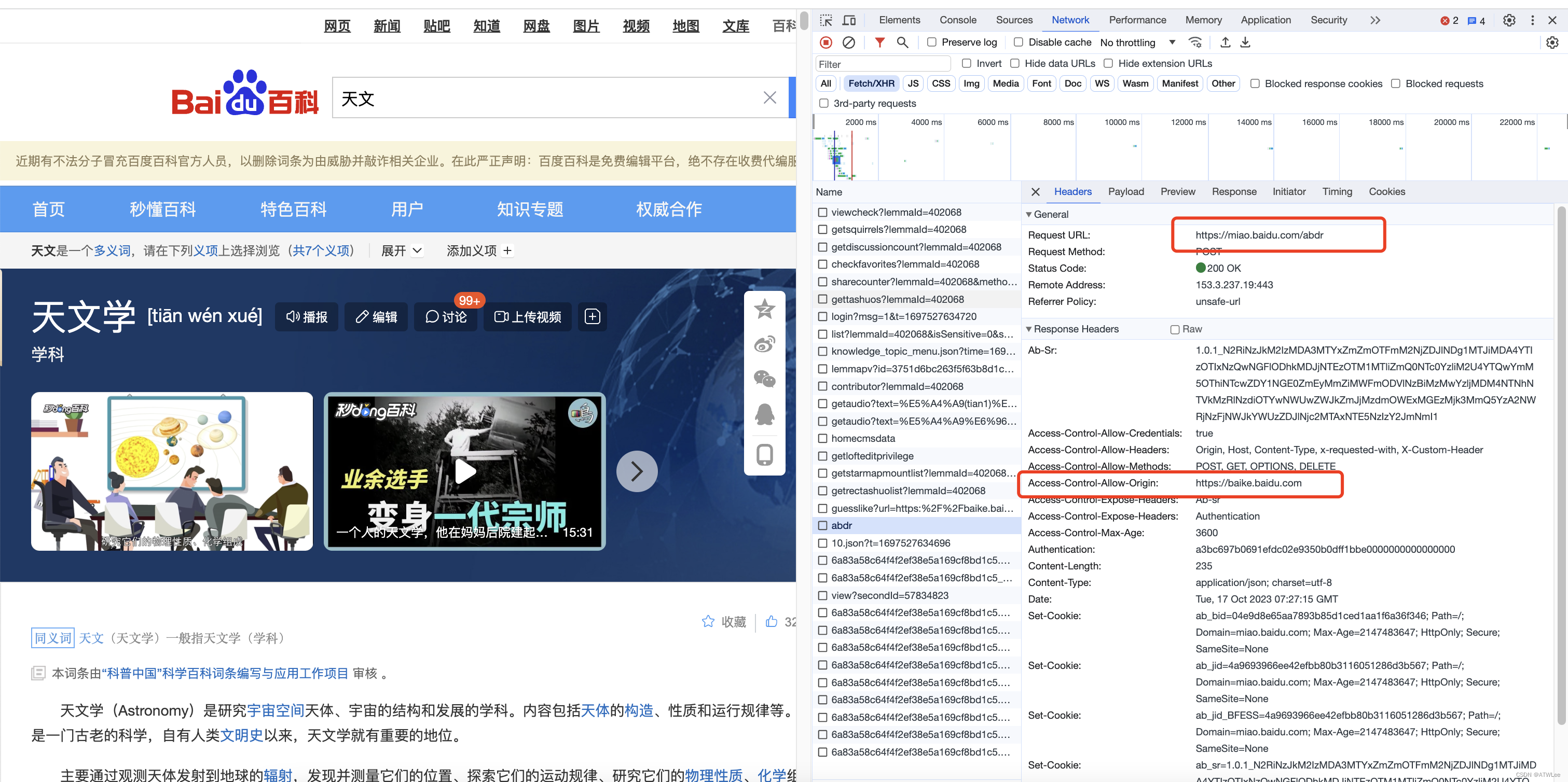
目录
1. 二叉树的链式存储:
2. 二叉树的前序遍历:
3. 二叉树的中序遍历:
4. 二叉树的后序遍历:
5. 统计二叉树的结点总数
6.统计二叉树的叶子结点数:
7. 统计二叉树第层的结点数量:
8. 二叉树的销毁:
9.查找树中值为结点:
10. 二叉树的层序遍历:
11. 代码总览:
11.1 头文件TRLIst.h
11.2 函数实现文件TRList.c
11.3 函数测试文件Test.c
在数据结构的第七篇文章中提到,对于完全二叉树而言,可以采用顺序存储的方法来存储完全二叉树。但是对于非完全二叉树而言,(例如下图中给出的二叉树)存储方法需要采用链式存储。本文将围绕二叉树的链式存储展开,介绍链式存储方法以及此类二叉树相关功能的实现。

1. 二叉树的链式存储:
在前几篇文章介绍完全二叉树及堆的代码实现时,会涉及到此类数据结构的插入结点、删除结点等特点。但是,对于非完全二叉树,由于结构并不像完全二叉树一样有一定规律,因此,利用非完全二叉树存储数据的操作较为复杂。并且,在存储数据这一方面,之前的完全二叉树更为合适。所以,对于普通的非完全二叉树来说,插入、删除结点的操作是没有意义的。
对于非完全二叉树的价值,主要是体现于后续更复杂的数据结构中,例如红黑树等。因此,文章后续实现的功能主要是利用递归来针对于非完全二叉树自身而言,例如求非完全二叉树的叶子结点数目,二叉树的深度等等。在二叉树的链式存储这一部分,将通过构建关于新建结点函数来手动构建上图给出的非完全二叉树。
对于非完全二叉树,在关于树的基础的文章中就提到,链式存储的方法可以归结为左孩子,右兄弟。所以,树的结点的结构如下:
typedef int TRDataType;
typedef struct TreeNode
{
TRDataType val;
struct TreeNode* left;
struct TreeNode* right;
}TRNode; 在确立了二叉树结点的结构之后,下一步构建函数,代码如下:
TRNode* BuyTRNode(int x)
{
TRNode* newnode = (TRNode*)malloc(sizeof(TRNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->val = x;
newnode->left = NULL;
newnode->right = NULL;
return newnode;
}下一步,通过上面的两个函数,直接构建出上图中给出的非完全二叉树,即:
int main()
{
TRNode* node1 = BuyTRNode(1);
TRNode* node2 = BuyTRNode(2);
TRNode* node3 = BuyTRNode(3);
TRNode* node4 = BuyTRNode(4);
TRNode* node5 = BuyTRNode(5);
TRNode* node6 = BuyTRNode(6);
node1->left = node2;
node1->right = node4;
node2->left = node3;
node4->left = node5;
node4->right = node6;
return 0;
}(注: 文章后续所有的运行结果均需要适配相应的测试代码,测试代码将在文章最后统一给出)
2. 二叉树的前序遍历:
对于二叉树的前序遍历,其顺序是按照:根结点,左结点,右结点进行访问的,例如对于上面给出的树:其结点访问顺序依次为(注:将空看作结点):1,2,3,
