在上期文章,我们对比了在 Amazon SageMaker 上部署大模型的两种不同的部署方式。本期文章,我们将探讨两个目前大语言模型领域的开发者们都关注的两个热门话题:大型语言模型(LLM)的高效微调和量化。
微调大型语言模型允许开发者调整开源基础模型,从而提高特定领域任务的性能。接下来的两期文章,我们将探讨如何利用 Hugging Face 的参数高效微调 (PEFT) 库和 QLoRA 量化技术,使用单个实例对大型模型进行参数高效微调和量化部署。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
由于该研究范畴尚属前沿领域,因此我计划用两篇文章的篇幅来阐述原理及背后的主要论文,然后指导大家在亚马逊云科技上的具体实践。包括:
-
原理探索:大模型参数高效微调和量化原理概述
-
动手实验:使用 PEFT 和 QLoRA 量化技术,在单个 ml.g5.12xlarge 实例上微调 Falcon-40B 开源大模型
首先我们进入第一部分,梳理参数高效微调 (PEFT) 和 QLoRA 量化技术背后的理论基础。
大模型参数高效微调(PEFT)
当前,预训练语言模型的规模越来越大,在消费级硬件上进行全量微调(Full Fine-Tuning)变得越来越不现实;同时,为每项下游任务单独存储和部署微调模型的成本,也非常昂贵,因为微调模型的大小需要与预训练模型的大小相同。
参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)技术被提出以解决这两个问题。
在保证几乎和完全微调相当性能的前提下,PEFT 技术可以帮助预训练模型高效适应各种下游应用任务,而无需微调预训练模型的所有参数。PEFT 技术固定了大部分预训练参数,仅对少量的模型参数进行微调,这在很大程度上地降低了微调工作所需要的计算和存储成本。
下图显示了 Hugging Face 开源的一个高效微调大模型的库 PEFT。

Source: https://github.com/huggingface/peft?trk=cndc-detail
由以上可知,该算法库目前已经支持以下六类大模型高效微调的技术方法:
1. LoRA: LORA:LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
2. Prefix Tuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation, P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
3. P-Tuning: GPT Understands, Too
4. Prompt Tuning: The Power of Scale forParameter-Efficient Prompt Tuning
5. AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
6. (IA)^3 : Infused Adapter by Inhibiting and Amplifying Inner Activations
篇幅所限,这两期文章,我们将聚焦 LoRA 这个方向的大模型参数高效微调技术方法,以及亚马逊云科技上的落地实践。
大语言模型的低秩自适应(LoRA)
在 2021 年的 LoRA 论文中,研究者们首次提出了低秩(LOW-RANK)自适应(LoRA)的大语言模型的低秩自适应方法。LoRA 方法通过冻结预训练模型权重,将可训练的秩分解矩阵注入 Transformer 架构的每一层,从而大大减少了下游任务需要训练的参数数量。LoRA 论文如下图所示。

Source: https://arxiv.org/pdf/2106.09685.pdf?trk=cndc-detail
在该论文的摘要里,研究者们已经对提出 RoLA 方法的起心动念做了精辟的阐述。他们分析:在预训练大模型时,随着模型越来越大,重新训练所有模型参数不太现实了。以 GPT-3 175B 大模型为例,部署经过微调的模型独立实例,每个实例已经有 175B 个参数,这样的训练成本会高得让一般的企业和个人望而却步。
论文提出了低秩(LOW-RANK)自适应(LoRA),它冻结了预训练的模型权重,并将可训练的秩分解矩阵注入 Transformer 架构的每一层,从而大大减少了下游任务的可训练参数数量。与用 Adam 微调的 GPT-3 175B 相比,LoRA 可以将可训练参数的数量减少 1 万倍,因此,GPU 和内存需求会减少 3 倍。
这篇 2021 年论文的价值,到了今天这个开源大模型时代,变得更加重要。LoRA 论文中那张著名的图一,已经被一些研究者做成了动图,这样在诠释原理时,变得更加生动了。
如下图所示:

Source: https://huggingface.co/blog/4bit-transformers-bitsandbytes?tr...
上图旨在说明在重新参数化的过程中,只需要训练 A 和 B 即可。低秩自适应(LoRA)方法,允许通过优化适应过程中密集层变化的秩分解矩阵,来间接训练神经网络中的一些密集层,同时保持预训练的权重不变。以 GPT-3 175B 为例,即使当全秩(即 d)高达 12,288 时,非常低的秩(即图中 r 的数量)也足够了,从而使 LoRA 在存储和计算两方面都颇具效率。
低精度量化的高效微调(QLoRA)
了解 RoLA 的论文之后,让我们来看看 QLoRA 论文的创新角度和视野。
LoRA 为大模型的每一层添加了少量的可训练参数(适配器),并冻结了所有原始参数。这样对于微调,只需要更新适配器权重,这可以显著减少内存占用。但是,当大模型越来越大,这些大模型的全精度表示已经无法装入单个甚至多个 GPU 的内存中了。为了支持这种规模的模型在单个实例上进行微调和推理,QLoRA 出现了。
1.QLoRA 论文概述
QLoRA 是 Quantized LLMs with Low-Rank Adapters 的缩写,它来自华盛顿大学 2023 年 5 月发表的一篇论文,如下所示:

Source: https://arxiv.org/pdf/2305.14314.pdf?trk=cndc-detail
概括起来,QLoRA 有三项重要贡献:引入 4 位量化、双量化、以及利用 NVIDIA 统一内存进行分页。以下分别阐述:
-
4 位 NormalFloat 量化(4-bit NormalFloat,NF4):这种改进的量化方法,确保了每个量化仓中有相同数量的值,以避免计算问题和异常值错误
-
双量化(Double Quantization):QLoRA 的作者将其定义如下“对量化常量再次量化以节省额外内存的过程”
-
统一内存分页(Paged Optimizers):依赖 NVIDIA 统一内存管理,自动处理 CPU 和 GPU 之间的页到页传输

Source: https://arxiv.org/pdf/2305.14314.pdf?trk=cndc-detail
关于 QLoRA 的优异表现,论文阐述了他们利用 QLoRA 方法训练的系列模型 Guanaco,在 Vicuna 基准测试中的表现超过了所有以前公开发布的模型,在 24 小时内微调的 Guanaco 65B 大模型甚至能够 达到 GPT4 性能水平的 99.3%。以下是论文中所公布的基准测试数据结果:

Source: https://arxiv.org/pdf/2305.14314.pdf?trk=cndc-detail
QLoRA 的 Q 就是量化(Quantization)。为帮助大家理解量化(Quantization)这个抽象的概念,下一节我们将先梳理下机器学习场景下的常用数据类型,这样大家就会对不同数据类型占用的资源比例有一定的了解;然后我们再通过论文,一起来揭开量化技术方法背后的神秘面纱。
2. 机器学习的常用数据类型
我们从对不同浮点数据类型的基本理解开始,这些数据类型在机器学习的背景下也被称为 “精度(precision)”。模型的大小由其参数的数量及其精度决定,通常为 Float32 (FP32)、Float16 (FP16) 或 BFloat16 (BF16)。如下图所示:

