1、将emp.csv、dept.csv文件上传到分布式环境,再用
hdfs dfs -put dept.csv /input/
hdfs dfs -put emp.csv /input/
将本地文件put到hdfs文件系统的input目录下
2、或者调用本地文件也可以。区别:sc.textFile("file:///D:\\temp\\emp.csv")
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import spark.implicits._
case classEmp(empno:Int,ename:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptno:Int)
val lines =sc.textFile("hdfs://Master:9000/input/emp.csv").map(_.split(","))
val allEmp = lines.map(x=>Emp(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt))
val allEmpDF = allEmp.toDF
allEmpDF.show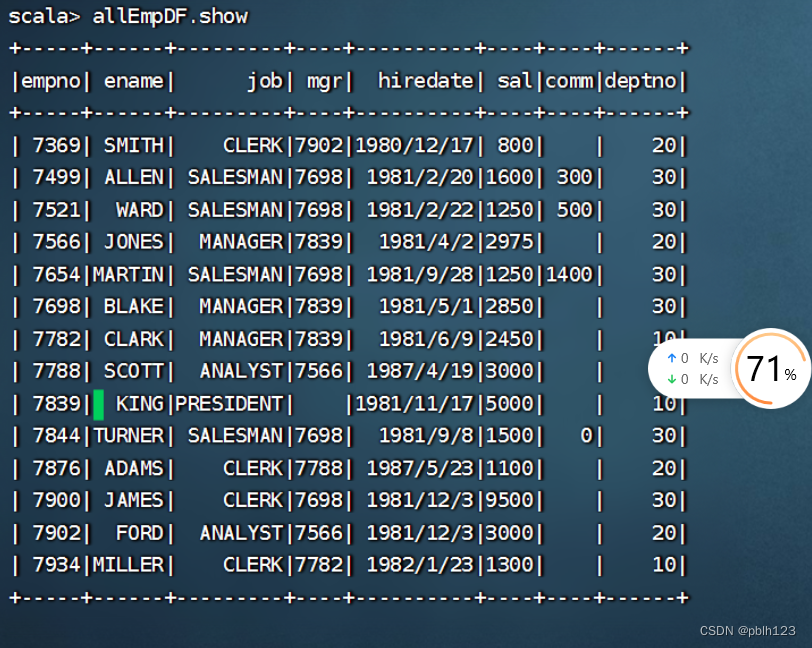
-
StructType 是个case class,一般用于构建schema.
-
因为是case class,所以使用的时候可以不用new关键字
构造函数
-
可以传入Seq,List,Array,都是可以的~
-
还可以用无参的构造器,因为它有一个无参的构造器.
例子
private val schema: StructType = StructType(List(
StructField("name", DataTypes.StringType),
StructField("age", DataTypes.IntegerType)
))也可以是
private val schema: StructType = StructType(Array(
StructField("name", DataTypes.StringType),
StructField("age", DataTypes.IntegerType)
))-
还可以调用无参构造器,这么写
