作者姓名:邓泽波
文章简介:Disruptor是一种高性能的异步事件处理框架,它通过无锁的方式实现了高效的并发处理,通过本文为大家介绍将优秀的框架引入流程编排中并落地
文章内容:
金融事业部同学为大家介绍将Disruptor这一框架引入流程编排中的应用探索
1、流程编排引入Disruptor背景
在业务开发中,经常会遇到需要将同步接收的请求转换为异步流程的场景,例如归集还款接收合作方的同步请求后,需要异步处理文件,并逐笔调用核心还款冲销。类似的场景很多,在流程编排中提供了异步链功能,可以通过配置来指定链的异步或同步方式。对于异步链,它会被加入到线程池中进行异步处理,这样在业务开发中无需关注异步线程池的具体实现,只需进行简单的配置即可完成异步流程的编排。这种优化方案能够简化异步流程的开发过程,提高效率和可维护性。
那为何选Disruptor的作为异步线程池实现方案,Disruptor是一种高性能的异步事件处理框架,最初由LMAX Exchange公司开发。它通过无锁(lock-free)的方式实现了高效的并发处理,可以在多核CPU环境下处理百万级别的事件。Disruptor通过将事件数据和处理逻辑分离,实现了高效的数据流转和处理,同时也提供了丰富的可配置参数,方便用户根据具体的应用场景进行定制化配置。
应用Disruptor的知名项目有如下的一些:Storm, Camel, Log4j2,还有目前的美团点评技术团队也有很多不少的应用,或者说有一些借鉴了它的设计机制。
2、Disruptor结构
Disruptor是一个开源的框架,可以在无锁的情况下对队列进行高并发操作,那么这个队列的设计就是Disruptor的核心所在;
