1. 索引概念
1.1 什么是索引
- 例子
当我们看一本书时,目录就相当于对照表,通过目录可以快速找到要看的内容。 - 拓展
索引就相当于书的目录。- 索引是
有序的 - 索引在计算机领域中
是一种数据结构
- 索引是
1.2 索引的作用
主要用于提高查询效率。
例子:
-
磁盘索引:
- 帮助 CPU 读数据时,提高内存和磁盘置换数据效率。
- 降低磁盘 IO
-
数据库索引:
- 提高数据查询速度。
- 降低数据库的IO
1.3 索引存放位置
一般来说索引本身也很大,不可能全部存储在内存中,因此无论磁盘索引还是数据库索引往往是存储在磁盘上的文件中的(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。
2. 能做索引的数据结构
做索引首先要查询效率高,其次磁盘 IO 要少才是最佳选择。
2.1 链表
- 链表并不适合做索引。因为查询效率太低了。
原因:- 因为索引是有顺序的,故链表检索时间复杂度是 O(n)。
思考下查询效率更高的二分查找才是更好的索引选择。故树形结构更适合做索引。
- 因为索引是有顺序的,故链表检索时间复杂度是 O(n)。
2.2 树
下文分析都是以树为数据结构阐述的。
2.2.1 树做索引前置知识
-
索引(树)保存数据的方式一般有两种:
- 数据区保存 键 对应保存数据的具体内容,这意味着随着节点增多,加载进入内存的数据量会特别大。
- 数据区保存 键 对应真正保存数据的磁盘地址,这意味着,只要加载到的不是真正的键时,内存就不会增特别大。
-
通过索引(树)查找数据的过程
- 加载根节点进入内存
- 比较节点 键值 ,若未命中继续加载下一节点
- 此处若节点保存的是真实数据,那么每次多加载一个节点,会进行一次磁盘 IO,同时会让内存增大,增大大小(较大) = 整个索引节点大小(包含 键、真实数据大小等)
- 此处若节点保存的是真实数据的地址,那么每次多加载一个节点,会进行一次磁盘 IO,同时会让内存增大,增大大小(较小) = 整个索引节点大小(不包含真实数据大小)
- 若命中,则将对应数据加载给操作系统
2.2.1 二叉树
- 二叉树查找时间复杂度O(log2(n))。
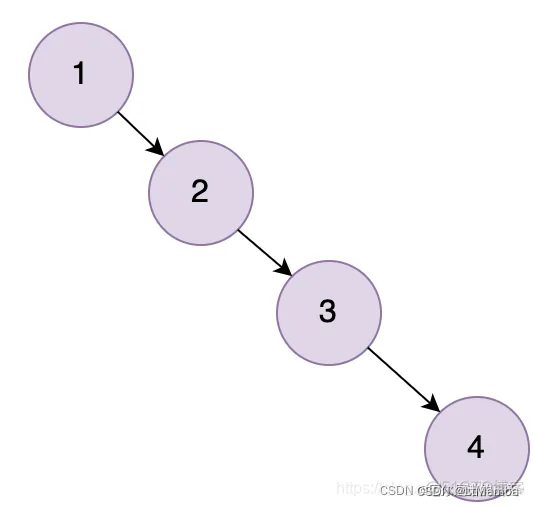
- 但是如下图二叉树可能出现 链表的结构,那么查询效率还是很低,故也不适合。
2.2.2 平衡二叉树
如红黑树等。
- 平衡二叉树很好的解决了二叉树的线性链表结构问题。
- 但仍有问题:
- 因为结构问题,当数据量很大时候,就会造成树的深度是很大。
如果查找的数据在根节点还好,如果在叶子结点,就会造成多次 IO。而 IO 是比较耗时的。 - 每个节点存储的数据内容太少,没有很好的利用操作系统和磁盘的数据交换特性。也没有利用好磁盘 IO 的预读能力。
- 扩展
操作系统和磁盘之间的一次数据交换是以页为单位的。
一页大小为4K,即一次 IO 操作系统会将 4K(整倍数)的数据加载到内存中。
但是二叉树每个节点值保存了一个关键字,一个数据区,两个子节点的引用,并不能填满 4K 的内容。辛辛苦苦的一次IO操作,只加载了一个关键字。
所以平衡二叉树也并不适合做索引。
- 扩展
- 因为结构问题,当数据量很大时候,就会造成树的深度是很大。
2.2.3 多路平衡查找树–B Tree
B Tree/B-Tree 概念参考链接
-
B Tree 和 B+ Tree 都满足查询效率高,且能减少磁盘 IO 的特性。
- 为什么查询效率高
二分查找,效率很高。 - 为什么能减少磁盘 IO
- 由前文知,加载一个节点会进行一次磁盘 IO。
- 若进行一次 IO (即加载一个节点)
- 假设一次 IO 将一个节点(16K)内容加载进内存。
- 同时假设关键字类型为 int,即 4 字节,若每个关键字对应的数据区也为 4 字节,不考虑子节点引用的情况下,则每个节点大约能够存储(16 * 1000)/ 8 = 2000 个关键字,共 2001 个路数。
- 对于 平衡二叉树,三层高度,最多可以保存 7 个关键字
- 而对于这种有 2001 路的B树,三层高度能够搜索的关键字个数远远的大于二叉树,且只进行了一次 IO (减少磁盘 IO 的点)。