private val schema = (new StructType)
.add(StructField("name", DataTypes.StringType))
.add(StructField("age", DataTypes.IntegerType))-
这个无参的构造器,调用了一个有参构造器.this里面是个方法,这个方法的返回值是Array类型,实际上就是无参构造器调用了主构造器
def this() = this(Array.empty[StructField])
case class StructType(fields: Array[StructField]) extends DataType with Seq[StructField] {}
import org.apache.spark.sql.types._
val myschema =StructType(List(
StructField("empno",DataTypes.IntegerType),
StructField("ename",DataTypes.StringType),
StructField("job",DataTypes.StringType),
StructField("mgr",DataTypes.StringType),
StructField("hiredate",DataTypes.StringType),
StructField("sal",DataTypes.IntegerType),
StructField("comm",DataTypes.StringType),
StructField("deptno",DataTypes.IntegerType)
))
val empcsvRDD = sc.textFile("hdfs://Master:9000/input/emp.csv").map(_.split(","))
import org.apache.spark.sql.Row
val rowRDD=empcsvRDD.map(line => Row (line(0).toInt,line(1),line(2),line(3),line(4),line(5).toInt,line(6),line(7).toInt))
val df = spark.createDataFrame(rowRDD,myschema)
将people.json文件上传到分布式环境
