1.环境说明:
| 系统 | 主机名 | IP地址 | 内存 | 添加共享磁盘大小 |
|---|---|---|---|---|
| Centos7.9 | gpfs1 | 192.168.10.101 | 2G | 20G |
| Centos7.9 | gpfs2 | 192.168.10.102 | 2G | 20G |
2.环境配置:
-
配置网路IP地址:
-
修改网卡会话:
nmcli connection modify ipv4.method manual ipv4.addresses '192.168.10.101/24' \ ipv4.gateway 192.168.10.2 ipv4.dns 8.8.8.8 autoconnect yes nmcli conection up ens33 -
(可选)在网卡上添加会话:
nmcli connection add type ethernet con-name ens38 ifname ens38 \ ipv4.method manual ipv4.addresses '192.168.10.152/24' \ ipv4.gateway 192.168.10.2 ipv4.dns 8.8.8.8 autoconnect yes nmcli connection up ens38
-
-
关闭防火墙和selinux:
[root@localhost ~]# systemctl stop firewalld;systemctl disable firewalld Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service. [root@localhost ~]# sed -i 's/SELINUX=.*/SELINUX=disabled/' /etc/selinux/config [root@localhost ~]# reboot 连接断开 连接主机... 连接主机成功 Last failed login: Wed Jul 12 19:43:52 EDT 2023 on tty1 There was 1 failed login attempt since the last successful login. Last login: Wed Jul 12 11:53:49 2023 from 192.168.178.1 [root@localhost ~]# getenforce Disabled
3.配置yum源:
-
配置本地yum源:
mkdir /mnt/cdrom;mount /dev/cdrom /mnt/cdromcat << eof >> /etc/fstab /dev/cdrom /mnt/cdrom iso9660 defaults 0 0 eofcat << eof > /etc/yum.repos.d/centos-local.repo [centos7.9] name=centos7.9 baseurl=file:///mnt/cdrom enabled=1 gpgcheck=0 eofyum clean all && yum repolist -
配置扩展源:
yum install epel-release -yyum clean all && yum repolist -
(可选)配置远程阿里源:
yum install -y wget && wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repoyum clean all && yum repolist
4.安装必要工具:
yum install -y bash-completion vim net-tools tree psmisc lrzsz dos2unix5.配置域名映射:
cat << eof >> /etc/hosts
192.168.10.101 node1
192.168.10.102 node2
192.168.10.111 client-side
eof6.ssh免密登录:
# 自己生成的公钥也要给自己添加上
ssh-keygen -t rsa -b 1024
ssh-copy-id -i ~/.ssh/id_rsa.pub root@[IP地址]7.配置chrony时间服务器:
-
两个节点都并且连接到阿里云时间服务器,安装:
[root@node1 ~]# yum -y install chrony
-
启动进程:
[root@node1 ~]# systemctl enable chronyd;systemctl start chronyd
-
node1节点,修改配置文件/etc/chrony.conf
[root@node1 ~]# sed -i '/^server [0-9]/d' /etc/chrony.conf
[root@node1 ~]# sed -i '2a\server 192.168.10.101 iburst\' /etc/chrony.conf [root@node1 ~]# sed -i 's/#allow 192.168.0.0\/16/allow 192.168.10.0\/24/' /etc/chrony.conf [root@node1 ~]# sed -i 's/#local stratum 10/local stratum 10/' /etc/chrony.conf
-
node2节点,修改配置文件/etc/chrony.conf
[root@node2 ~]# sed -i '/^server [0-9]/d' /etc/chrony.conf [root@node2 ~]# sed -i '2a\server 192.168.10.101 iburst\' /etc/chrony.conf
-
重启服务:
[root@node1 ~]# systemctl restart chronyd
-
查看时间同步状态:
[root@node1 ~]# timedatectl status Local time: 三 2023-07-26 23:02:14 EDT Universal time: 四 2023-07-27 03:02:14 UTC RTC time: 四 2023-07-27 03:02:14 Time zone: America/New_York (EDT, -0400) NTP enabled: yes NTP synchronized: yes RTC in local TZ: no DST active: yes Last DST change: DST began at 日 2023-03-12 01:59:59 EST 日 2023-03-12 03:00:00 EDT Next DST change: DST ends (the clock jumps one hour backwards) at 日 2023-11-05 01:59:59 EDT 日 2023-11-05 01:00:00 EST
-
开启网络时间同步:
[root@node1 ~]# timedatectl set-ntp true
-
查看具体的同步信息:
[root@node1 ~]# chronyc sources -v 210 Number of sources = 1 .-- Source mode '^' = server, '=' = peer, '#' = local clock. / .- Source state '*' = current synced, '+' = combined , '-' = not combined, | / '?' = unreachable, 'x' = time may be in error, '~' = time too variable. || .- xxxx [ yyyy ] +/- zzzz || Reachability register (octal) -. | xxxx = adjusted offset, || Log2(Polling interval) --. | | yyyy = measured offset, || \ | | zzzz = estimated error. || | | \ MS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^* 203.107.6.88 2 6 17 2 +2105us[+1914us] +/- 20ms
8.配置共享硬盘:
-
前提:两台虚拟机没有拍摄快照
-
在mds001主机中:
-
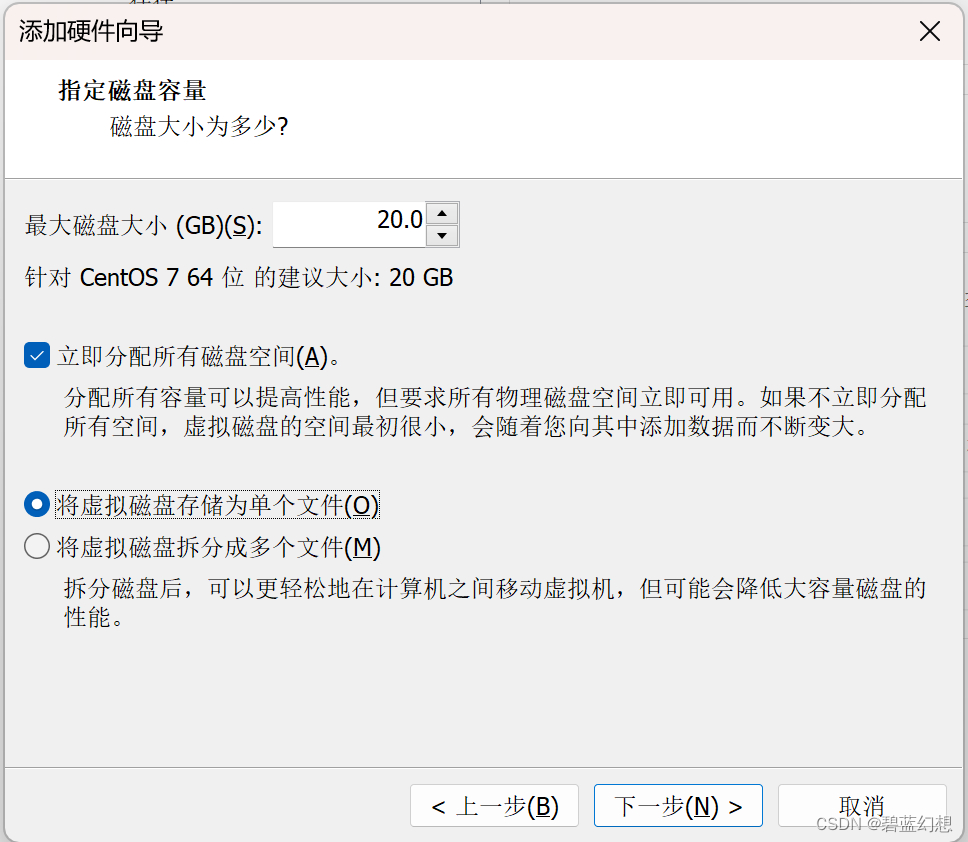
添加五块5G的硬盘
SCSI > 创建新虚拟磁盘 > 指定磁盘容量 ,立即分配所有磁盘空间,将虚拟磁盘存储为单个文件
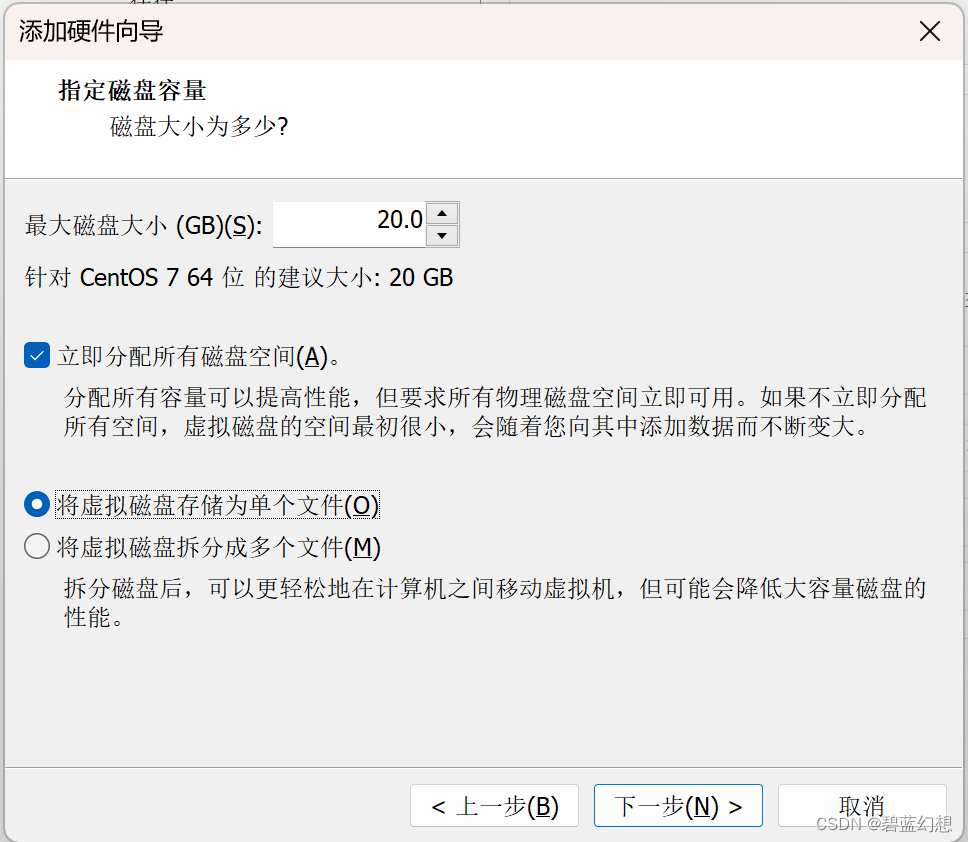
-
修改磁盘属性:
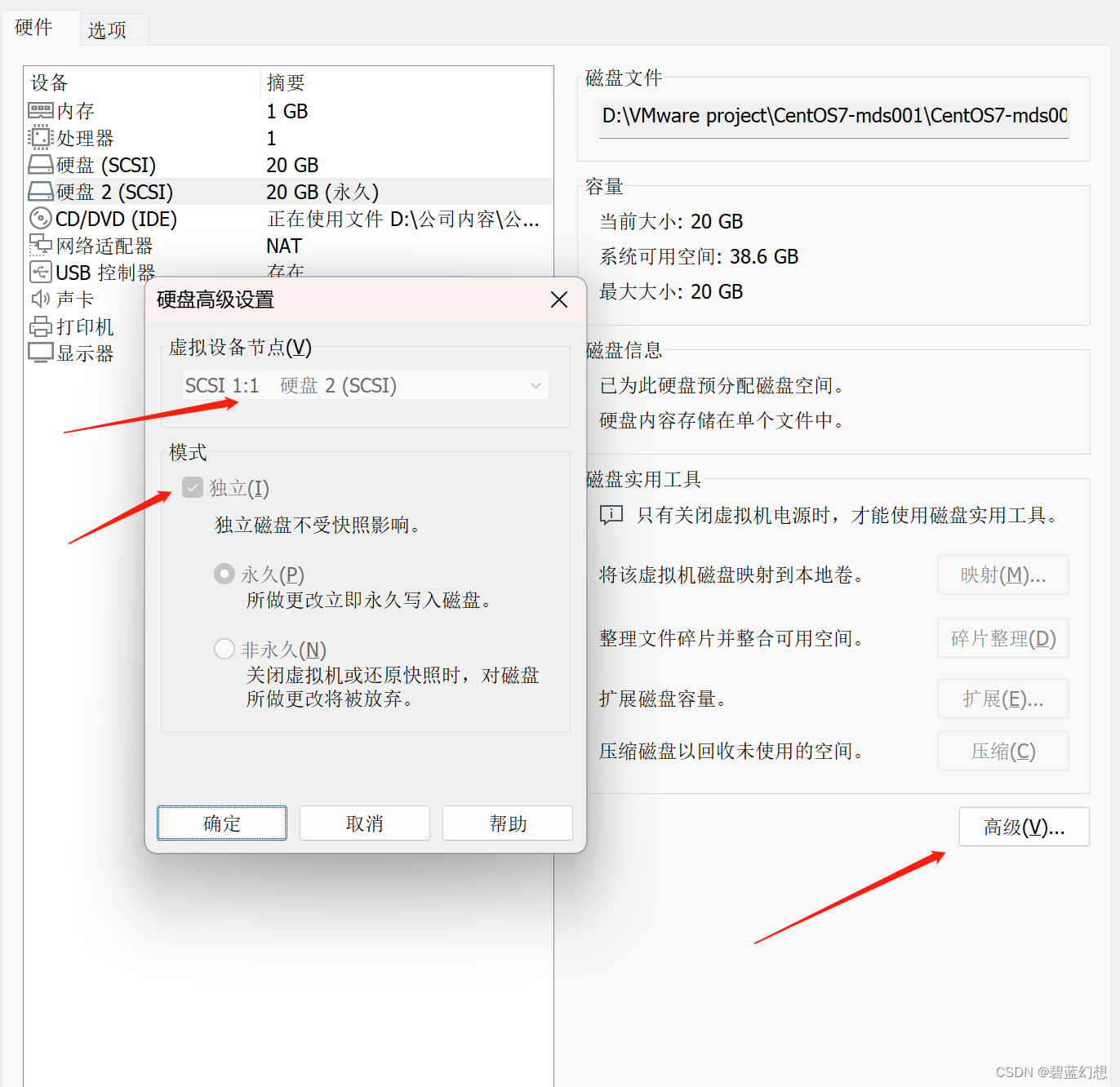
-
-
在mds002主机中:
-
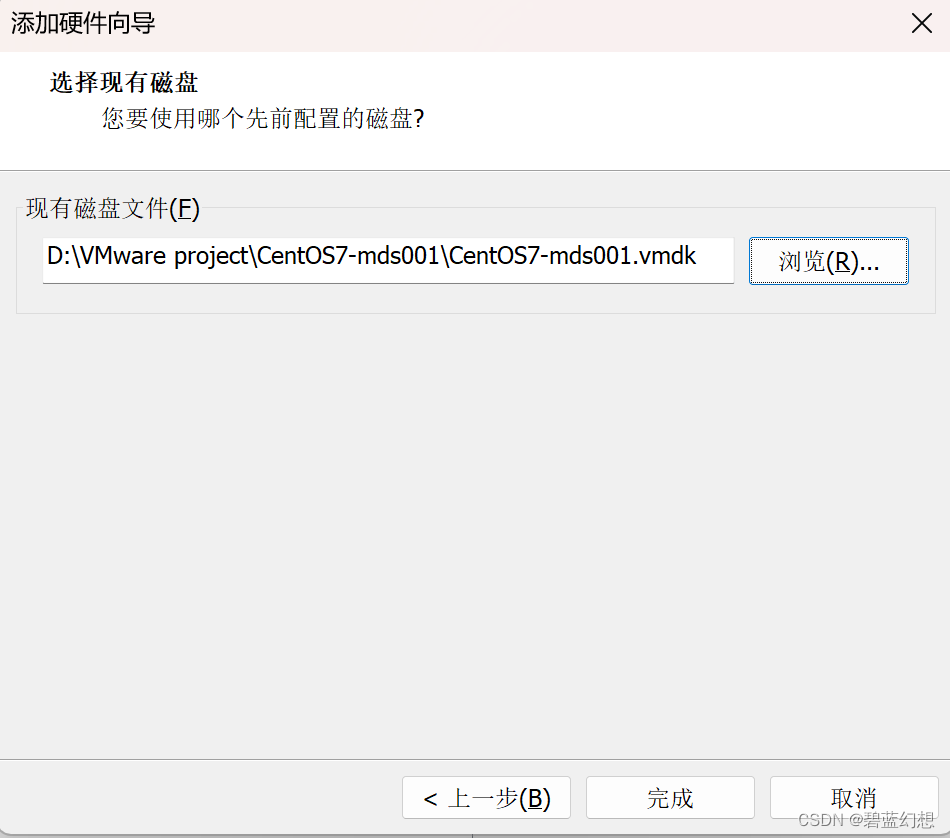
添加5块5G的硬盘
SCSI > 使用已有的虚拟磁盘 > 指定磁盘容量 ,立即分配所有磁盘空间,将虚拟磁盘存储为单个文件 > 选择mds001主机新添加的磁盘文件
-
-
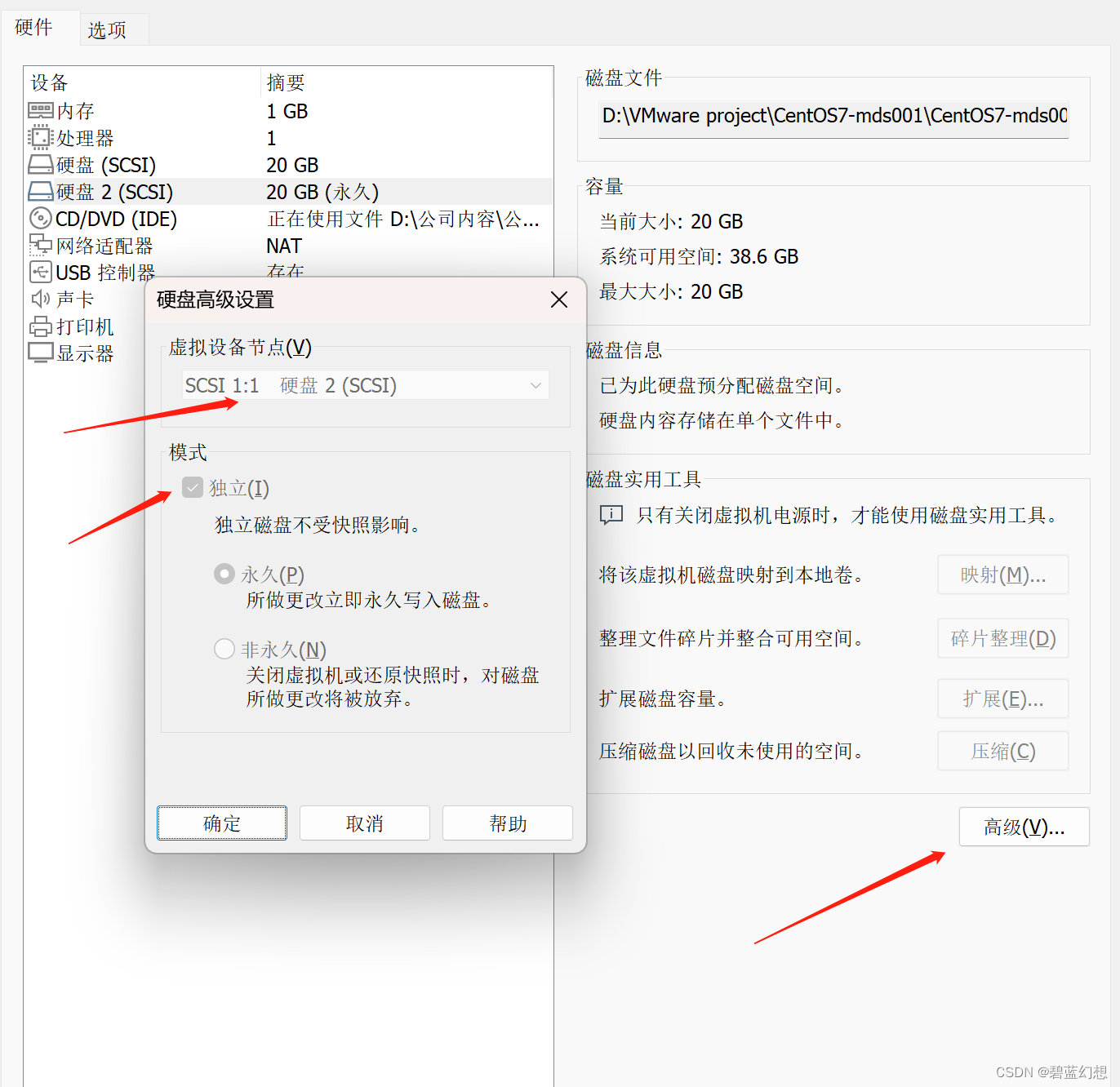
修改磁盘属性:
-
-
在mds001和mds002的虚拟机目录下,找个后缀名为vmx的文件,在文件末尾添加一下内容:
scsi1.sharedBus = "virtual" disk.locking = "false" diskLib.dataCacheMaxSize = "0" diskLib.dataCacheMaxReadAheadSize = "0" diskLib.dataCacheMinReadAheadSize = "0" diskLib.dataCachePageSize = "4096" diskLib.maxUnsyncedWrites = "0" disk.EnableUUID = "TRUE"
-
重启两台虚拟机发现,添加成功
[root@mds001 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 20G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 19G 0 part ├─centos-root 253:0 0 17G 0 lvm / └─centos-swap 253:1 0 2G 0 lvm [SWAP] sdb 8:16 0 5G 0 disk sdc 8:32 0 5G 0 disk sdd 8:48 0 5G 0 disk sde 8:64 0 5G 0 disk sdf 8:80 0 5G 0 disk sr0 11:0 1 9.5G 0 rom /mnt/cdrom
9.安装GPFS软件包:
-
GPFS所需包:
软件包 说明 gpfs.base-4.2.3-22.x86_64.rpm GPFS的基本软件包(GPFS服务器和客户端组件) gpfs.docs-4.2.3-22.noarch.rpm GPFS的文档和帮助文件软件包 gpfs.gpl-4.2.3-22.noarch.rpm GPFS的GNU通用公共许可证(GPL)软件包,包含一些GPFS的开源组件 gpfs.gskit-8.0.50-86.x86_64.rpm IBM Global Security Kit(GSKit)的组件,用于加密和安全通信 gpfs.msg.en_US-4.2.3-22.noarch.rpm GPFS的英语消息文件,用于本地化和国际化 gpfs.ext-4.2.3-22.x86_64.rpm GPFS 的扩展工具包,用于安装和管理 GPFS 文件系统的特定组件 -
创建目录:
mkdir ~/gpfs-4.2.3-22
-
上传gpfs的rpm包
-
安装依赖:
yum -y install make perl rsh ld-linux.so libm.so.6 libc.so.6 ksh libstdc++.so.5 rsh-server rpcbind xinetd libaio cpp gcc-c++ gcc nfs-utils kernel-headers kernel-devel compat-libstdc++ glibc-devel libXp.so.6 imake rpm-build rpm-build m4
-
安装:
cd ~/gpfs-4.2.3-22 && rpm -ivh \ gpfs.base-4.2.3-22.x86_64.rpm \ gpfs.docs-4.2.3-22.noarch.rpm \ gpfs.gpl-4.2.3-22.noarch.rpm \ gpfs.gskit-8.0.50-86.x86_64.rpm \ gpfs.msg.en_US-4.2.3-22.noarch.rpm \ gpfs.ext-4.2.3-22.x86_64.rpm
-
编译1:
cd /usr/lpp/mmfs/src && make Autoconfig LINUX_DISTRIBUTION=REDHAT_AS_LINUX && make World && make InstallImages
-
编译问题:
-
问题一:
Cannot find a valid kernel header file. One of these files should exist. /lib/modules/3.10.0-1160.el7.x86_64/build/include/linux/version.h /usr/src/linux-3.10.0-1160.el7.x86_64/include/linux/version.h /usr/src/kernels/3.10.0-1160.el7.x86_64/include/generated/uapi/linux/version.h /lib/modules/3.10.0-1160.el7.x86_64/build/include/generated/uapi/linux/version.h Contact IBM Service if you still encounter this problem after you install all the required packages. make: *** [Autoconfig] 错误 1
# 原因:路径/usr/src/kernels/3.10.0-1160.el7.x86_64不存在 [root@gpfs 3.10.0-1160.el7.x86_64]# ll /lib/modules/3.10.0-1160.el7.x86_64 total 3300 lrwxrwxrwx. 1 root root 39 Aug 31 08:35 build -> /usr/src/kernels/3.10.0-1160.el7.x86_64 .....
[root@node1 src]# wget http://mirror.centos.org/centos/7/os/x86_64/Packages/kernel-devel-3.10.0-1160.el7.x86_64.rpm [root@node1 src]# rpm -Uvh kernel-devel-3.10.0-1160.el7.x86_64.rpm --force
-
问题二:
In file included from /usr/include/sys/ioctl.h:26:0, from /usr/lpp/mmfs/src/gpl-linux/lxtrace.c:61: /usr/include/bits/ioctls.h:23:24: 致命错误:asm/ioctls.h:没有那个文件或目录 #include <asm/ioctls.h> ^
[root@node1 src]# find /usr/src/kernels/3.10.0-1160.el7.x86_64 -name "ioctls.h" /usr/src/kernels/3.10.0-1160.el7.x86_64/arch/x86/include/uapi/asm/ioctls.h /usr/src/kernels/3.10.0-1160.el7.x86_64/include/uapi/asm-generic/ioctls.h [root@node1 src]# rm -rf /usr/include/asm/ioctls.h [root@node1 src]# ln -s /usr/src/kernels/3.10.0-1160.el7.x86_64/arch/x86/include/uapi/asm/ioctls.h /usr/include/asm/ioctls.h
-
问题三:
kdump-kern.o:在函数‘GetOffset’中: kdump-kern.c:(.text+0x15):对‘__x86_return_thunk’未定义的引用 kdump-kern.o:在函数‘KernInit’中: kdump-kern.c:(.text+0x1a5):对‘__x86_return_thunk’未定义的引用 kdump-kern.o:在函数‘GenericGet’中: kdump-kern.c:(.text+0x348):对‘__x86_return_thunk’未定义的引用 kdump-kern.c:(.text+0x35e):对‘__x86_return_thunk’未定义的引用 kdump-kern.o:在函数‘tiInit’中: kdump-kern.c:(.text+0x3bc):对‘__x86_return_thunk’未定义的引用 kdump-kern.o:kdump-kern.c:(.text+0x445): 跟着更多未定义的参考到 __x86_return_thunk collect2: 错误:ld 返回 1 make[1]: *** [modules] 错误 1 make[1]: 离开目录“/usr/lpp/mmfs/src/gpl-linux” make: *** [Modules] 错误 1
vim /usr/lpp/mmfs/src/gpl-linux/kdump.c # 在122行添加内容 unsigned long __x86_return_thunk;
-
问题三:
kdump-kern.o: In function `GetOffset': kdump-kern.c:(.text+0x9): undefined reference to `page_offset_base' kdump-kern.o: In function `KernInit': kdump-kern.c:(.text+0x58): undefined reference to `page_offset_base' collect2: error: ld returned 1 exit status make[1]: *** [modules] Error 1 make[1]: Leaving directory `/usr/lpp/mmfs/src/gpl-linux' make: *** [Modules] Error 1
vim /usr/lpp/mmfs/src/gpl-linux/kdump.c # 在122行添加内容 unsigned page_offset_base;
-
-
如果没有任何错误,即为成功
-
继续执行编译命令2:(构建 GPFS 可移植层)
cd /usr/lpp/mmfs/src && make rpm
-
完全成功如下:
检查未打包文件:/usr/lib/rpm/check-files /tmp/rpm 写道:/root/rpmbuild/RPMS/x86_64/gpfs.gplbin-3.10.0-1160.95.1.el7.x86_64-4.2.3-22.x86_64.rpm 执行(%clean): /bin/sh -e /var/tmp/rpm-tmp.WyvdX3 + umask 022 + cd /root/rpmbuild/BUILD + /usr/bin/rm -rf /tmp/rpm + exit 0
-
最后的安装:
[root@gpfs1 src]# rpm -ivh /root/rpmbuild/RPMS/x86_64/gpfs.gplbin-3.10.0-1160.el7.x86_64-4.2.3-22.x86_64.rpm 准备中... ################################# [100%] 正在升级/安装... 1:gpfs.gplbin-3.10.0-1160.95.1.el7.################################# [100%]
-
查看GPFS安装情况:
[root@gpfs1 ~]# rpm -qa|grep gpfs gpfs.msg.en_US-4.2.3-22.noarch gpfs.base-4.2.3-22.x86_64 gpfs.ext-4.2.3-22.x86_64 gpfs.gskit-8.0.50-86.x86_64 gpfs.gplbin-3.10.0-1160.el7.x86_64-4.2.3-22.x86_64 gpfs.gpl-4.2.3-22.noarch gpfs.docs-4.2.3-22.noarch
-
gpfs的执行文件位于/usr/lpp/mmfs/bin目录中,请尽量将此路径添加到系统PATH环境变量中
echo 'export PATH=$PATH:/usr/lpp/mmfs/bin' >> /etc/profile
source /etc/profile
10.创建集群:
-
修改配置文件:
# 第一项为所使用机器的主机名,第二项为配置项,包括quorum节点的指定和manager节点的指定 cat << eof > /tmp/gpfsfile node1:quorum-manager node2:quorum-manager eof
-
创建集群:
参数 说明 -N 指定节点文件名 -p 指定主NSD服务器 -s 指定备NSD服务器 -r和-R -r是rsa密钥,-R是复制命令 -A 指定当节点出现时自动启动 GPFS 守护进程。默认情况下不自动启动守护进程 -C 设定集群名称 -U bgbc 定义域名 -c 配置文件 [root@node1 ~]# mmcrcluster -N /tmp/gpfsfile -p node1 -s node2 -r /usr/bin/ssh -R /usr/bin/scp -A -C gpfs which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) mmcrcluster: Performing preliminary node verification ... node1: which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) mmcrcluster: Processing quorum and other critical nodes ... mmcrcluster: Finalizing the cluster data structures ... mmcrcluster: Command successfully completed mmcrcluster: Warning: Not all nodes have proper GPFS license designations. Use the mmchlicense command to designate licenses as needed. mmcrcluster: Propagating the cluster configuration data to all affected nodes. This is an asynchronous process.
-
创建集群报错:
-
报错1:卡住不动:
[root@node1 ~]# mmcrcluster -N /tmp/gpfsfile -p node1 -s node2 -r /usr/bin/ssh -R /usr/bin/scp -A -C gpfs mmcrcluster: Performing preliminary node verification ... mmcrcluster: Processing quorum and other critical nodes ... mmcrcluster: Finalizing the cluster data structures ...
# 删除iptables yum remove -y iptables
-
报错2:
which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) Tue Sep 12 06:17:05 EDT 2023: mmstartup: Starting GPFS ... which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) node4: which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) node3: which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) node4: The GPFS subsystem is already active. node3: The GPFS subsystem is already active.
yum install iproute -y
-
-
如果执行失败或者中断,可以通过一下命令清除
[root@gpfs1 ~]# mmdelnode -f mmdelnode: [W] This option should only be used to remove all GPFS configuration files on a node that has already been deleted from a cluster. If the node is still a member of a cluster, and it is then added to the same or to another cluster after 'mmdelnode -f' is issued, results will be unpredictable, possibly leading to mmfsd daemon failure. Do you want to continue? (yes/no) yes mmdelnode: All GPFS configuration files on node gpfs1 have been removed.
-
查看GPFS集群:
[root@node1 ~]# mmlscluster which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) GPFS cluster information ======================== GPFS cluster name: gpfs.node1 GPFS cluster id: 1484988891360413006 GPFS UID domain: gpfs.node1 Remote shell command: /usr/bin/ssh Remote file copy command: /usr/bin/scp Repository type: CCR Node Daemon node name IP address Admin node name Designation ---------------------------------------------------------------------- 1 node1 192.168.10.101 node1 quorum-manager 2 node2 192.168.10.102 node2 quorum-manager
-
授权:(服务节点或quorum节点用server,其它节点用client)
[root@node1 ~]# mmchlicense server --accept -N node1,node2 which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) The following nodes will be designated as possessing server licenses: node2 node1 mmchlicense: Command successfully completed mmchlicense: Propagating the cluster configuration data to all affected nodes. This is an asynchronous process.
11.启动集群:
-
启动集群:
[root@node1 ~]# mmstartup -a # -a启动所有节点 Thu Aug 31 23:49:52 EDT 2023: mmstartup: Starting GPFS ...
-
报错问题1:
which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) 2023年 08月 31日 星期四 04:03:03 EDT: mmstartup: Starting GPFS ... which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) node2: which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) node1: which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) node2: mmremote: startSubsys: The /lib/modules/3.10.0-1160.el7.x86_64/extra/mmfslinux.ko kernel extension does not exist. Use mmbuildgpl command to create the needed kernel extension for your kernel or copy the binaries from another node with the identical environment. node2: mmremote: startSubsys: Unable to verify kernel/module configuration. node1: mmremote: startSubsys: The /lib/modules/3.10.0-1160.el7.x86_64/extra/mmfslinux.ko kernel extension does not exist. Use mmbuildgpl command to create the needed kernel extension for your kernel or copy the binaries from another node with the identical environment. node1: mmremote: startSubsys: Unable to verify kernel/module configuration. mmdsh: node2 remote shell process had return code 1. mmdsh: node1 remote shell process had return code 1. mmstartup: Command failed. Examine previous error messages to determine cause.
# 原因:mmfslinux.ko文件在编译过程中根据你(kernel-devel-3.10.0-1160.el7.x86_64版本)的生成,并且生成在/lib/modules/3.10.0-1160.el7.x86_64/extra下。如果你使用的kernel-devel版本是3.10.0-1160.95.1.el7.x86_64,那生成的mmfslinux.ko路径会是/lib/modules/3.10.0-1160.95.1.el7.x86_64/extra。 # 所以我这里的解决方法是:下载kernel-devel-3.10.0-1160.el7.x86_64 [root@node1 ~]# rpm -qa | grep kernel kernel-3.10.0-1160.el7.x86_64 kernel-headers-3.10.0-1160.95.1.el7.x86_64 kernel-tools-3.10.0-1160.el7.x86_64 kernel-tools-libs-3.10.0-1160.el7.x86_64 kernel-devel-3.10.0-1160.el7.x86_64
-
报错2:
which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) Tue Sep 12 06:17:05 EDT 2023: mmstartup: Starting GPFS ... which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) node4: which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) node3: which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) node4: The GPFS subsystem is already active. node3: The GPFS subsystem is already active.
yum install iproute -y
12.查看集群状态:
[root@node1 ~]# mmgetstate -Lsa Node number Node name Quorum Nodes up Total nodes GPFS state Remarks ------------------------------------------------------------------------------------ 1 node1 2 0 2 arbitrating quorum node 2 node2 2 0 2 arbitrating quorum node Summary information --------------------- mmgetstate: Information cannot be displayed. Either none of the nodes in the cluster are reachable, or GPFS is down on all of the nodes.