环形数组RingBuffer
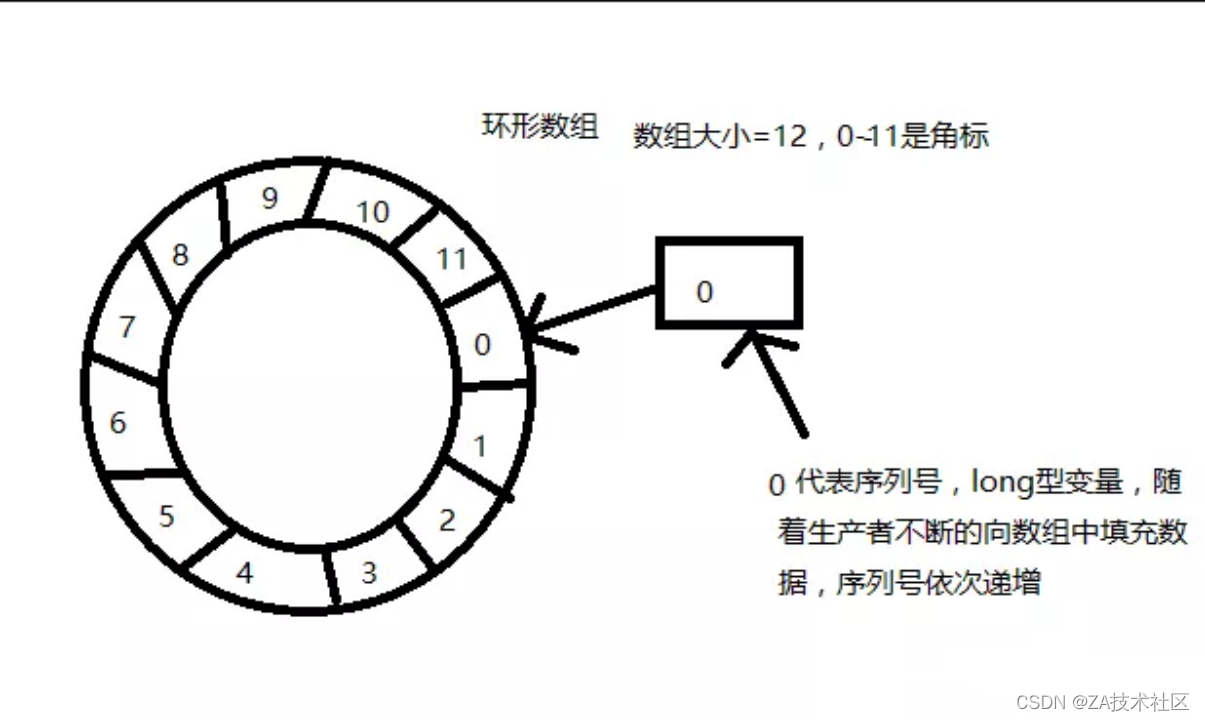
在Disruptor中,采用了RingBuffer来作为队列的数据结构,RingBuffer就是一个环形的数组,既然是数组,我们便可对其设置大小;
在这个ringBuffer中,除了数组之外,还有一个序列号,用来指向数组中的下一个可用元素,供生产者使用或者消费者使用,也就是生产者可以生产的地方,或者消费者可以消费的地方(序列号和数组索引是两个概念);
序列号= 2的63次方-1. (30万年才能用完)
RingBuffer的优点
- 高效的内存管理:RingBuffer是基于内存的实现,可以有效地管理内存,减少内存分配和回收的开销,提高系统性能。
- 无锁设计:RingBuffer采用无锁设计,可以避免线程间的锁竞争,提高系统的并发性能。
- 高效的数据结构:RingBuffer是一个环形缓冲区,可以高效地存储和访问数据,同时支持多生产者和多消费者模式。
- 支持批量读写:RingBuffer可以支持批量读写操作,可以减少系统的上下文切换开销,提高系统的性能。
- 易于扩展:RingBuffer可以很容易地扩展到多个消费者和生产者,支持动态增加和删除消费者和生产者,具有很好的可扩展性。
RingBuffer具有高效、无锁、高效的数据结构、支持批量读写和易于扩展等优点,可以帮助开发者构建高性能、可扩展的系统
3、Disruptor主要实现类
Disruptor