hdfs dfs -put people.json /input
hdfs dfs -put emp.json /input//读json文件
val df = spark.read.json("hdfs://Master:9000/input/emp.json")
df.show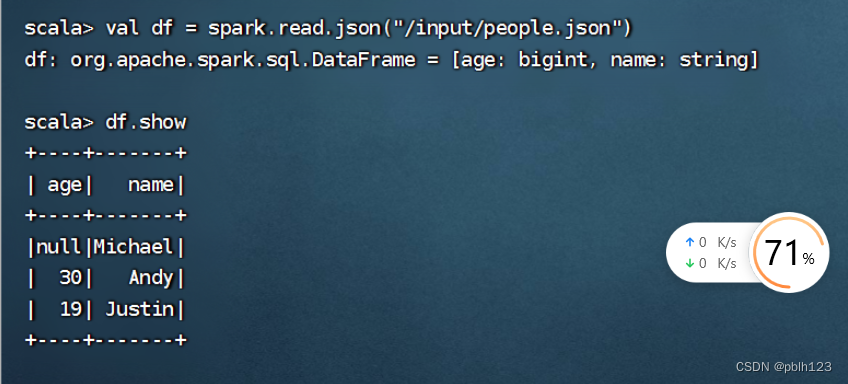
df.select ("ename").show
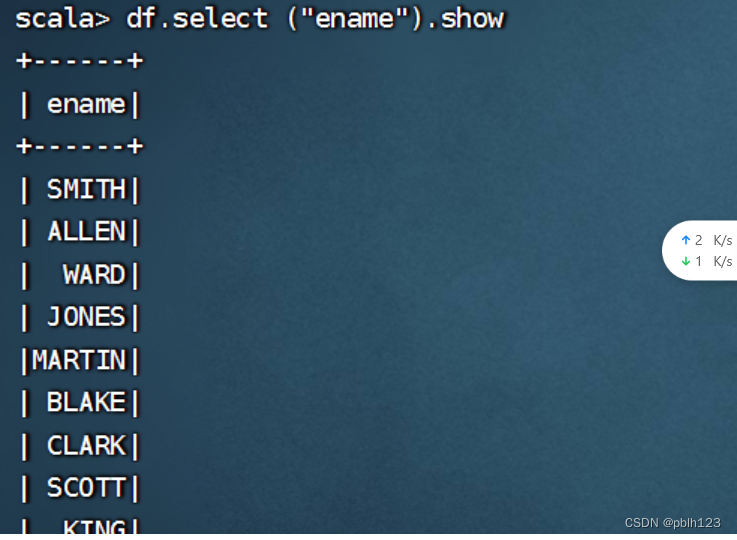
df.select($"ename").show
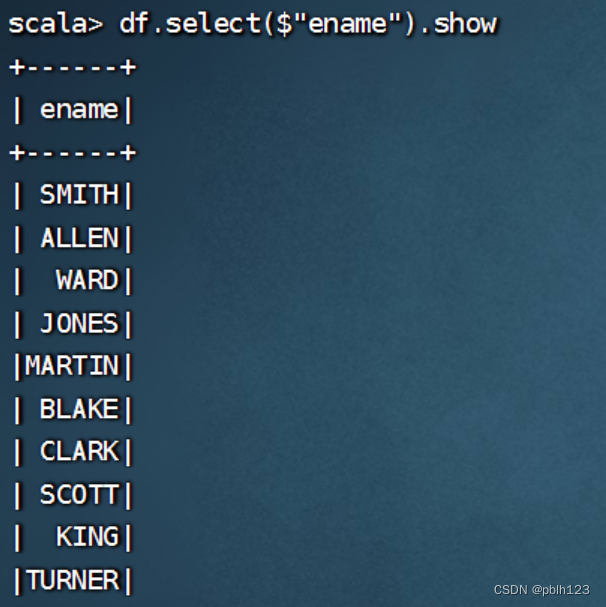
df.select($"ename",$"sal",$"sal"+100).show
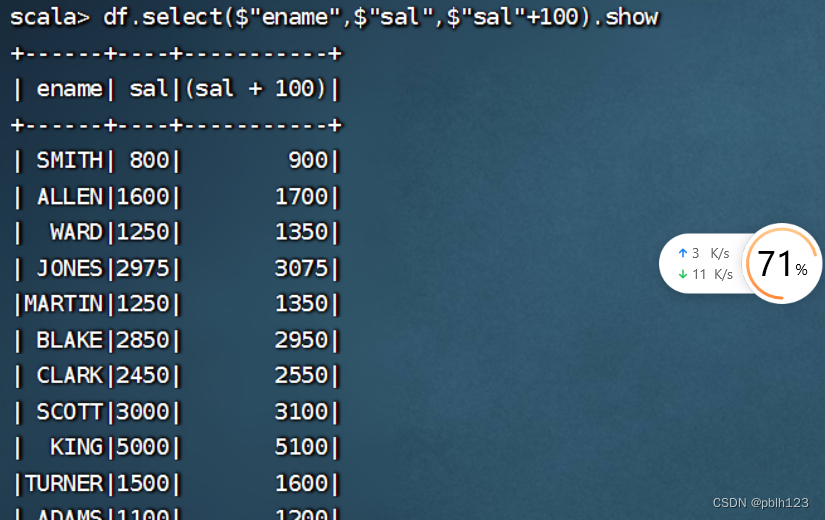
df.filter($"sal">2000).show
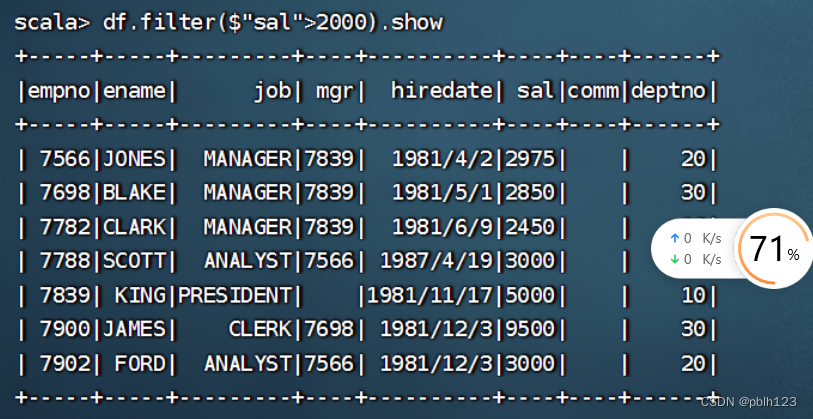
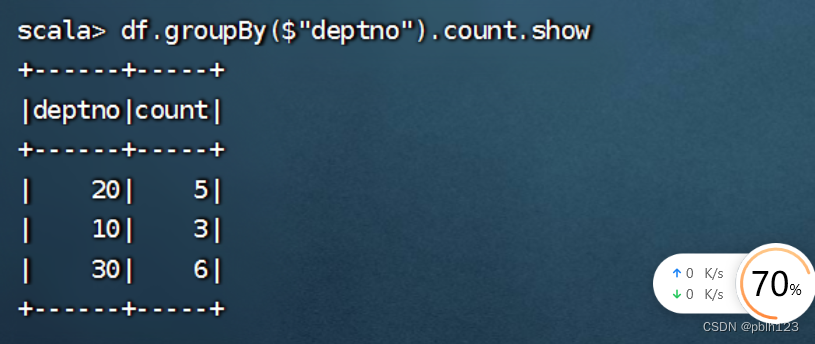
df.groupBy($"deptno").count.show
df.createOrReplaceTempView("emp")
spark.sql("select * from emp").show
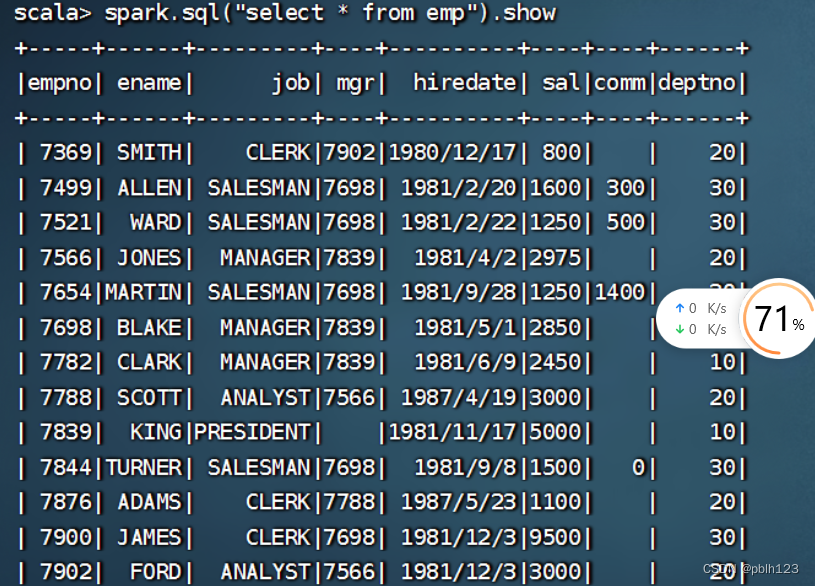
spark.sql("select * from emp where deptno=10").show

spark.sql("select deptno,sum(sal) from emp group by deptno").show

//1 创建一个普通的 view 和一个全局的 view
df.createOrReplaceTempView("emp1")
df.createGlobalTempView("emp2")
//2 在当前会话中执行查询,均可查询出结果
spark.sql("select * from emp1").show
spark.sql("select * from global_temp.emp2").show
//3 开启一个新的会话,执行同样的查询
spark.newSession.sql("select * from emp1").show //运行出错
