1.数据库读写分离了解吗?
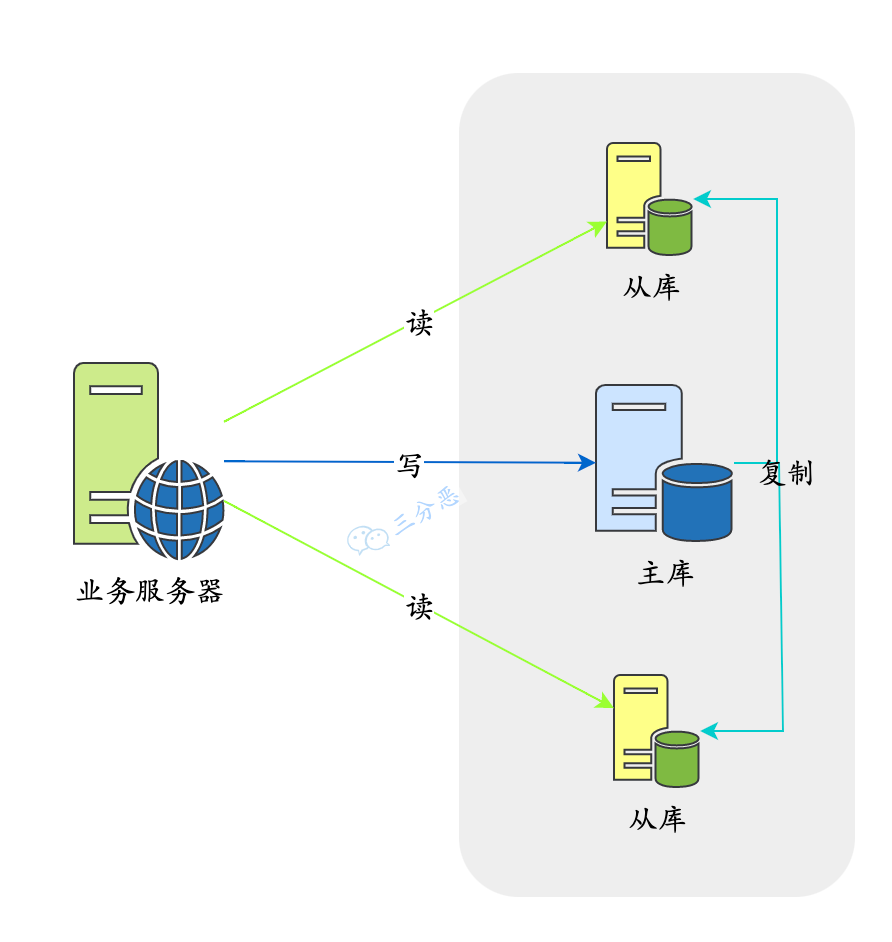
读写分离的基本原理是将数据库读写操作分散到不同的节点上,下面是基本架构图:
读写分离
读写分离的基本实现是:
-
数据库服务器搭建主从集群,一主一从、一主多从都可以。
-
数据库主机负责读写操作,从机只负责读操作。
-
数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据。
-
业务服务器将写操作发给数据库主机,将读操作发给数据库从机。
2.那读写分离的分配怎么实现呢?
将读写操作区分开来,然后访问不同的数据库服务器,一般有两种方式:程序代码封装和中间件封装。
-
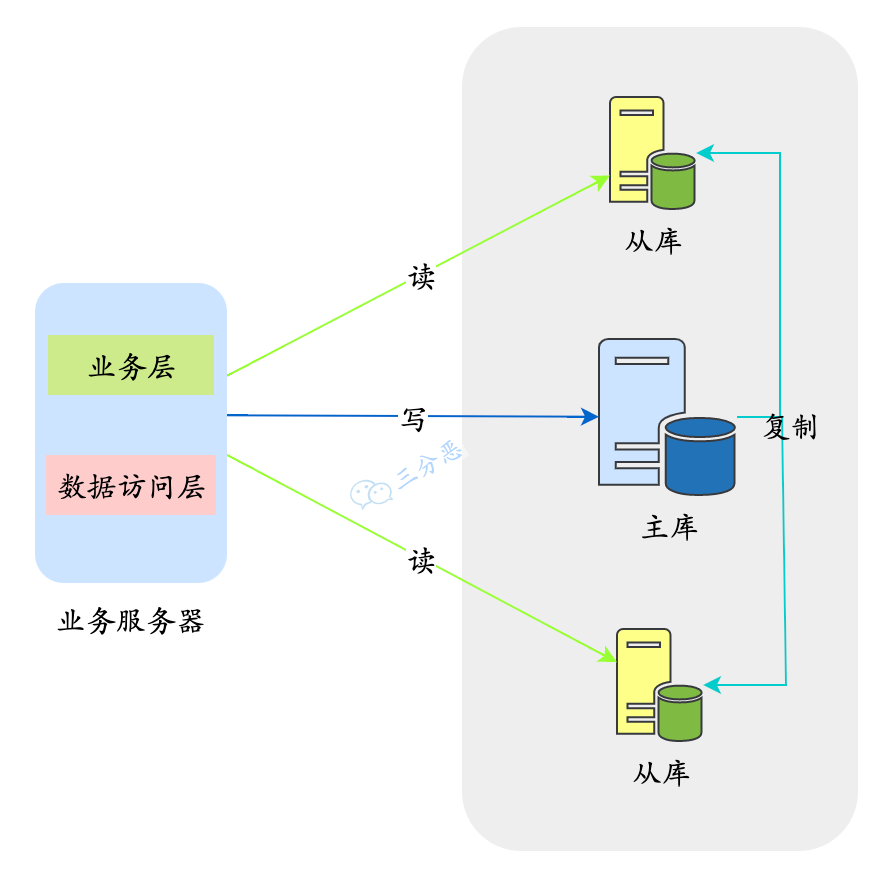
程序代码封装