,
,
,4,5,
,
,6,
,
。
利用图形来表示结点访问的顺序,即:
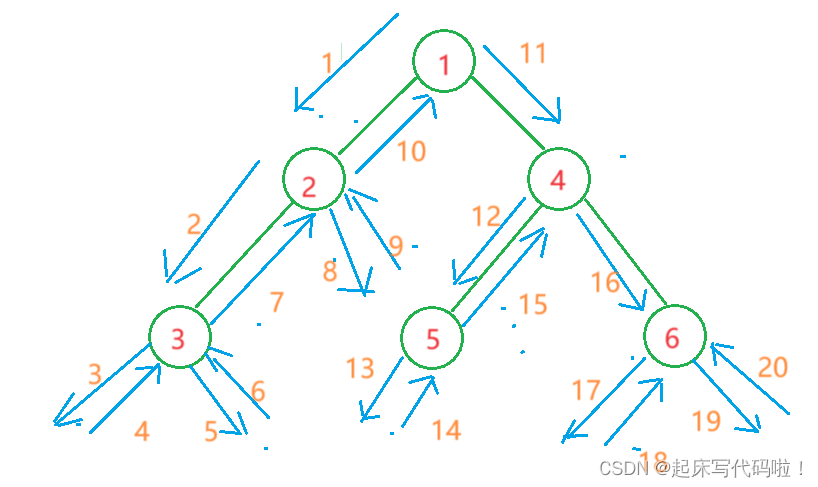
其中均代表访问到空结点,
代表访问到空结点后,返回上一个结点。在结点访问的过程中,每个结点都是按照:根结点、左结点、右结点的顺序。因此,对于这种重复性的问题,可以使用递归实现,具体代码如下:
//前序遍历
void PreOrder(TRNode* root)
{
if (root == NULL)
{
return;
}
//访问根结点:
printf("%d ", root->val);
//访问左结点:
PreOrder(root->left);
//访问右结点:
PreOrder(root->right);
}运行结果如下:

3. 二叉树的中序遍历:
二叉树的中序遍历顺序为:左结点、根结点、右结点,依旧针对于上面给出的二叉树,中序遍历对于结点的访问顺序为:,3,
,2,
,1,
,5,
,4,
,6
。用图片表示结点的访问顺序,即:
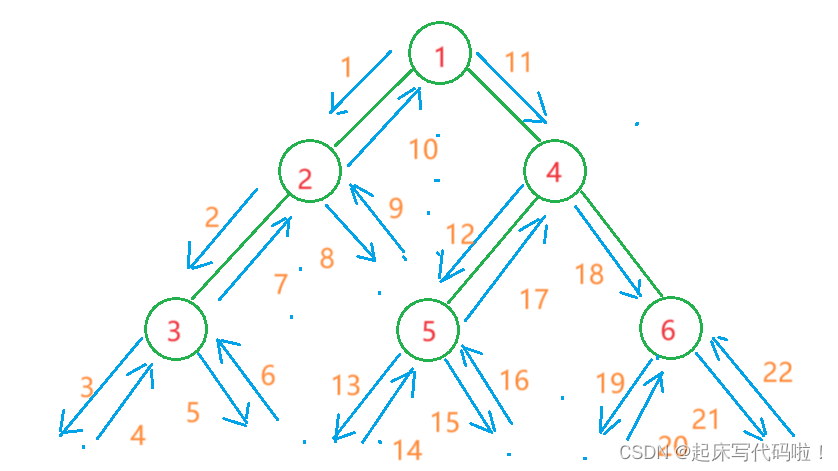
对应代码如下:
//中序遍历
void InOrder(TRNode* root)
{
if (root == NULL)
{
return;
}
//访问左结点:
InOrder(root->left);
//访问根结点:
printf("%d ", root->val);
//访问右结点:
InOrder(root->right);
}结果如下:

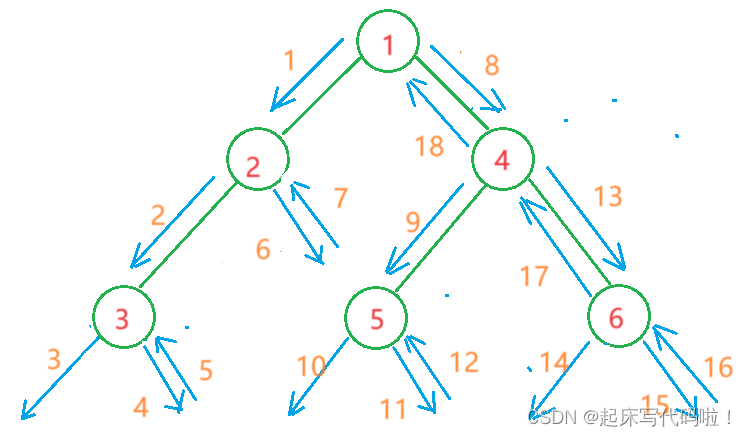
4. 二叉树的后序遍历:
二叉树的后序遍历顺序为:左结点,右结点,根结点。针对上方给出的二叉树,后序遍历访问结点的顺序依次为:,
,
,
,
,
,
,
,
,
,
,
,
。
用图形表示结点的访问顺序,即:
对应代码如下:
//后序遍历
void PostOrder(TRNode* root)
{
if (root == NULL)
{
return;
}
//访问左结点:
InOrder(root->left);
//访问右结点:
InOrder(root->right);
//访问根结点:
printf("%d ", root->val);
}结果如下:

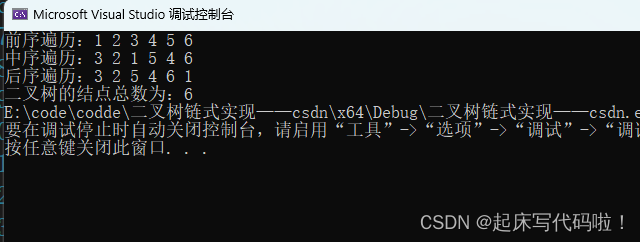
5. 统计二叉树的结点总数
对于统计二叉树的结点总数这一功能,可以拆分为以下步骤利用递归进行实现:
1. 检测结点是否为空,如果为空,则表示结点为空,即不存在此结点,返回。如果不为空,则表示存在本结点,结果加1并且向下检测本结点的左、右结点。
2.在检测结点时,需要检测结点的左、右结点,检测方法参考1
具体代码如下:
//统计二叉树的结点树:
int TreeSize(TRNode* root)
{
if (root == NULL)
{
return 0;
}
return TreeSize(root->left) + TreeSize(root->right) + 1;
}测试结果如下:
6.统计二叉树的叶子结点数:
对于统计二叉树叶子结点数的功能实现,可以分成下面的部分:
1. 检测本结点是否符合叶子结点的特点,即:,并且
。如果符合,则返回值返回
。
2.若本结点不符合1中的判定条件,则存在两种情况,一是本结点为空,二是本结点为分支结点。对于第一种情况,返回值返回,对于第二种情况,则继续向下检测本结点的子结点,即
对应代码为:
//统计二叉树的叶子结点数:
int TreeLeafSize(TRNode* root)
{
if (root == NULL)
{
return 0;
}
if (root->left == NULL && root->right == NULL)
{
return 1;
}
return TreeLeafSize(root->left) + TreeLeafSize(root->right);
}运行结果如下:
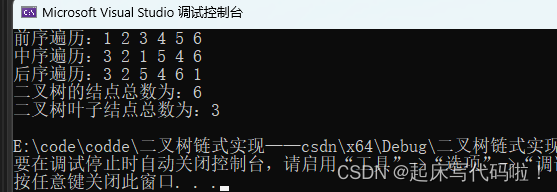
符合上图中的叶子结点数量。
7. 统计二叉树第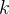 层的结点数量:
层的结点数量:
对于此功能的实现,同样可以分为下面的几步:
1.额外创建一个变量,用
来间接表示二叉树的层数,每经过依次递归,对
进行一次
的操作。当
时,表示已经到达目标层数。此时,如果目标层存在结点,则返回值返回
.
2.当时,表示还未到达目标层数,继续向下遍历该结点左、右两个子结点。
3.在函数传参的时候,需要注意,不能传递,需要传递
。具体代码如下:
//统计二叉树第k层结点数
int TNodeSize(TRNode* root, int k)
{
if (root == NULL)
{
return 0;
}
if (k == 0)
{
return 1;
}
return TNodeSize(root->left, k - 1) + TNodeSize(root->right, k - 1);
}运行结果如下:

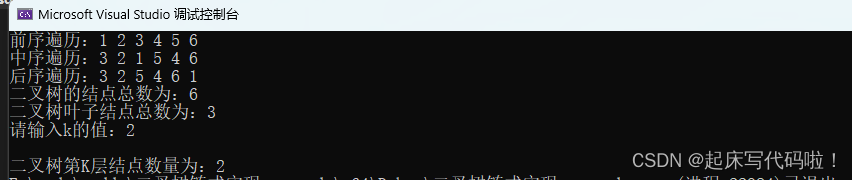


结点数量符合上方给出的二叉树。
8. 二叉树的销毁:
原理较为简单,只给出代码,不做过多解释:
//二叉树的销毁
void TNodeDestory(TRNode* root)
{
if (root == NULL)
{
return;
}
TNodeDestory(root->left);
TNodeDestory(root->right);
free(root);
}9.查找树中值为 结点:
结点:
对于查找树中值为的结点这一功能,可以分成下面的步骤实现:
1. 检测本结点是否为空,如果为空则返回。
2.若本结点不为空,则检测本结点中存储的数值是否,若符合条件,则返回该结点的地址。
3.此时,结点即不为空,结点中存储的数值也,因此,继续遍历该结点的左、右两个子结点。
对于函数返回值的处理,可以在函数中额外创建一个函数指针,为了方便表达,将这个指针命名为。
如果函数的根结点中存储的数值就是,则直接返回该结点指针。如果不等于,按照上面的思路,函数会继续遍历根结点的子结点。直接令
接收函数的返回值,并且,在遍历的后方加上对于
的判定。由于
的返回值只存在两种情况,即
。所以,如果
返回值不为
,则不允许返回返回值。判定
的返回值为
,则返回返回值。如果在函数遍历的过程中,所有的
都不允许返回,则表示树种不存在存储数值为
的结点。直接返回
对应代码如下:
//查找树中值为x的结点:
TRNode* TRFind(TRNode* root,int x)
{
if (root == NULL)
{
return NULL;
}
if (root->val = x)
{
return root;
}
TRNode* ret = NULL;
ret = TRFind(root->left, x);
if (ret)
{
return ret;
}
ret = TRFind(root->right, x);