Disruptor的入口,主要封装了环形队列RingBuffer、消费者集合ConsumerRepository的引用,主要提供了获取环形队列、添加消费者、生产者向RingBuffer中添加事件(即生产者生产数据的操作)
RingBuffer
Disruptor中队列具体的实现,底层封装了Object[]数组,在初始化时,会使用Event事件对数组进行填充,填充的大小就是bufferSize设置的值,此外该对象内部还维护了Sequencer(序列生成器)具体的实现
Sequencer
序列生成器,分别有MultiProducerSequencer(多生产者序列生产器) 和 SingleProducerSequencer(单生产者序列生产器)两个实现类。在Sequencer中,维护了消费者的Sequence(序列对象)和生产者自己的Sequence(序列对象);以及维护了生产者与消费者序列冲突时候的等待策略WaitStrategy
Sequence
序列对象,内部维护了一个long型的value,这个序列指向了RingBuffer中Object[]数组具体的角标,生产者和消费者各自维护自己的Sequence,但都是指向RingBuffer的Object[]数组;
WaitStrategy
等待策略,当没有可消费的事件时,消费者根据特定的策略进行等待,当没有可生产的地方时,生产者根据特定的策略进行等待
Event
事件对象,就是我们Ringbuffer中存在的数据,在Disruptor中用Event来定义数据,并不存在Event类,它只是一个定义,是一个概念,表示要传递的数据;
EventProcessor