程序代码封装指在代码中抽象一个数据访问层(所以有的文章也称这种方式为 "中间层封装" ) ,实现读写操作分离和数据库服务器连接的管理。例如,基于 Hibernate 进行简单封装,就可以实现读写分离:
业务代码封装
目前开源的实现方案中,淘宝的 TDDL (Taobao Distributed Data Layer, 外号:头都大了)是比较有名的。
-
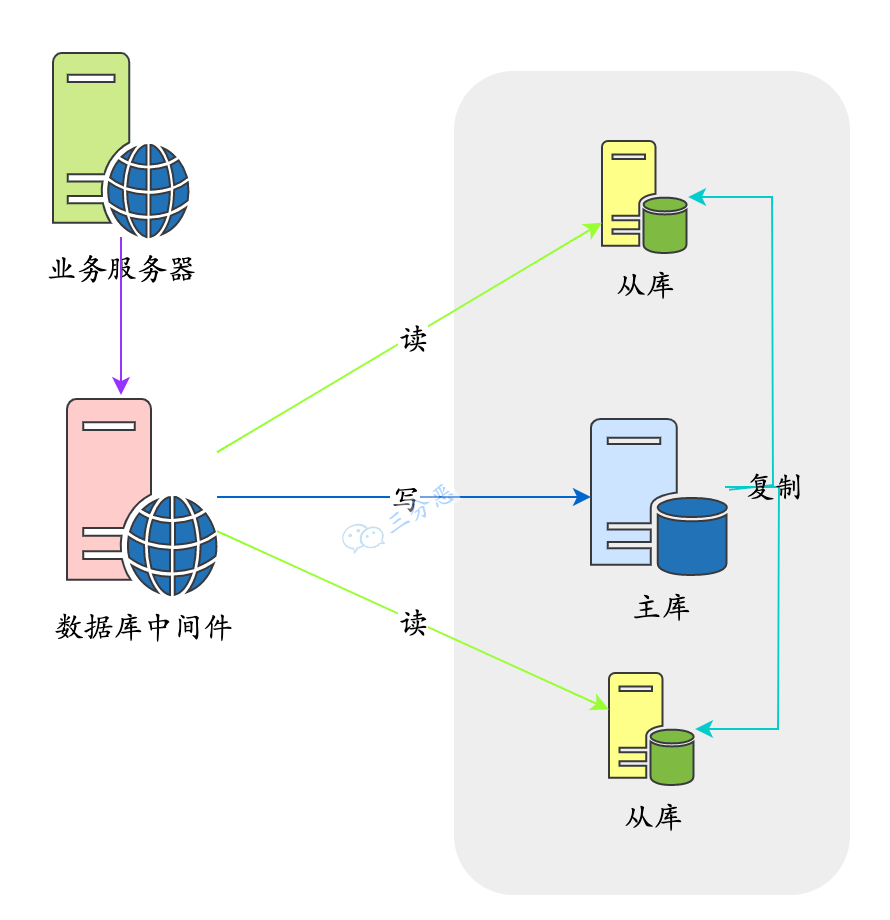
中间件封装
中间件封装指的是独立一套系统出来,实现读写操作分离和数据库服务器连接的管理。中间件对业务服务器提供 SQL 兼容的协议,业务服务器无须自己进行读写分离。
对于业务服务器来说,访问中间件和访问数据库没有区别,事实上在业务服务器看来,中间件就是一个数据库服务器。
其基本架构是:
数据库中间件
3.主从复制原理了解吗?
