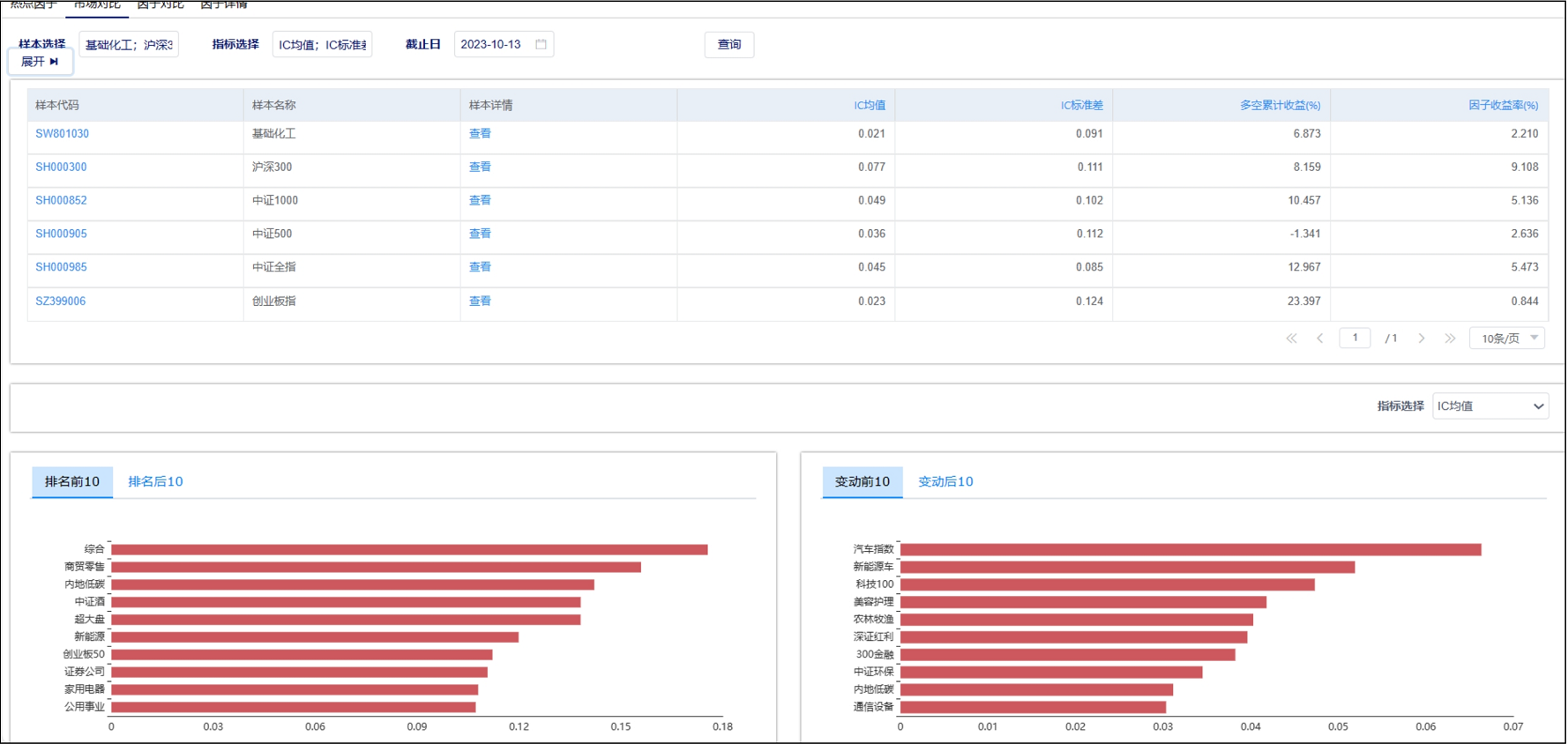
文章目录
- 概要
- 一、目标追踪概述
- 二、光流法进行目标追踪
- 小结
概要
在当今计算机视觉领域,图像处理被广泛应用于多个关键领域,包括图像分类、目标检测、语义分割、实例分割和目标追踪。其中,图像分类和目标检测作为基础应用为其他高级领域奠定了基础。在这个基础上,衍生出了更为复杂的任务,如语义分割、实例分割和目标追踪。
语义分割和实例分割是图像处理中的两项重要任务,它们致力于将图像中的每个像素点准确分类,从而实现图像前景和背景的清晰分离。与此同时,目标追踪则扩展了这一概念,专注于在图像序列或视频中跟踪目标的运动轨迹,准确定位目标在连续图像帧中的位置,为视频分析和实时监控等应用提供了重要支持。
一、目标追踪概述
在计算机视觉领域,视频是一种非常重要的数据形式,它由一系列有序的图像帧组成。这些图像帧按照一定的逻辑顺序组成视频的不同层次,包括帧(Frame)、镜头(Shot)、场景(Scene)和视频(Video)。
-
帧(Frame): 帧是视频的基本单元,实际上就是一幅图像。在视频中,每一帧呈现了一个瞬间的静态画面。其中,关键帧(Key Frame)是具有代表性的帧,通常用来代表整个视频内容。
-
镜头(Shot): 镜头由一系列相邻的帧组成,这些帧捕捉了同一个事件或者摄像机的一组连续运动。镜头可以看作是一段连续的视频片段。
-
场景(Scene): 场景由一系列相似的镜头组成,这些镜头在内容上有一定的语义关联,通常表达了同一批对象或者环境。场景划分通常依赖于图像内容的相似性和场景的转换。
-
视频(Video): 视频是所有层次的顶层结构,由一系列有序的镜头和场景组成,呈现了一个完整的动态场景或者事件。
在实际应用中,我们常常需要将视频转换为图像序列,或者将图像序列合成为视频。这种转换在很多图像处理和计算机视觉任务中是必不可少的。Python中的OpenCV库提供了便捷的接口,使得视频和图像序列之间的转换变得非常容易。
视频转图像序列:
首先,我们使用OpenCV的VideoCapture模块将视频文件读取为一系列的图像帧。每一帧都是一个独立的图像,我们可以将其保存为图像文件。这种转换能够方便地将视频数据处理为单独的图像,以便进行进一步的处理和分析。
import cv2
import os
videoFile = './video/ball.mp4' # 输入的视频文件
imgPath = "./video/frame/" # 输出的图像文件路径
cap = cv2.VideoCapture(videoFile)
frame_id = 0
while True:
ret, frame = cap.read() # 读取视频的帧
if not ret: # 视频结束
break
cv2.imwrite("%s/%04d.jpg" % (imgPath, frame_id), frame)
frame_id = frame_id + 1
print("转换结束:(视频文件:%s,图像序列路径:%s)" % (videoFile, imgPath))
图像序列转视频:
另一方面,如果我们有一系列的图像帧,我们可以使用OpenCV的VideoWriter模块将这些图像帧合成为视频。在这个过程中,我们需要设置视频的帧率、尺寸等参数,以及指定输出视频文件的格式。
import os
import cv2
imgPath = "./video/frame/" # 输入的图像文件路径
videoFile = './video/video.mp4' # 输出的视频文件
fps = 25.0 # 速率,每秒25帧