事件处理器,单独在一个线程内执行,判断消费者的序列和生产者序列关系,决定是否调用自定义的事件处理器,也就是是否可以进行消费
EventHandler
事件处理器,由用户自定义实现,也就是最终的事件消费者,需要实现EventHandler接口
Producer
事件生产者,我们定义的发送事件的对象
4、Disruptor的生产和消费
(1)当Disruptor框架启动:

(2)此时,还没有数据进行写入
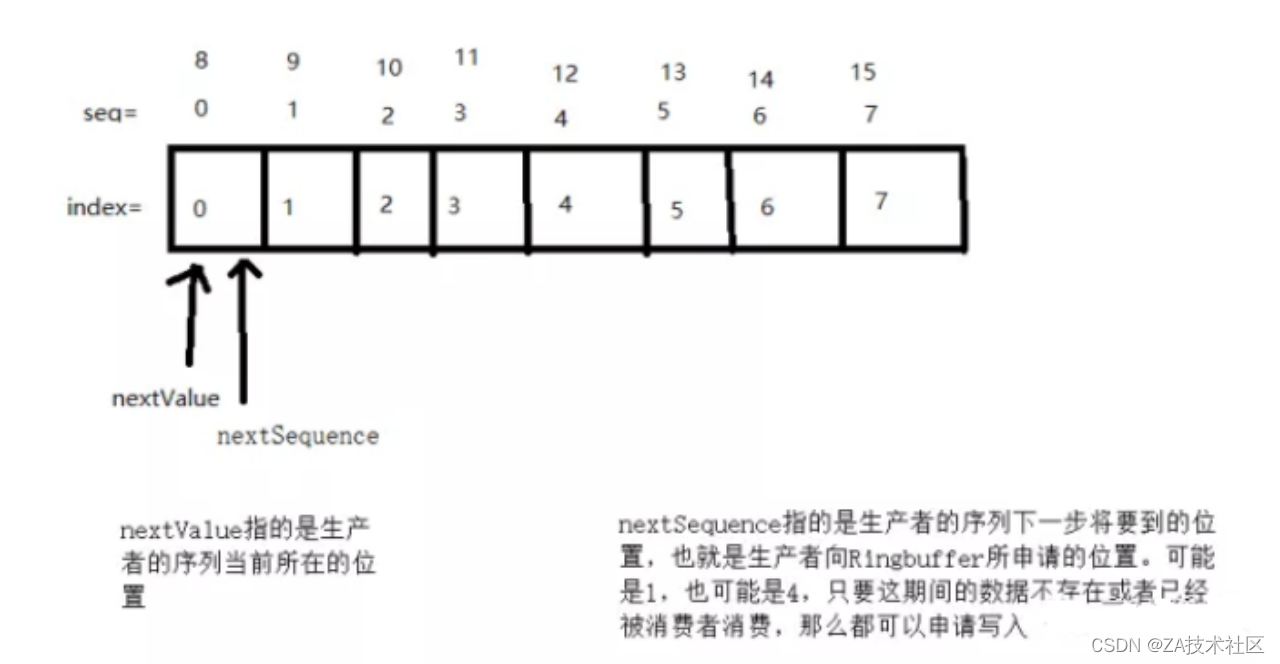
(3)准备写入数据前的准备,获取可以写入数据的最大序列;

(4)写入数据完成,更新生产者序列对象的值;
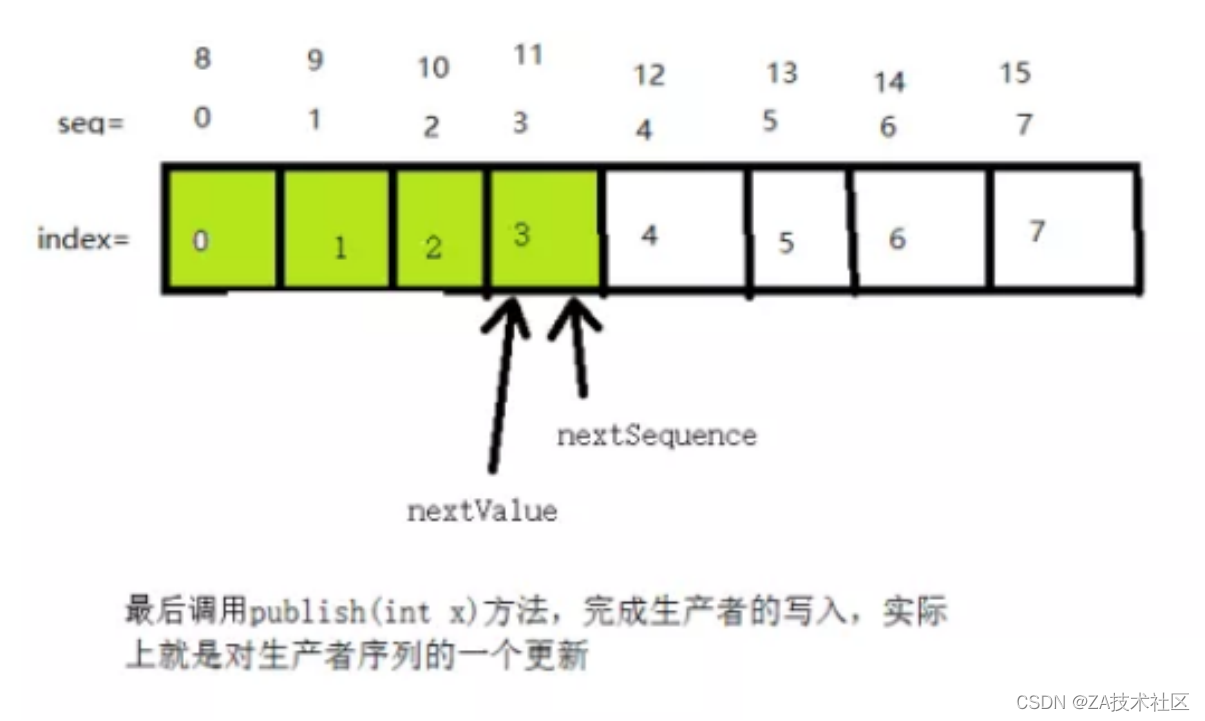
以上就是单生产者写入数据的过程,要注意的是,无论是生产者还是消费者,序列的初始值都是-1
当引入消费者后,生产者在获取可写入的序列之前,都会判断消费者所处的序列。
5、Disruptor常用等待策略
com.lmax.disruptor.WaitStrategy
决定一个消费者如何等待生产者将Event置入Disruptor;
其所有实现都是针对消费者线程的;
主要策略有
com.lmax.disruptor.BlockingWaitStrategy
最低效的策略,但其对CPU的消耗最小,并且在各种部署环境中能提供更加一致的性能表现;
内部维护了一个重入锁ReentrantLock和Condition;
com.lmax.disruptor.SleepingWaitStrategy