-
master数据写入,更新binlog
-
master创建一个dump线程向slave推送binlog
-
slave连接到master的时候,会创建一个IO线程接收binlog,并记录到relay log中继日志中
-
slave再开启一个sql线程读取relay log事件并在slave执行,完成同步
-
slave记录自己的binglog
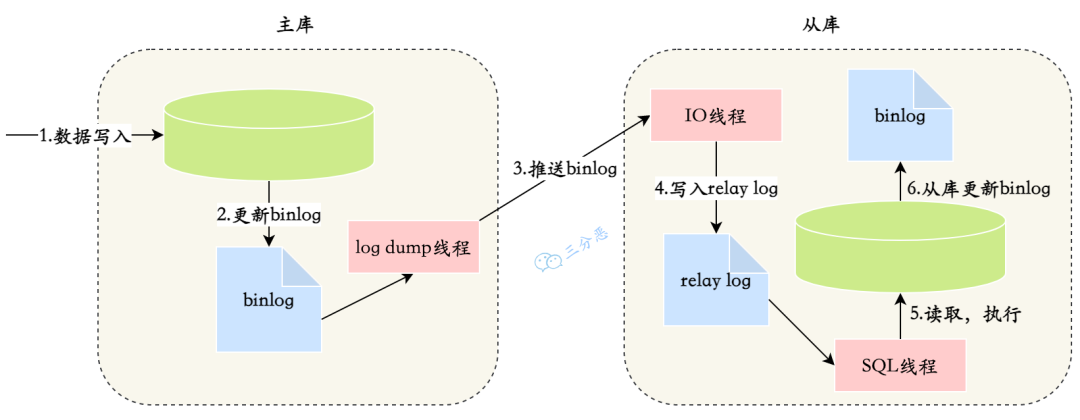
主从复制
4.主从同步延迟怎么处理?
主从同步延迟的原因
一个服务器开放N个链接给客户端来连接的,这样有会有大并发的更新操作, 但是从服务器的里面读取 binlog 的线程仅有一个,当某个 SQL 在从服务器上执行的时间稍长 或者由于某个 SQL 要进行锁表就会导致,主服务器的 SQL 大量积压,未被同步到从服务器里。这就导致了主从不一致, 也就是主从延迟。
主从同步延迟的解决办法
解决主从复制延迟有几种常见的方法:
-
写操作后的读操作指定发给数据库主服务器
例如,注册账号完成后,登录时读取账号的读操作也发给数据库主服务器。这种方式和业务强绑定,对业务的侵入和影响较大,如果哪个新来的程序员不知道这样写代码,就会导致一个bug。
-
读从机失败后再读一次主机