13.查看GPFS集群日志:
[root@node1 ras]# tail -f /var/adm/ras/mmsdrserv.log 2023-08-31_01:57:40.570-0400: 2063787904 [N] Starting CCR serv ... 2023-08-31_02:11:42.723-0400: 2022106880 [N] CCR: Resetting previous state before 'initialization' enter 2023-08-31_02:11:42.728-0400: 2022106880 [N] CCR: initialization complete; cluster 1484988891360405094 node 1 epoch 0 err 0 2023-08-31_02:35:16.673-0400: 2617968512 [N] Starting CCR serv ... 2023-08-31_02:48:53.968-0400: 2576287488 [N] CCR: Resetting previous state before 'initialization' enter 2023-08-31_02:48:53.983-0400: 2576287488 [N] CCR: initialization complete; cluster 1484988891360408201 node 1 epoch 0 err 0 which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) 2023-08-31_03:49:15.246-0400: 2769160064 [N] Starting CCR serv ... 2023-08-31_03:49:15.712-0400: 2727479040 [N] CCR: Resetting previous state before 'initialization' enter 2023-08-31_03:49:15.717-0400: 2727479040 [N] CCR: initialization complete; cluster 1484988891360413006 node 1 epoch 0 err 0
14.释放文件锁:
-
有时候会出现无法执行命令无法读取配置文件的错误
-
原因:有命令正在执行没有释放文件锁,所以我们无法获取
-
解决方法如下:
-
查看是否存在配置文件锁:
[root@node1 ~]# mmcommon showLocks which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) lockServer lockName lockHolder PID Extended Info ---------------------------------------------------------------------------------------------- node1 mmfsEnvLock node1 12546 12546 2432 /usr/lpp/mmfs/bin/mmksh /usr/lpp/mmfs/bin/mmdelnsd -p C0A80A6564F056B9 CCR mmSdrLock node1 12546 12546 2432 /usr/lpp/mmfs/bin/mmksh /usr/lpp/mmfs/bin/mmdelnsd -p C0A80A6564F056B9
-
释放文件锁:
[root@node1 ~]# mmcommon freeLocks mmfsEnvLock
14.创建NSD磁盘:
-
修改配置文件:
usage属性值 说明 dataAndMetadata 表示该磁盘存储GPFS文件系统的数据和元数据(默认情况);用于系统池中的磁盘 dataOnly 表示该磁盘只存储GPFS文件系统的数据; metadataOnly 表示该磁盘只存储GPFS文件系统的元数据; descOnly 表示该磁盘既没有元数据也没有数据;仅用于保存文件系统描述符(灾难恢复) localCache 表示该磁盘作为本地只读缓存 # NSD磁盘的名称 %nsd: nsd=NSD_1 # 磁盘路径 device=/dev/sdb # 节点列表,最前的最先IO,如果前面的节点故障后面的接管 servers=node1 node2 # GPFS文件系统的存储方式 usage=dataAndMetadata # 用于指定NSD(Network Shared Disk)共享磁盘所属的故障组,如果将多个NSD分配到同一个故障组中,GPFS将确保文件系统的数据在这些NSD之间分布均匀,以提供冗余和容错性。 failureGroup=100 # 用于指定NSD(Network Shared Disk)共享磁盘所属的存储池,存储池是GPFS中的一个概念,它允许您将存储资源组织和分配给不同的文件系统或目录。通过将NSD分配给特定的存储池,您可以更好地控制和管理文件系统的存储资源。 pool=system
cat << eof > /tmp/nsd.node %nsd: nsd=NSD_1 device=/dev/sdb servers=node1,node2 usage=dataAndMetadata failureGroup=100 pool=system %nsd: nsd=NSD_2 device=/dev/sdc servers=node1,node2 usage=dataAndMetadata failureGroup=100 pool=system eof
-
使用mmcrnsd命令创建NSD磁盘
mmcrnsd命令参数 说明 -F 指定配置文件 -v 验证磁盘是否已格式化为NSD(默认yes), -A 指定是否将NSD标记为可共享,即是否允许多个节点访问(默认no) -p 用于指定NSD(Network Shared Disk)共享磁盘所属的存储池, -t 指定NSD的描述文本,提供有关该NSD的描述信息 -s 指定NSD的大小。通常,如果未指定 -s参数,GPFS 会自动检测磁盘的大小-f 用于指定NSD(Network Shared Disk)共享磁盘所属的故障组 -h 显示命令的帮助信息 -m 将NSD分配给的存储池的编号 [root@node1 src]# mmcrnsd -F /tmp/nsd.node -v no mmcrnsd: Processing disk sdb mmcrnsd: Processing disk sdc mmcrnsd: Processing disk sdb mmcrnsd: Processing disk sdc mmcrnsd: Propagating the cluster configuration data to all affected nodes. This is an asynchronous process.
-
查看nsd信息:
[root@node1 ~]# mmlsnsd -m Disk name NSD volume ID Device Node name Remarks --------------------------------------------------------------------------------------- NSD_1 C0A80A656501153A /dev/sdb node1 server node NSD_1 C0A80A656501153A /dev/sdb node2 server node NSD_2 C0A80A656501153C /dev/sdc node1 server node NSD_2 C0A80A656501153C /dev/sdc node2 server node
-
查看NSD配置文件:
[root@node1 ~]# cat cat /tmp/nsd.node cat: cat: No such file or directory # /dev/sdb:node1::dataAndMetadata:1:nsd1: nsd1:::dataAndMetadata:1::system # /dev/sdc:node2::dataAndMetadata:1:nsd2: nsd2:::dataAndMetadata:1::system
15.配置tiebreaker仲裁盘:
-
仲裁盘作用:
-
当定义的仲裁盘有一半的磁盘不可用时,该集群不可用。
-
有效磁盘数小于等于整个磁盘数一半时,整个文件系统不可用
-
-
配置仲裁盘:
mmchconfig tiebreakerDisks="NSD_1;NSD_2"
16.在线添加NSD:
-
添加一块共享硬盘:
[root@node3 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 20G 0 disk |-sda1 8:1 0 1G 0 part /boot `-sda2 8:2 0 19G 0 part |-centos-root 253:0 0 17G 0 lvm / `-centos-swap 253:1 0 2G 0 lvm [SWAP] sdb 8:16 0 5G 0 disk `-sdb1 8:17 0 5G 0 part sdc 8:32 0 5G 0 disk `-sdc1 8:33 0 5G 0 part sdd 8:48 0 5G 0 disk sr0 11:0 1 9.5G 0 rom /mnt/cdrom
-
修改配置文件:
usage属性值 说明 dataAndMetadata 表示该磁盘存储GPFS文件系统的数据和元数据(默认情况);用于系统池中的磁盘 dataOnly 表示该磁盘只存储GPFS文件系统的数据; metadataOnly 表示该磁盘只存储GPFS文件系统的元数据; descOnly 表示该磁盘既没有元数据也没有数据;仅用于保存文件系统描述符(灾难恢复) localCache 表示该磁盘作为本地只读缓存 # NSD磁盘的名称 %nsd: nsd=NSD_1 # 磁盘路径 device=/dev/sdb # 节点列表,最前的最先IO,如果前面的节点故障后面的接管 servers=node1 node2 # GPFS文件系统的存储方式 usage=dataAndMetadata # 用于指定NSD(Network Shared Disk)共享磁盘所属的故障组,如果将多个NSD分配到同一个故障组中,GPFS将确保文件系统的数据在这些NSD之间分布均匀,以提供冗余和容错性。 failureGroup=100 # 用于指定NSD(Network Shared Disk)共享磁盘所属的存储池,存储池是GPFS中的一个概念,它允许您将存储资源组织和分配给不同的文件系统或目录。通过将NSD分配给特定的存储池,您可以更好地控制和管理文件系统的存储资源。 pool=system
cat << eof > /tmp/nsd.node %nsd: nsd=NSD_1 device=/dev/sdb servers=node1,node2 usage=dataAndMetadata failureGroup=100 pool=system %nsd: nsd=NSD_2 device=/dev/sdc servers=node1,node2 usage=dataAndMetadata failureGroup=100 pool=system %nsd: nsd=NSD_3 device=/dev/sdd servers=node1,node2 usage=dataAndMetadata failureGroup=100 pool=system eof
-
使用mmcrnsd命令创建NSD磁盘:
mmcrnsd命令参数 说明 -F 指定配置文件 -v 验证磁盘是否已格式化为NSD(默认yes), -A 指定是否将NSD标记为可共享,即是否允许多个节点访问(默认no) -p 用于指定NSD(Network Shared Disk)共享磁盘所属的存储池, -t 指定NSD的描述文本,提供有关该NSD的描述信息 -s 指定NSD的大小。通常,如果未指定 -s参数,GPFS 会自动检测磁盘的大小-f 用于指定NSD(Network Shared Disk)共享磁盘所属的故障组 -h 显示命令的帮助信息 -m 将NSD分配给的存储池的编号 [root@node1 src]# mmcrnsd -F /tmp/nsd.node -v no mmcrnsd: Processing disk sdb mmcrnsd: Processing disk sdc mmcrnsd: Processing disk sdb mmcrnsd: Processing disk sdc mmcrnsd: Propagating the cluster configuration data to all affected nodes. This is an asynchronous process.