if (ret)
{
return ret;
}
return NULL;
}运行结果如下:
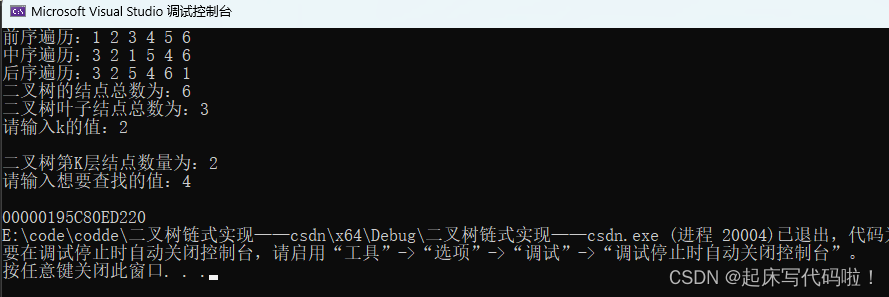
10. 二叉树的层序遍历:
对于二叉树的层序遍历,由于需要每一层挨个访问结点,因此,不能再用前面递归的思想来实现此功能 。如果不采用递归,则必须对每个结点的数值进行一次存储。所以,文章这里利用队列来辅助实现二叉树的层序遍历
(注:关于队列的相关知识及代码,可在前面的文章一起学数据结构(6)——栈和队列-CSDN博客获取,需要注意,在实现本功能时,需要将队列头文件中,
改成
以便匹配后序的返回值)
实现本功能的具体思路如下:
1. 创建一个队列,为了方便表达,将这个队列命名为。
2. 先往队列中利用插入函数插入二叉树根结点的数值。
3. 创建一个指针,命名为,利用这个指针来接受
函数(取队头元素函数)的返回值(返回值返回该结点的地址)。
4.按照层序遍历的顺序(即:一层一层,从左到右访问结点),向队列中插入数据,顺序为:插入左子结点,插入右子结点
5.销毁队头指针,利用循环配合上述步骤来完成对整个二叉树的访问,判定条件为(探空函数)
对应代码如下:
//层序遍历
void LevelOrder(Que* qs,TRNode* root)
{
if(root)
QueuePush(qs, root);
while (!QueueEmpty(qs))
{
TRNode* violent = QueueFront(qs);
printf("%d ", violent->val);
if (violent->left)
QueuePush(qs,violent->left);
if (violent->right)
QueuePush(qs,violent->right);
QueuePop(qs);
}
}运行结果如下: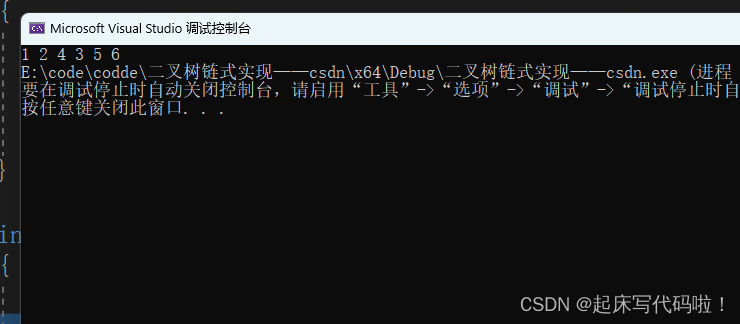
11. 代码总览:
11.1 头文件TRLIst.h
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int TRDataType;
typedef struct TreeNode
{
TRDataType val;
struct TreeNode* left;
struct TreeNode* right;
}TRNode;
#include"queue.h"
//结点插入函数
TRNode* BuyTRNode(int x);
//前序遍历
void PreOrder(TRNode* root);
//中序遍历
void InOrder(TRNode* root);
//后序遍历
void PostOrder(TRNode* root);
//统计二叉树的结点树:
int TreeSize(TRNode* root);
//统计二叉树的叶子结点数:
int TreeLeafSize(TRNode* root);
//统计二叉树第k层结点数
int TNodeSize(TRNode* root, int k);
//二叉树的销毁
void TNodeDestory(TRNode* root);
//查找树中值为x的结点:
TRNode* TRFind(TRNode* root, int x);
//层序遍历
void LevelOrder(Que* qs,TRNode* root);
11.2 函数实现文件TRList.c
#include"TRList.h"
//结点插入函数