这就是通常所说的 "二次读取" ,二次读取和业务无绑定,只需要对底层数据库访问的 API 进行封装即可,实现代价较小,不足之处在于如果有很多二次读取,将大大增加主机的读操作压力。例如,黑客暴力破解账号,会导致大量的二次读取操作,主机可能顶不住读操作的压力从而崩溃。
-
关键业务读写操作全部指向主机,非关键业务采用读写分离
例如,对于一个用户管理系统来说,注册 + 登录的业务读写操作全部访问主机,用户的介绍、爰好、等级等业务,可以采用读写分离,因为即使用户改了自己的自我介绍,在查询时却看到了自我介绍还是旧的,业务影响与不能登录相比就小很多,还可以忍受。
5.你们一般是怎么分库的呢?
-
垂直分库:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
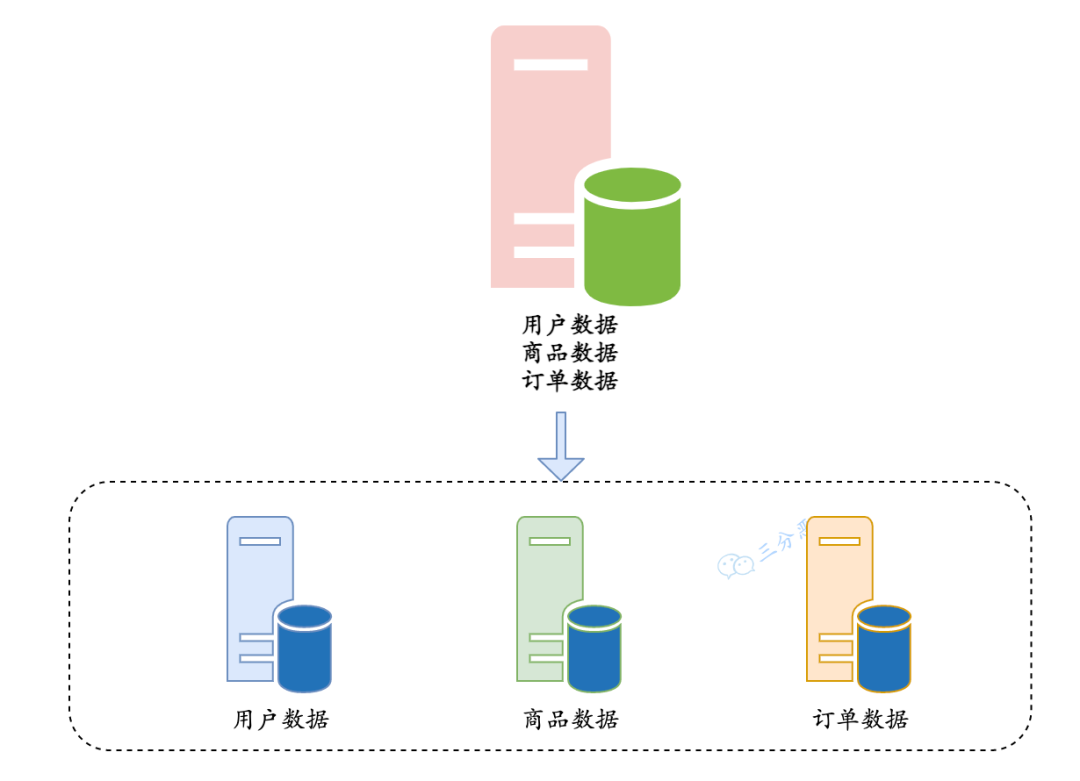
垂直分库
-
水平分库:以字段为依据,按照一定策略(hash、range 等),将一个库中的数据拆分到多个库中。
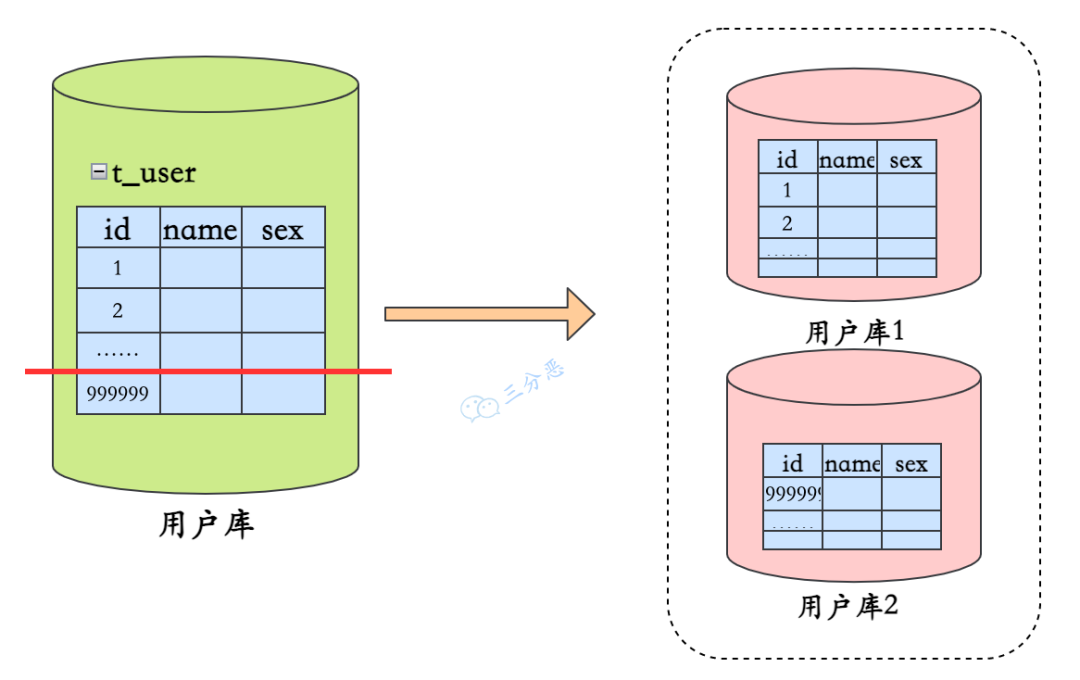
水平分库
6.那你们是怎么分表的?
-
水平分表:以字段为依据,按照一定策略(hash、range 等),将一个表中的数据拆分到多个表中。
-
