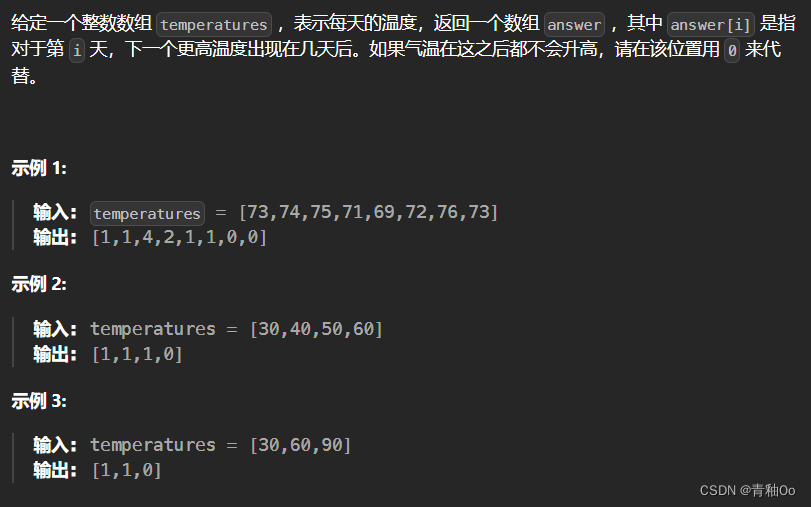
本文主要是语音合成模型实验结果经验总结!!
首先列出实验过的所有模型
- Fastspeech&Fastspeech2
- Tacotron&Tacotron2
- Transformer-TTS
- Bark(E2E)
- VITS/VITS2(E2E)
- NaturalSpeech2
- MB-iSTFT-VITS/ MB-iSTFT-VITS2(E2E)
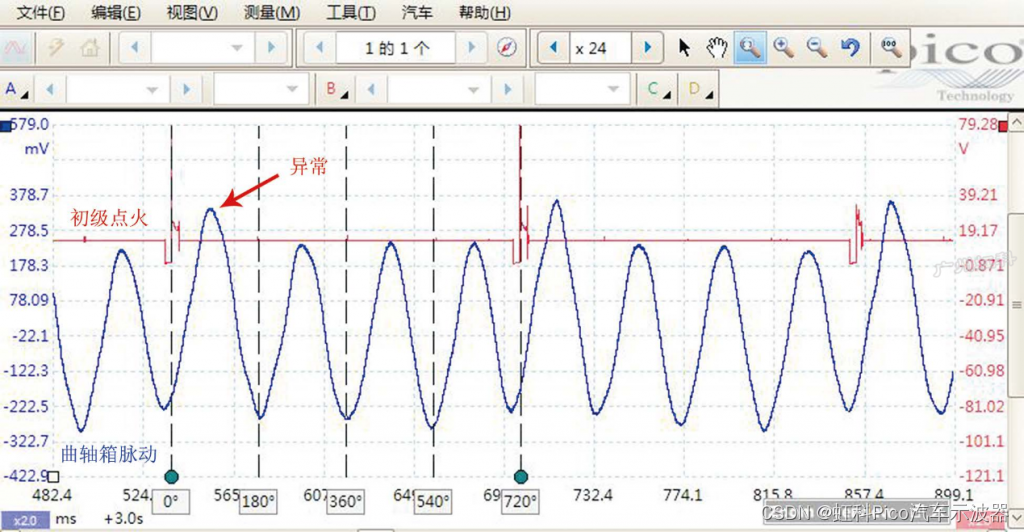
1.语音合成主主要架构如下
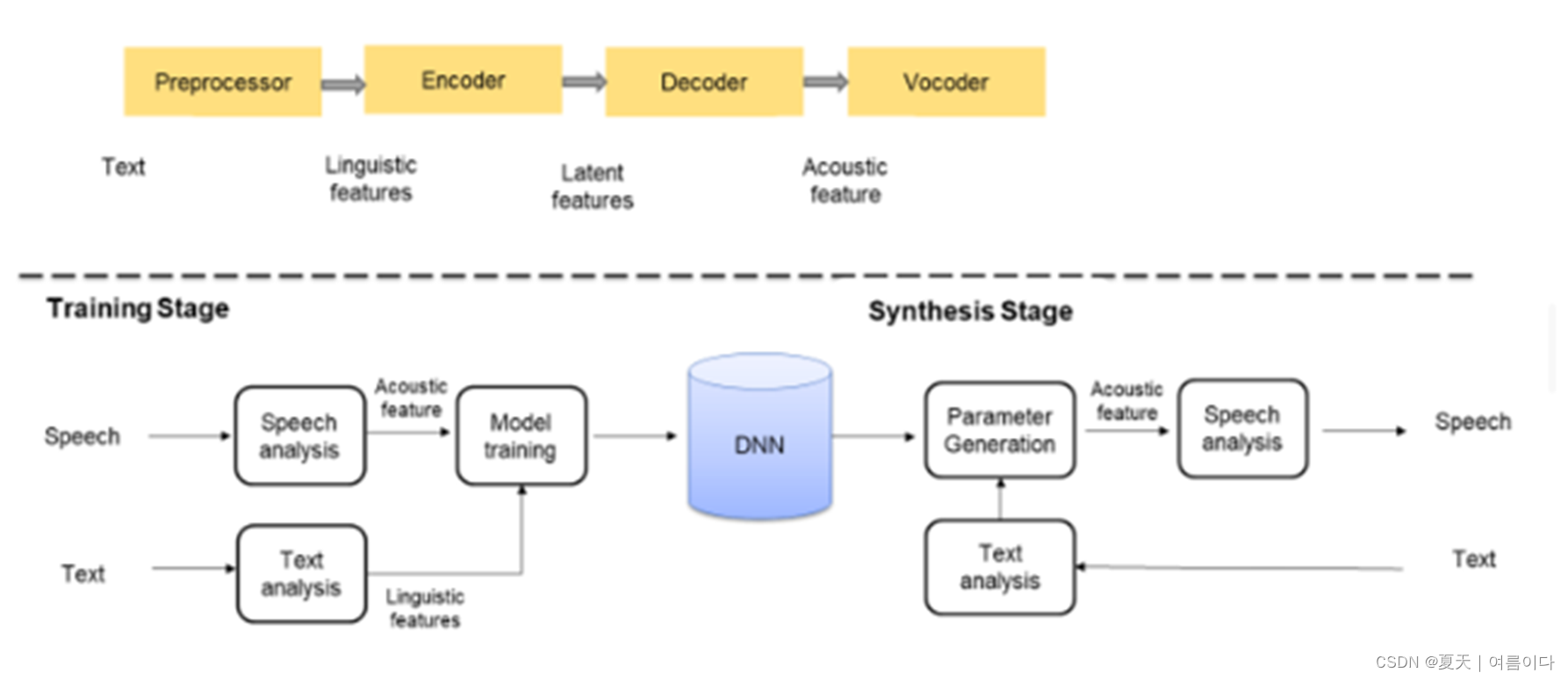
2.模型间的比较

# 比较基于同样的数据,参数等测试结果
3.模型优缺点
Fatespeech系列是俩阶段模型,对数据要求较高,尤其在使用MFA工具进行对齐时,可能出现错误,且语音数据越多,相对来说学习的越好。
VITS系列典型的端到端模型,便于训练,且在数据集较少的情况下依旧可以生成较好的语音。

![红队专题-从零开始VC++C/S远程控制软件RAT-MFC-[5]客户端与服务端连接](https://img-blog.csdnimg.cn/69bda4c6158d412abc7a503189f78fe8.png)


![2023年中国熔盐储能装机量、新增装机量及行业投资规模分析[图]](https://img-blog.csdnimg.cn/img_convert/ca455f9baba4380fb2304ab6ec63852e.png)