性能表现和com.lmax.disruptor.BlockingWaitStrategy差不多,对CPU的消耗也类似,但其对生产者线程的影响最小,适合用于异步日志类似的场景;
是一种无锁的方式,比如log4j2使用了Disruptor框架;
com.lmax.disruptor.YieldingWaitStrategy
性能最好,适合用于低延迟的系统,在要求极高性能且事件处理线程数小于CPU逻辑核心数的场景中,推荐使用此策略,例如CPU开启超线程的特性;
6、Disruptor为什么这么快
Disruptor通过以下设计来解决队列速度慢的问题:
环形数组结构
为了避免垃圾回收,采用数组而非链表,同时,数组对处理器的缓存机制更加友好。
元素位置定位
数组长度2^n,通过位运算,加快定位的速度,下标采取递增的形式,不用担心index溢出的问题,index是long类型,即使100万QPS的处理速度,也需要30万年才能用完。
无锁设计
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。
7、性能测试及内存分析
为了直观地感受 Disruptor 有多快,设计了一个性能对比测试:Producer 发布 1 亿次事件,从发布第一个事件开始计时,捕捉 Consumer 处理完所有事件的耗时。
测试用例在 Producer 如何将事件通知到 Consumer 的实现方式上,设计了两种不同的实现:
1. Producer 的事件发布和 Consumer 的事件处理在不同的线程,通过 ArrayBlockingQueue 传递给Consumer 进行处理;