垂直分表:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
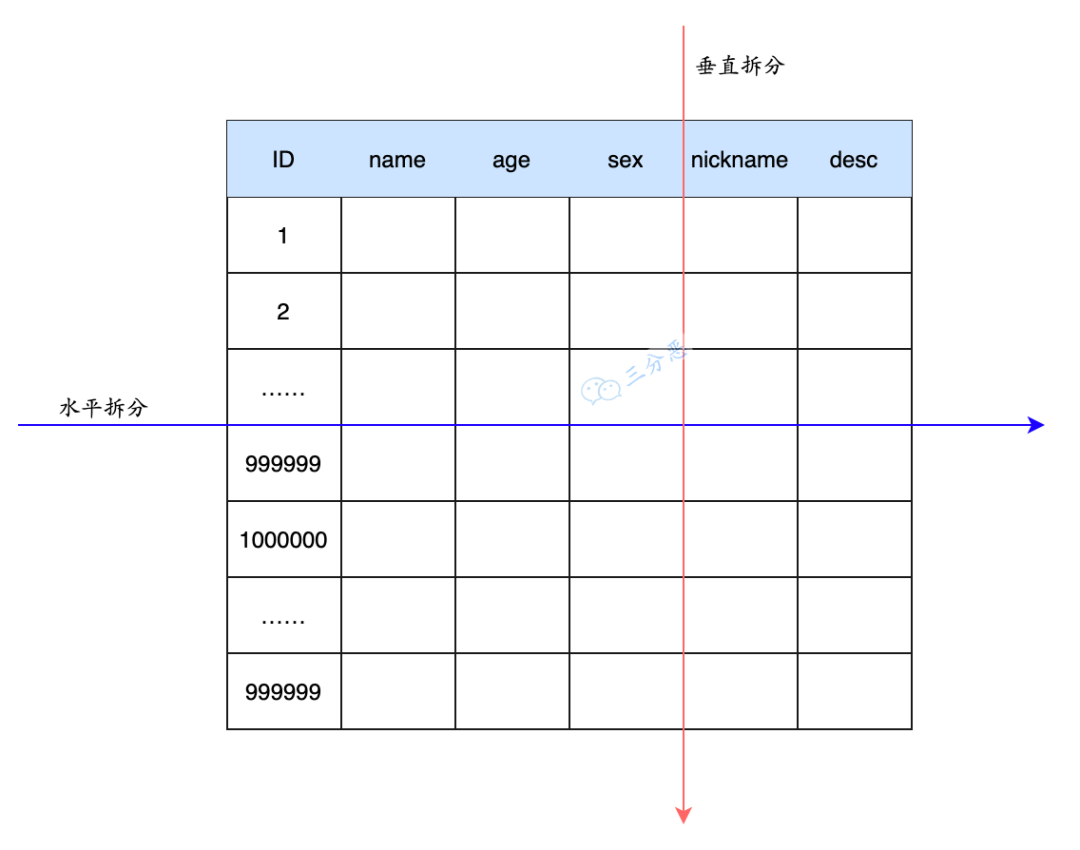
表拆分
7.水平分表有哪几种路由方式?
什么是路由呢?就是数据应该分到哪一张表。
水平分表主要有三种路由方式:
-
范围路由:选取有序的数据列 (例如,整形、时间戳等) 作为路由的条件,不同分段分散到不同的数据库表中。
我们可以观察一些支付系统,发现只能查一年范围内的支付记录,这个可能就是支付公司按照时间进行了分表。
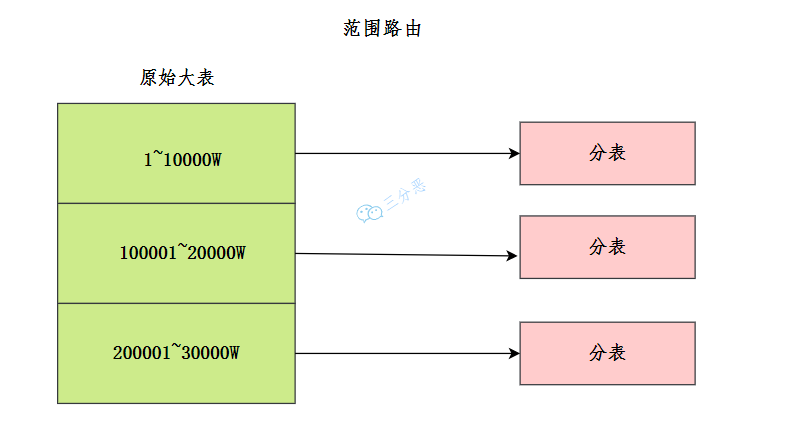
范围路由
范围路由设计的复杂点主要体现在分段大小的选取上,分段太小会导致切分后子表数量过多,增加维护复杂度;分段太大可能会导致单表依然存在性能问题,一般建议分段大小在 100 万至2000 万之间,具体需要根据业务选取合适的分段大小。
范围路由的优点是可以随着数据的增加平滑地扩充新的表。例如,现在的用户是 100 万,如果增加到 1000 万,只需要增加新的表就可以了,原有的数据不需要动。范围路由的一个比较隐含的缺点是分布不均匀,假如按照 1000 万来进行分表,有可能某个分段实际存储的数据量只有 1000 条,而另外一个分段实际存储的数据量有 900 万条。