# 找到目录下所有的图像文件,并按照文件名排序
files = [f for f in os.listdir(imgPath) if os.path.isfile(os.path.join(imgPath, f)) and f.endswith('.jpg')]
files.sort()
# 获取图像文件的尺寸
img = cv2.imread(os.path.join(imgPath, files[0]))
height, width, channels = img.shape
# 创建视频对象,使用mpg4格式压缩
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # 使用mp4v编码
video = cv2.VideoWriter(videoFile, fourcc, fps, (width, height))
# 将图像序列写入视频文件
for file_name in files:
img = cv2.imread(os.path.join(imgPath, file_name))
video.write(img)
# 释放视频对象
video.release()
print("转换结束:(图像序列路径:%s, 视频文件:%s)" % (imgPath, videoFile))
- 目标追踪的分类
目标追踪根据实时性要求和应用场景可以分为不同类型:
(1)在线追踪 vs. 离线追踪
在线追踪:通过过去和现在的视频帧确定目标的位置,适用于对实时性要求较高的场景。
离线追踪:通过过去、现在和未来的视频帧确定目标的位置,准确性通常高于在线追踪,但对实时性要求较低。
(2)单目标追踪 vs. 多目标追踪 vs. 多目标多摄像头追踪 vs. 姿态追踪
单目标追踪:追踪单个固定目标在视频帧中的位置。
多目标追踪:同时追踪多个目标在视频帧中的位置。
多目标多摄像头追踪:追踪多个摄像头拍摄到的多个目标,在不同的视频帧中的位置。
姿态追踪:追踪目标在视频帧中的姿态变化,例如人体的不同姿势。
- 生成式模型 vs. 鉴别式模型
生成式模型
生成式模型首先定义目标的特征,然后在后续视频帧中寻找具有相似特征的位置,从而定位目标。早期的目标追踪方法如光流法属于生成式模型,但由于特征定义简单,面对光照变化、遮挡、分辨率低、角度变化等情况时效果不佳。
鉴别式模型
鉴别式模型通过比较视频帧中目标和背景的差异,将目标从视频帧中提取出来,实现目标定位。这类模型综合考虑了目标和背景信息,在准确性和实时性方面通常优于生成式模型。传统的机器学习模型(如SVM、随机森林、GBDT)逐渐被引入,同时基于深度学习的目标追踪方法也逐渐兴起。
4. 目标追踪的方法
目标追踪方法可以根据时间顺序分为“经典方法”、“基于滤波方法”和“基于深度学习方法”。
(1)经典方法
经典的目标追踪方法首先对目标的外观进行建模,例如特征点、轮廓、SIFT等特征,然后在视频帧中查找目标出现的位置。通常使用预测算法,对可能出现的区域进行预测,仅在这些区域内查找目标,以提高效率。
(2)基于滤波方法
这种方法通过度量视频帧中目标的相似程度,将不同视频帧中的目标进行关联,实现追踪。例如,MOSSE算法使用相关滤波器(Correlation Filter),计算目标之间的相关值,根据相关值找到不同视频帧中相同的目标并建立关联,实现目标追踪。
(3)基于深度学习方法
基于深度学习的目标追踪方法将深度学习模型引入目标追踪中。例如,基于目标检测的追踪方法(Tracking By Detecting,简称TBD)使用深度学习模型在每个视频帧上执行目标检测,并在检测到的目标之间建立关联,实现目标追踪。
二、光流法进行目标追踪
光流(Optical Flow)是一种用来描述运动物体在图像中像素级别运动的方法。当一个物体在三维空间中移动时,它在图像上的投影位置也会随之变化。光流就是描述这种投影位置变化的二维矢量。
