GD


梯度下降法的含义是通过当前点的梯度(偏导数)的反方向寻找到新的迭代点,并从当前点移动到新的迭代点继续寻找新的迭代点,直到找到最优解,梯度下降的目的,就是为了最小化损失函数。


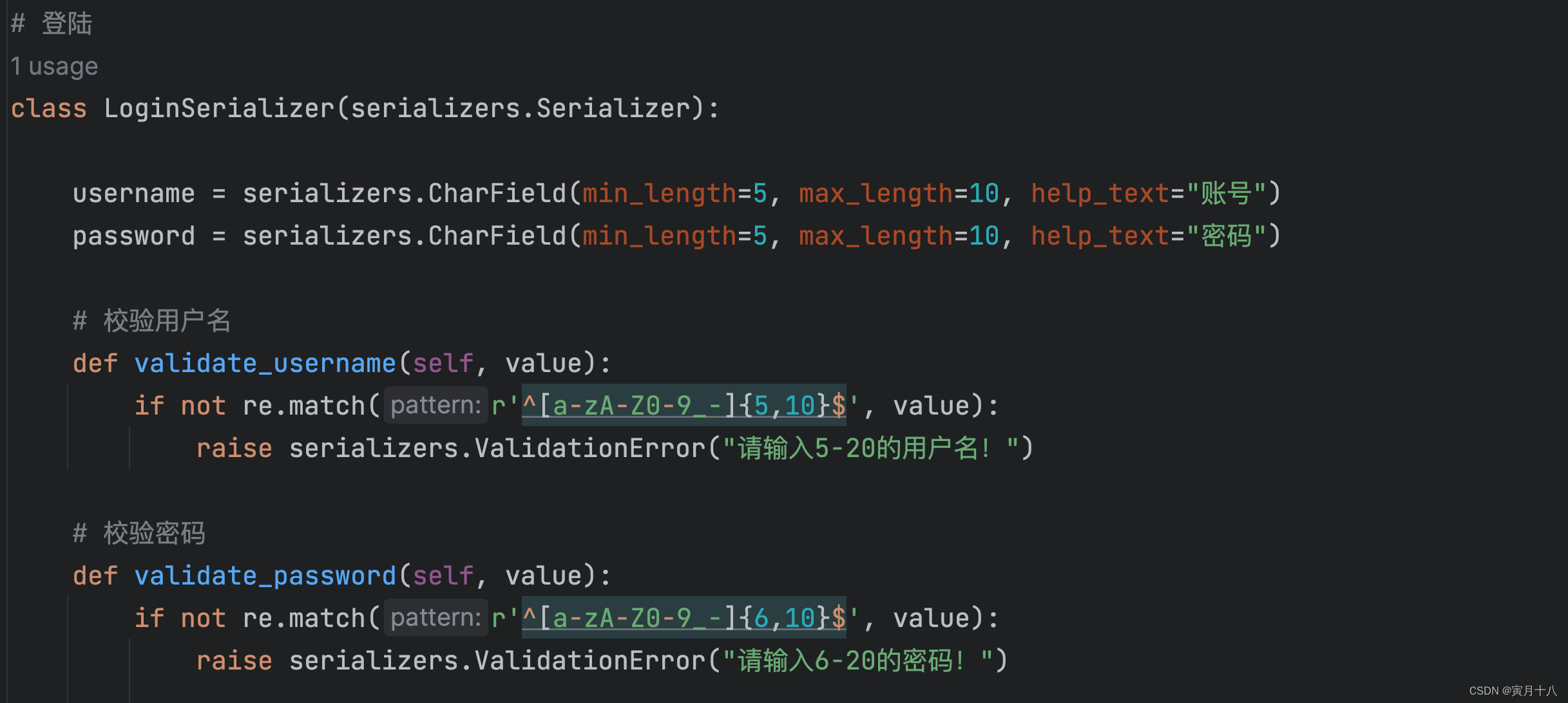
1、给定待优化连续可微分的函数J(θ),学习率或步长,以及一组初始值(真实值)
2、计算待优化函数梯度
3、更新迭代
4、再次计算新的梯度
5、计算向量的模来判断是否需要终止循环
三种梯度下降法
- 批量梯度下降法(Batch Gradient Descent,BGD):每次迭代时(每次计算梯度)使用所有样本来进行梯度的更新
- 随机梯度下降法(Stochastic Gradient Descent,SGD):每次迭代的过程中,仅通过随机选择的一个样本计算梯度
- 小批量梯度下降法(Mini-Batch Gradient Descent,MBGD):对BGD和SGD进行了折中,每次迭代时,抽取一部分(batch-size)训练样本,进行梯度的运算
- 轮次:epoch,训练数据集学习的轮数
- 批次:batch,如果训练数据集较大,一轮要学习太多数据,那就把一轮次要学习的 数据分成多个批次,一批一批数据地学习
简单实例f(x) = x^2
import numpy as np
# 目标函数:f(x) = x^2
def target_function(x):
return x**2
# 目标函数的导数:f'(x) = 2x
def gradient(x):
return 2 * x
# 梯度下降算法
def gradient_descent(learning_rate, num_iterations, initial_x):
x = initial_x
for i in range(num_iterations):
grad = gradient(x)
x -= learning_rate * grad
cost = target_function(x)
print(f"Iteration {i+1}: x = {x}, f(x) = {cost}")
return x
# 初始参数值和超参数设置
learning_rate = 0.1
num_iterations = 10
initial_x = 5
# 运行梯度下降算法
final_x = gradient_descent(learning_rate, num_iterations, initial_x)
print(f"最优解:x = {final_x}, f(x) = {target_function(final_x)}")