-
Hash 路由:选取某个列 (或者某几个列组合也可以) 的值进行 Hash 运算,然后根据 Hash 结果分散到不同的数据库表中。
同样以订单 id 为例,假如我们一开始就规划了 4个数据库表,路由算法可以简单地用 id % 4 的值来表示数据所属的数据库表编号,id 为 12的订单放到编号为 50的子表中,id为 13的订单放到编号为 61的字表中。
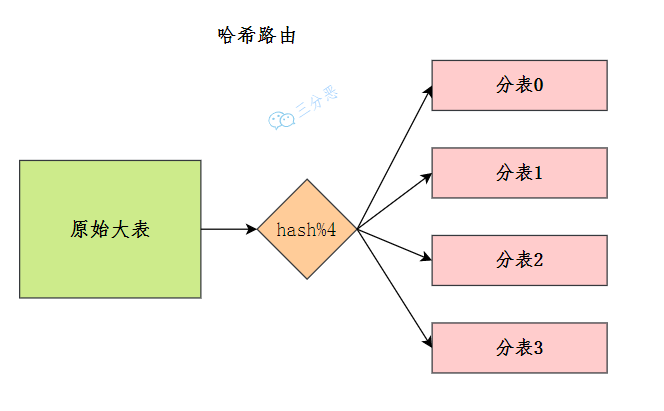
Hash路由
Hash 路由设计的复杂点主要体现在初始表数量的选取上,表数量太多维护比较麻烦,表数量太少又可能导致单表性能存在问题。而用了 Hash 路由后,增加子表数量是非常麻烦的,所有数据都要重分布。Hash 路由的优缺点和范围路由基本相反,Hash 路由的优点是表分布比较均匀,缺点是扩充新的表很麻烦,所有数据都要重分布。
-
配置路由:配置路由就是路由表,用一张独立的表来记录路由信息。同样以订单id 为例,我们新增一张 order_router 表,这个表包含 orderjd 和 tablejd 两列 , 根据 orderjd 就可以查询对应的 table_id。
配置路由设计简单,使用起来非常灵活,尤其是在扩充表的时候,只需要迁移指定的数据,然后修改路由表就可以了。
