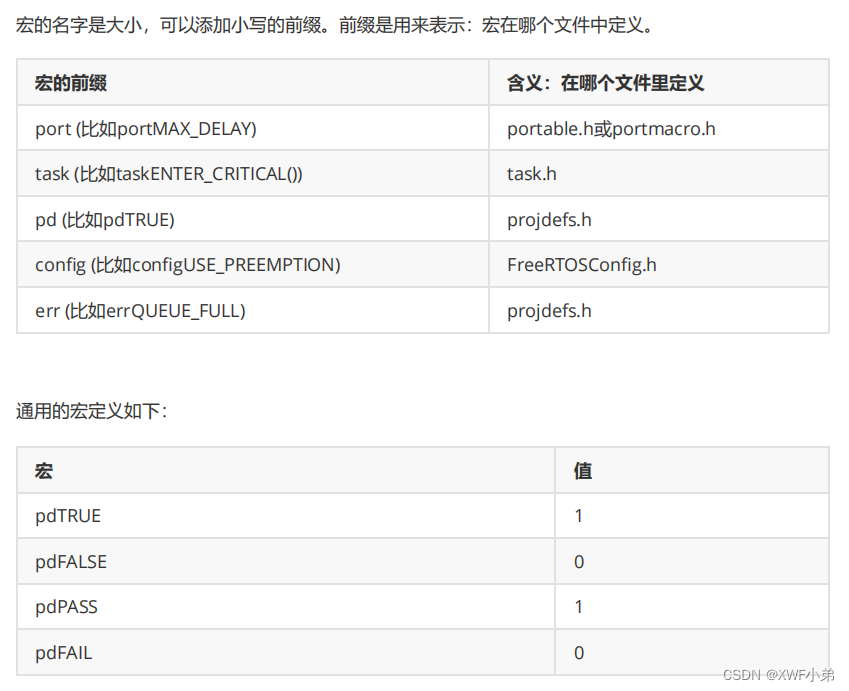
实现功能
使用pandas库来进行DataFrame的分组和提取每一组的第一条记录
实现代码
import pandas as pd
# 创建一个示例DataFrame
data = {'Group': ['A', 'A', 'B', 'B', 'C'],
'Value': [1, 2, 3, 4, 5]}
df = pd.DataFrame(data)
# 按照 'Group' 列进行分组,并提取每一组的第一条记录
first_records = df.groupby('Group').first().reset_index()
first_records = pd.DataFrame(first_records)
print(first_records)实现效果

本人读研期间发表5篇SCI数据挖掘相关论文,现在某研究院从事数据挖掘相关科研工作,对数据挖掘有一定认知和理解,会结合自身科研实践经历不定期分享关于python、机器学习、深度学习基础知识与案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
邀请三个朋友关注V订阅号:数据杂坛,即可在后台联系我获取相关数据集和源码,送有关数据分析、数据挖掘、机器学习、深度学习相关的电子书籍。
![c刷题[6]](https://img-blog.csdnimg.cn/4889de9caf954ddd8861d4d96cbe5d65.png)


![BUUCTF题解之[极客大挑战 2019]EasySQL 1](https://img-blog.csdnimg.cn/bbfd1656e402468d898d7c69b62eb4c3.png)