2. Producer 的事件发布和 Consumer 的事件处理在不同的线程,通过 Disruptor 传递给 Consumer进行处理;
关键测试代码
a. 抽象类
进行一亿次 CAS运算计算耗时
b. ArrayBlockingQueue性能测试代码

c. Disruptor性能测试代码

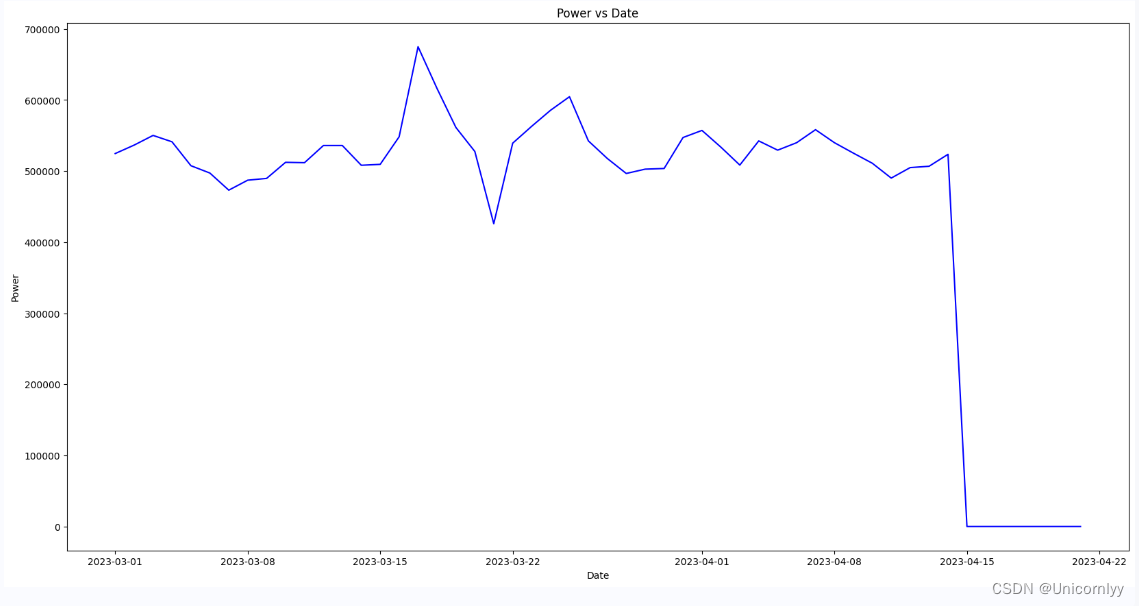
耗时测试对比结果
| 测试类 | 运行次数 | 耗时(ms) |
| DisruptorTest | 100000000 | 3963 |
| ArrayBlockingQueueTest | 100000000 | 14430 |
堆内存对比结果
指定-Xms1024m -Xmx1024m 运行环境
ArrayBlockingQueueTest 测试结果

DisruptorTest 测试结果
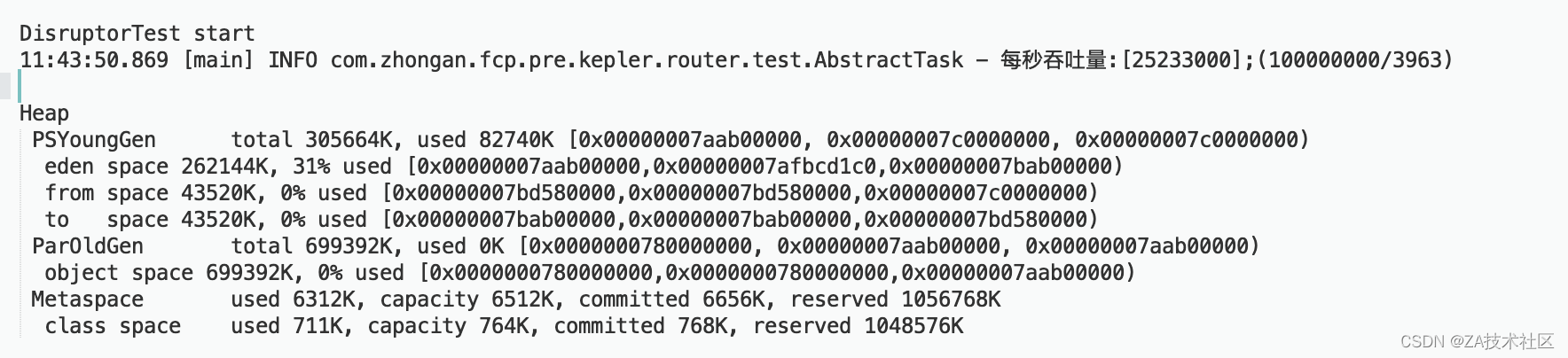
gc对比:ArrayBlockingQueueTest触发了13次gc,而DisruptorTest使用ringBuffer避免了每次需要分配和释放,因此未触发gc;
新生代内存:ArrayBlockingQueueTest占用了177176K,而DisruptorTest占用82740k,节省40%的内存占用
老年的内存:ArrayBlockingQueueTest占用5%,而DisruptorTest占用0%
经过对比可以看出Disruptor对应内存的使用优化更优