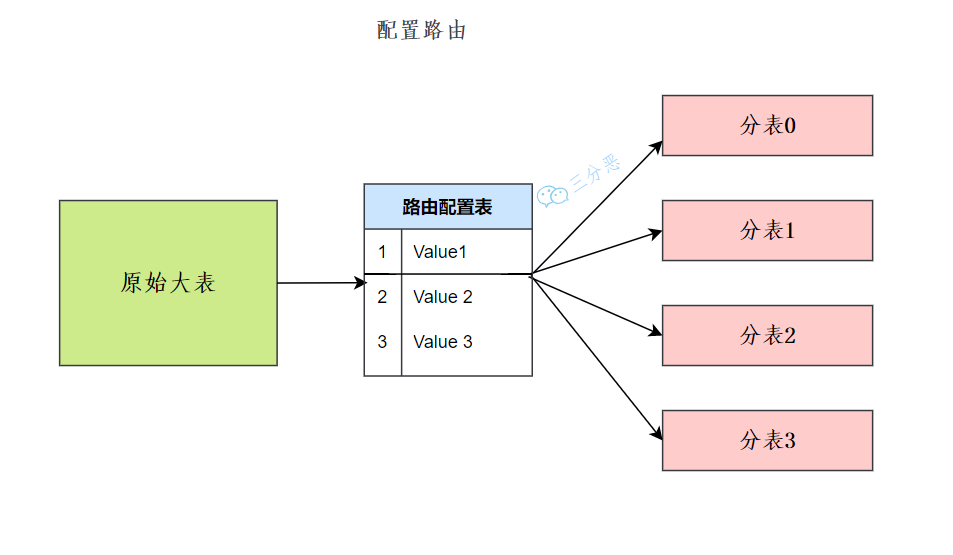
配置路由
配置路由的缺点就是必须多查询一次,会影响整体性能;而且路由表本身如果太大(例如,几亿条数据) ,性能同样可能成为瓶颈,如果我们再次将路由表分库分表,则又面临一个死循环式的路由算法选择问题。
8.不停机扩容怎么实现?
实际上,不停机扩容,实操起来是个非常麻烦而且很有风险的操作,当然,面试回答起来就简单很多。
-
第一阶段:在线双写,查询走老库
-
建立好新的库表结构,数据写入久库的同时,也写入拆分的新库
-
数据迁移,使用数据迁移程序,将旧库中的历史数据迁移到新库
-
使用定时任务,新旧库的数据对比,把差异补齐
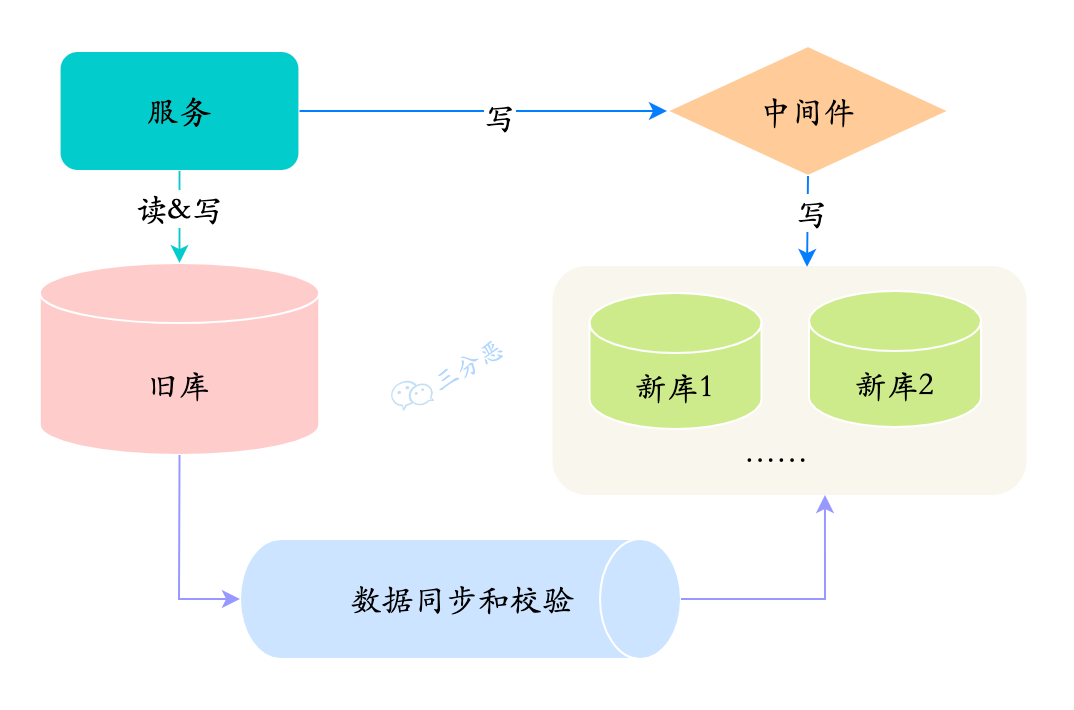
第一阶段
-
-
第二阶段:在线双写,查询走新库
-
完成了历史数据的同步和校验
-
把对数据的读切换到新库
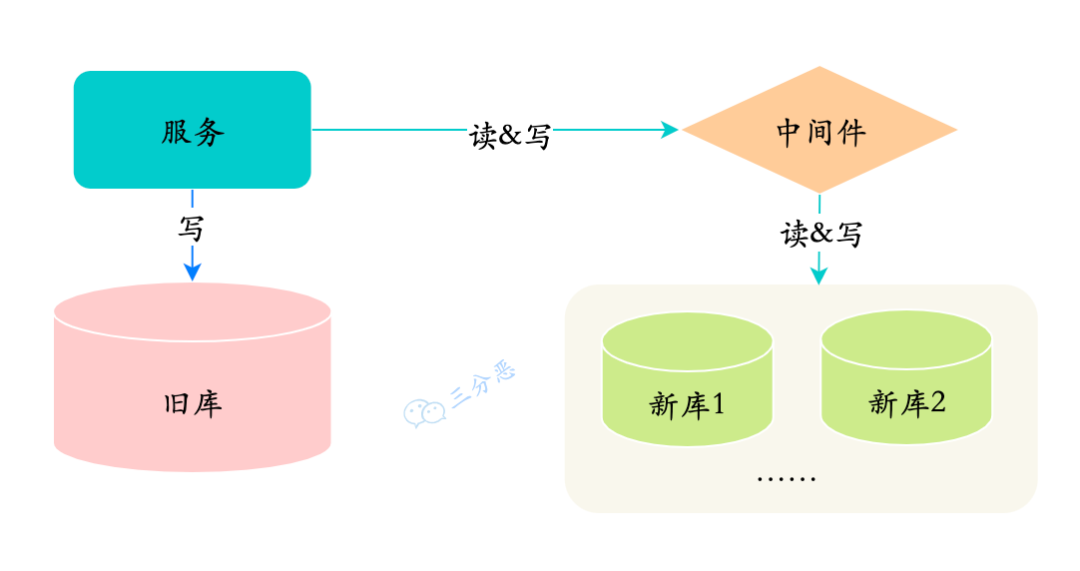
第二阶段
-
-
第三阶段:旧库下线
-
旧库不再写入新的数据
-
经过一段时间,确定旧库没有请求之后,就可以下线老库
-
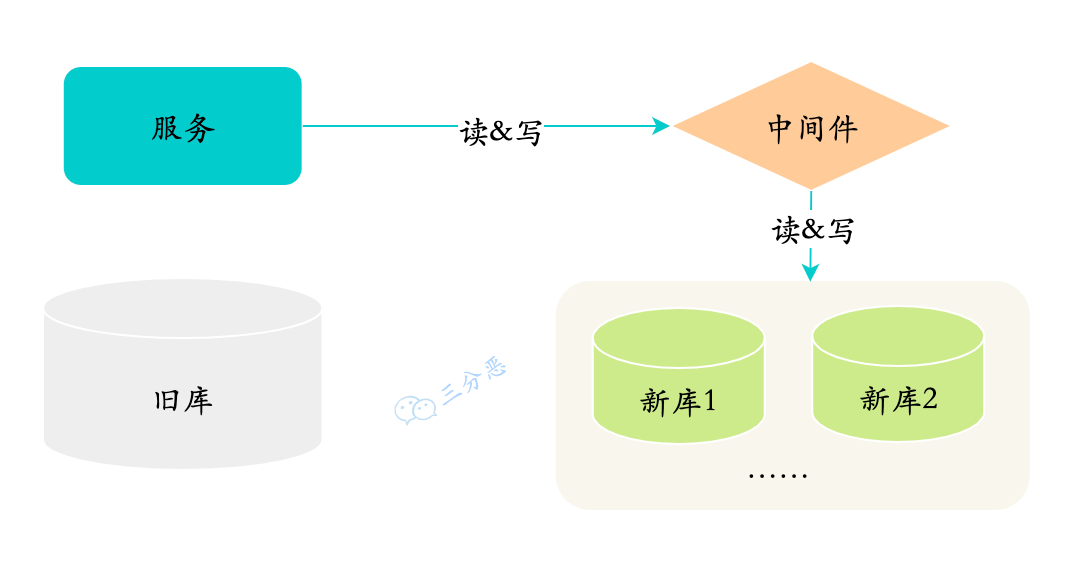
第三阶段
9.常用的分库分表中间件有哪些?