TRNode* BuyTRNode(int x)
{
TRNode* newnode = (TRNode*)malloc(sizeof(TRNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->val = x;
newnode->left = NULL;
newnode->right = NULL;
return newnode;
}
//前序遍历
void PreOrder(TRNode* root)
{
if (root == NULL)
{
return;
}
//访问根结点:
printf("%d ", root->val);
//访问左结点:
PreOrder(root->left);
//访问右结点:
PreOrder(root->right);
}
//中序遍历
void InOrder(TRNode* root)
{
if (root == NULL)
{
return;
}
//访问左结点:
InOrder(root->left);
//访问根结点:
printf("%d ", root->val);
//访问右结点:
InOrder(root->right);
}
//后序遍历
void PostOrder(TRNode* root)
{
if (root == NULL)
{
return;
}
//访问左结点:
InOrder(root->left);
//访问右结点:
InOrder(root->right);
//访问根结点:
printf("%d ", root->val);
}
//统计二叉树的结点树:
int TreeSize(TRNode* root)
{
if (root == NULL)
{
return 0;
}
return TreeSize(root->left) + TreeSize(root->right) + 1;
}
//统计二叉树的叶子结点数:
int TreeLeafSize(TRNode* root)
{
if (root == NULL)
{
return 0;
}
if (root->left == NULL && root->right == NULL)
{
return 1;
}
return TreeLeafSize(root->left) + TreeLeafSize(root->right);
}
//统计二叉树第k层结点数
int TNodeSize(TRNode* root, int k)
{
if (root == NULL)
{
return 0;
}
if (k == 0)
{
return 1;
}
return TNodeSize(root->left, k - 1) + TNodeSize(root->right, k - 1);
}
//二叉树的销毁
void TNodeDestory(TRNode* root)
{
if (root == NULL)
{
return;
}
TNodeDestory(root->left);
TNodeDestory(root->right);
free(root);
}
//查找树中值为x的结点:
TRNode* TRFind(TRNode* root,int x)
{
if (root == NULL)
{
return NULL;
}
if (root->val = x)
{
return root;
}
TRNode* ret = NULL;
ret = TRFind(root->left, x);
if (ret)
{
return ret;
}