8、实际场景应用
流程编排如何支持异步链,将同步链路转为异步链路,传统方式开启异步线程执行,线程数量超过核心线程数时,线程将放入java队列中等待唤起,java队列的缺点上面已经阐述,我们可以通过Disruptor的特性自定义实现线程池
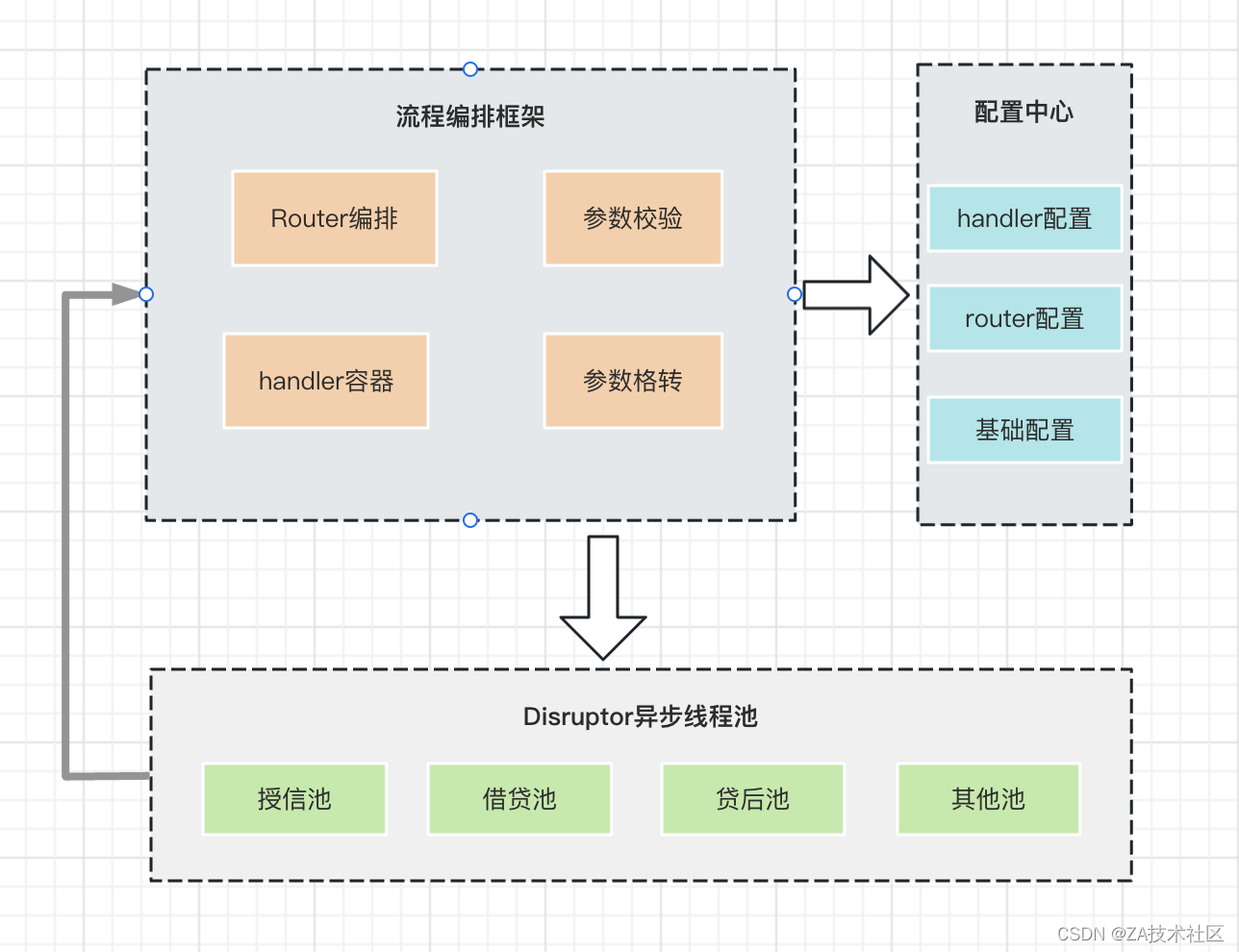
流程编排增加Disruptor异步线程池扩展,丰富组件的功能
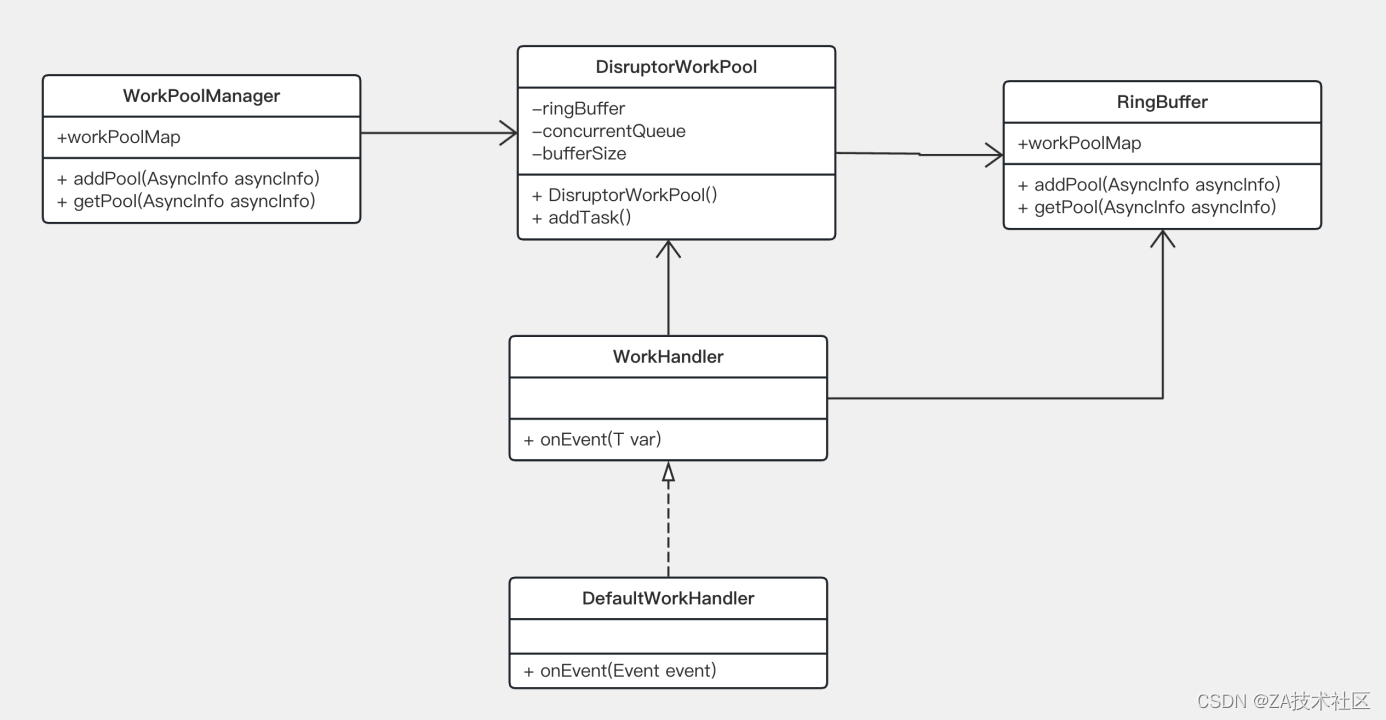
以上为根据Disruptor组件封装的自定义线程池,收发消息的公共模块
- Disruptor中队列具体的实现,底层封装了Object[]数组
- WorkPoolManager 提供Disruptor自定义线程组件初始化,缓存线程池
- DisruptorWorkPool 实现自定义线程池的封装,线程池的一级缓存队列、二级缓存队列,
ringbuffer 虽然号称无界队列,但本质是一个数组(有界),只是消息在数组上可以反复覆盖。
当消息没有被覆盖的情况下,已经消费的消息一直被引用不会GC,所以建议ringbuffer的size不要太大。
但是异步任务很可能是一个耗时的长任务,所以在此引进了二级缓存的概念
- WorkHandler 为消费者接口,DefaultWorkerHandler 封装消费handler执行的父类
针对组件的封装,使用者只需关注业务逻辑handler实现即可
以流程编排执行一个异步流程的handler为例,画如下时序图
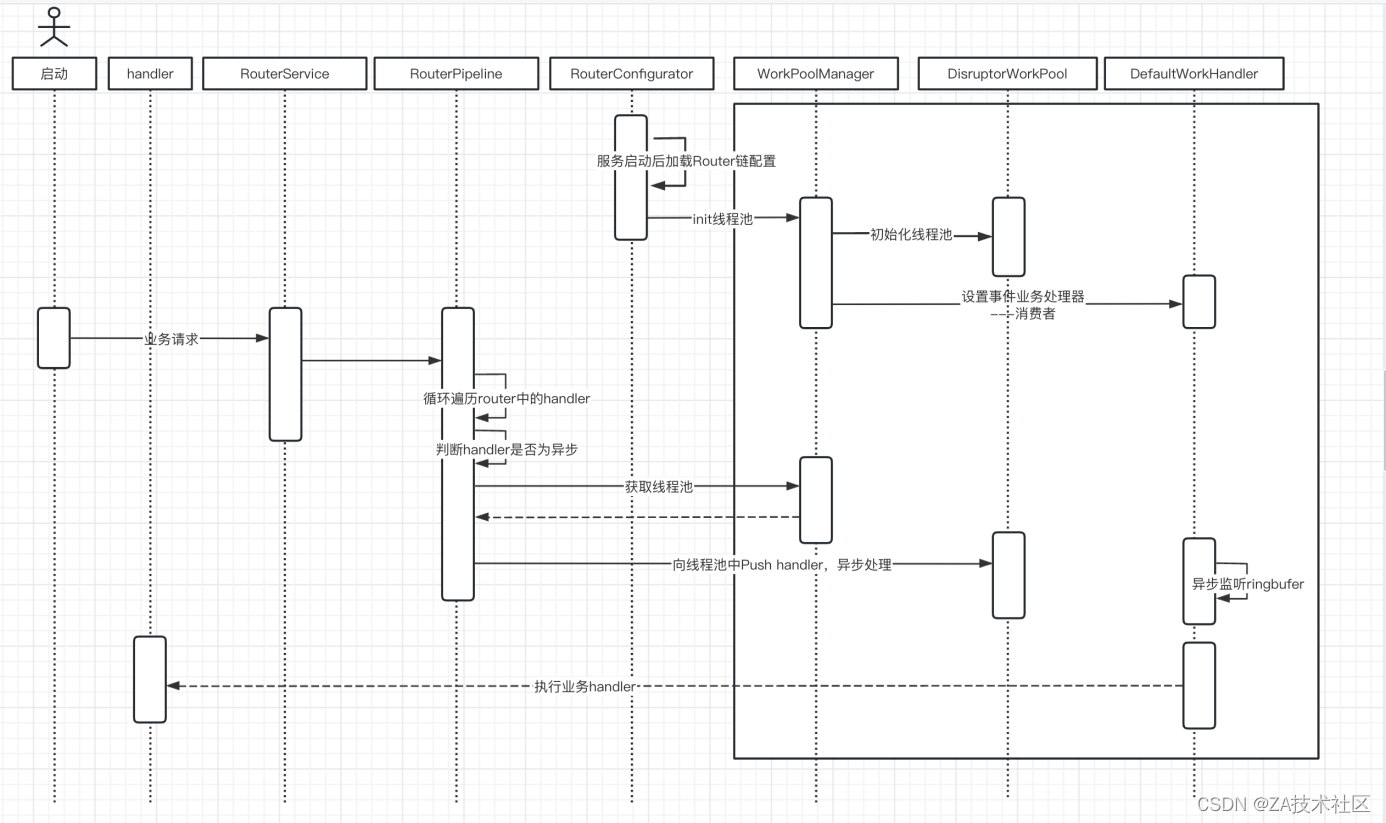