spark.newSession.sql("select * from global_temp.emp2").show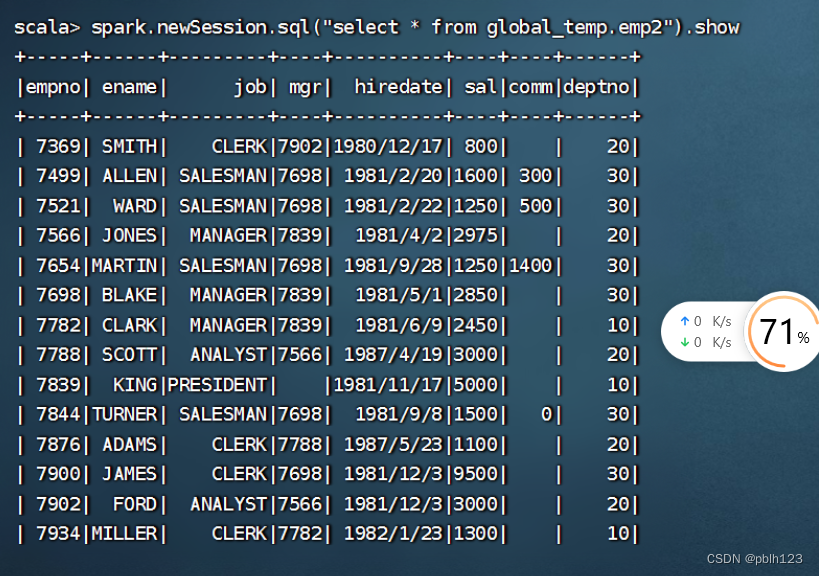
//7、创建 Datasets
//创建 DataSet,方式一:使用序列
//1、定义 case class
case class MyData(a:Int,b:String)
//2、生成序列,并创建 DataSet
val ds = Seq(MyData(1,"Tom"),MyData(2,"Mary")).toDS
//3、查看结果
ds.show
ds.collect
//创建 DataSet,方式二:使用 JSON 数据
//1、定义 case class
case class Person(name: String, gender: String)
//2、通过 JSON 数据生成 DataFrame
val df = spark.read.json(sc.parallelize("""{"gender": "Male", "name": "Tom"}""":: Nil))
//3、将 DataFrame 转成 DataSet
df.as[Person].show
df.as[Person].collect
//创建 DataSet,方式三:使用 HDFS 数据
val linesDS = spark.read.text("hdfs://Master:9000/input/word.txt").as[String]
val words = linesDS.flatMap(_.split(" ")).filter(_.length > 3)
words.show
words.collect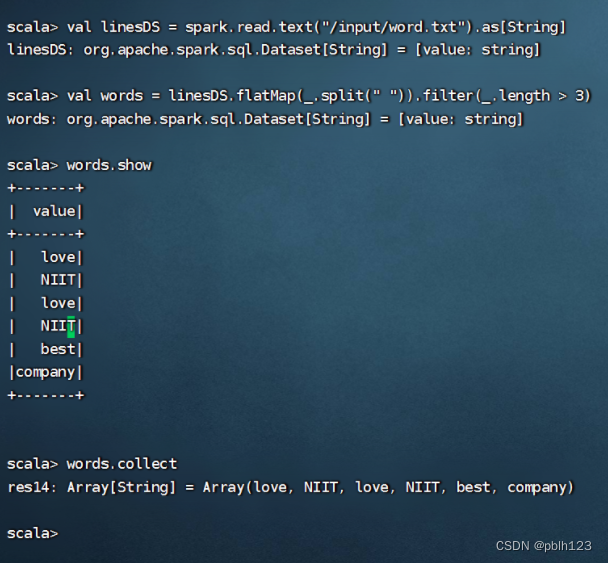
val result = linesDS.flatMap(_.split(" ")).map((_,1)).groupByKey(x => x._1).count
result.show
result.orderBy($"value").show
1、将emp.json文件上传到分布式环境,再用
hdfs dfs -put emp.json /input/
将本地文件put到hdfs文件系统的input目录下
//8、Datasets 的操作案例
//1.使用 emp.json 生成 DataFrame