Source: https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-preci...
Float32(FP32)数据类型:代表标准化的 IEEE 32 位浮点表示法。使用这种数据类型,可以表示各种浮点数。在 FP32 中,8 位用于表示指数,23 位用于表示小数,1 位用于数字符号。大多数硬件都支持 FP32 操作和指令。
Float16(FP16)数据类型:为指数保留 5 位,为小数保留 10 位。这使得 FP16 数字的可表示范围远低于 FP32。这使 FP16 面临 overflowing 溢出(试图表示非常大的数字)和 underflowing 溢出(表示非常小的数字)的风险。
例如如果你计算 10k * 10k,由于结果是 100M,这在 FP16 中是不能表示的,因为它可能的最大数字只是 64k。因此,你最终会得到 NaN(Not a Number)结果,如果你像神经网络一样进行顺序计算,那么先前的所有工作都会被破坏。虽然可以使用损失缩放(loss scaling)来部分回避这个问题,但有时也不起作用。
BFloat16(BF16)数据类型:为了避免这些限制,一种名为 bfloat16(BF16)的新数据类型出现。在 BF16 中,为指数保留 8 位(与 FP32 相同),为小数保留 7 位。这意味着在 BF16 中,我们可以保留与 FP32 相同的动态范围。但是相对于 FP16,我们损失了 3 位精度。现在大数字绝对没有问题,但是这里的精度比 FP16 差。
在安培(Ampere)架构中,NVIDIA 还引入了 TensorFloat-32(TF32)数据类型,将 BF16 的动态范围和 FP16 的精度相结合,仅使用 19 位。它目前仅在其内部某些操作时使用。
在机器学习术语中,FP32 被称为全精度(4 字节),而 BF16 和 FP16 被称为半精度(2 字节)。而 int8(INT8) 数据类型由一个 8 位表示组成,可以存储 2^8 个不同的值(对于有符号整数,介于 [0, 255] 或 [-128, 127] 之间)。
虽然理想情况下,训练和推理应在 FP32 中完成,但速度比 FP16/BF16 慢两倍,因此,实际场景又是会使用混合精度(mixed precision) 方法:将权重保存在 FP32 中作为精确的 “主权重” 参考,而对 FP16/BF16 进行向前和向后传递的计算以提高训练速度。然后,使用 FP16/BF16 梯度来更新 FP32 的主权重。
在训练过程中,主权重始终存储在 FP32 中,但实际上,半精度权重(half-precision)在推理过程中通常提供与 FP32 同类权重相似的结果质量(quality)——只有在模型收到多个梯度更新时才需要模型的精确参考。这意味着我们可以使用半精度权重并使用一半的 GPU 来实现相同的结果。
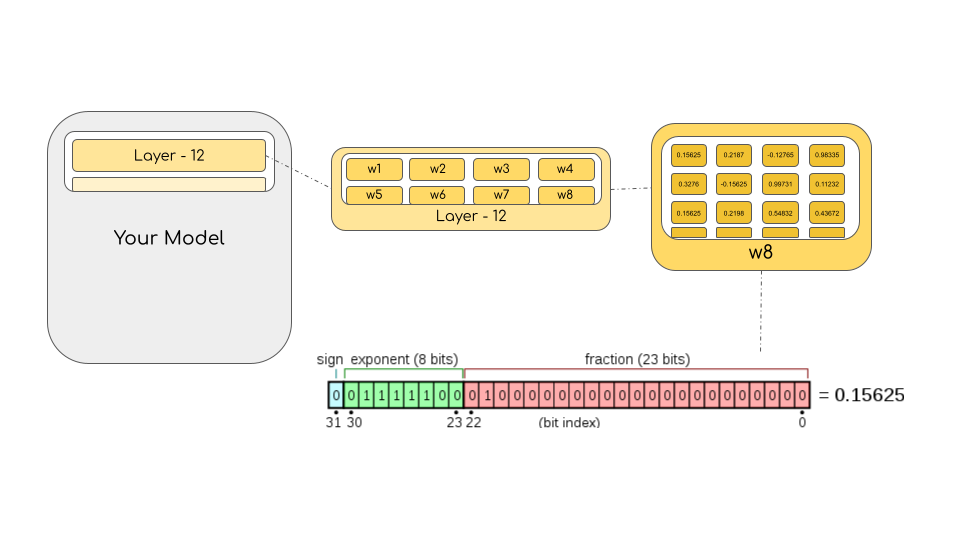
Source: https://huggingface.co/blog/hf-bitsandbytes-integration?trk=c...
举个例子来详细阐述。如上图所示,如果我们要计算模型大小(以字节为单位),需要将参数数乘以所选精度的大小(以字节为单位)。比如我们使用 bfloat16 版本的 BLOOM-176B 大模型,我们就需要(17610*9)x 2 字节 = 352GB!如果只有几个 GPU 来做这件事,这将是一项巨大的挑战。
但是,如果我们可以使用不同的数据类型用更少的内存存储这些权重呢?在这种场景需求的背景下,一种叫做量化(Quantization)的技术方法终于闪亮登场了。
3. 量化(Quantization)技术概述
量化本质上是通过从一种数据类型“四舍五入”到另一种数据类型来完成的。量化是一个嘈杂的过程,可能会有信息丢失;这个过程是一种有损压缩的过程。
FP8 和 FP4 分别代表浮点精度 8 位和 4 位精度。让我们先来看看如何用 FP8 数据类型格式表示浮点值,然后了解 FP4 数据类型格式的情况。
FP8 数据格式
浮点数包含 n 位,每个位都属于一个特定的类别,负责表示数字的组成部分(符号、尾数和指数)。FP8(浮点 8)数据格式最初是在论文“FP8 for Deep Learning”中引入的,它有两种不同的 FP8 编码:E4M3(4 位指数和 3 位小数)和 E5M2(5 位指数和 2 位小数)。
不同数据类型的每位表达情况,如下图所示。比如,FP8 E4M3 格式表示的潜在浮点数,是在 -448 到 448 之间;而 FP8 E5M2 格式中,随着指数位数的增加,范围会增加到 -57344 到 57344,而由于可能的表示数量保持不变,这会降低精度。
一些研究者的经验显示:E4M3 最适合向前传递,E5M2 最适合向后计算。

