文章目录
- 1 加载数据集
- 2 构思算法的流程
- 3 Pipeline执行流程的分析
- Reference
- Statement
一个典型的机器学习构建包含若干个过程
- 源数据ETL
- 数据预处理
- 特征选取
- 模型训练与验证
一个典型的机器学习构建包含若干个过程
以上四个步骤可以抽象为一个包括多个步骤的流水线式工作,从数据收集开始至输出我们需要的最终结果。因此,对以上多个步骤、进行抽象建模,简化为流水线式工作流程则存在着可行性,对利用spark进行机器学习的用户来说,流水线式机器学习比单个步骤独立建模更加高效、易用。
管道机制在机器学习算法中得以应用的根源在于,参数集在新数据集(比如测试集)上的重复使用。
管道机制实现了对全部步骤的流式化封装和管理(streaming workflows with pipelines)。注意:管道机制更像是编程技巧的创新,而非算法的创新。
接下来我们以一个具体的例子来演示sklearn库中强大的Pipeline用法:
1 加载数据集
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelEncoder
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/'
'breast-cancer-wisconsin/wdbc.data', header=None)
# Breast Cancer Wisconsin dataset
X, y = df.values[:, 2:], df.values[:, 1]
# y为字符型标签
# 使用LabelEncoder类将其转换为0开始的数值型
encoder = LabelEncoder()
y = encoder.fit_transform(y)
>>> encoder.transform(['M', 'B'])
array([1, 0])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.2, random_state=0)
2 构思算法的流程
可放在Pipeline中的步骤可能有:
- 特征标准化是需要的,可作为第一个环节
- 既然是分类器,classifier也是少不了的,自然是最后一个环节
- 中间可加上比如数据降维(PCA)
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
pipe_lr = Pipeline([('sc', StandardScaler()),
('pca', PCA(n_components=2)),
('clf', LogisticRegression(random_state=1))
])
pipe_lr.fit(X_train, y_train)
print('Test accuracy: %.3f' % pipe_lr.score(X_test, y_test))
# Test accuracy: 0.947
Pipeline对象接受二元tuple构成的list,每一个二元 tuple 中的第一个元素为 arbitrary identifier string,我们用以获取(access)Pipeline object 中的 individual elements,二元 tuple 中的第二个元素是 scikit-learn与之相适配的transformer 或者 estimator。
Pipeline([('sc', StandardScaler()), ('pca', PCA(n_components=2)), ('clf', LogisticRegression(random_state=1))])
3 Pipeline执行流程的分析
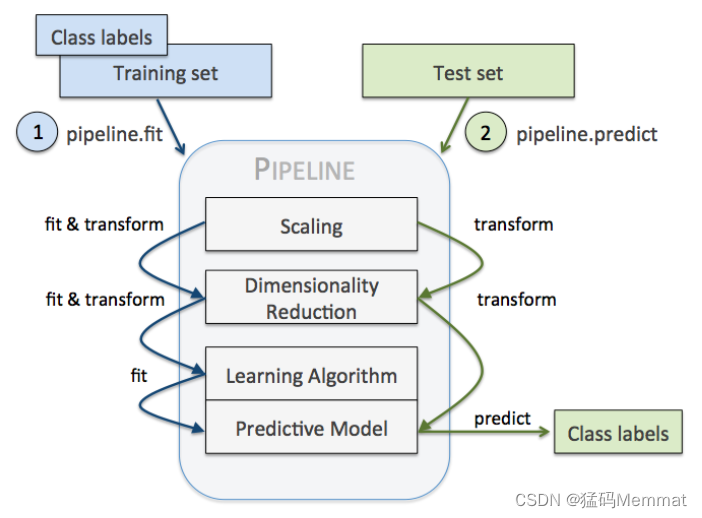
Pipeline 的中间过程由scikit-learn相适配的转换器(transformer)构成,最后一步是一个estimator。比如上述的代码,StandardScaler和PCA transformer 构成intermediate steps,LogisticRegression 作为最终的estimator。
当我们执行 pipe_lr.fit(X_train, y_train)时,首先由StandardScaler在训练集上执行 fit 和 transform 方法,transformed后的数据又被传递给Pipeline对象的下一步,也即PCA()。和StandardScaler一样,PCA也是执行 fit 和 transform 方法,最终将转换后的数据传递给 LosigsticRegression。整个流程如下图所示:
Reference
https://blog.csdn.net/lanchunhui/article/details/50521648
Statement
本文未经专业测试和评审,欢迎在评论区反馈和讨论问题。