- 服务启动时,RouterConfigrator加载链配置,循环handler调用WorkPoolManager.init()初始化线程池,并设置事件业务处理器对应消费者处理

- 用户发起请求后,业务系统接收到请求,RouterService解析请求参数的routerName,在spring容器中获取该bean
- RouterPipleLine处理类循环遍历Router中的handler,判断async是否为异步标识,如上图配置所示。当async为false同步时,直接执行handler;当async为true异步时,向DisruptorWorkPool自定义线程池中加入该handler。
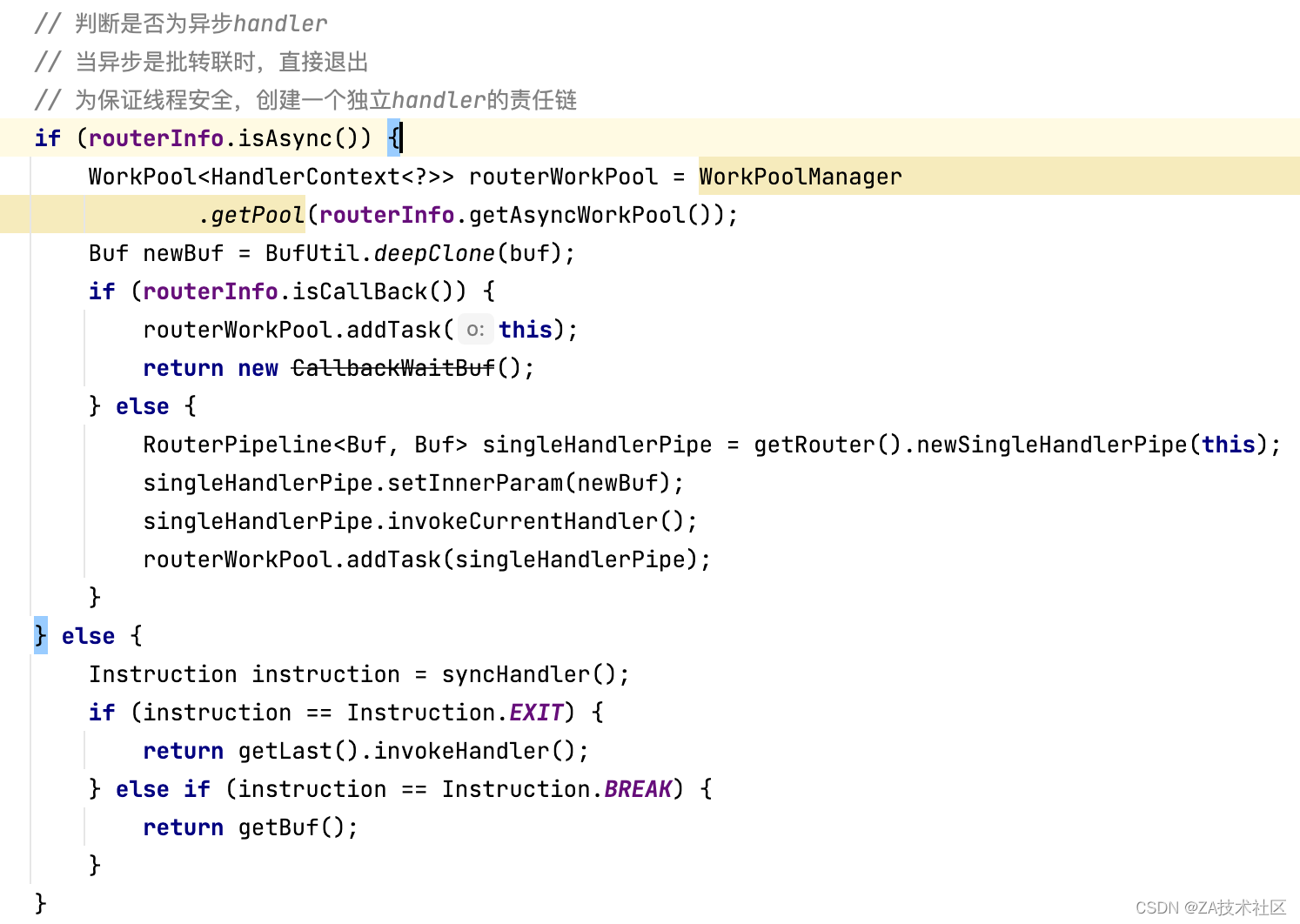
- DefaultWorkerHandler消费监听到消息,解析消息信息,并执行对应handler,完成异步链路。
9、总结
Disruptor 和传统的线程池相比,具有更高的并发性能和更低的延迟。这是因为 Disruptor 使用了无锁算法和基于序列的技术来实现数据共享和通信,避免了线程间的互斥和同步操作,从而提高了并发性能,并且由于没有线程切换的开销,也可以降低延迟。
Disruptor 适用于需要高性能、低延迟、大规模并发、对数据顺序有要求等场景,例如高频交易系统、大规模数据处理系统、实时消息系统等。Disruptor 是一种本地内存消息传递机制,不适用于分布式系统。如果需要在分布式环境中使用 Disruptor,可以考虑使用类似于 Kafka 的分布式消息队列来代替。