什么是V8
V8是谷歌的开源高性能JavaScript和WebAssembly引擎,用C++编写。它被用于Chrome和Node.js等。它实现ECMAScript和WebAssembly,并在Windows 7或更高版本、macOS 10.12+以及使用x64、IA-32、ARM或MIPS处理器的Linux系统上运行。V8可以独立运行,也可以嵌入到任何C++应用程序中。
V8官网 https://v8.dev/
宏观图

扫描器Scanner
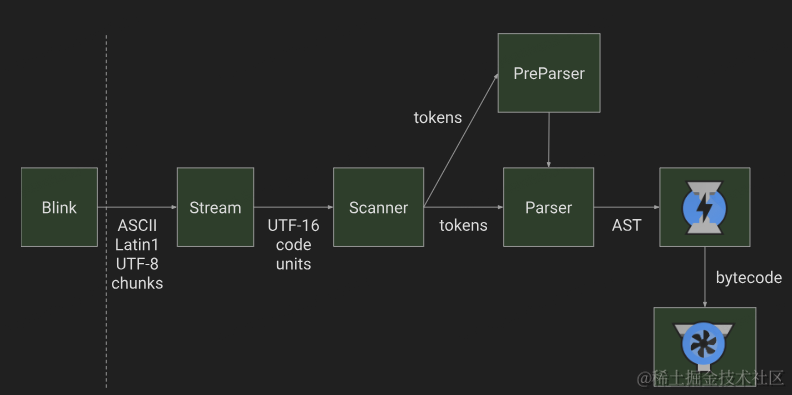
Blink(谷歌浏览器的渲染引擎,基于webkit分支开发)主要负责HTML DOM CSS 渲染,嵌入V8引擎,执行js,计算样式和布局,嵌入合成器,绘制图形。
Blink 拿到html代码分析,找到script代码交给V8引擎解析,注意Blink是通过流的形式传给V8的。
通过以流的形式传输数据,Blink可以逐步接收和处理来自网络的字节流,并在需要时将相应的数据传递给V8引擎执行。这种流式处理方式使得浏览器可以在数据到达的同时并行处理不同的任务,提高了页面的加载速度和用户体验
Scanner(扫描器)首先会进行词法分析
摘抄自V8部分源码 Scanner
V8_INLINE Token::Value Scanner::ScanSingleToken() {
Token::Value token;
do {
next().location.beg_pos = source_pos();
if (V8_LIKELY(static_cast<unsigned>(c0_) <= kMaxAscii)) {
token = one_char_tokens[c0_];
switch (token) {
case Token::LPAREN:
case Token::RPAREN:
case Token::LBRACE:
case Token::RBRACE:
case Token::LBRACK:
case Token::RBRACK:
case Token::COLON:
case Token::SEMICOLON:
case Token::COMMA:
case Token::BIT_NOT:
case Token::ILLEGAL:
// One character tokens.
return Select(token);
case Token::CONDITIONAL:
// ? ?. ?? ??=
Advance();
if (c0_ == '.') {
Advance();
if (!IsDecimalDigit(c0_)) return Token::QUESTION_PERIOD;
PushBack('.');
} else if (c0_ == '?') {
return Select('=', Token::ASSIGN_NULLISH, Token::NULLISH);
}
return Token::CONDITIONAL;
case Token::STRING:
return ScanString();
case Token::LT:
// < <= << <<= <!--
Advance();
if (c0_ == '=') return Select(Token::LTE);
if (c0_ == '<') return Select('=', Token::ASSIGN_SHL, Token::SHL);
if (c0_ == '!') {
token = ScanHtmlComment();
continue;
}
return Token::LT;
case Token::GT:
// > >= >> >>= >>> >>>=
Advance();
if (c0_ == '=') return Select(Token::GTE);
if (c0_ == '>') {
// >> >>= >>> >>>=
Advance();
if (c0_ == '=') return Select(Token::ASSIGN_SAR);
if (c0_ == '>') return Select('=', Token::ASSIGN_SHR, Token::SHR);
return Token::SAR;
}
return Token::GT;
case Token::ASSIGN:
// = == === =>
Advance();
if (c0_ == '=') return Select('=', Token::EQ_STRICT, Token::EQ);
if (c0_ == '>') return Select(Token::ARROW);
return Token::ASSIGN;
case Token::NOT:
// ! != !==
Advance();
if (c0_ == '=') return Select('=', Token::NE_STRICT, Token::NE);
return Token::NOT;
case Token::ADD:
// + ++ +=
Advance();
if (c0_ == '+') return Select(Token::INC);
if (c0_ == '=') return Select(Token::ASSIGN_ADD);
return Token::ADD;
case Token::SUB:
// - -- --> -=
Advance();
if (c0_ == '-') {
Advance();
if (c0_ == '>' && next().after_line_terminator) {
// For compatibility with SpiderMonkey, we skip lines that
// start with an HTML comment end '-->'.
