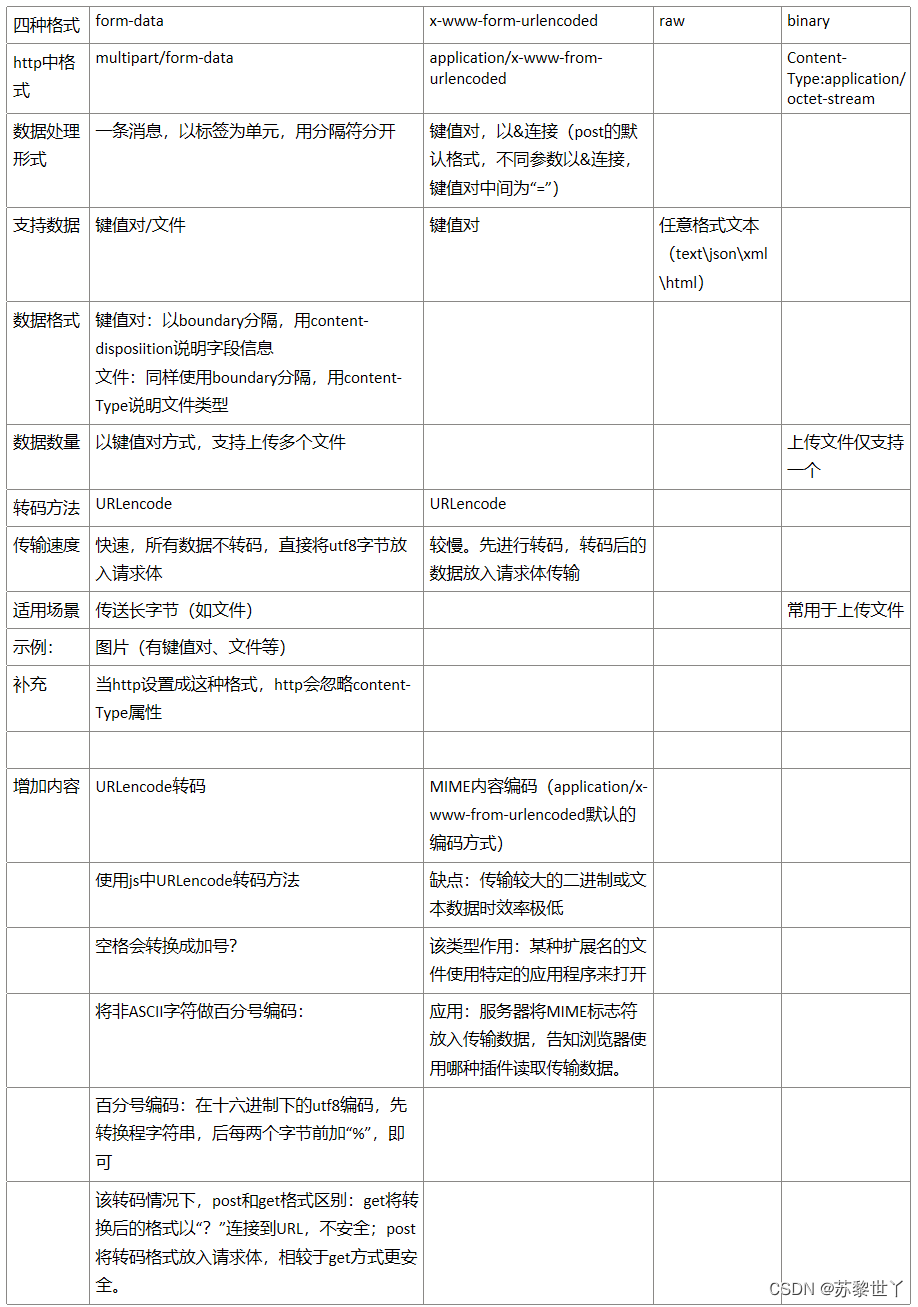
参考:
目标检测的未来是什么? - 知乎 (zhihu.com)![]() https://www.zhihu.com/question/394900756/answer/32489649815大应用场景
https://www.zhihu.com/question/394900756/answer/32489649815大应用场景
1 行人检测:
- 遮挡问题:行人之间的互动和遮挡是非常常见的,这给行人检测带来了挑战。
- 非刚性目标:行人是非刚性目标,其运动非常灵活。在复杂交通环境下,行人的行为具有很大的随机性和任意性。
- 多姿势变化问题:行人可能有多种行走姿态,而且可能会与背景混合,难以分离。
- 检测场景的复杂性:例如光照度的变化、时变性和大量存在的类似行人部分轮廓的物体等因素的干扰。
- 行人检测的准确性和实时性:如何准确地检测和跟踪行人是行人检测技术需要解决的关键问题。
2 人脸检测
- 人脸姿态和饰物问题:由于非配合型监控,人脸会出现侧脸、低头、抬头等各种姿态,以及佩戴帽子、黑框眼镜、口罩等饰物现象。
- 光照问题:由于环境光源的影响,可能出现侧光、顶光、背光和高光等现象。
- 人脸相似性问题:不同个体之间特别是同一民族的区别不大,所有人脸的结构都相似,甚至人脸的结构外形都很相似。
- 人脸易变性:人可以通过脸部的变化产生很多表情,而在不同观察角度,人脸的视觉图像也相差很大。
- 人脸表情复杂:人脸具有多样的变化能力,人的脸上分布着五十多块面部肌肉,这些肌肉的运动导致不同面部表情的出现,会造成人脸特征的显著改变。
- 人脸随年龄而改变:随着年龄的增长,皱纹的出现和面部肌肉的松弛使得人脸的结构和纹理都将发生改变。
- 人脸有易变化的附加物:例如改变发型,蓄留胡须或者佩戴帽子和眼镜等饰物。
- 人脸特征遮掩:人脸全部、部分遮掩将会造成错误识别。
- 人脸图像畸变:由于光照、视角、摄取角度不同,可能会造成图像的灰度畸变、角度旋转等,降低了图像质量,增大了识别难度。
3 文本检测
- 文本具有多样性:自然场景中的文本检测难点主要在于文本的多样性,包括文字颜色、大小、字体、形状、方向、语言、以及文本长度的影响。
- 文本形状复杂多样:文本的形状也是一大难点,因为文本可以以各种不同的形式出现在图像或视频中,包括单个字符的位置或者整个文本行的位置。
- 缺乏通用方法:当前所说的文本检测一般是自然场景文本检测,其难点在于缺乏一个通用的方法来解决所有问题。
- 背景复杂:在图像或视频中,文本可能会出现在各种不同的背景中,这增加了检测的难度。
- 光照条件不定:光照的变化也会对文本检测造成很大的影响。
- 文本大小不一:文本的大小也是一大难点,因为文本的大小会因图像或视频的分辨率不同而变化。
- 字符粘连和断字:在某些情况下,文本中的字符可能会相互粘连,或者字符可能会断开,这会增加检测的难度。
- 字体和字库大小有限:不同的字体和字库大小也会影响文本检测的结果。
- 文本倾斜:文本可能会以不同的角度倾斜出现在图像或视频中,这也会增加检测的难度。
- 遮挡和背景扰动:文本可能会被其他物体遮挡,或者背景中存在扰动因素,这也会影响文本检测的结果。
4 交通信号检测
- 复杂的背景环境:在实际的城市自动驾驶场景中采集的交通信号灯图像具有复杂的背景,如四面八方的信号灯以及其他各类发光源。 遮挡问题:例如前面行驶的大货车或是交通指示牌等,都可能导致交通信号灯被遮挡。
- 多态性的问题:交通信号灯不仅有颜色、形状和位置的变化,一些交通灯还包括箭头来指示方向和标记,比如人或自行车。
- 成像条件的影响:包括天气、低分辨率、模糊等因素的影响,这些因素都可能降低交通信号灯检测的准确性。
- 特征提取和分类问题:对交通信号灯进行识别通常来说分为两个过程,第一步是对图像的候选区域进行特征提取,第二步就是根据特征对识别的特征进行分类。
5 遥感目标检测
- 数据规模问题:由于遥感图像的数据规模相对较小,这可能会对模型的训练产生影响。
- 目标尺寸问题:遥感图像中包含了大量小尺寸的目标,这些小目标在经过神经网络的多层处理后,细节信息可能会丢失过多,导致检测准确率下降。
- 旋转目标的检测问题:这是遥感图像目标检测中的一个重要难题,因为一般的检测算法往往假设目标在图像中是固定方向和姿态的,而旋转目标的出现会大大增加检测的难度。
- 大中小目标分布不均:遥感场景下进行旋转目标检测时,大、中、小目标的分布通常是不均匀的,这种分布的不均衡性也增加了检测的难度。
- 计算资源限制:相比于自然图像数据集,航拍图像一般分辨率较高,受计算资源限制,一些在自然图像中有效的检测小目标的方法如FPN直接应用到航拍图像就无能为力了。
- 遥感图像分辨率巨大:遥感图像分辨率巨大,因此如何快速准确地检测出遥感目标仍然是一个挑战性的问题。
- 目标遮挡问题:超过50%的目标被云雾所遮挡,因此目标遮挡问题也是遥感图像目标检测所面临的一个挑战。
- 域适应问题:由不同传感器所捕获的遥感图像仍然存在很大差异。
7大发展趋势
1 轻量型目标检测
轻量型目标检测的难点主要集中在以下几个方面:
- 小模型性能问题:由于模型容量和能力的限制,小模型往往难以达到较好的性能。虽然大型模型的性能较好,但速度较慢,不符合实时需求。
