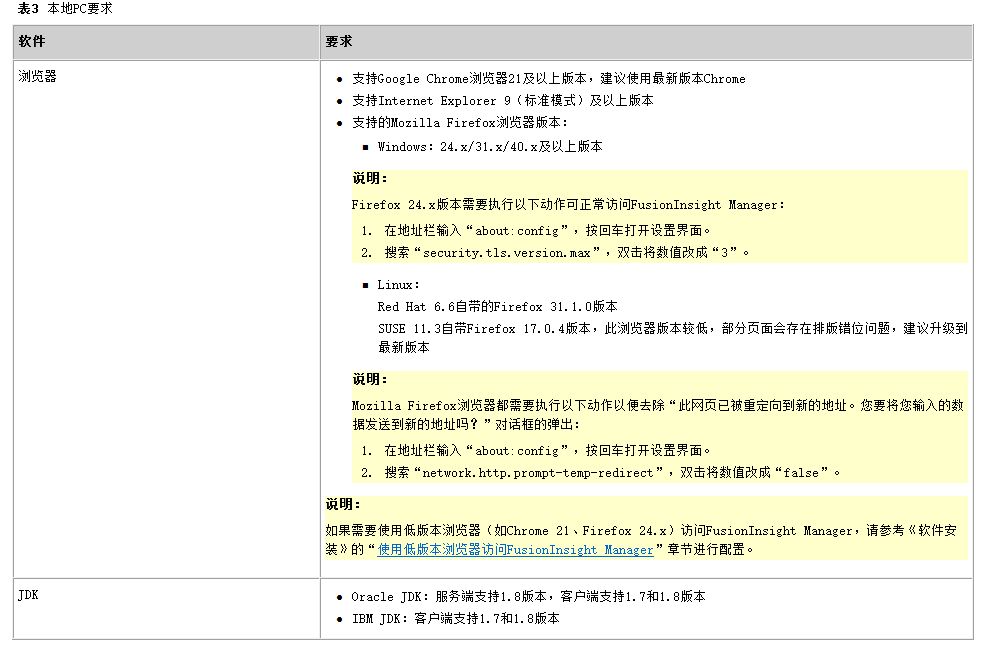
文章目录
- 概述
- 设计实现
- 通用的序列化接口
- 通用的序列化实现【推荐】 vs 专用的序列化实现
- 专用序列化接口定义
- 序列化实现

概述
网络传输和序列化这两部分的功能相对来说是非常通用并且独立的,在设计的时候,只要能做到比较好的抽象,这两部的实现,它的通用性是非常强的。不仅可以用于 RPC 框架中,同样可以直接拿去用于实现消息队列,或者其他需要互相通信的分布式系统中。
我们先来实现序列化和反序列化部分,因为后面的部分会用到序列化和反序列化。
设计实现
通用的序列化接口
首先我们需要设计一个可扩展的,通用的序列化接口,为了方便使用,我们直接使用静态类的方式来定义这个接口(严格来说这并不是一个接口)
public class SerializeSupport {
public static <E> E parse(byte [] buffer) {
// ...
}
public static <E> byte [] serialize(E entry) {
// ...