- 为什么查询效率高
-
注意:
B Tree 保证树的平衡的过程中,每次关键字的变化,都会导致结构发生很大的变化,这个过程是特别浪费时间的,所以创建索引一定要创建合适的索引,而不是把所有的字段都创建索引,创建冗余索引只会在对数据进行新增,删除,修改时增加性能消耗。 -
B Tree 的应用
B树主要应用于文件系统以及部分数据库索引,如MongoDB。
2.2.4 多路平衡查找树–B+ Tree
B+ Tree 是 B Tree 的变形。
-
B+ Tree 和 B Tree 主要区别
- B+Tree是B TREE的变种,B -TREE能解决的问题,B+TREE也能够解决( 降低树的高度,增大节点存储数据量)
- B+ Tree 的关键字
全部存放在叶子节点中,非叶子节点用来做索引。故 B+TREE 磁盘读写能力更强。 - B+ Tree 的
叶子节点有一个双向链表。可以加快范围查询。故 B+Tree扫库和扫表能力更强(通过叶子节点的双链表)。- 正是这个特性决定了 B+树 更适合用来存储外部数据
- 加快范围查询例子
假如我找前100条数据,那么我找到第一条叶子节点的数据就可以从叶子节点直接向后取100个数据即可,不用再从根节点向下寻找
-
B+ Tree 的应用:
大部分关系型数据库索引是使用 B+ Tree 实现。- 数据库索引采用 B+树 的主要原因是 B树在提高了磁盘 IO 性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+ 树应运而生。B+ 树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)
4. 磁盘索引
要想深入理解磁盘索引,肯定要了解操作系统的文件系统。
4.1 了解磁盘结构及读取机制
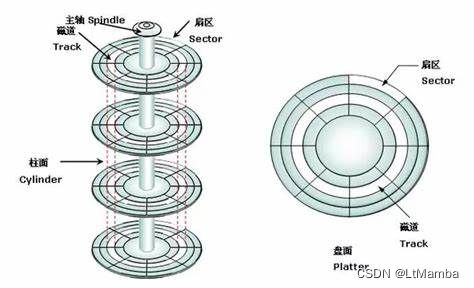
4.1.1 磁盘结构图示
-
在计算机中磁盘存储数据最小单元是
扇区,一个扇区的大小是512字节,很明显,如果每次读写都以这么小为单位,那这读写的效率会非常低。磁盘一次读多少通过操作系统实现。 -
磁盘读取数据步骤(此处简述,可能不完全准确,详细自行查找资料):
- 当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。
- 接着需要寻道,
- 寻道后,需要旋转到指定扇区
- 最后读出数据。
4.1.2 磁盘块
- 磁盘块是一个虚拟概念,相较于文件系统而衍生出的概念。
- 也就是说 磁盘块 是 文件系统操作磁盘的最小单位。
- 一般磁盘块的大小是扇区的整数倍,目的是加快磁盘 IO 效率。
4.1.3 详解–内存页 和 块啥关系
- 页
是 操作系统(即 CPU)和内存交互的一个虚拟单位。
操作系统 和 内存使用的是 页的相关映射。
内存页–参考链接 - 块
块是 磁盘 和 内存交互的一个虚拟单位。
也就是内存读取磁盘上数据时才用到磁盘索引。
4.2 了解文件系统
参考链接
4.2.1 什么是文件系统
文件系统是操作系统中负责管理持久数据的子系统,说简单点,就是负责把用户的文件存到磁盘硬件中,因为即使计算机断电了,磁盘里的数据并不会丢失,所以可以持久化的保存文件。
4.2.2 文件系统类型
文件系统的基本数据单位是文件,它的目的是对磁盘上的文件进行组织管理,那组织的方式不同,就会形成不同的文件系统。
4.2.3 文件系统示例–Linux 文件系统
Linux 最经典的一句话是:「一切皆文件」,不仅普通的文件和目录,就连块设备、管道、socket 等,也都是统一交给文件系统管理的。
-
Linux 文件系统会为每个文件分配两个数据结构:
-
索引节点(index node)
用来记录文件的元信息。- 元信息包括 比如 inode 编号、文件大小、访问权限、创建时间、修改时间、数据在磁盘的位置等等。
- 索引节点是文件的唯一标识,它们之间一一对应,也同样都会被存储在硬盘中,所以索引节点同样占用磁盘空间。
- 为了加速文件的访问,通常会把索引节点加载到内存中。
-
目录项(directory entry)
用来记录文件的名字、索引节点指针以及与其他目录项的层级关联关系。