Source: https://huggingface.co/blog/4bit-transformers-bitsandbytes?tr...
在找资料的过程中,我还找到了另一张解释机器学习不同数据格式的图,和上图相比更有一种简洁之美。因此,我也一并发出来供大家参考学习:

Source: https://www.nextplatform.com/2022/03/31/deep-dive-into-nvidias-hopper-gpu-architecture/?trk=cndc-detail
FP4 数据格式
不同于 FP8 精度的数据格式,FP4 精度仅使用 4 位来表示一个数字。这 4 位被分为 1 个符号位、3 个指数位和 0 个尾数位。例如:在下表中,各列的符号位和尾数位的值不同,而指数位的行是不同的值。

Source: https://en.wikipedia.org/wiki/Minifloat?trk=cndc-detail
FP4 精度没有固定格式。这意味着可以使用不同的尾数和指数位组合。一般来说,在大多数情况下使用 3 个指数位,因为它们提供更好的精度。但是,有时 2 个指数位和 1 个尾数位可以获得更好的性能。
关于 FP4 数据格式的详细表述,由于篇幅所限,就不在这里展开讨论了。Hugging Face 和上述论文的作者发表过一篇详细的博客文章:“Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA”,文章中涵盖了 4-bit 量化技术方法的一些底层解读,感兴趣的开发者们可参考: https://huggingface.co/blog/4bit-transformers-bitsandbytes?tr...
总结
与标准的 16 位模型微调相比,QLoRA 减少了大模型微调的内存使用量,而无需权衡性能。此方法允许在单个 24GB GPU 上微调 33B 模型,在单个 46GB GPU 上对 65B 模型进行微调。QLoRA 使用 4-bit 量化来压缩预训练的语言模型,然后冻结住大模型的参数,并以低等级适配器的形式将相对较少的可训练参数添加到模型中。在微调期间,QLoRA 将梯度通过冻结的 4 位量化预训练模型反向传播到低等级适配器,而 LoRA 层是训练时唯一需要更新的参数。
QLoRA 的量化过程可以基本概述如下:
-
QLoRA 有一个用于基本模型权重的存储数据类型(NF4)和一个用于执行计算的计算数据类型(BF16);
-
QLoRA 将权重从存储数据类型反量化为计算数据类型以执行向前和向后传递, 但在传递过程中仅计算使用 BF16 的 LoRA 参数的权重梯度。权重仅在需要时解压缩,因此在训练和推理期间内存使用量保持较低。
探索完基本理论之后,我们就要开始动手实践了。在下一篇文章中,我们将探讨使用 Amazon SageMaker Notebook 在交互式环境中快速高效地微调大语言模型。我们将运用 QLoRA 和 4-bits 的 bitsandbtyes 量化技术原理,在 Amazon SageMaker 上使用 Hugging Face PEFT 来微调 Falcon-40B 模型,敬请期待。
请持续关注 Build On Cloud 专栏,了解更多面向开发者的技术分享和云开发动态!

文章来源:
https://dev.amazoncloud.cn/column/article/64e74d0d1defb92aa89afc06?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN