@深度学习基础知识
深度学习基础知识(一):卷积神经网络CNN基础知识
卷积神经网络CNN基础知识
0、目录
1. CNN卷积神经网络的特点
2. 卷积操作基础知识
2.1 卷积操作的概念
2.2 卷积操作的种类
2.3 卷积操作后特征图谱大小计算公式
3. 池化操作基础知识
3.1 池化操作的作用/为什么要进行池化操作?
3.2 池化操作的种类
3.3 池化操作后特征图谱大小计算公式
1、CNN卷积神经网络的特点
- CNN的使用范围是具有局部空间相关性的数据,比如图像、自然语言、语音。
- 局部连接(稀疏连接):可以提取局部特征
- 权值共享:减少参数数量,降低训练难度,避免过拟合,提升模型“平移不变性”
- 降维:通过池化或卷积stride实现
- 多层次结构:将低层次的局部特征组合成较高层次的特征,不同层级的特征可以对应不同任务
2、卷积操作基础知识
2.1 卷积操作的概念
- 卷积操作
当卷积核在输入图像上扫描时,将卷积核与输入图像中对应位置的数值逐个相乘,最后汇总求和,就得到该位置的卷积结果。不断移动卷积核,就可算出各个位置的卷积结果。 - 卷积属性
- 卷积核(Kernel):卷积操作的感受野,直观理解就是一个滤波矩阵,普遍使用的卷积核大小为3×3、5×5等;
- 步长(Stride):卷积核遍历特征图时每步移动的像素,如步长为1则每次移动1个像素,步长为2则每次移动2个像素(即跳过1个像素),以此类推;
- 填充(Padding):处理特征图边界的方式,一般有两种,一种是对边界外完全不填充,只对输入像素执行卷积操作,这样会使输出特征图的尺寸小于输入特征图尺寸;另一种是对边界外进行填充(一般填充为0),再执行卷积操作,这样可使输出特征图的尺寸与输入特征图的尺寸一致;
- 通道(Channel):卷积层的通道数(层数)
- 卷积操作示意图
如下图所示,一个卷积核(kernel)为3×3、步长(stride)为1、填充(padding)为1的二维卷积过程:

- 卷积操作计算示意图
如下图所示,一个33大小的卷积核(矩阵)正在一个55大小的图像(矩阵)进行扫描,根据公式:y=wx进行叠加即可:

2.2 卷积操作的种类
- 二维卷积(单通道卷积版本)
- 2D Convolution: the single channel version
- 只有一个通道的卷积
- 如下图是一个卷积核(kernel)为3×3、步长(stride)为1、填充(padding)为0的卷积
- 二维卷积(多通道版本)
-
2D Convolution: the multi-channel version
-
拥有多个通道的卷积,例如处理彩色图像时,分别对R, G, B这3个层处理的3通道卷积,如下图:

-
再将三个通道的卷积结果进行合并(一般采用元素相加),得到卷积后的结果,如下图:

- 三维卷积3D Convolution
- 卷积有三个维度(高度、宽度、通道),沿着输入图像的3个方向进行滑动,最后输出三维的结果
- 1x1卷积
- 当卷积核尺寸为1x1时的卷积,也即卷积核变成只有一个数字。
- 1x1卷积的作用在于能有效地减少维度,降低计算的复杂度。
- 反卷积 / 转置卷积
- Deconvolution / Transposed Convolution)
- 卷积是对输入图像提取出特征(可能尺寸会变小),而所谓的“反卷积”便是进行相反的操作。但这里说是“反卷积”并不严谨,因为并不会完全还原到跟输入图像一样,一般是还原后的尺寸与输入图像一致,主要用于向上采样。
- 从数学计算上看,“反卷积”相当于是将卷积核转换为稀疏矩阵后进行转置计算,因此,也被称为“转置卷积”
- 如下图,在2x2的输入图像上应用步长为1、边界全0填充的3x3卷积核,进行转置卷积(反卷积)计算,向上采样后输出的图像大小为4x4。