-
查看nsd信息:
[root@node1 ~]# mmlsnsd -m Disk name NSD volume ID Device Node name Remarks --------------------------------------------------------------------------------------- NSD_1 C0A80A656501153A /dev/sdb node1 server node NSD_1 C0A80A656501153A /dev/sdb node2 server node NSD_2 C0A80A656501153C /dev/sdc node1 server node NSD_2 C0A80A656501153C /dev/sdc node2 server node NSD_3 C0A80A6565011BB5 /dev/sdd node1 server node NSD_3 C0A80A6565011BB5 /dev/sdd node2 server node
17.删除NSD磁盘:
-
查看是否存在配置文件锁:
[root@node1 ~]# mmcommon showLocks which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) lockServer lockName lockHolder PID Extended Info ---------------------------------------------------------------------------------------------- node1 mmfsEnvLock node1 12546 12546 2432 /usr/lpp/mmfs/bin/mmksh /usr/lpp/mmfs/bin/mmdelnsd -p C0A80A6564F056B9 CCR mmSdrLock node1 12546 12546 2432 /usr/lpp/mmfs/bin/mmksh /usr/lpp/mmfs/bin/mmdelnsd -p C0A80A6564F056B9
-
释放文件锁:
[root@node1 ~]# mmcommon freeLocks mmfsEnvLock
-
查看存在的NSD磁盘:
[root@node1 ~]# mmlsnsd -m which: no ip in (/bin:/usr/bin:/sbin:/usr/sbin:/usr/lpp/mmfs/bin) Disk name NSD volume ID Device Node name Remarks --------------------------------------------------------------------------------------- nsd1 C0A80A6564F056B9 /dev/sdb node1 server node nsd1 C0A80A6564F056B9 /dev/sdb node2 nsd2 C0A80A6564F056BB /dev/sdc node1 server node nsd2 C0A80A6564F056BB /dev/sdc node2 nsd3 C0A80A6664F056BC /dev/sdd node1 nsd3 C0A80A6664F056BC /dev/sdd node2 server node nsd4 C0A80A6664F056BE /dev/sde node1 nsd4 C0A80A6664F056BE /dev/sde node2 server node
-
删除NSD磁盘:
[root@node1 ~]# mmdelnsd nsd1
[root@node1 ~]# mmdelnsd -F /tmp/nsd.node
18.创建GPFS文件系统:
-
参数:
参数 说明 /gpfs1 文件系统 mount 点名称 /dev/gpfs1 指定文件系统 lv 名称 -F 指定 NSD 的文件名 -A 自动 mount 选项为 yes -B 块大小为512K -n 代表该集群最大支持节点数 -j 代表存储工作方式为集群方式 -Q 代表打开磁盘配额管理功能 -
创建GPFS文件系统:
[root@node1 ~]# mmcrfs /gpfs1 /dev/gpfs1 -F /tmp/nsd.node -A yes -B 512k -m 1 -M 2 -r 1 -R 2 -n 512 -j cluster -Q yes The following disks of gpfs1 will be formatted on node node1: nsd1: size 5120 MB nsd2: size 5120 MB Formatting file system ... Disks up to size 596 GB can be added to storage pool system. Creating Inode File Creating Allocation Maps Creating Log Files Clearing Inode Allocation Map Clearing Block Allocation Map Formatting Allocation Map for storage pool system Completed creation of file system /dev/gpfs1. mmcrfs: Propagating the cluster configuration data to all affected nodes. This is an asynchronous process.
-
查看集群状态:
[root@node1 ~]# mmgetstate -a # 查看集群状态,所有节点为active,则集群正常启动 Node number Node name GPFS state ------------------------------------------ 1 node1 active 2 node2 active
[root@node1 ~]# mmlsconfig Configuration data for cluster gpfs-node1-2.node1: -------------------------------------------------- clusterName gpfs-node1-2.node1 clusterId 1484988891361513241 autoload yes dmapiFileHandleSize 32 minReleaseLevel 4.2.3.9 ccrEnabled yes cipherList AUTHONLY tiebreakerDisks NSD_1;NSD_2 adminMode central File systems in cluster gpfs-node1-2.node1: ------------------------------------------- /dev/gpfs1
19.挂载GPFS文件系统:
mmmount all -a # 在所有节点挂载所有GPFS mmmount /gpfs1 -N node1 # 在某节点挂载某GPFS文件系统
[root@node1 src]# mmlsmount gpfs1 -L File system gpfs1 is mounted on 3 nodes: 192.168.10.101 node1 192.168.10.102 node2 192.168.10.111 client-side
-
报错1:
[root@node1 gpfs1]# mmumount gpfs1 -N node2 Wed Sep 13 10:19:32 EDT 2023: mmumount: Unmounting file systems ... node2: /bin/ksh: /usr/lpp/mmfs/bin/mmremote: not found mmumount: Command failed. Examine previous error messages to determine cause.
# 安装gpfs-base软件包 rpm -ivh gpfs.base-4.2.3-22.x86_64.rpm