简介
ChatGLM2-6B 是清华大学开源的一款支持中英双语的对话语言模型。经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,具有62 亿参数的 ChatGLM2-6B 已经能生成相当符合人类偏好的回答。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
准备工作
安装wget
- 删除自带的wget:
yum remove wget - 重新安装wget:
yum -y install wget - 检测wget版本:
rpm -qa | grep "wget"
若出现以下,则成功。
[root@localhost ~]# rpm -qa | grep "wget"
wget-1.14-18.el7_6.1.x86_64
安装ANACONDA
- 官网下载页面:
https://www.anaconda.com/download#downloads - Linux64位下载:
wget https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Linux-x86_64.sh - 安装:
sh Anaconda3-2023.09-0-Linux-x86_64.sh - 会出现很多信息,一路
yes下去,观看文档用q跳过 - 查看版本验证是否安装成功:
conda -V
(base) [root@localhost ~]# conda -V
conda 23.7.4
安装pytorch
- 前往
pytorch官网:https://pytorch.org/ - 选择
Stable,Linux,Conda,Python,CPU - 执行给出的指令:
conda install pytorch torchvision torchaudio cpuonly -c pytorch
创建虚拟Python环境
- conda创建虚拟环境:
conda create --name ChatGLM2 python=3.10.6 -y
- –name 后面ChatGLM2为创建的虚拟环境名称
- python=之后输入自己想要的python版本
- -y表示后面的请求全部为yes,这样就不用自己每次手动输入yes了。
- 激活虚拟环境:
conda activate ChatGLM2
大语言模型ChatGLM2-6B安装
- 源码/文档:
https://github.com/THUDM/ChatGLM2-6B - 下载源码:
git clone https://github.com/THUDM/ChatGLM2-6B - 创建ChatGLM2项目的虚拟环境:
python -m venv venv - 激活虚拟环境venv:
source ./venv/bin/activate - 安装依赖(豆瓣源):
pip install -r requirements.txt -i https://pypi.douban.com/simple
- 参数:-r 是read的意思,可以把要安装的文件统一写在一个txt中,批量下载
- 参数:-i 后面是下载的网址,这里使用的是豆瓣源,下载安装大概十几分钟
- 清华大学源:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn- 阿里云源:
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
- 也可以离线安装
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install -r requirements.txt --no-index --find-links=/home/ChatGLM2/chatglm2-dependence
- 安装依赖:
pip install gradio -i https://pypi.douban.com/simple
从Hugging Face Hub下载模型实现和参数文件
- 在上面的
ChatGLM2-6B目录下新建THUDM文件夹 - 在
THUDM文件夹下新建chatglm2-6b文件夹和chatglm2-6b-int4文件夹 - 下载模型实现和参数文件:
git clone https://huggingface.co/THUDM/chatglm2-6b - 也可以仅下载模型实现:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b - 然后从清华大学下载模型参数文件:
https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2F&mode=list - 把下载后的所有文件放到上面新建的
chatglm2-6b文件夹 - 如果需要使用量化模型和参数,
chatglm2-6b-int4的模型和参数文件地址:https://huggingface.co/THUDM/chatglm2-6b-int4,下载方式与chatglm2-6b一样
- 国内无法访问huggingface.co,可以让国外的朋友帮忙下载
- 可以从这里下载模型实现
- 然后从清华大学下载参数文件
修改启动脚本
如果使用有chatglm2-6b-int4,需要修改
cli_demo.py、api.py、web_demo.py、web_demo2.py
# 修改前
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
# 修改后
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b-int4", trust_remote_code=True)
# GPU用cuda(),CPU用float()
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4", trust_remote_code=True).float()
修改 web_demo.py文件
- 除了需要按上面修改,还需要在最后一行,将
demo.queue().lanuch函数改为如下
demo.queue().launch(share=True, inbrowser=True, server_name = '0.0.0.0')
- 在
predict函数中,第二句话改为
for response, history in model.stream_chat ( tokenizer ,input ,history,past_key_values=past_key_values, return_past_key_values=False, max_length=max_length, top_p=top_p,
temperature=temperature)
启动
- 启动基于
Gradio的网页版demo:python web_demo.py - 启动基于
Streamlit的网页版demo:streamlit run web_demo2.py - 网页版
demo会运行一个Web Server,并输出地址。在浏览器中打开输出的地址即可使用。 经测试,基于Streamlit的网页版Demo会更流畅。 - 命令行
Demo:python cli_demo.py
API部署
- 安装额外的依赖:
pip install fastapi uvicorn -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com - 运行:
python api.py - 通过
POST方法进行调用:
curl -X POST "http://192.168.3.109:8000" -H "Content-Type: application/json" -d "{\"prompt\": \"你好\", \"history\": []}"
- 得到的返回值为
{"response":"你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。","history":[["你好","你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。"]],"status":200,"time":"2023-10-18 14:26:48"}
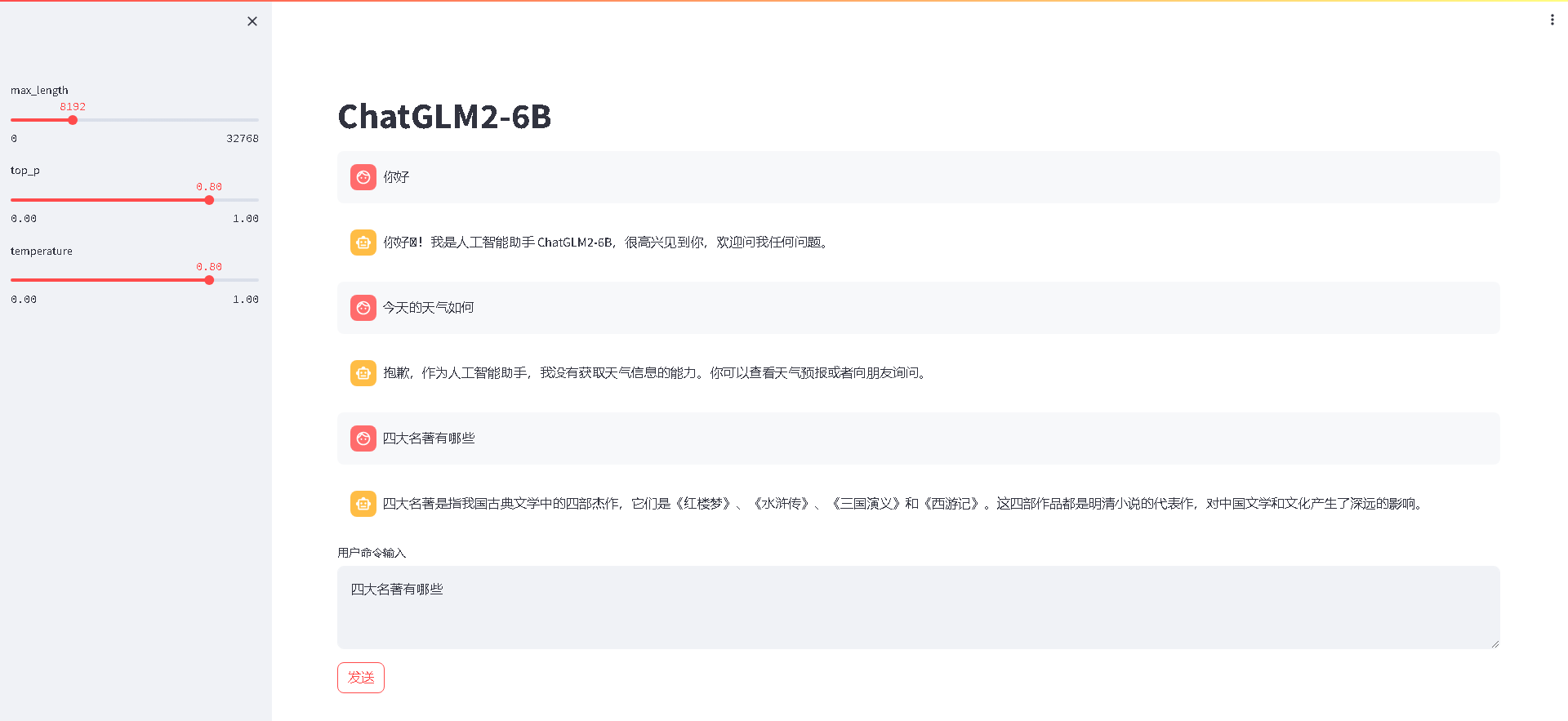
可视化交互界面
协议
- 本仓库的代码依照
Apache-2.0协议开源,ChatGLM2-6B模型的权重的使用则需要遵循Model License。ChatGLM2-6B权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
总结
- 如果机器的内存资源不多,命令行交互模式、可视化模式、API模式,通常只能运行一种
- 再启动另外一个脚本时,会导致前一个启动的进行被
killed ChatGLM2在多个中文数据集上测试结果优于GPT,比上代版本ChatGLM1有较大改善,受限于训练数据和资源,从实际效果看推理对话内容仍比较简单,本次部署在云端的CPU,推理过程需要几分钟,甚至十几分钟,不过重在体验,看下效果。有兴趣的话使用GPU能够较大程度提高反应速度,几秒就能给出答案。


![[备忘]WindowsLinux上查看端口被什么进程占用|端口占用](https://img-blog.csdnimg.cn/fbd2e4466dbc4f00aaac1501b3c21d69.png)