token = SkipSingleHTMLComment();
continue;
}
return Token::DEC;
}
if (c0_ == '=') return Select(Token::ASSIGN_SUB);
return Token::SUB;
case Token::MUL:
// * *=
Advance();
if (c0_ == '*') return Select('=', Token::ASSIGN_EXP, Token::EXP);
if (c0_ == '=') return Select(Token::ASSIGN_MUL);
return Token::MUL;
case Token::MOD:
// % %=
return Select('=', Token::ASSIGN_MOD, Token::MOD);
case Token::DIV:
// / // /* /=
Advance();
if (c0_ == '/') {
uc32 c = Peek();
if (c == '#' || c == '@') {
Advance();
Advance();
token = SkipSourceURLComment();
continue;
}
token = SkipSingleLineComment();
continue;
}
if (c0_ == '*') {
token = SkipMultiLineComment();
continue;
}
if (c0_ == '=') return Select(Token::ASSIGN_DIV);
return Token::DIV;
case Token::BIT_AND:
// & && &= &&=
Advance();
if (c0_ == '&') return Select('=', Token::ASSIGN_AND, Token::AND);
if (c0_ == '=') return Select(Token::ASSIGN_BIT_AND);
return Token::BIT_AND;
case Token::BIT_OR:
// | || |= ||=
Advance();
if (c0_ == '|') return Select('=', Token::ASSIGN_OR, Token::OR);
if (c0_ == '=') return Select(Token::ASSIGN_BIT_OR);
return Token::BIT_OR;
case Token::BIT_XOR:
// ^ ^=
return Select('=', Token::ASSIGN_BIT_XOR, Token::BIT_XOR);
case Token::PERIOD:
// . Number
Advance();
if (IsDecimalDigit(c0_)) return ScanNumber(true);
if (c0_ == '.') {
if (Peek() == '.') {
Advance();
Advance();
return Token::ELLIPSIS;
}
}
return Token::PERIOD;
case Token::TEMPLATE_SPAN:
Advance();
return ScanTemplateSpan();
case Token::PRIVATE_NAME:
if (source_pos() == 0 && Peek() == '!') {
token = SkipSingleLineComment();
continue;
}
return ScanPrivateName();
case Token::WHITESPACE:
token = SkipWhiteSpace();
continue;
case Token::NUMBER:
return ScanNumber(false);
case Token::IDENTIFIER:
return ScanIdentifierOrKeyword();
default:
UNREACHABLE();
}
}
if (IsIdentifierStart(c0_) ||
(CombineSurrogatePair() && IsIdentifierStart(c0_))) {
return ScanIdentifierOrKeyword();
}
if (c0_ == kEndOfInput) {
return source_->has_parser_error() ? Token::ILLEGAL : Token::EOS;
}
token = SkipWhiteSpace();
// Continue scanning for tokens as long as we're just skipping whitespace.
} while (token == Token::WHITESPACE);
return token;
}
- 首先获取当前字符c0_的值,并设置token为初始值。
- 判断c0_是否是ASCII字符,如果是,则根据c0_的值来确定token的类型,并返回相应的Token。
- 对于一些特殊情况,如条件运算符、字符串、小于号、大于号、等号、逻辑非、加号、减号、乘号、取模、除号、按位与、按位或等,根据当前字符和后续字符的组合来确定token的类型,并返回相应的Token。
- 如果c0_不是ASCII字符,或者不满足以上条件,则判断c0_是否是标识符的起始字符,如果是,则调用ScanIdentifierOrKeyword()函数来获取标识符或关键字的Token。
- 如果c0_是HTML注释的结束符’-',则调用SkipSingleHTMLComment()函数来跳过整个HTML注释。
- 如果扫描到文件末尾,则返回Token::EOS。
- 否则,如果遇到空白字符,则调用SkipWhiteSpace()函数来跳过连续的空白字符,并继续扫描下一个Token。
- 最后,返回扫描到的Token。
举个例子 词法分析 解析为如下格式
var xiaoman = 'xmzs'
- Token::VAR:表示关键字"var"。
- Token::WHITESPACE:表示空格字符。
- Token::IDENTIFIER:表示标识符"xiaoman"。
- Token::WHITESPACE:表示空格字符。
- Token::ASSIGN:表示赋值符号"="。
- Token::WHITESPACE:表示空格字符。
- Token::STRING:表示字符串"‘xmzs’"。
词法分析结束后我们的js代码就会变成tokens 接下来进行语法分析
解析器parser
parser 的作用就是将 tokens 转化为 AST 抽象语法树
Program
└── VariableDeclaration
├── Identifier (name: "xiaoman")
└── StringLiteral (value: "'xmzs'")
预解析PreParser
PreParser是预解析器,它的作用是在 JavaScript 代码执行之前对代码进行可选的预处理。预解析器的存在是为了提高代码的执行效率。
V8 引擎采用了延迟解析(Lazy Parsing)的策略,它的原理是只解析当前需要的内容,而把其他内容推迟到函数被调用时再进行解析。这样可以减少不必要的解析工作,提高网页的运行效率。
例如,在一个函数 outer 内部定义了另一个函数 inner,那么 inner 函数就会进行预解析。这意味着在函数 outer 被调用之前,只会对 outer 函数的内容进行解析,而对于 inner 函数的解析会在 outer 函数调用到 inner 函数时才进行。
通过延迟解析的方式,V8 引擎可以避免解析和编译未被执行的函数,节省了不必要的时间和资源开销,提高了 JavaScript 代码的执行效率。这种优化策略在大型复杂的 JavaScript 应用程序中尤为重要,可以帮助提升整体性能和用户体验。
解释器Ignition
解释器的作用主要就是将AST 抽象语法树 转化成 字节码(bytecode)
问?为什么要转成字节码而不是直接转成机器码
跨平台执行:不同的硬件架构和操作系统有不同的机器码格式。通过将代码转换为字节码,可以使得同一份字节码在不同的平台上都能执行,实现跨平台的能力。- 快速启动和解析:将代码转换为字节码可以比直接生成机器码更快速地进行启动和解析。字节码通常具有更简单的格式和结构,可以更快地被引擎加载和解释执行。
- 动态优化:现代的JavaScript引擎通常具有即时编译(JIT)功能,可以将热点代码编译成高效的机器码。通过首先将代码转换为字节码,引擎可以更好地进行动态优化和编译,根据实际执行情况生成最优的机器码。这种方式可以在运行时根据代码的实际执行情况进行优化,而不需要提前生成固定的机器码。
- 代码安全性:字节码作为中间表示形式,可以提供一定的代码安全性。字节码相对于源代码或机器码来说更难以理解和修改,可以提供一定程度的代码保护。
示例 以下代码会被转成 字节码
Program
└── VariableDeclaration
├── Identifier (name: "xiaoman")
└── StringLiteral (value: "'xmzs'")
转化之后
0001: PushString "'xmzs'"
0002: StoreVar "xiaoman"
PushString "'xmzs'":将字符串字面量 "'xmzs'"推入堆栈(栈帧)。在这个例子中,它将字符串 "'xmzs'"推入堆栈。StoreVar "xiaoman":将栈顶的值存储到变量 “xiaoman” 中。在这个例子中,它将栈顶的字符串值存储到变量 “xiaoman”
编译器TurboFan
编译器就是将字节码也可以叫中间代码 最后 转换成 机器码 能让我们的CPU识别
但是我们的CPU有不同的架构 ARM X86
示例 我们的 字节码 转换成机器码例如 X86
0001: PushString "'xmzs'"
0002: StoreVar "xiaoman"
X86机器码
MOV EAX, 'xmzs' ; 将字符串 'xmzs' 存储到寄存器
EAX MOV [xiaoman], EAX ; 将寄存器 EAX 的值存储到变量 xiaoman 对应的内存地址中
ARM机器码
LDR R0, ='xmzs' ; 将字符串 'xmzs' 的地址加载到寄存器
R0 STR R0, [xiaoman] ; 将寄存器 R0 中的值存储到变量 xiaoman 对应的内存地址中