}
}
- parse 方法用于反序列化
- serialize 方法用于序列化
比如
// 序列化
MyClass myClassObject = new MyClass();
byte [] bytes = SerializeSupport.serialize(myClassObject);
// 反序列化
MyClass myClassObject1 = SerializeSupport.parse(bytes);
通用的序列化实现【推荐】 vs 专用的序列化实现
在讲解序列化和反序列化的时候说过,可以使用通用的序列化实现,也可以自己来定义专用的序列化实现。
- 专用的序列化性能最好,但缺点是实现起来比较复杂,你要为每一种类型的数据专门编写序列化和反序列化方法。
- 一般的 RPC 框架采用的都是通用的序列化实现,比如 gRPC 采用的是 Protobuf 序列化实现,Dubbo 支持 hession2 等好几种序列化实现
为什么这些 RPC 框架不像消息队列一样,采用性能更好的专用的序列化实现呢?这个原因很简单,消息队列它需要序列化数据的类型是固定的,只是它自己的内部通信的一些命令。但 RPC 框架,它需要序列化的数据是,用户调用远程方法的参数,这些参数可能是各种数据类型,所以必须使用通用的序列化实现,确保各种类型的数据都能被正确的序列化和反序列化。
我们这里还是采用专用的序列化实现,主要的目的是一起来实践一下,如何来实现序列化和反序列化
专用序列化接口定义
public interface Serializer<T> {
/**
* 计算对象序列化后的长度,主要用于申请存放序列化数据的字节数组
* @param entry 待序列化的对象
* @return 对象序列化后的长度
*/
int size(T entry);
/**
* 序列化对象。将给定的对象序列化成字节数组
* @param entry 待序列化的对象
* @param bytes 存放序列化数据的字节数组
* @param offset 数组的偏移量,从这个位置开始写入序列化数据
* @param length 对象序列化后的长度,也就是{@link Serializer#size(java.lang.Object)}方法的返回值。
*/
void serialize(T entry, byte[] bytes, int offset, int length);
/**
* 反序列化对象
* @param bytes 存放序列化数据的字节数组
* @param offset 数组的偏移量,从这个位置开始写入序列化数据
* @param length 对象序列化后的长度
* @return 反序列化之后生成的对象
*/
T parse(byte[] bytes, int offset, int length);
/**
* 用一个字节标识对象类型,每种类型的数据应该具有不同的类型值
*/
byte type();
/**
* 返回序列化对象类型的Class对象。
*/
Class<T> getSerializeClass();
}
这个接口中,除了 serialize 和 parse 这两个序列化和反序列化两个方法以外,还定义了下面这几个方法:
- size 方法计算序列化之后的数据长度,用于事先来申请存放序列化数据的字节数组;
- type 方法定义每种序列化实现的类型,这个类型值也会写入到序列化之后的数据中,主要的作用是在反序列化的时候,能够识别是什么数据类型的,以便找到对应的反序列化实现类;
- getSerializeClass 这个方法返回这个序列化实现类对应的对象类型,目的是,在执行序列化的时候,通过被序列化的对象类型找到对应序列化实现类
序列化实现
利用这个 Serializer 接口,我们就可以来实现 SerializeSupport 这个支持任何对象类型序列化的通用静态类了。
首先我们定义两个 Map,这两个 Map 中存放着所有实现 Serializer 接口的序列化实现类
private static Map<Class<?>/*序列化对象类型*/, Serializer<?>/*序列化实现*/> serializerMap = new HashMap<>();
private static Map<Byte/*序列化实现类型*/, Class<?>/*序列化对象类型*/> typeMap = new HashMap<>();
- serializerMap 中的 key 是序列化实现类对应的序列化对象的类型,它的用途是在序列化的时候,通过被序列化的对象类型,找到对应的序列化实现类。
- typeMap 的作用和 serializerMap 是类似的,它的 key 是序列化实现类的类型,用于在反序列化的时候,从序列化的数据中读出对象类型,然后找到对应的序列化实现类
理解了这两个 Map 的作用,实现序列化和反序列化这两个方法就很容易了。这两个方法的实现思路是一样的,都是通过一个类型在这两个 Map 中进行查找,查找的结果就是对应的序列化实现类的实例,也就是 Serializer 接口的实现,然后调用对应的序列化或者反序列化方法就可以了。
public class SerializeSupport {
private static final Logger logger = LoggerFactory.getLogger(SerializeSupport.class);
private static Map<Class<?>/*序列化对象类型*/, Serializer<?>/*序列化实现*/> serializerMap = new HashMap<>();
private static Map<Byte/*序列化实现类型*/, Class<?>/*序列化对象类型*/> typeMap = new HashMap<>();
static {
for (Serializer serializer : ServiceSupport.loadAll(Serializer.class)) {
registerType(serializer.type(), serializer.getSerializeClass(), serializer);
logger.info("Found serializer, class: {}, type: {}.",
serializer.getSerializeClass().getCanonicalName(),
serializer.type());
}
}
private static byte parseEntryType(byte[] buffer) {
return buffer[0];
}
private static <E> void registerType(byte type, Class<E> eClass, Serializer<E> serializer) {
serializerMap.put(eClass, serializer);
typeMap.put(type, eClass);
}
@SuppressWarnings("unchecked")
private static <E> E parse(byte [] buffer, int offset, int length, Class<E> eClass) {
Object entry = serializerMap.get(eClass).parse(buffer, offset, length);
if (eClass.isAssignableFrom(entry.getClass())) {
return (E) entry;
} else {
throw new SerializeException("Type mismatch!");
}
}
public static <E> E parse(byte [] buffer) {
return parse(buffer, 0, buffer.length);
}
private static <E> E parse(byte[] buffer, int offset, int length) {
byte type = parseEntryType(buffer);
@SuppressWarnings("unchecked")
Class<E> eClass = (Class<E> )typeMap.get(type);
if(null == eClass) {
throw new SerializeException(String.format("Unknown entry type: %d!", type));
} else {
return parse(buffer, offset + 1, length - 1,eClass);
}
}
public static <E> byte [] serialize(E entry) {
@SuppressWarnings("unchecked")
Serializer<E> serializer = (Serializer<E>) serializerMap.get(entry.getClass());
if(serializer == null) {
throw new SerializeException(String.format("Unknown entry class type: %s", entry.getClass().toString()));
}
byte [] bytes = new byte [serializer.size(entry) + 1];
bytes[0] = serializer.type();
serializer.serialize(entry, bytes, 1, bytes.length - 1);
return bytes;
}
}
所有的 Serializer 的实现类是怎么加载到 SerializeSupport 的那两个 Map 中的呢?这里面利用了 Java 的一个 SPI 类加载机制
public class ServiceSupport {
private final static Map<String, Object> singletonServices = new HashMap<>();
public synchronized static <S> S load(Class<S> service) {
return StreamSupport.
stream(ServiceLoader.load(service).spliterator(), false)
.map(ServiceSupport::singletonFilter)
.findFirst().orElseThrow(ServiceLoadException::new);
}
public synchronized static <S> Collection<S> loadAll(Class<S> service) {
return StreamSupport.
stream(ServiceLoader.load(service).spliterator(), false)
.map(ServiceSupport::singletonFilter).collect(Collectors.toList());
}
@SuppressWarnings("unchecked")
private static <S> S singletonFilter(S service) {
if(service.getClass().isAnnotationPresent(Singleton.class)) {
String className = service.getClass().getCanonicalName();
Object singletonInstance = singletonServices.putIfAbsent(className, service);
return singletonInstance == null ? service : (S) singletonInstance;
} else {
return service;
}
}
}
到这里,我们就封装好了一个通用的序列化的接口,
-
对于使用序列化的模块来说,它只要依赖 SerializeSupport 这个静态类,调用它的序列化和反序列化方法就可以了,不需要依赖任何序列化实现类。
-
对于序列化实现的提供者来说,也只需要依赖并实现 Serializer 这个接口就可以了。
比如,我们的 HelloService 例子中的参数是一个 String 类型的数据,我们需要实现一个支持 String 类型的序列化实现
public class StringSerializer implements Serializer<String> {
@Override
public int size(String entry) {
return entry.getBytes(StandardCharsets.UTF_8).length;
}
@Override
public void serialize(String entry, byte[] bytes, int offset, int length) {
byte [] strBytes = entry.getBytes(StandardCharsets.UTF_8);
System.arraycopy(strBytes, 0, bytes, offset, strBytes.length);
}
@Override
public String parse(byte[] bytes, int offset, int length) {
return new String(bytes, offset, length, StandardCharsets.UTF_8);
}
@Override
public byte type() {
return Types.TYPE_STRING;
}
@Override
public Class<String> getSerializeClass() {
return String.class;
}
}
在把 String 和 byte 数组做转换的时候,一定要指定编码方式,确保序列化和反序列化的时候都使用一致的编码,我们这里面统一使用 UTF8 编码。否则,如果遇到执行序列化和反序列化的两台服务器默认编码不一样,就会出现乱码。我们在开发过程用遇到的很多中文乱码问题,绝大部分都是这个原因
还有一个更复杂的序列化实现 MetadataSerializer,用于将注册中心的数据持久化到文件中
/**
* Size of the map 2 bytes
* Map entry:
* Key string:
* Length: 2 bytes
* Serialized key bytes: variable length
* Value list
* List size: 2 bytes
* item(URI):
* Length: 2 bytes
* serialized uri: variable length
* item(URI):
* ...