具体地说,当我们观察两个相邻的图像帧时,每个像素点在这两帧之间会发生位移。这个位移可以被表示为一个二维向量,其中的两个分量(x 和 y)分别表示了像素在图像平面上的水平和垂直位移。这个二维向量即为光流矢量。
光流矢量的计算基于一个假设:在相邻的图像帧之间,相邻像素的灰度不会发生剧烈变化。基于这个假设,光流算法通过分析像素点在两帧之间的灰度变化,估计出每个像素点的运动矢量。这种方法可以用来追踪图像中的目标,分析视频中的运动模式,或者用于图像稠密匹配等应用。
总结而言,光流是通过比较相邻图像帧之间像素灰度的变化来估计像素点运动的方法,用二维矢量表示像素点在图像平面上的瞬时速度。

光流法的原理基于两个关键假设条件:
- 亮度不变性假设:
这个假设表明,同一个目标在不同的视频帧之间运动时,其亮度(像素值)不会发生显著的变化。换句话说,目标在相邻帧之间的灰度值保持不变。
2. 时间连续性假设:
这个假设指的是,时间的变化不会引起目标位置的剧烈变化。也就是说,相邻帧之间的目标位移是连续的,而不是突然发生的大幅度变化。
在这两个假设的基础上,光流法通过计算相邻帧之间像素点的位移,得到光流场,其中包含了目标的运动信息。这个位移信息可以用来分析和追踪目标的运动轨迹。
具体来说,对于某个像素点在时刻 tt 的坐标为 (xt,yt)(xt,yt),像素值为 ItIt,在时刻 t+1t+1 的坐标为 (xt+1,yt+1)(xt+1,yt+1),像素值为 It+1It+1。光流法计算出的位移向量 (u,v)(u,v) 表示了该像素点在水平方向(uu)和垂直方向(vv)上的位移。
光流法的目标是找到适当的位移向量 (u,v)(u,v) 使得下面的方程成立:
It(xt,yt)=It+1(xt+1,yt+1)It(xt,yt)=It+1(xt+1,yt+1)
这个方程表示了亮度不变性假设。通过求解这个方程,光流法能够估计目标在相邻帧之间的位移,从而实现目标的追踪。光流法的结果通常是一个矢量场,其中包含了图像中各个像素点的运动信息。
Lucas-Kanade(LK)光流算法是一种用于估计图像中物体运动的经典方法。在LK算法中,我们希望找到一个光流矢量 (u,v)(u,v),表示图像中每个像素点在水平和垂直方向上的位移。光流矢量的计算是基于以下假设的:
- 亮度不变性假设:
这个假设表明,在相邻的图像帧之间,同一个像素点的灰度值保持不变。也就是说,如果在第一帧图像中某个像素的灰度值为 I(x,y)I(x,y),在下一帧图像中相同位置的像素的灰度值仍然是 I(x+u,y+v)I(x+u,y+v)。其中 (u,v)(u,v) 是我们要估计的光流矢量。
2. 时间连续性假设:
这个假设指的是,在一个短时间内,目标的运动是连续的,相邻帧之间的位移是平滑的。即,目标在相邻帧之间的位移是有限的,不会突然发生剧烈变化。
3. 空间一致性假设:
LK算法引入了“空间一致性”假设,这意味着在目标像素周围的一个小窗口内,所有像素点都有相同的光流矢量。该窗口的大小通常选择为3x3,这样就有9个像素点。
对于这9个像素点,可以建立如下的9个方程:
Ix⋅ui+Iy⋅vi=−ItIx⋅ui+Iy⋅vi=−It
其中 IxIx 和 IyIy 分别表示在 xx 和 yy 方向上的梯度,uiui 和 vivi 表示第 ii 个像素点的光流矢量分量,ItIt 是两帧图像之间的灰度差。
LK算法的目标是通过最小二乘法,找到一个最优的光流矢量 (u,v)(u,v),使得上述9个方程的误差最小化。通过解这个最小二乘问题,可以得到光流矢量 (u,v)(u,v),从而实现目标的运动估计。这种方法对于小的位移和较好的纹理区域通常具有良好的效果。
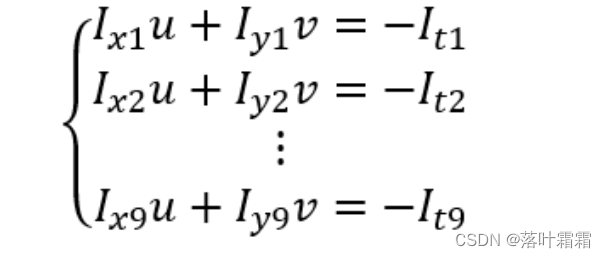