6. 空洞卷积(膨胀卷积)
- Dilated Convolution / Atrous Convolution
- 为扩大感受野,在卷积核里面的元素之间插入空格来“膨胀”内核,形成“空洞卷积”(或称膨胀卷积),并用膨胀率参数L表示要扩大内核的范围,即在内核元素之间插入L-1个空格。
- 当L=1时,则内核元素之间没有插入空格,变为标准卷积。 如下图为膨胀率L=2的空洞卷积:

- 空间可分离卷积(Spatially Separable Convolutions)
- 空间可分离卷积是将卷积核分解为两项独立的核分别进行操作。一个3x3的卷积核分解如下图:

- 分解后的卷积计算过程如下图,先用3x1的卷积核作横向扫描计算,再用1x3的卷积核作纵向扫描计算,最后得到结果。采用可分离卷积的计算量比标准卷积要少。

- 深度可分离卷积(Depthwise Separable Convolutions)
- 深度可分离卷积的方法有所不同。正常卷积核是对3个通道同时做卷积。也就是说,3个通道,在一次卷积后,输出一个数。
- 深度可分离卷积分为两步:
(1)用三个卷积对三个通道分别做卷积,这样在一次卷积后,输出3个数。
(2)这输出的三个数,再通过一个1x1x3的卷积核(pointwise核),得到一个数。所以深度可分离卷积其实是通过两次卷积实现的。
第一步,对三个通道分别做卷积,输出三个通道的属性:

具体运算过程如下:

第二步,用卷积核1x1x3对三个通道再次做卷积,这个时候的输出就和正常卷积一样,是8x8x1:

-
这步就是正常的卷积过程,只是卷积核大小为(3x1x1),一个卷积核得到一个特征图;8x8x3 * 1x1x3x1 => 8x8x1。
-
深度可分离与普通卷积神经网络的区别
添加了一个1*1的卷积核 如果仅仅是提取一个属性,深度可分离卷积的方法,不如正常卷积 随着要提取的属性越来越多,深度可分离卷积就能够节省更多的参数 -
计算量比较
默认输入图像大小为D*D 默认卷积核大小为K*K M:输入通道数,N:输出通道数, 普通卷积 = K * K * M * N * D * D 深度可分离卷积 = K *K * M * D * D + M * N * D * D 优化比例 = (K *K * M * D * D + M * N * D * D)/ (K * K * M * N * D * D)=1/N+1/(K * K) -
总结
========== DSC作为普通卷积的一种替代品,它的最大优点是计算效率非常高。 因此使用DSC构建轻量级模型是当下非常常见的做法。 不过DSC的这种高效性是以低精度作为代价的。 ===========
2.3 卷积操作后特征图谱大小计算公式
1.普通卷积
经过某层卷积操作后的特征图大小计算方式:
====
h1代表输入图像的高度,w1代表输入图像的宽度,k代表卷积核大小,s代表步长
====
h2、w2分别代表输出的特征图像高度和宽度
====
h2 = (h1-k+2padding)/s + 1
w2 = (w1-k+2padding)/s + 1
2.空洞卷积
空洞卷积的等效卷积核大小
h1代表输入图像的高度,k代表卷积核大小,s代表步长,d为diarate参数
h2代表输出的特征图像高度
=====
h2=1+[h1-(k*d-1)+2padding]/s
- 注意:卷积(除不尽)向下取整,池化(除不尽)向上取整。
3. 常规卷积和深度可分离卷积的参数量
普通卷积:
3x3x3x4=108
3x3是卷积核尺寸,3是输入图片通道数目,4是输出卷积核的个数。
====================
深度可分离卷积:
DW:3x3x3x1=27
这里卷积核个数其实只设置为1。会形成3张feature map
PW:1x1x3x4=12
1x1为卷积核的尺寸,3为上一层feature map的数量,4为最终需要的维度。其实这里我们也得到了4维的feature map。
total: 27+12=39
明显可以看到,深度可分离卷积计算量比普通卷积小很多,只有其近三分之一的计算量。
3. 池化操作基础知识
3.1 池化操作的作用/为什么要进行池化操作?
-
池化层大大降低了网络模型参数和计算成本,也在一定程度上降低了网络过拟合的风险。概括来说,池化层主要有以下4点作用:
1.增大网络感受野 2.抑制噪声,降低信息冗余 3.降低模型计算量,降低网络优化难度,防止网络过拟合 4.使模型对输入图像中的特征位置变化更加鲁棒
3.2 池化操作的种类
1. Max Pooling(最大池化)
- 是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。
- 对于最大池化操作,只选择每个矩形区域中的最大值进入下一层,而其他元素将不会进入下一层。所以最大池化提取特征图中响应最强烈的部分进入下一层,这种方式摒弃了网络中大量的冗余信息,使得网络更容易被优化。
- 最大池化也常常丢失了一些特征图中的细节信息,所以最大池化更多保留些图像的纹理信息。
2. Average Pooling(平均池化)
- 将输入的图像划分为若干个矩形区域,对每个子区域输出所有元素的平均值。
- 平均池化取每个矩形区域中的平均值,可以提取特征图中所有特征的信息进入下一层,而不像最大池化只保留值最大的特征,所以平均池化可以更多保留些图像的背景信息。
3.Global Average Pooling(全局平均池化)
-
作用
在卷积神经网络训练初期,卷积层通过池化层后一般要接多个全连接层进行降维,最后再Softmax分类,这种做法使得全连接层参数很多,降低了网络训练速度,且容易出现过拟合的情况。在这种背景下,M Lin等人提出使用全局平均池化Global Average Pooling来取代最后的全连接层。用很小的计算代价实现了降维,更重要的是GAP极大减少了网络参数(CNN网络中全连接层占据了很大的参数)。 -
全局平均池化是一种特殊的平均池化,只不过它不划分若干矩形区域,而是将整个特征图中所有的元素取平均输出到下一层。
-
作为全连接层的替代操作,GAP对整个网络在结构上做正则化防止过拟合,直接剔除了全连接层中黑箱的特征,直接赋予了每个channel实际的类别意义。
-
使用GAP代替全连接层,可以实现任意图像大小的输入,而GAP对整个特征图求平均值,也可以用来提取全局上下文信息,全局信息作为指导进一步增强网络性能。
论文地址: https://arxiv.org/pdf/1312.4400.pdf%20http://arxiv.org/abs/1312.4400 代码链接: https://worksheets.codalab.org/worksheets/0x7b8f6fbc6b5c49c18ac7ca94aafaa1a7
4. Mix Pooling(混合池化)
-
为了提高训练较大CNN模型的正则化性能,受Dropout的启发,Dingjun Yu等人提出了一种随机池化Mix Pooling的方法,随机池化用随机过程代替了常规的确定性池化操作,在模型训练期间随机采用了最大池化和平均池化方法,并在一定程度上有助于防止网络过拟合现象。
-
其中,是0或1的随机值,表示选择使用最大池化或平均池化,换句话说,混合池化以随机方式改变了池调节的规则,这将在一定程度上解决最大池和平均池所遇到的问题。
-
混合池化优于传统的最大池化和平均池化方法,并可以解决过拟合问题来提高分类精度。
-
此外该方法所需要的计算开销可忽略不计,而无需任何超参数进行调整,可被广泛运用于CNN。
3.3 池化操作后特征图谱大小计算公式
====
h1代表输入图像的高度,w1代表输入图像的宽度,k代表卷积核大小,s代表步长
====
h2、w2分别代表输出的特征图像高度和宽度
====
h2 = (h1-k) /s + 1
w2 = (w1-k) /s + 1






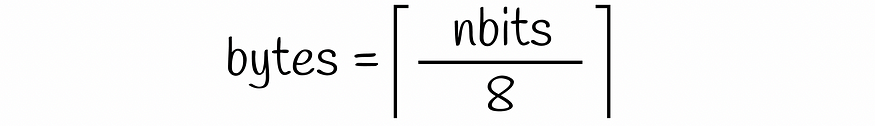


![2023年中国有创呼吸机产量、需求量及行业市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/96ed74d0f2764f882efdcacf8a0b49e9.png)