* Map entry:
* ...
*
*/
public class MetadataSerializer implements Serializer<Metadata> {
@Override
public int size(Metadata entry) {
return Short.BYTES + // Size of the map 2 bytes
entry.entrySet().stream()
.mapToInt(this::entrySize).sum();
}
@Override
public void serialize(Metadata entry, byte[] bytes, int offset, int length) {
ByteBuffer buffer = ByteBuffer.wrap(bytes, offset, length);
buffer.putShort(toShortSafely(entry.size()));
entry.forEach((k,v) -> {
byte [] keyBytes = k.getBytes(StandardCharsets.UTF_8);
buffer.putShort(toShortSafely(keyBytes.length));
buffer.put(keyBytes);
buffer.putShort(toShortSafely(v.size()));
for (URI uri : v) {
byte [] uriBytes = uri.toASCIIString().getBytes(StandardCharsets.UTF_8);
buffer.putShort(toShortSafely(uriBytes.length));
buffer.put(uriBytes);
}
});
}
private int entrySize(Map.Entry<String, List<URI>> e) {
// Map entry:
return Short.BYTES + // Key string length: 2 bytes
e.getKey().getBytes().length + // Serialized key bytes: variable length
Short.BYTES + // List size: 2 bytes
e.getValue().stream() // Value list
.mapToInt(uri -> {
return Short.BYTES + // Key string length: 2 bytes
uri.toASCIIString().getBytes(StandardCharsets.UTF_8).length; // Serialized key bytes: variable length
}).sum();
}
@Override
public Metadata parse(byte[] bytes, int offset, int length) {
ByteBuffer buffer = ByteBuffer.wrap(bytes, offset, length);
Metadata metadata = new Metadata();
int sizeOfMap = buffer.getShort();
for (int i = 0; i < sizeOfMap; i++) {
int keyLength = buffer.getShort();
byte [] keyBytes = new byte [keyLength];
buffer.get(keyBytes);
String key = new String(keyBytes, StandardCharsets.UTF_8);
int uriListSize = buffer.getShort();
List<URI> uriList = new ArrayList<>(uriListSize);
for (int j = 0; j < uriListSize; j++) {
int uriLength = buffer.getShort();
byte [] uriBytes = new byte [uriLength];
buffer.get(uriBytes);
URI uri = URI.create(new String(uriBytes, StandardCharsets.UTF_8));
uriList.add(uri);
}
metadata.put(key, uriList);
}
return metadata;
}
@Override
public byte type() {
return Types.TYPE_METADATA;
}
@Override
public Class<Metadata> getSerializeClass() {
return Metadata.class;
}
private short toShortSafely(int v) {
assert v < Short.MAX_VALUE;
return (short) v;
}
}
到这里序列化的部分就实现完成了。我们这个序列化的实现,对外提供服务的就只有一个 SerializeSupport 静态类,并且可以通过扩展支持序列化任何类型的数据,这样一个通用的实现,不仅可以用在我们这个 RPC 框架的例子中,完全可以把这部分直接拿过去用在业务代码中