这段代码演示了如何使用OpenCV中的calcOpticalFlowPyrLK()函数实现稀疏光流的计算,以及如何将两帧图像的特征点进行关联,从而显示图像中的运动信息。
步骤解释:
- 导入库:
import cv2
import numpy as np
from matplotlib import pyplot as plt
- 读取图像并转换为灰度图:
img_0 = cv2.imread("./images/da_feng_che_0.jpg")
img_1 = cv2.imread("./images/da_feng_che_1.jpg")
img_0 = cv2.cvtColor(img_0, cv2.COLOR_BGR2RGB)
img_1 = cv2.cvtColor(img_1, cv2.COLOR_BGR2RGB)
gray_0 = cv2.cvtColor(img_0.copy(), cv2.COLOR_RGB2GRAY)
gray_1 = cv2.cvtColor(img_1.copy(), cv2.COLOR_RGB2GRAY)
mask = img_0 + img_1 # mask用来显示最后的结果
- 生成特征点:
params = {"maxCorners": 10, "qualityLevel": 0.01, "minDistance": 50, "blockSize": 1}
key_points_0 = cv2.goodFeaturesToTrack(gray_0, mask=None, **params)
- 计算稀疏光流并关联特征点:
key_points_1, match, _ = cv2.calcOpticalFlowPyrLK(gray_0, gray_1, key_points_0, None)
matched_0 = key_points_0[match == 1] # 第一帧图像上的特征点
matched_1 = key_points_1[match == 1] # 第二帧图像上的特征点
- 显示运动信息:
for i, (frame_0, frame_1) in enumerate(zip(matched_0, matched_1)):
a, b = frame_0.ravel()
c, d = frame_1.ravel()
mask = cv2.circle(mask, (a, b), 3, (255, 0, 0), -1) # 用红色标记,第一帧图上的特征点
mask = cv2.circle(mask, (c, d), 3, (0, 0, 255), -1) # 用蓝色标记,第二帧图上的特征点
mask = cv2.line(mask, (a, b), (c, d), (255, 255, 255), 2) # 用白色标记,两帧图像上特征点的对应关系
f, ax = plt.subplots(1, 3, figsize=(12, 12))
ax[0].imshow(img_0)
ax[1].imshow(img_1)
ax[2].imshow(mask)
在这段代码中,我们首先导入所需的库。然后,我们读取两帧图像,并将它们转换为灰度图像。接着,使用cv2.goodFeaturesToTrack()函数生成第一帧图像的特征点。随后,我们使用cv2.calcOpticalFlowPyrLK()函数计算稀疏光流,并将第一帧和第二帧图像的特征点进行关联。最后,我们将特征点和它们的对应关系可视化在两帧图像上,用红色和蓝色标记特征点,并用白色线条连接两帧图像上对应的特征点。
小结
步骤展示了如何使用OpenCV实现稀疏光流的计算,并可视化特征点的运动信息。这种方法通常适用于追踪图像中的关键特征点,例如角点,以分析物体的运动轨迹。