ret = TRFind(root->right, x);
if (ret)
{
return ret;
}
return NULL;
}
//层序遍历
void LevelOrder(Que* qs,TRNode* root)
{
if(root)
QueuePush(qs, root);
while (!QueueEmpty(qs))
{
TRNode* violent = QueueFront(qs);
printf("%d ", violent->val);
if (violent->left)
QueuePush(qs,violent->left);
if (violent->right)
QueuePush(qs,violent->right);
QueuePop(qs);
}
}11.3 函数测试文件Test.c
#include"TRList.h"
void TestOrder(TRNode* root)
{
printf("前序遍历:");
PreOrder(root);
printf("\n");
printf("中序遍历:");
InOrder(root);
printf("\n");
printf("后序遍历:");
PostOrder(root);
printf("\n");
}
void TestNode(TRNode* root)
{
printf("二叉树的结点总数为:");
int sum = TreeSize(root);
printf("%d ", sum);
printf("\n");
int sum1 = TreeLeafSize(root);
printf("二叉树叶子结点总数为:");
printf("%d ", sum1);
printf("\n");
int k = 0;
printf("请输入k的值:");
scanf("%d", &k);
int sum2 = TNodeSize(root, k-1);
printf("\n");
printf("二叉树第K层结点数量为:");
printf("%d ", sum2);
printf("\n");
}
void TestTRDes(TRNode* root)
{
printf("请输入想要查找的值:");
int x = 0;
scanf("%d", &x);
TRNode* ret = NULL;
ret = TRFind(root, x);
printf("\n");
}
void TestLOrder(TRNode* root)
{
Que qs;
QueueInit(&qs);
LevelOrder(&qs, root);
QueueDestory(&qs);
}
int main()
{
TRNode* node1 = BuyTRNode(1);
TRNode* node2 = BuyTRNode(2);
TRNode* node3 = BuyTRNode(3);
TRNode* node4 = BuyTRNode(4);
TRNode* node5 = BuyTRNode(5);
TRNode* node6 = BuyTRNode(6);
node1->left = node2;
node1->right = node4;
node2->left = node3;
node4->left = node5;
node4->right = node6;
TestOrder(node1);
TestNode(node1);
TestTRDes(node1);
TestLOrder(node1);
return 0;
}