- 精确度与模型压缩之间的差距:在模型压缩过程中,可能会出现精确度下降的问题。物体检测比分类要困难得多,例如标签的计算更加昂贵,类别不均衡,多任务同时需要分类和回归等。
- 数据不平衡问题:在轻量级目标检测中,正负样本比例失衡是一个常见问题,这会导致模型过于关注多数类,而忽视少数类,从而影响检测的准确性。
- 计算资源限制:轻量型目标检测需要在有限的计算资源上进行,如何在保证准确性的同时提高检测速度是一个重要的挑战。
- 模型加速与优化:如何设计并优化轻量化网络结构以提高模型的速度和准确度是一个重要的研究方向。
2 与AutoML结合的目标检测
3 领域自适应的目标检测
4 弱监督目标检测
5 小目标检测
- 可利用特征较少:小目标相比于大/中目标分辨率低,信息较少,难以提取到具有鉴别力的特征。
- 定位精度要求高:小目标在图像中位置过小且极易受到环境干扰,网络预测时偏移一个像素则对小目标的影响是巨大的。
- 现有数据集中小目标占比少:现有数据集较少关注小目标这一特别类型。同时,小目标不易标注,人力成本巨大,而且对误差更为敏感。
- 样本不均衡:训练时通过设定阈值来判断锚框是否属于正样本,这样会导致不同尺寸目标的样本不均衡问题。因此,当人工设定的锚框与真实边框相差较大时,会导致模型忽略小目标的检测。
- 小目标聚集:小目标更容易出现聚集的现象,这时网络模型的预测边框可能会因非极大值抑制过滤掉大量正确边框,导致漏掉小目标,或是边框距离过近,导致模型难以收敛。
6 视频检测
- 图像模糊:在拍摄视频的过程中,由于物体或相机的移动,会造成视频中的某些帧的画面发生模糊,造成无法分辨目标的情况。
- 目标遮挡:如果目标物体被其他物体遮挡,会使目标检测更加困难。在这种情况下,需要算法能够识别并分割出被遮挡的目标。
- 区分相似目标:在图像中,可能存在与目标物体外形相似的非目标物体,如何区分它们是一个难题。
- 保持视频中目标的时空一致性:由于视频比静态图像多了一个时间维度上的信息,所以大多数视频目标检测算法利用该信息来增强检测性能,最常见的思路就是使用其他帧的特征来增强关键帧的预测效果。
- 夜间诊断效果不佳:由于夜间为黑白画面呈现,加上夜间灯光的影响,视频诊断系统很难对画面问题做出准确判断。
-
上下文信息利用:由于视频相较于单张图片多了一个时间维度上的信息,因此如何有效地利用这些时间上下文信息来提高检测性能,是视频检测面临的一个重要问题。
-
运动变化处理:视频中的目标检测需要在静态图像目标检测的基础上对目标因运动产生的各种变化进行处理。
7 信息融合目标检测