val empDF = spark.read.json("hdfs://Master:9000/input/emp.json")
//查询工资大于 3000 的员工
empDF.where($"sal" >= 3000).show
//创建 case class
case classEmp(empno:Long,ename:String,job:String,hiredate:String,mgr:String,sal:Long,comm:String,deptno:Long)
//生成 DataSets,并查询数据
val empDS = empDF.as[Emp]
//查询工资大于 3000 的员工
empDS.filter(_.sal > 3000).show
//查看 10 号部门的员工
empDS.filter(_.deptno == 10).show
//多表查询
//1、创建部门表
val deptRDD=sc.textFile("hdfs://Master:9000/input/dept.csv").map(_.split(","))
case class Dept(deptno:Int,dname:String,loc:String)
val deptDS = deptRDD.map(x=>Dept(x(0).toInt,x(1),x(2))).toDS
//2、创建员工表
case classEmp(empno:Int,ename:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptno:Int)
val empRDD = sc.textFile("hdfs://Master:9000/input/emp.csv").map(_.split(","))
val empDS = empRDD.map(x =>Emp(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt)).toDS
//3、执行多表查询:等值链接
val result = deptDS.join(empDS,"deptno")
//另一种写法:注意有三个等号
val result = deptDS.joinWith(empDS,deptDS("deptno")===empDS("deptno"))
//查看执行计划:
result.explain