-
sharding-jdbc
-
Mycat
10.那你觉得分库分表会带来什么问题呢?
从分库的角度来讲:
-
事务的问题
使用关系型数据库,有很大一点在于它保证事务完整性。
而分库之后单机事务就用不上了,必须使用分布式事务来解决。
-
跨库 JOIN 问题
在一个库中的时候我们还可以利用 JOIN 来连表查询,而跨库了之后就无法使用 JOIN 了。
此时的解决方案就是在业务代码中进行关联,也就是先把一个表的数据查出来,然后通过得到的结果再去查另一张表,然后利用代码来关联得到最终的结果。
这种方式实现起来稍微比较复杂,不过也是可以接受的。
还有可以适当的冗余一些字段。比如以前的表就存储一个关联 ID,但是业务时常要求返回对应的 Name 或者其他字段。这时候就可以把这些字段冗余到当前表中,来去除需要关联的操作。
还有一种方式就是数据异构,通过binlog同步等方式,把需要跨库join的数据异构到ES等存储结构中,通过ES进行查询。
从分表的角度来看:
-
跨节点的 count,order by,group by 以及聚合函数问题
只能由业务代码来实现或者用中间件将各表中的数据汇总、排序、分页然后返回。
-
数据迁移,容量规划,扩容等问题
数据的迁移,容量如何规划,未来是否可能再次需要扩容,等等,都是需要考虑的问题。
-
ID 问题
数据库表被切分后,不能再依赖数据库自身的主键生成机制,所以需要一些手段来保证全局主键唯一。
-
还是自增,只不过自增步长设置一下。比如现在有三张表,步长设置为3,三张表 ID 初始值分别是1、2、3。这样第一张表的 ID 增长是 1、4、7。第二张表是2、5、8。第三张表是3、6、9,这样就不会重复了。
-
UUID,这种最简单,但是不连续的主键插入会导致严重的页分裂,性能比较差。
-
分布式 ID,比较出名的就是 Twitter 开源的 sonwflake 雪花算法
11.百万级别以上的数据如何删除?
关于索引:由于索引需要额外的维护成本,因为索引文件是单独存在的文件,所以当我们对数据的增加,修改,删除,都会产生额外的对索引文件的操作,这些操作需要消耗额外的IO,会降低增/改/删的执行效率。
所以,在我们删除数据库百万级别数据的时候,查询MySQL官方手册得知删除数据的速度和创建的索引数量是成正比的。
-
所以我们想要删除百万数据的时候可以先删除索引
-
然后删除其中无用数据
-
删除完成后重新创建索引创建索引也非常快
12.百万千万级大表如何添加字段?
当线上的数据库数据量到达几百万、上千万的时候,加一个字段就没那么简单,因为可能会长时间锁表。
大表添加字段,通常有这些做法:
-
通过中间表转换过去
创建一个临时的新表,把旧表的结构完全复制过去,添加字段,再把旧表数据复制过去,删除旧表,新表命名为旧表的名称,这种方式可能回丢掉一些数据。
-
用pt-online-schema-change
pt-online-schema-change是percona公司开发的一个工具,它可以在线修改表结构,它的原理也是通过中间表。 -
先在从库添加 再进行主从切换
如果一张表数据量大且是热表(读写特别频繁),则可以考虑先在从库添加,再进行主从切换,切换后再将其他几个节点上添加字段。
13.MySQL 数据库 cpu 飙升的话,要怎么处理呢?
排查过程:
(1)使用 top 命令观察,确定是 mysqld 导致还是其他原因。
(2)如果是 mysqld 导致的,show processlist,查看 session 情况,确定是不是有消耗资源的 sql 在运行。
(3)找出消耗高的 sql,看看执行计划是否准确, 索引是否缺失,数据量是否太大。
处理:
(1)kill 掉这些线程 (同时观察 cpu 使用率是否下降),
(2)进行相应的调整 (比如说加索引、改 sql、改内存参数)
(3)重新跑这些 SQL。
其他情况:
也有可能是每个 sql 消耗资源并不多,但是突然之间,有大量的 session 连进来导致 cpu 飙升,这种情况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等










![[ Linux ] 死锁以及如何避免死锁](https://img-blog.csdnimg.cn/img_convert/8733faf1ff66283a5c5db0ee6097fc95.png)