多个目录项关联起来,就会形成目录结构,但它与索引节点不同的是,目录项是由内核维护的一个数据结构,不存放于磁盘,而是缓存在内存。- 目录项包含两种,一种是文件 一种是目录。
-
拓展
- 目录项和索引节点的关系是多对一,也就是说,一个文件可以有多个别字。比如,硬链接的实现就是多个目录项中的索引节点指向同一个文件。
- 目录也是文件,也是用索引节点唯一标识,和普通文件不同的是,普通文件在磁盘里面保存的是文件数据,而目录文件在磁盘里面保存子目录或文件。
- 目录项和目录不是一个东西
- 区别
目录是个文件,持久化存储在磁盘,
而目录项是内核一个数据结构,缓存在内存。 - 目录作用
如果查询目录频繁从磁盘读,效率会很低,所以内核会把已经读过的目录用目录项这个数据结构缓存在内存,下次再次读到相同的目录时,只需从内存读就可以,大大提高了文件系统的效率。
- 区别
-
-
文件系统和磁盘联系
-
磁盘扇区和文件系统块的关系
-
磁盘最小存储单位是 扇区
-
文件系统最小单位是 逻辑块(在linux系统中称为块,在windows系统中称为簇)
- 通俗的来讲,在Windows下如NTFS等文件系统中叫做簇;在Linux下如Ext4等文件系统中叫做块(block)。
- 块的大小一般在硬盘格式化时被指定。如果块的大小设置为4K,那么磁盘要读取8个扇区之后,才将数据块传给操作系统。 这将大大提高了磁盘的读写的效率。
-
文件系统把多个扇区组成了一个逻辑块,每次读写的最小单位就是逻辑块(数据块)
-
-
了解磁盘分区
一个磁盘可以分很多区,如 A盘、B盘…等等。 -
磁盘分区的格式化
-
作用
这个过程就是给磁盘分区写入文件系统结构。经过格式化,写入文件系统后,才能被操作系统识别,才能够正常的写入与读出数据,正常使用。 -
和文件系统的关系
文件系统有不同的格式,可以在同一块物理硬盘的不同分区,分别选择不同的文件系统。 -
磁盘分区格式化过程
磁盘进行格式化的时候,会被分成三个存储区域,分别是超级块、索引节点区和数据块区。- 超级块,用来存储文件系统的详细信息,比如块个数、块大小、空闲块等等。
当文件系统挂载时进入内存; - 索引节点区,用来存储索引节点;
当文件被访问时进入内存。 - 数据块区,用来存储文件或目录数据;
- 超级块,用来存储文件系统的详细信息,比如块个数、块大小、空闲块等等。
-
-
4.3 磁盘预读
- 磁盘存取劣势
由前文知,由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘存取速度远远小于主存存取速度。 - 如何降低磁盘存取劣势–预读
- 因此为了提高磁盘存取效率,要尽量减少磁盘 I/O。
- 为了达到这个目的(减少磁盘 I/O),磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高 I/O 效率。
- 为了达到这个目的(减少磁盘 I/O),磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。
- 预读利用的依据是 计算机科学中著名的局部性原理(如下):
- 当一个数据被用到时,其附近的数据也通常会马上被使用。
- 程序运行期间所需要的数据通常比较集中。
- 因此为了提高磁盘存取效率,要尽量减少磁盘 I/O。
4.4 了解操作系统读取数据流程
- 流程
- 操作系统运行时若发现数据确实,则触发一次缺页中断。
- 缺页后系统会从磁盘中读取一个完整的页面(一般为 4 KB),并将其加载到主存中
- 硬盘的最小读写单位是块(一般为512字节),而不是页。
如果一个页面跨多个块,那么为了读取完整的页面,系统可能需要多次磁盘IO操作。- 例子
假设一页(4 KB)包含 8个块,每个块大小为 512 字节。当需要从磁盘中读取某个页面时,如果该页面正好被分布在连续的8个块中,那么只需要进行一次磁盘 IO 来读取整个页面。但是,如果该页面跨越了两个或多个块组,那么可能需要进行多次磁盘 IO 来读取完整的页面。
- 例子
- 硬盘的最小读写单位是块(一般为512字节),而不是页。
4.5 磁盘索引
磁盘索引 一般为 B Tree的应用就在 内存 和 磁盘 交互时用到。